As of May 4, 2026, this is not a one-winner race: test GPT-5.5 first for OpenAI-native coding and tool workflows, keep Claude Opus 4.7 as the premium deployable control, and pilot DeepSeek V4 Pro when cost or open-weight flexibility is worth a same-task validation run.
The safest default is to choose the route you can verify, not the model name that wins a public table. GPT-5.5 belongs in the first OpenAI-native pilot, Opus 4.7 belongs in the premium control lane, and DeepSeek V4 Pro belongs in a bounded cost or self-host pilot until it proves the same task with the same tools.
| Route need | Start with | Why it fits | Stop rule |
|---|---|---|---|
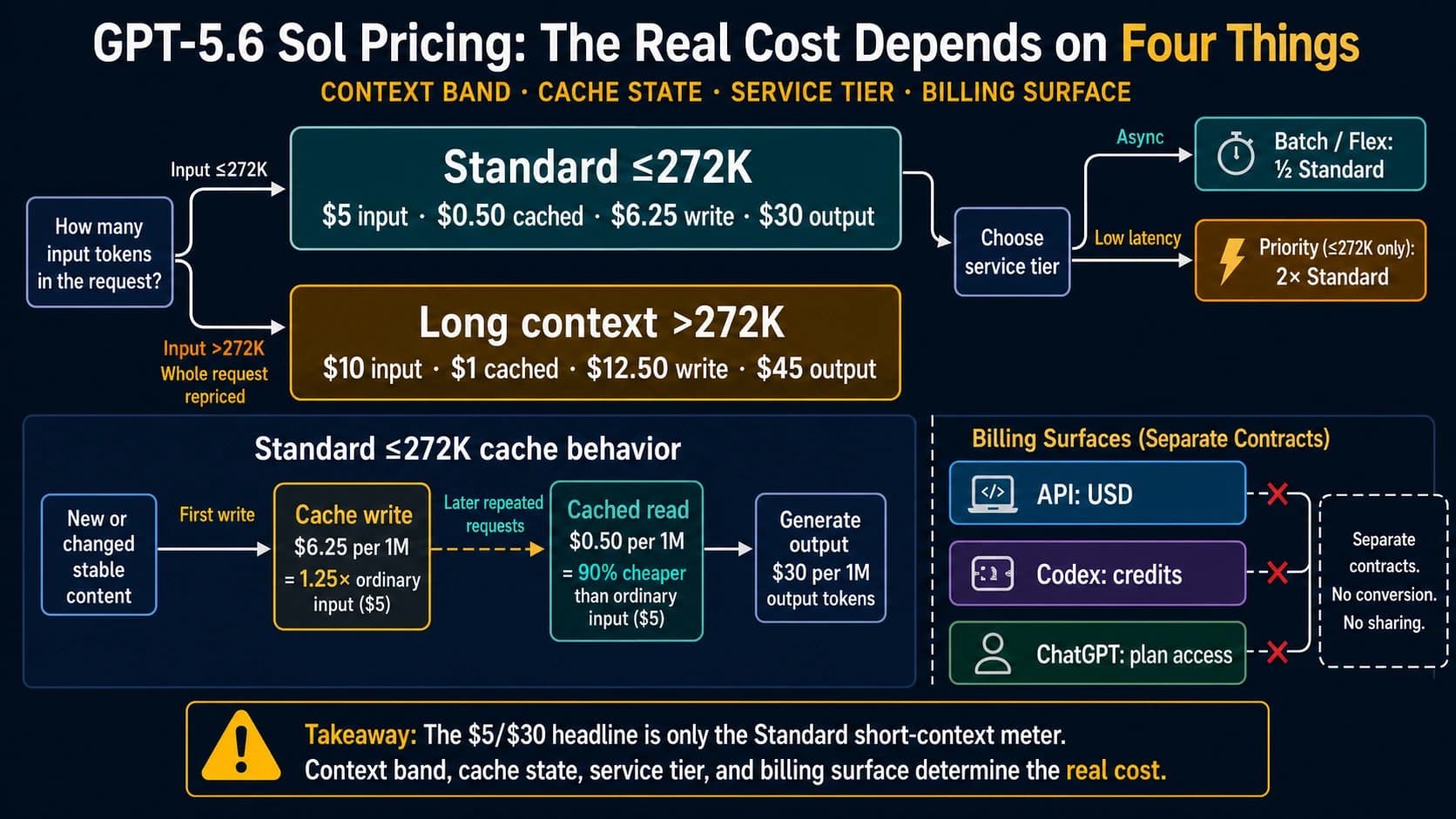
| OpenAI-native coding, Codex, or tool-heavy API work | GPT-5.5 | OpenAI developer docs currently list gpt-5.5, with 1M context and 128K max output, so it is the clean first test when your stack already depends on OpenAI routes. | Recheck account access and the older Help Center/API-doc conflict before production traffic. |
| Correctness-sensitive agents, cloud/API deployment, or premium control | Claude Opus 4.7 | Anthropic positions Opus 4.7 for demanding coding, agents, tools, vision, and deployable API/cloud use. | Do not approve the premium cost until it reduces defects or review time on your tasks. |
| Cost-sensitive pilots, open-weight control, or high-volume long-context experiments | DeepSeek V4 Pro | DeepSeek documents a temporary V4 Pro API discount, compatible URLs, 1M context, and a 384K max output route. | Treat it as a pilot until route fidelity, quality, latency, and rollback all pass. |
| Any production default change | Dual-run first | Public benchmarks and price gaps do not measure your failure modes. | No switch without the same prompts, tools, files, acceptance tests, and rollback threshold. |
Start With The Contract You Can Run
The practical comparison begins with the route owner. OpenAI owns GPT-5.5 model and API facts, Anthropic owns Claude Opus 4.7 facts, and DeepSeek owns the V4 Pro API and open-weight route. Secondary comparison pages can be useful for questions, but they should not decide model IDs, prices, endpoint behavior, context windows, or discount windows.
Here is the dated contract view that should sit above every benchmark argument:
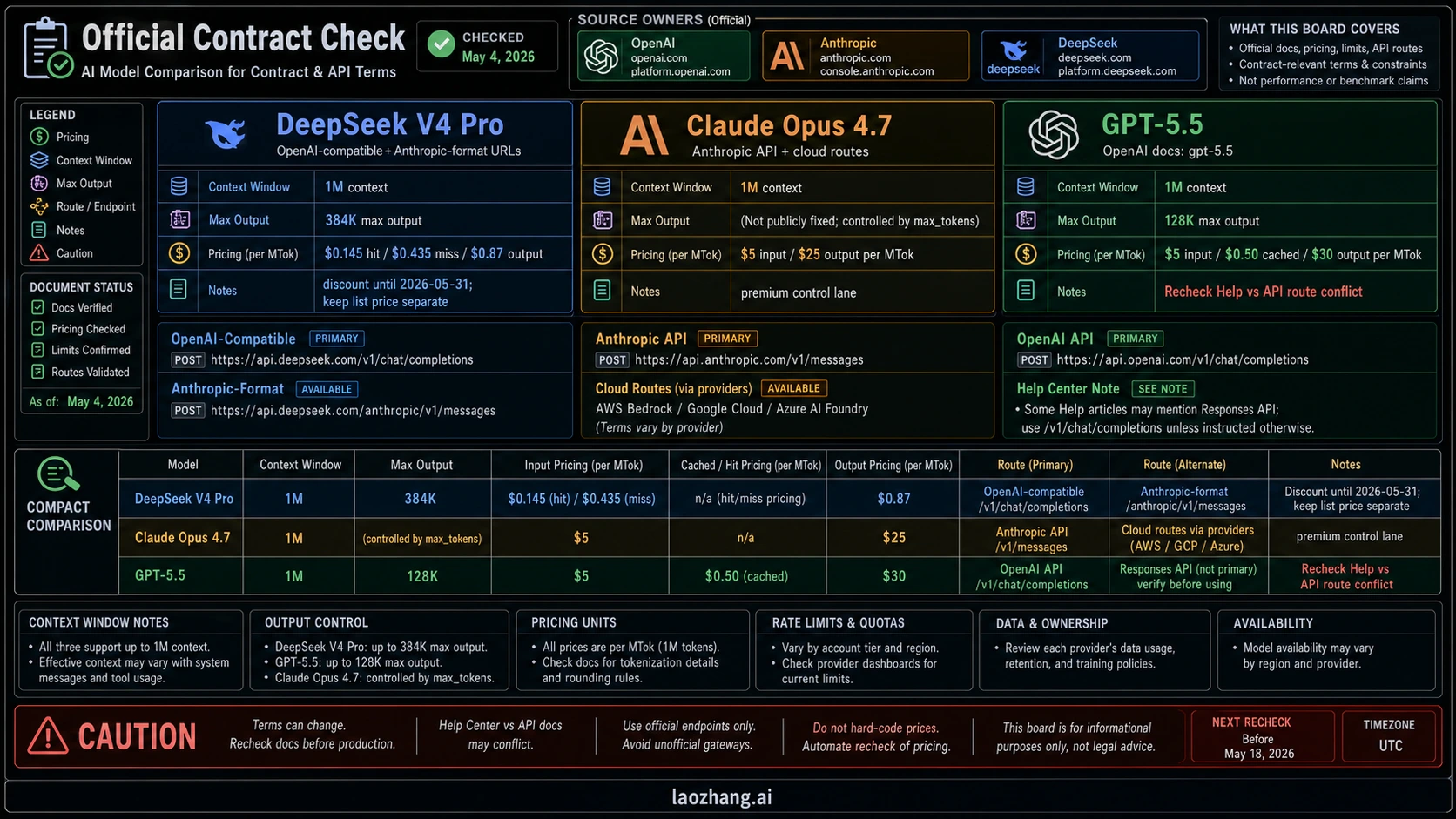
| Contract item | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 Pro |
|---|---|---|---|
| Primary owner route | OpenAI developer platform and OpenAI-native product/tool routes | Anthropic API, Claude products, and major cloud partners | DeepSeek API plus official open-weight model card |
| Model/API label to verify | OpenAI model docs list gpt-5.5, gpt-5.5-chat, gpt-5.5-thinking, and dated variants | Verify the current Anthropic model ID in Anthropic docs or the console before deployment | DeepSeek API docs list deepseek-v4-pro |
| Context and output | OpenAI docs list 1M context and 128K max output for GPT-5.5 | Anthropic positions Opus 4.7 for long-context and demanding agent work; verify the deploy route limits you use | DeepSeek docs list 1M context and 384K max output |
| Price owner | OpenAI docs currently list $5 input, $0.50 cached input, and $30 output per million tokens for the standard short-context API row | Anthropic's launch material lists the same Opus 4.6 price level: $5 input and $25 output per million tokens | DeepSeek docs list discount pricing through 2026-05-31: $0.145 cache-hit input, $0.435 cache-miss input, $0.87 output per million tokens |
| Boundary to keep visible | OpenAI's older GPT-5.3/5.5 ChatGPT rollout help article said GPT-5.5 was not launching to the API on that rollout day, while current developer docs list GPT-5.5. Recheck before production. | Premium price can be justified only when it reduces defects, review time, or rollout risk. | Compatible API URLs do not prove behavior parity with OpenAI or Anthropic routes. |
OpenAI's model docs and model comparison page are the controlling sources for GPT-5.5 API contract details. The OpenAI Help Center rollout note is still worth naming because it creates a dated source conflict: it described the ChatGPT/Codex rollout and said GPT-5.5 was not launching to the API that day. If you are about to route paid traffic, resolve that conflict against your current developer docs and account access, not a summary.
Anthropic's Claude Opus 4.7 launch page says the model is available across Claude products, the Anthropic API, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry, with pricing at $5 input and $25 output per million tokens. DeepSeek's pricing docs list V4 Pro pricing, compatible OpenAI and Anthropic-format URLs, 1M context, 384K max output, and the temporary discount window. The official DeepSeek V4 Pro model card adds the open-weight side: 1.6T total parameters, 49B activated, and 1M context.
Which Model Fits Which Workload
The clean way to compare DeepSeek V4 Pro, Claude Opus 4.7, and GPT-5.5 is to map them to the work you actually run. A model that looks best for an OpenAI-native tool loop may not be the safest premium control for a deployable multi-tool agent. A model that is much cheaper per million tokens may still be more expensive if it creates retries, defects, or review load.

| Workload | First model to test | Why | What to measure |
|---|---|---|---|
| OpenAI-native coding, Codex, Responses API tools, structured outputs | GPT-5.5 | The model sits closest to OpenAI's current tool and developer surface. | Accepted diffs, tool recovery, format stability, review time, token cost. |
| Correctness-sensitive coding agents or multi-step orchestration | Claude Opus 4.7 | Opus is the premium control lane when failure cost is higher than model cost. | Defect severity, tool-call reliability, rollback behavior, reviewer trust. |
| High-volume retries, batch exploration, fuzzing, cheap long-context tests | DeepSeek V4 Pro | The temporary discount and open-weight route make it worth a cost pilot. | Task-level success rate, retry rate, latency under load, route fidelity. |
| Long-context document, repo, or evidence analysis | Route-specific test | All three routes claim or support large context in different ways. | Actual truncation, output length, recall quality, cost at full prompt size. |
| Self-host, private cloud, or open-weight governance | DeepSeek V4 Pro | GPT-5.5 and Opus are closed hosted routes; DeepSeek's model card gives an open-weight path. | Deployment complexity, security review, inference cost, maintenance burden. |
| Existing production default | Dual-run | The incumbent model already has known failure modes and operational history. | Regression count, total cost, human minutes, fallback success. |
For OpenAI-native development, GPT-5.5 deserves the first seat because the model route is closest to Codex, OpenAI tools, and OpenAI account controls. That does not automatically make it the best production default for every API workflow, but it means you should test it first when your system already depends on OpenAI routes.
For premium reliability, Claude Opus 4.7 is the safer control lane. It is especially relevant when you need deployable API/cloud availability, multi-tool orchestration, high-resolution vision or document review, and conservative rollout behavior. If an Opus pilot costs more but avoids failures that consume senior review time, the premium can still be rational.
For cost and open-weight pressure, DeepSeek V4 Pro is the lane to pilot, not the lane to declare as a replacement. Its API discount is real enough to test; its compatible endpoints are useful; its open-weight model card matters for teams that need self-hosting or governance control. But none of those facts prove that it will recover from tool errors, preserve output format, or handle your exact codebase better than the premium routes.
Price Is A Routing Input, Not The Whole Decision
DeepSeek V4 Pro has the most visible price advantage. The current DeepSeek docs show discounted V4 Pro API pricing through May 31, 2026: $0.145 per million cache-hit input tokens, $0.435 per million cache-miss input tokens, and $0.87 per million output tokens. The list prices shown next to that discount are much higher: $0.58, $1.74, and $3.48 respectively. Keep both sets visible because a pilot started during the discount can look very different after the window closes.
GPT-5.5 is not a budget model by the current OpenAI comparison table: the standard short-context API row lists $5 input, $0.50 cached input, and $30 output per million tokens. Treat long-context pricing as a separate route check rather than merging it into this standard row. Claude Opus 4.7 sits at $5 input and $25 output per million tokens in Anthropic's launch material. On raw listed hosted API price, DeepSeek is cheaper by a wide margin, Claude is the premium control with a lower listed output price than GPT-5.5, and GPT-5.5 is the expensive OpenAI-native frontier route.
The price table still does not answer the deployment question by itself. A cheaper model can become expensive if it needs more retries, creates more review work, breaks structured output, or forces you to maintain a separate serving stack. A more expensive model can be cheaper at the task level if it cuts human review minutes and failed generations. That is why the decision keeps returning to same-task testing: the unit that matters is the completed job, not only the million-token row.
For budget planning, run four numbers before you choose:
| Cost variable | Why it matters |
|---|---|
| Input and cached input | Long prompts, repeated context, and cache behavior change the model ranking. |
| Output length | GPT-5.5's listed output price and DeepSeek's 384K max output can affect long-generation economics differently. |
| Retry rate | A lower token price can lose if the model needs multiple attempts. |
| Human review time | The most expensive part of a coding or agent workflow may be the senior engineer reading the result. |
How To Read Benchmarks Without Overclaiming
Public benchmarks are useful when they resemble your workload and useless when they become a universal crown. Coding-agent rows, terminal-task evaluations, browsing or research scores, long-context tests, and math/security benchmarks each measure different things. A strong GPT-5.5 row in an OpenAI-native benchmark is a reason to test GPT-5.5 in that route. It is not proof that DeepSeek V4 Pro cannot be a cost pilot, or that Opus 4.7 is no longer the right premium control.
The same caution applies in reverse. A DeepSeek price/performance claim is a reason to build a pilot harness. It is not proof that DeepSeek can replace Claude Opus 4.7 in a high-risk agent. An Anthropic launch claim is a reason to include Opus in the control lane. It is not proof that Opus is always worth the premium when GPT-5.5 or DeepSeek passes the same task.
Use this evidence ladder:
- Official docs decide whether the route exists, what it costs, what model label to call, and what limits apply.
- Provider-reported or third-party benchmarks suggest which workloads deserve testing.
- Your same-task harness decides whether the model should become a default.
- Production rollout decides whether the improvement survives real traffic, permissions, latency, and failures.
This ladder also prevents provider-route mistakes. DeepSeek offers OpenAI-compatible and Anthropic-format API URLs, but URL shape is not behavior parity. Tool calling, streaming, timeouts, tokenization, output format, safety behavior, retries, and SDK edge cases can differ. Treat compatibility as a lower-integration starting point, not as proof that existing OpenAI or Anthropic code can switch without validation.
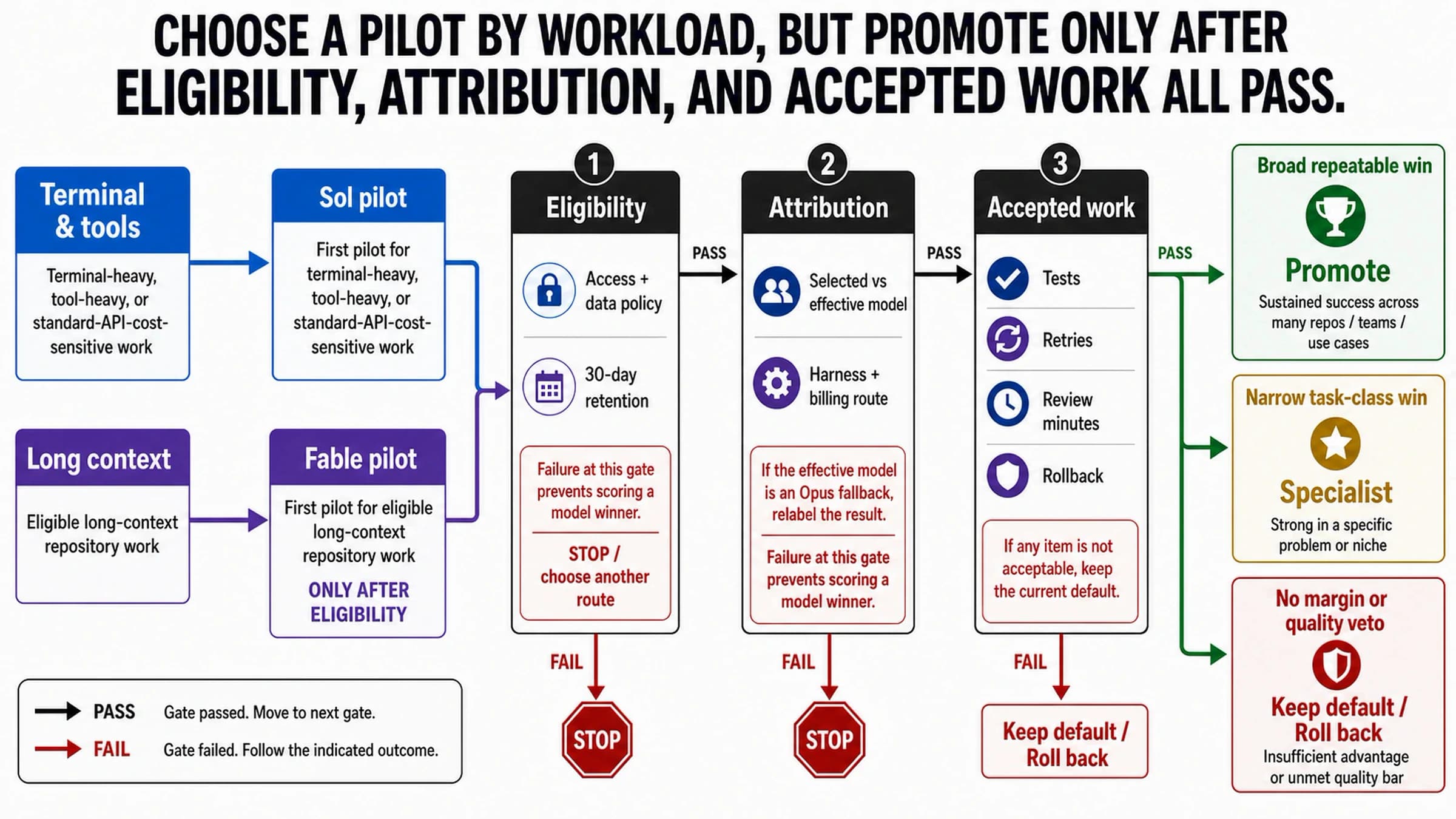
Same-Task Pilot Before You Switch
A practical pilot can be small. It only needs to be fair enough that the result can survive a real deployment conversation.
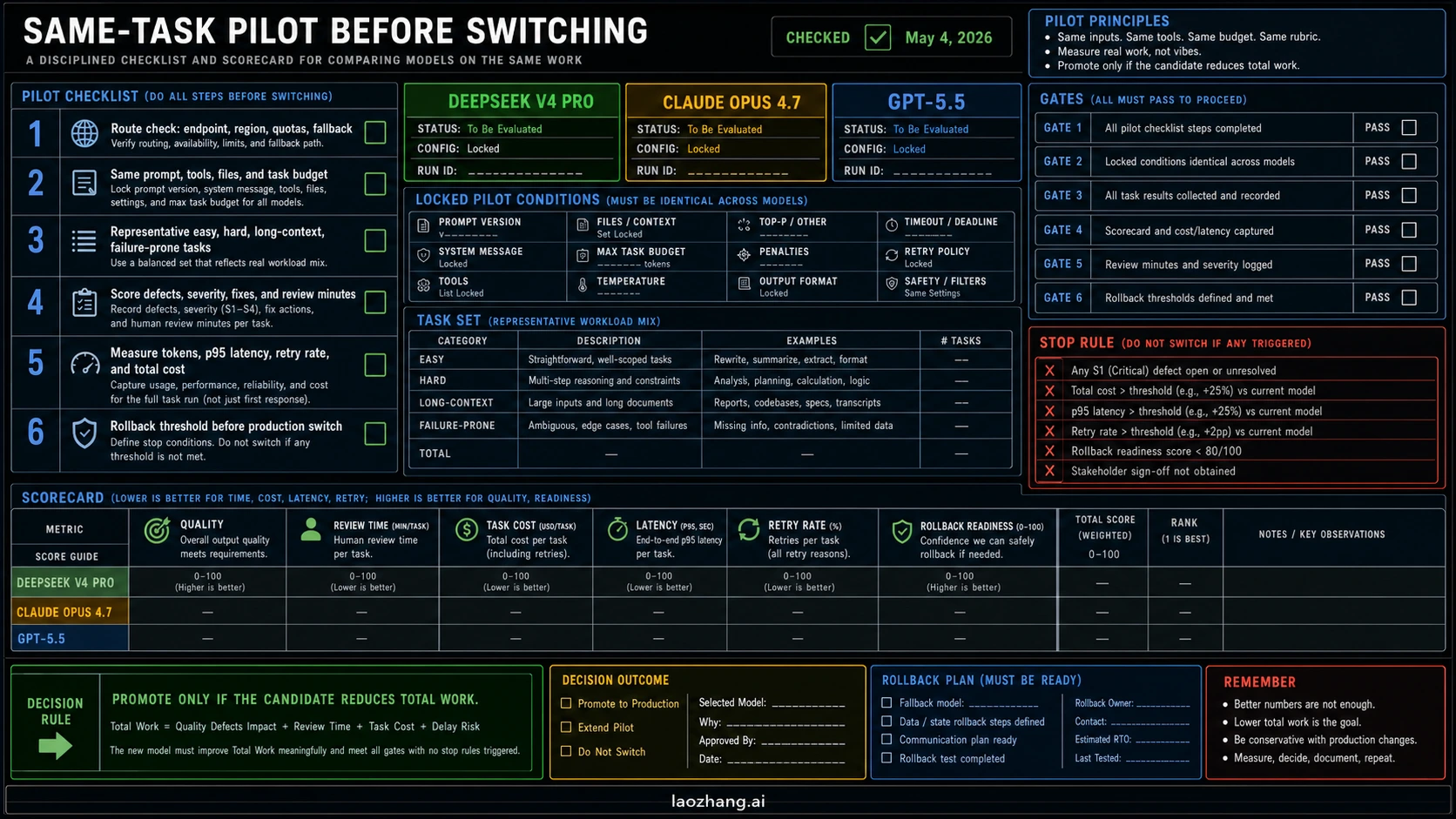
| Pilot gate | What to do | Pass condition |
|---|---|---|
| Route check | Confirm model label, endpoint, account access, region, quota, and fallback. | The team can call the route it plans to deploy. |
| Same prompt and tools | Use the same system prompt, files, tools, permissions, and task budget where the surfaces allow it. | Differences come from model behavior, not a better harness for one model. |
| Representative tasks | Include easy, hard, long-context, output-format, and failure-prone tasks. | The sample matches the work that costs money or review time. |
| Defect scoring | Classify correctness, severity, security risk, and recovery effort. | The candidate reduces high-severity failures, not just superficial errors. |
| Review-time scoring | Count human review minutes and accepted-result rate. | The candidate reduces total work for the team. |
| Cost and latency | Measure input, cached input, output, retries, task-level cost, and p95 latency. | Savings survive full-task accounting. |
| Rollback threshold | Decide what failure rate, latency, or cost triggers fallback. | The old route can return without rebuilding the system. |
For a team already using GPT-5.4, Opus 4.7, or another stable model, the threshold should be higher than "the new model is impressive." Keep the current default while you shadow-run the candidate. Promote only when the new route reduces total work, not just when it writes a stronger demo answer.
For a team choosing its first route, run GPT-5.5 and Opus 4.7 on the high-risk tasks first, then add DeepSeek V4 Pro where cost or open-weight control matters. If DeepSeek passes the same tasks, it can become a serious default candidate for that workload. If it fails in ways that require manual repair, keep it in the exploration lane and use it where low cost still helps.
Adjacent Decisions
The exact DeepSeek V4 Pro vs Claude Opus 4.7 vs GPT-5.5 route decision is one job. If your question is narrower, use the sibling that owns that job.
If your real choice is only OpenAI versus Anthropic, use the pairwise GPT-5.5 vs Claude Opus 4.7 guide. It can spend more space on OpenAI-native testing versus Anthropic deployability without the DeepSeek cost lane.
If you want the broader cheap-route pool with Kimi included, use Kimi K2.6 vs DeepSeek V4 vs GPT-5.5 vs Claude Opus 4.7. That four-way allocation problem needs its own route pool.
If you are still choosing among older official frontier API routes, use Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro. If you need DeepSeek release and route background before the comparison, start with DeepSeek V4.
FAQ
Is GPT-5.5 better than Claude Opus 4.7 and DeepSeek V4 Pro?
GPT-5.5 is the better first test when your work is OpenAI-native, especially coding or tool workflows that already depend on OpenAI routes. That does not make it a universal winner. Claude Opus 4.7 remains the premium control lane, and DeepSeek V4 Pro deserves a cost/open-weight pilot when the workload can be validated fairly.
Is DeepSeek V4 Pro cheaper than GPT-5.5 and Claude Opus 4.7?
Yes on the current listed API discount. DeepSeek V4 Pro's documented discount prices are far below GPT-5.5 and Opus 4.7 hosted API prices, but the discount expires on the documented schedule and must be separated from list price. The completed-task cost still depends on quality, retries, latency, and review time.
Should I use Claude Opus 4.7 for coding agents?
Use Claude Opus 4.7 first when the coding agent is correctness-sensitive, deployable through Anthropic or cloud routes, and expensive to review or roll back. Use GPT-5.5 first when the work is OpenAI-native. Use DeepSeek V4 Pro as a pilot when cost or open weights matter more than premium control.
Can DeepSeek V4 Pro replace Claude Opus 4.7?
Only after a same-task pilot proves it on your workload. DeepSeek V4 Pro can be a serious candidate for high-volume or open-weight work, but price and compatible endpoints do not prove production replacement.
Is GPT-5.5 available through the API?
Current OpenAI developer docs list GPT-5.5 model entries and API price/context details. An older OpenAI Help Center rollout note said GPT-5.5 was not launching to the API on that rollout day. Before routing production traffic, verify the current model docs, account access, limits, and console behavior for your organization.
Which model should I test first for long-context work?
Test the route that matches your deployment need. OpenAI and DeepSeek docs both list 1M context for the relevant routes, and Anthropic positions Opus 4.7 for demanding long-context agent work. Run a real long-context task and measure truncation, recall, output length, latency, and full-task cost.
What is the safest production switch rule?
Do not switch a production default from public benchmarks, price gaps, or launch excitement alone. Dual-run the candidate on the same prompts, tools, files, task budgets, and acceptance tests. Promote only when it reduces total work and has a rollback path.
The right answer is a route plan: GPT-5.5 for OpenAI-native first tests, Claude Opus 4.7 for premium deployable control, and DeepSeek V4 Pro for cost or open-weight pilots. Make the model earn a production switch on the same tasks before you change the default.