As of Apr 24, 2026, this comparison should be built around DeepSeek V4, not an older DeepSeek label. Test Kimi K2.6 first when the job is low-cost coding-agent exploration, test DeepSeek V4 Flash or V4 Pro when you need a cheap callable API route today, use GPT-5.5 inside ChatGPT or Codex while its API contract is still pending, and keep Claude Opus 4.7 first when hidden defects, long context, and review cost matter more than token price.
The practical rule is not "pick the model with the loudest launch week." Pick the route whose official contract matches the work, then run the same task before changing defaults. The same repository snapshot, prompt, tools, tests, reviewer, and rollback threshold matter more than a social benchmark screenshot.
| Route | Test first when | Current boundary | Stop rule |
|---|---|---|---|
| Kimi K2.6 | You need many cheap coding-agent attempts or low-risk scaffolding. | Kimi documents the K2.6 model, RMB pricing, multimodal input, and a 256k-class context route. | Do not call it the production default until it wins the same workflow repeatedly. |
| DeepSeek V4 | You need a current DeepSeek API route with low input and output prices. | DeepSeek documents deepseek-v4-flash and deepseek-v4-pro, OpenAI and Anthropic-format base URLs, 1M context, and 384K max output. | Do not use older DeepSeek labels as the current deployment target. |
| GPT-5.5 | You work inside ChatGPT or Codex and want OpenAI-native behavior. | OpenAI says GPT-5.5 is available in ChatGPT and Codex, with API availability coming soon. | Do not invent a GPT-5.5 API model ID, price row, or quota. |
| Claude Opus 4.7 | The task is migration-heavy, security-adjacent, long-context, or expensive to review. | Anthropic lists claude-opus-4-7, 1M context, and Opus pricing. | Do not switch away without a same-task dual-run. |
The Fast Answer
The first model to test is route-dependent. Kimi K2.6 is the cheapest early pilot candidate when the goal is more attempts, more drafts, and more low-risk coding-agent coverage. DeepSeek V4 is the DeepSeek route to measure now because its Flash and Pro API rows are the current public contract. GPT-5.5 is a strong first test inside OpenAI operator surfaces, especially Codex, but the production API question must wait for official API documentation. Claude Opus 4.7 remains the first route for high-risk work where a hidden bug costs more than the token bill.
That makes this a router design problem, not a leaderboard problem. If the work is a low-risk bulk edit, test Kimi and DeepSeek V4 first. If the work is a difficult repo migration, use Opus as the control. If the work is already happening in Codex, test GPT-5.5 there before planning a server-side migration. The winner is the route that produces accepted work after review.
Official Contract Lanes
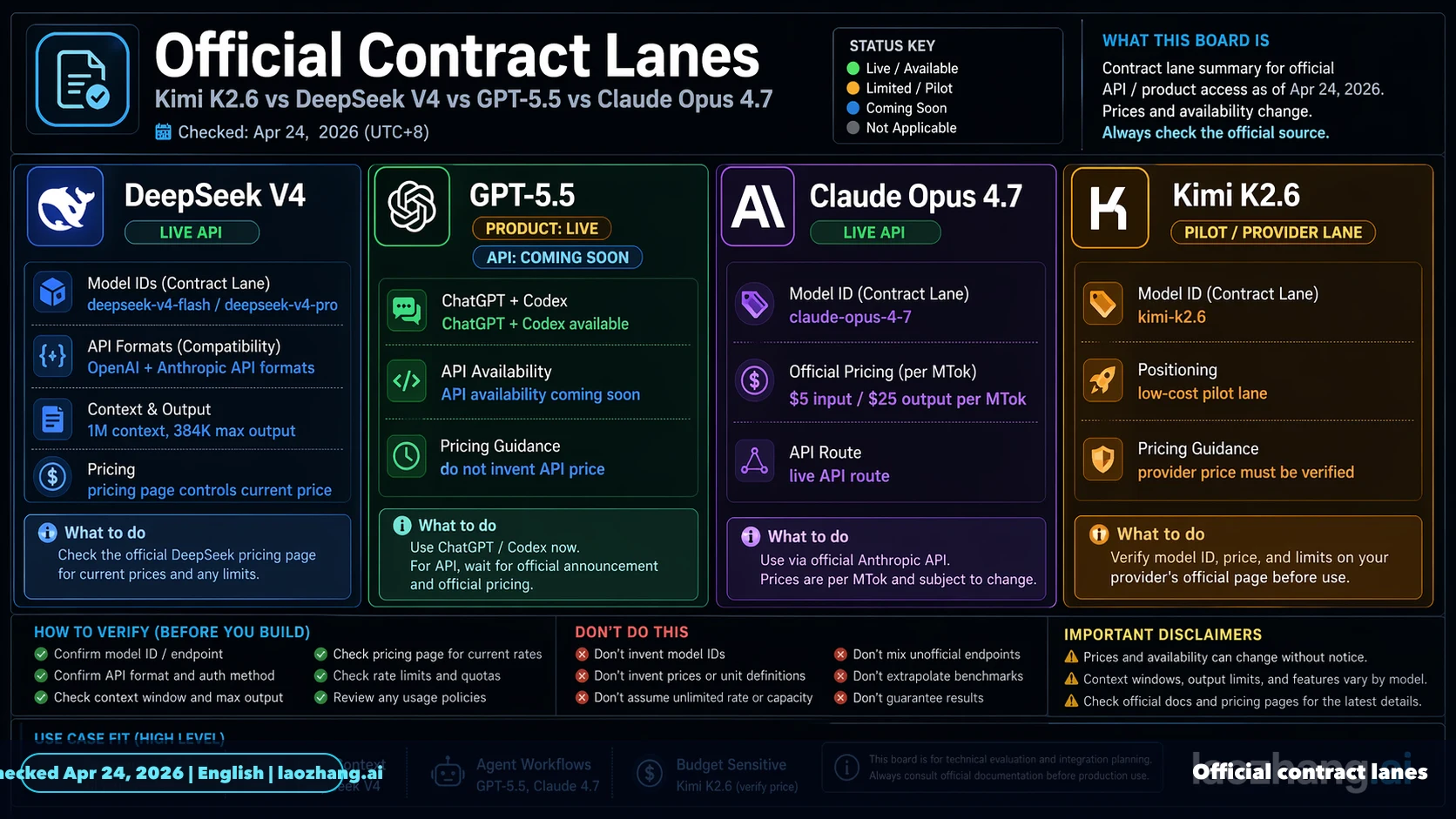
Official rows keep the comparison honest. Kimi's K2.6 pricing page says K2.6 is the latest and smartest Kimi model, supports text, image, and video input, and has a 256k context route. DeepSeek's pricing page lists deepseek-v4-flash and deepseek-v4-pro with a 1M context window, 384K maximum output, OpenAI-format base URL, Anthropic-format base URL, and prices of $0.028 or $0.145 cache-hit input, $0.14 or $1.74 cache-miss input, and $0.28 or $3.48 output per million tokens. OpenAI's current API guide is still titled around GPT-5.4 and states that GPT-5.5 is available in ChatGPT and Codex with API availability coming soon. Anthropic's model and pricing docs list Claude Opus 4.7 at $5 input and $25 output per million tokens with 1M context at standard pricing.
| Contract item | Kimi K2.6 | DeepSeek V4 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|---|---|
| Owner route | Kimi platform | DeepSeek API | ChatGPT and Codex first | Anthropic API and cloud routes |
| Deploy label | kimi-k2.6 | deepseek-v4-flash or deepseek-v4-pro | API ID must be rechecked when published | claude-opus-4-7 |
| Context | 256k-class route | 1M context, 384K max output | API context pending | 1M context |
| Price owner | Kimi RMB pricing page | DeepSeek USD pricing page | no public GPT-5.5 API price row in the current API guide | Anthropic USD pricing page |
Sources checked on Apr 24, 2026: DeepSeek V4 release, DeepSeek pricing, Kimi K2.6 pricing, OpenAI latest model guide, Claude model overview, and Claude pricing. Recheck these before changing production defaults.
Why DeepSeek V4 Changes The Comparison
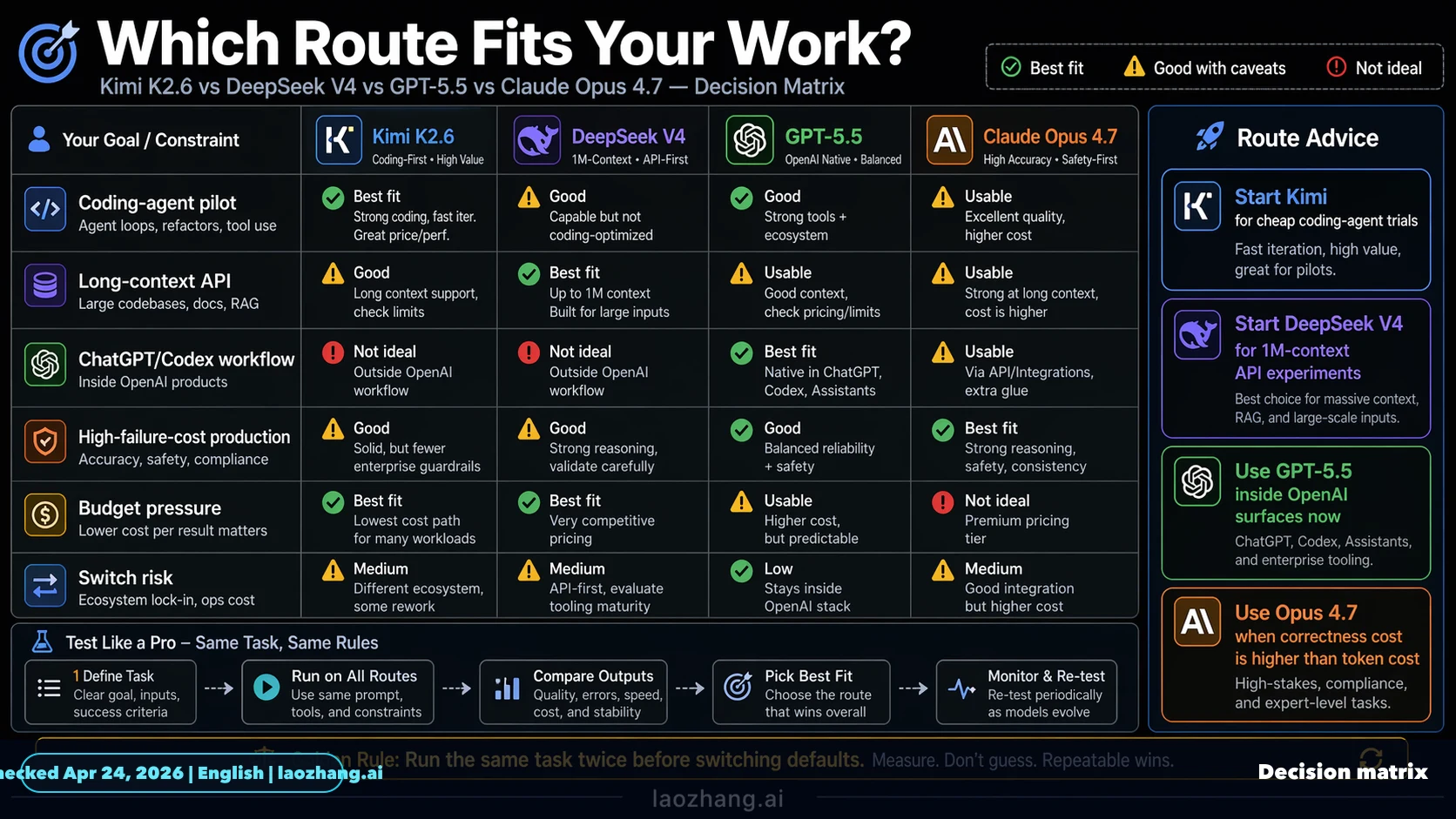
DeepSeek V4 is not just another name to drop into a title. It changes the test plan because it gives the DeepSeek lane a current model ID, price row, context route, and compatibility route. Flash is the cheap default DeepSeek candidate; Pro is the stronger DeepSeek candidate when you want to stay inside the DeepSeek API contract before paying premium Opus prices.
This also prevents a common launch-week mistake: comparing a current Kimi release, a current OpenAI product surface, and a current Anthropic API route against a stale DeepSeek label. The fair comparison is current route against current route. If a buyer or developer can call deepseek-v4-flash or deepseek-v4-pro today, those are the rows to measure.
Price Is Only A Pilot Signal
Cheap tokens matter because agentic work needs retries, variants, and recovery. Kimi and DeepSeek V4 deserve early tests when the task can tolerate review and iteration. But price is not a replacement verdict. A cheap run becomes expensive if it creates hidden defects, extra reviewer time, tool loops, or rollback work.
Use this cost log before changing defaults:
| Cost area | Record | Decision use |
|---|---|---|
| Token cost | input, cache hit, cache miss, output, retries, tool calls | proves invoice shape, not quality |
| Quality cost | blocker defects, major defects, minor defects, format misses | shows whether cheap attempts are actually usable |
| Time cost | latency, queue time, reviewer minutes, reruns | catches cost shifted to humans |
| Integration cost | model ID, auth, context behavior, tool behavior, billing owner | avoids a one-off demo becoming a brittle default |
Same-Task Pilot Checklist

A default model switch is a production change. Pick five to ten real tasks: one small bug fix, one refactor, one test-writing job, one long-context analysis task, and one ambiguous task where the model must resist a bad assumption. Run the candidate route and the current default under the same constraints.
Set loss thresholds before the run starts. One blocker defect should stop default promotion. Three major defects should keep the route in pilot mode. Reviewer time above twice the control route usually means token savings are being moved to people. Tool or format instability means the route may work in chat but fail as an agent default.
Existing Users Should Route By Workload
If you already use Kimi, add DeepSeek V4 Flash and Pro to the cheap-route pool and keep Opus as the high-risk control. If you already use DeepSeek, update the test harness to V4 model IDs before comparing against Kimi, GPT-5.5, or Opus. If you already use OpenAI API models, learn from GPT-5.5 inside ChatGPT or Codex now and wait for the API contract before server routing. If you already use Claude Opus 4.7, keep it for migrations and correctness-sensitive work while cheaper routes prove themselves on lower-risk task classes.
For narrower decisions, the existing Kimi K2.6 vs Claude Opus 4.7 guide covers the cheap-pilot versus premium-default split, and GPT-5.5 vs Claude Opus 4.7 covers OpenAI surface versus Anthropic production routing.
FAQ
Is DeepSeek V4 the right keyword now?
Yes. For this comparison, DeepSeek V4 is the current route because DeepSeek documents V4 Flash and V4 Pro API rows. Older labels should not own the title or the deployment decision.
Is GPT-5.5 available through the API?
Treat GPT-5.5 as live in ChatGPT and Codex, but fail closed on API deployment until OpenAI publishes the API model ID, price row, limits, and tool behavior for your account.
Which route should a coding-agent team test first?
Use Kimi for cheap low-risk volume, DeepSeek V4 for cheap callable API tests, GPT-5.5 inside Codex for OpenAI-native operator flow, and Opus 4.7 for high-risk production correctness.
Can DeepSeek V4 replace Claude Opus 4.7?
Not from price alone. DeepSeek V4 may win low-cost API workloads, but Opus remains the control route when hidden failure cost, long context, and reviewer time dominate.
What is the safest switch rule?
Run the same task through both routes and promote only after repeated wins on accepted diffs, defect severity, reviewer time, latency, retry cost, and rollback risk.