
Claude Opus 4.7 is now Anthropic's stronger default Opus route for teams doing harder coding, longer agentic work, and higher-resolution vision tasks, but it is not a blind same-price swap from Claude Opus 4.6.
The fast answer is to move to Opus 4.7 if you want the stronger coding and reasoning profile now, stage the migration if prompt stability or cost forecasting matters, and keep Opus 4.6 as a baseline while you validate edge-case workflows before replacing defaults everywhere.
That boundary matters because unchanged list pricing does not settle the real upgrade cost. Anthropic kept Opus 4.7 at the same official $5/$25 per-million-token list price as Opus 4.6, but its migration guide says the same input can map to roughly 1.0-1.35x more tokens on 4.7 depending on content type, and that prompt or harness review may help because 4.7 follows instructions more literally.
As of April 17, 2026, the practical route is simple: switch now for agent-heavy coding workflows, stage carefully for tightly tuned or cost-sensitive systems, and keep 4.6 pinned as the control route until benchmark relevance, spend, and prompt behavior all check out on your own workloads.
The Fast Answer
If you are choosing today, do not start with a benchmark leaderboard. Start with the route that best matches your workflow and your tolerance for migration noise.
| If this sounds like you... | Best move right now | Why |
|---|---|---|
| You use Opus for repo-wide coding, agent loops, or vision-heavy debugging. | Switch now to Opus 4.7. | Anthropic's published coding and reasoning results mostly moved forward, and 4.7 is the new top Opus route. |
| Your prompts, harnesses, or budgets are tightly tuned. | Stage the migration. | The list price stayed flat, but token mapping and effort behavior can still change real spend and output feel. |
| You need a stable control route or you care about narrow exception workloads. | Keep Opus 4.6 as a baseline for now. | Anthropic's own chart still leaves a few rows where 4.6 holds up better, and a control route makes rollout decisions much cleaner. |
That table is the page's real thesis. Opus 4.7 is usually the right new default, but "usually" is not the same as "replace every 4.6 route immediately." If your team already has tuned prompts, cached cost expectations, and stable evaluation tasks on 4.6, the smartest move is a measured migration rather than a launch-day flip.
What Actually Changed From Opus 4.6 to Opus 4.7
The cleanest way to read this upgrade is not "new version beats old version." It is "same premium slot, same list price, different capability profile, and different migration behavior."
Claude Opus 4.6 launched on February 5, 2026 as Anthropic's flagship reasoning model. Claude Opus 4.7 followed on April 16, 2026 and kept the same official API price of $5 input and $25 output per million tokens. So the headline commercial story did not change. The operational story did.
First, the capability emphasis moved further toward long-running coding and agentic work. Anthropic's official 4.7 materials show better scores on the rows that matter most to teams using Opus as a coding operator rather than a pure chatbot: SWE-bench Pro, SWE-bench Verified, Terminal-Bench 2.0, and several reasoning and multimodal evaluations. That does not mean every workflow will feel better instantly, but it does mean the default upgrade case is grounded in more than marketing language.
Second, Anthropic made the migration contract more explicit. The 4.7 migration guide says the same input can map to roughly 1.0x-1.35x more tokens depending on content type. It also says 4.7 tends to follow instructions more literally, which is a polite way of saying that some prompts or harnesses that "worked fine" on 4.6 may reveal assumptions you were getting away with.
Third, 4.7 adds more leverage for teams that actually want a more deliberate reasoning workflow. Anthropic's current 4.7 docs introduce xhigh effort and task budgets in beta, alongside better high-resolution image handling and 1:1 coordinate mapping for vision-heavy work. Those are not reasons to rewrite your whole stack, but they are reasons the upgrade matters more for serious coding and operator-style workflows than for casual chat use.
What did not change is just as important. This is still not a brand-new pricing tier, not a fundamentally different Anthropic product family, and not proof that every 4.6 deployment should be retired on sight. The upgrade is meaningful, but it is still an upgrade decision, not a product reset.
Which Benchmark Changes Matter and Which Do Not
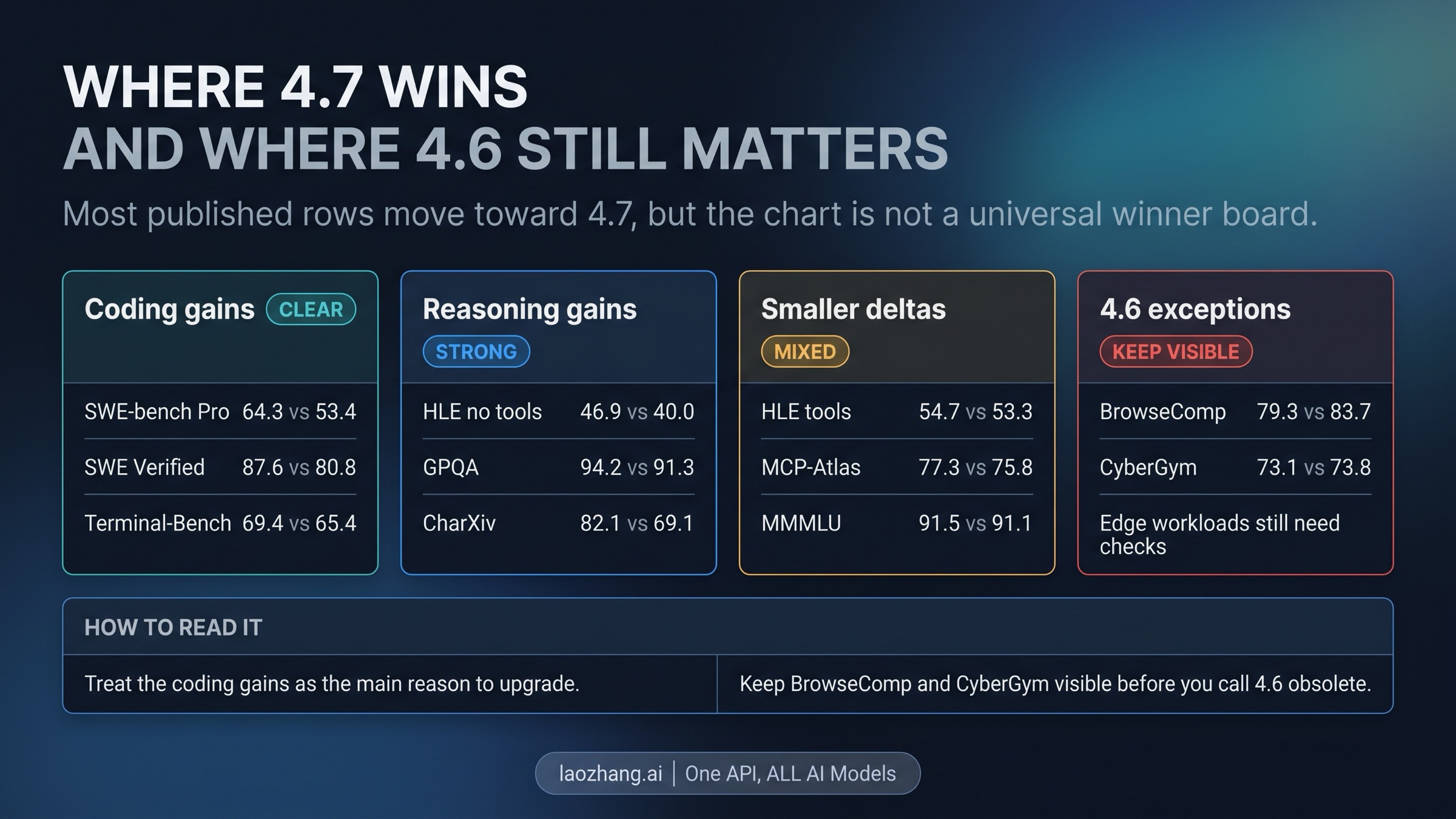
The benchmark story supports a 4.7-first default, but only if you read the chart like an operator instead of a fan account.
The most decision-relevant gains are the coding rows. Anthropic's published chart puts Opus 4.7 at 64.3% on SWE-bench Pro versus 53.4% for 4.6, 87.6% versus 80.8% on SWE-bench Verified, and 69.4% versus 65.4% on Terminal-Bench 2.0. If your team uses Opus for code generation, debugging, repo-wide edits, or long agent loops, those are the rows that justify moving the default.
The reasoning story also tilts toward 4.7, but with a different implication. Humanitys Last Exam without tools moves from 40.0% to 46.9%, GPQA Diamond moves from 91.3% to 94.2%, and CharXiv jumps from 69.1% to 82.1% without tools. Those numbers suggest a model that is not just marginally better on coding, but more reliable when the work requires harder synthesis and interpretation. That matters if your coding workflow regularly mixes code changes with long explanations, document reading, or multimodal review.
At the same time, the official chart is not a permission slip to declare 4.6 dead. BrowseComp still favors 4.6 at 83.7% versus 79.3%, and CyberGym slightly favors 4.6 at 73.8% versus 73.1%. Those are not big enough deltas to erase the broader 4.7 story, but they are big enough to matter if your own workload looks closer to those eval shapes than to SWE-bench.
That is the key distinction most launch-week comparison posts miss. The official results say "4.7 should usually become the new default." They do not say "4.6 is useless now." If your team has a narrow workflow that behaves more like the exception rows, keep 4.6 alive as the control route until you have your own evidence.
Same List Price, Different Real Cost

If you remember only one operational caveat from this page, make it this one: unchanged list pricing does not mean unchanged spend.
At the catalog level, the comparison is easy. Claude Opus 4.7 and Claude Opus 4.6 both sit at $5 input and $25 output per million tokens. If you stop there, the upgrade looks financially neutral.
The migration guide is why you should not stop there. Anthropic says the same input can map to roughly 1.0x-1.35x more tokens on 4.7 depending on content type. That is not a universal surcharge, and it should not be turned into a sloppy headline like "4.7 costs 35% more." But it does mean the real cost question lives in your workload, not on the pricing page.
There is a second layer on top of token mapping: effort behavior. Anthropic's newer 4.7 controls, including xhigh effort and task budgets, are useful precisely because 4.7 is meant for harder operator workflows. But if you raise effort defaults or let the model think longer across multi-step tasks, the invoice follows the behavior you actually run, not the headline rate you remember from launch day.
That is why the upgrade decision should start with measurement, not with intuition. The clean operator sequence is:
- Retest a real set of 4.6 tasks on 4.7 with the same prompts and the same harness.
- Compare token counts and effort defaults on those exact tasks.
- Set new budget expectations before you make 4.7 the default everywhere.
If the results stay close, great. If they drift, you still may prefer 4.7 because the quality gains are worth it. The point is to make that trade with your own workload in view rather than pretend a list-price tie answers the budget question.
How to Migrate Without Breaking a Working Setup

The safest migration is not "change the model ID and hope." It is "keep a control route, retest behavior, then flip defaults by workload."
1. Keep a Real 4.6 Control Set
Before you switch anything, save a small set of 4.6 tasks that represent the work you actually care about: one coding-heavy task, one long-context task, one output-format-sensitive task, and one budget-sensitive task. The point is not to rebuild Anthropic's benchmark suite. The point is to keep one honest control set so you can tell whether 4.7 changed quality, cost, or output shape in ways that matter to you.
2. Retest Prompt and Harness Behavior
Anthropic explicitly says 4.7 follows instructions more literally. In practice, that means prompts that relied on 4.6 being forgiving may now expose weak assumptions. If you have structured outputs, tool calls, or multi-step system prompts, do not assume "same prompt, same behavior." Retest the exact routes that already sit near your failure boundary.
If a migration exposes a concrete formatting or prefill problem rather than a general quality shift, take the narrow fix instead of blaming the whole model. Our Claude Opus prefill error fix is the right follow-up when the break is about request shape or prompt plumbing rather than model quality.
3. Re-Measure Spend, Not Just Output Quality
A migration that improves output but quietly blows up token counts is still a migration problem. Compare token usage on the same tasks, and do it before you normalize new defaults across Claude Code, API jobs, or internal automation. If you use higher effort levels or long agent loops, watch total task cost rather than per-call price in isolation.
4. Flip Workloads in Stages
The best rollout order is not "all routes at once." Move agent-heavy coding and higher-value reasoning workloads first, because that is where 4.7's published gains matter most. Hold edge cases longer. Replace defaults only after prompt behavior, output format, and spend all look stable enough to trust.
That staged approach is also what keeps Opus 4.6 useful. Its job is no longer "best default." Its job is "clean control route during migration." That is still a real job.
Who Should Switch Now, Who Should Stage, and Who Should Keep 4.6
The simplest way to end this comparison is to turn the whole thing back into route choices.
Switch Now
Switch now if your main use case is hard coding, repo-scale edits, agent loops, or vision-heavy debugging and you can retest prompts without much organizational drama. The published coding gains are strong enough that waiting usually costs more in lost quality than it saves in migration caution.
Stage Carefully
Stage carefully if your prompt stack is tightly tuned, your cost forecasting is rigid, or your downstream systems depend on very stable output behavior. In that case, 4.7 may still be the right destination, but not as a blind default swap. The value comes from controlling the rollout, not from pretending the rollout risk is zero.
If your team is also reopening the broader coding-model question, not just the Anthropic family question, our Claude Opus 4.6 vs GPT-5.3 Codex comparison is the better next page.
Keep 4.6 as a Baseline
Keep 4.6 as a baseline if you need a stable control route during migration, if your workload resembles the small set of exception rows more than the coding-heavy gains, or if your organization simply cannot afford a noisy rollout this week. That does not make 4.6 the better long-term default. It makes it the right short-term baseline.
And if your real question is no longer "4.7 or 4.6?" but "should I stay on today's default or start tracking the next future-tier signal?", the better adjacent route is Claude Capybara vs Opus 4.6. If you are reopening the broader outside-the-Claude-family choice after this upgrade decision, go next to Claude Opus 4.6 vs Grok 4.
FAQ
Is Claude Opus 4.7 actually more expensive in practice?
It can be. The official list price stayed at $5/$25 per million tokens, but Anthropic's migration guide says the same input can map to roughly 1.0x-1.35x more tokens on 4.7 depending on content type. Real spend depends on your workload and effort defaults, not just the pricing page.
Does Claude Opus 4.6 still win anywhere?
Yes. Anthropic's published chart still shows 4.6 ahead on BrowseComp and CyberGym. Those exceptions are not enough to overturn the broader 4.7 default story, but they are enough to justify keeping 4.6 as a control route when your workload looks similar.
Do I need to rewrite prompts to move from 4.6 to 4.7?
Not always, but you should expect to retest them. Anthropic says 4.7 follows instructions more literally, so prompts or harness assumptions that felt stable on 4.6 may need adjustment on 4.7.
Is Claude Opus 4.6 still available?
As of April 17, 2026, Anthropic still documents Claude Opus 4.6 in its current model and migration materials, which is why it remains a valid baseline during rollout. Treat it as a control route rather than as the long-term default unless your own evaluation proves otherwise.
Should I change Claude Code defaults immediately?
Only if your agent-heavy workflows are clearly better on 4.7 and your cost profile stays acceptable. For many teams, the better move is to switch the highest-value coding routes first, keep 4.6 pinned as the control route, and replace defaults only after prompt behavior and spend both look stable.
Claude Opus 4.7 deserves to be the new default more often than not. But the real upgrade threshold is not "same price and better benchmarks." It is whether your own workflow gains enough quality to justify the migration behavior, token drift, and rollout work that come with the change. For most serious coding teams, that answer will be yes. The smart version of yes is still a staged one.