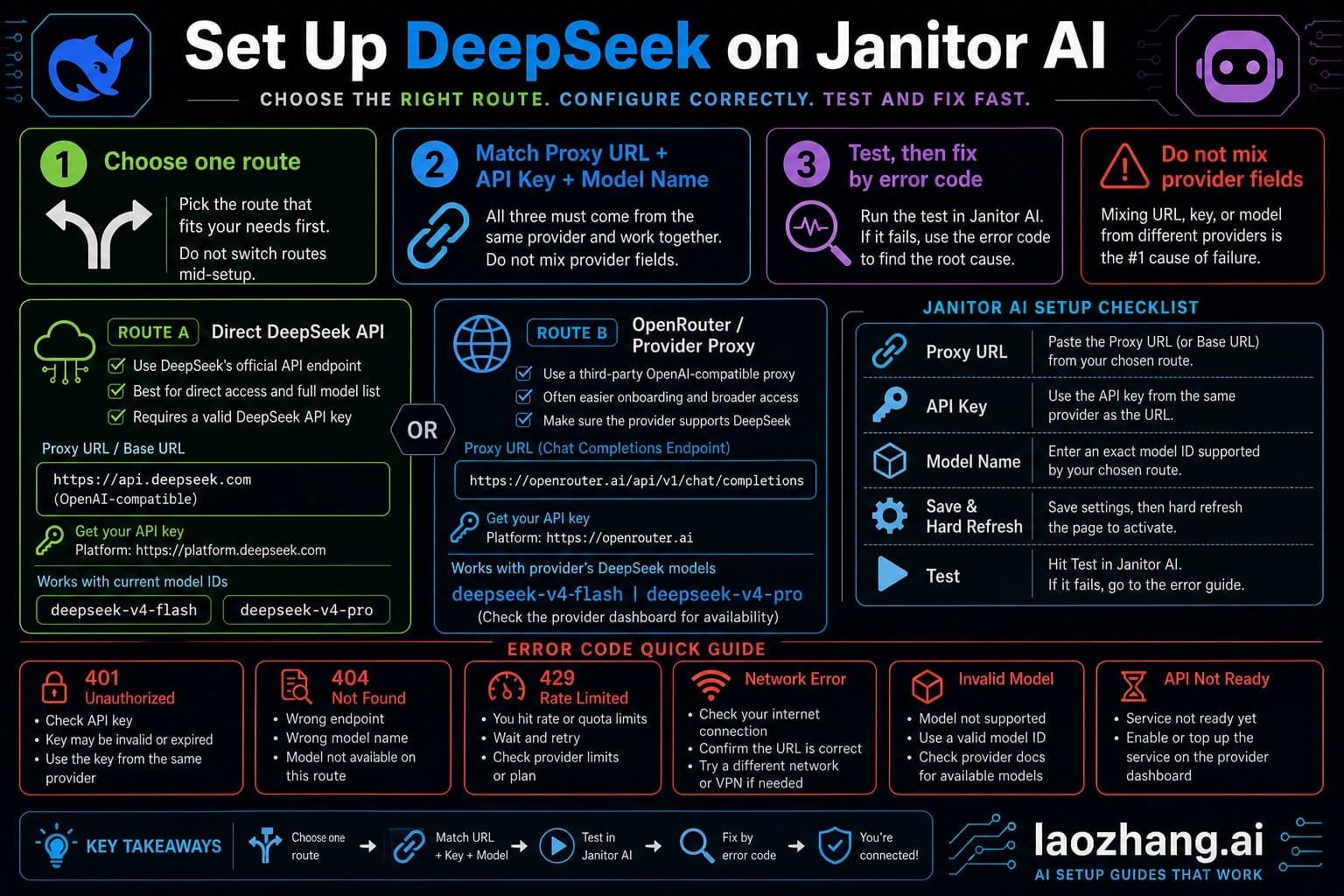
DeepSeek V4 Preview is live as of April 24, 2026. For API users, the useful change is concrete: the current official model IDs are deepseek-v4-flash and deepseek-v4-pro, both exposed through OpenAI-format and Anthropic-format DeepSeek endpoints. The older deepseek-chat and deepseek-reasoner aliases currently map to V4 Flash modes, but DeepSeek says they become inaccessible after July 24, 2026 at 15:59 UTC.
So the first decision is not whether DeepSeek V4 is "free." The web and app routes are useful for trying the release, and the weights are open, but the official hosted API is a priced token contract. Start with Flash unless your workload proves that Pro's harder reasoning or agentic coding behavior is worth the higher price.
What changed in the V4 Preview release
DeepSeek moved V4 from speculation into an official API surface. The release names two models: V4 Pro at 1.6T total parameters and 49B active parameters, and V4 Flash at 284B total parameters and 13B active parameters. DeepSeek also says 1M context is now standard across official services.
That matters because older comparison pages and rumors were still treating V4 as an unverified row. A developer now has a real route to check: model list, pricing table, balance endpoint, rate-limit behavior, and migration deadline. The old comparison context is still useful as a record of why V4 mattered, but it should not own today's implementation decision.
Choose Flash or Pro before you update code

| Choice | Start here when | Watch this boundary |
|---|---|---|
deepseek-v4-flash | You need the default API route, lower cost, faster response, or broad production testing. | Do not assume it is a free hosted API; usage still follows the official pricing and balance rules. |
deepseek-v4-pro | You need harder reasoning, stronger agentic coding, or higher quality on tasks where your own evaluation shows a gain. | Pro pricing is much higher, so use it where the value is visible in your workload. |
deepseek-chat | You are keeping old integrations alive briefly. | It is a compatibility alias to V4 Flash non-thinking mode, not a long-term model choice. |
deepseek-reasoner | You are keeping old reasoning integrations alive briefly. | It is a compatibility alias to V4 Flash thinking mode and has the same retirement deadline. |
If you are building today, pin the explicit V4 model ID. If you are maintaining an older application, treat alias cleanup as a scheduled migration, not optional housekeeping.
What to check in the API contract

The API surface is straightforward but easy to mislabel. The OpenAI-format base URL is https://api.deepseek.com; the Anthropic-format base URL is https://api.deepseek.com/anthropic. Both V4 models list 1M context and a maximum output of 384K tokens.
Pricing is not a single "cheap" label. DeepSeek publishes per-1M-token rates with cache-hit and cache-miss input pricing. Flash is listed at $0.028 cache-hit input, $0.14 cache-miss input, and $0.28 output. Pro is listed at $0.145 cache-hit input, $1.74 cache-miss input, and $3.48 output. Those numbers can change, so production docs should link to the live pricing page instead of freezing old screenshots.
Balance and limits are part of the same contract. The balance endpoint reports total, granted, and topped-up balances; charges prefer granted balance first when both exist. Rate limits are dynamic, and the operational signal is HTTP 429. Your client should back off cleanly rather than treating the absence of a fixed public limit as unlimited throughput.
Migration checklist for old aliases

- Search your code for
deepseek-chatanddeepseek-reasoner. - Decide whether each call should move to
deepseek-v4-flashordeepseek-v4-pro. - Test thinking and non-thinking behavior explicitly instead of relying on alias names.
- Call
/modelsin your deployment environment and confirm both V4 IDs are visible. - Check
/user/balanceserver-side before load tests. - Implement retry, backoff, and clear user feedback for
429. - Finish alias removal before the July 24, 2026 retirement window.
This is also the right moment to audit wrappers. If a provider advertises "DeepSeek V4 free API," check whether it is the official DeepSeek API, a wrapper with promotional credits, a local open-weight endpoint, or a web-session workaround. Those routes have different reliability, billing, and data boundaries.
How to evaluate V4 without overclaiming

Use Flash as the default evaluation route because it is the economical hosted choice and is the target behind the compatibility aliases. Use Pro only where your own tasks show a measurable improvement: long-context reasoning, agentic coding, tool-heavy workflows, or tasks where failure cost is high.
Do not publish "best model" claims from generic benchmarks alone. A useful V4 evaluation should keep three columns: task family, quality delta, and cost delta. If Pro wins quality but multiplies cost, the right default can still be Flash. If Flash passes your acceptance tests, it is the route most API teams should try first.
For teams comparing against the older April landscape, our previous DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4 comparison should now be read as pre-release context. The current implementation answer comes from the V4 release and API docs.
FAQ
Is DeepSeek V4 API free?
The official hosted API is not an unlimited free API. DeepSeek publishes token pricing and balance rules. The web/app experience and open weights are separate routes from hosted API billing.
Which DeepSeek V4 model should I start with?
Start with deepseek-v4-flash for most API tests. Move to deepseek-v4-pro only when your own workload proves that the stronger route justifies the cost.
Can I keep using deepseek-chat and deepseek-reasoner?
Only as a short compatibility bridge. DeepSeek says both aliases will be fully retired after July 24, 2026 at 15:59 UTC. New code should use explicit V4 model IDs.
What should I monitor after switching?
Monitor model ID availability, balance, cache behavior, output cost, latency, and 429 responses. Those checks catch most integration mistakes before users see them.