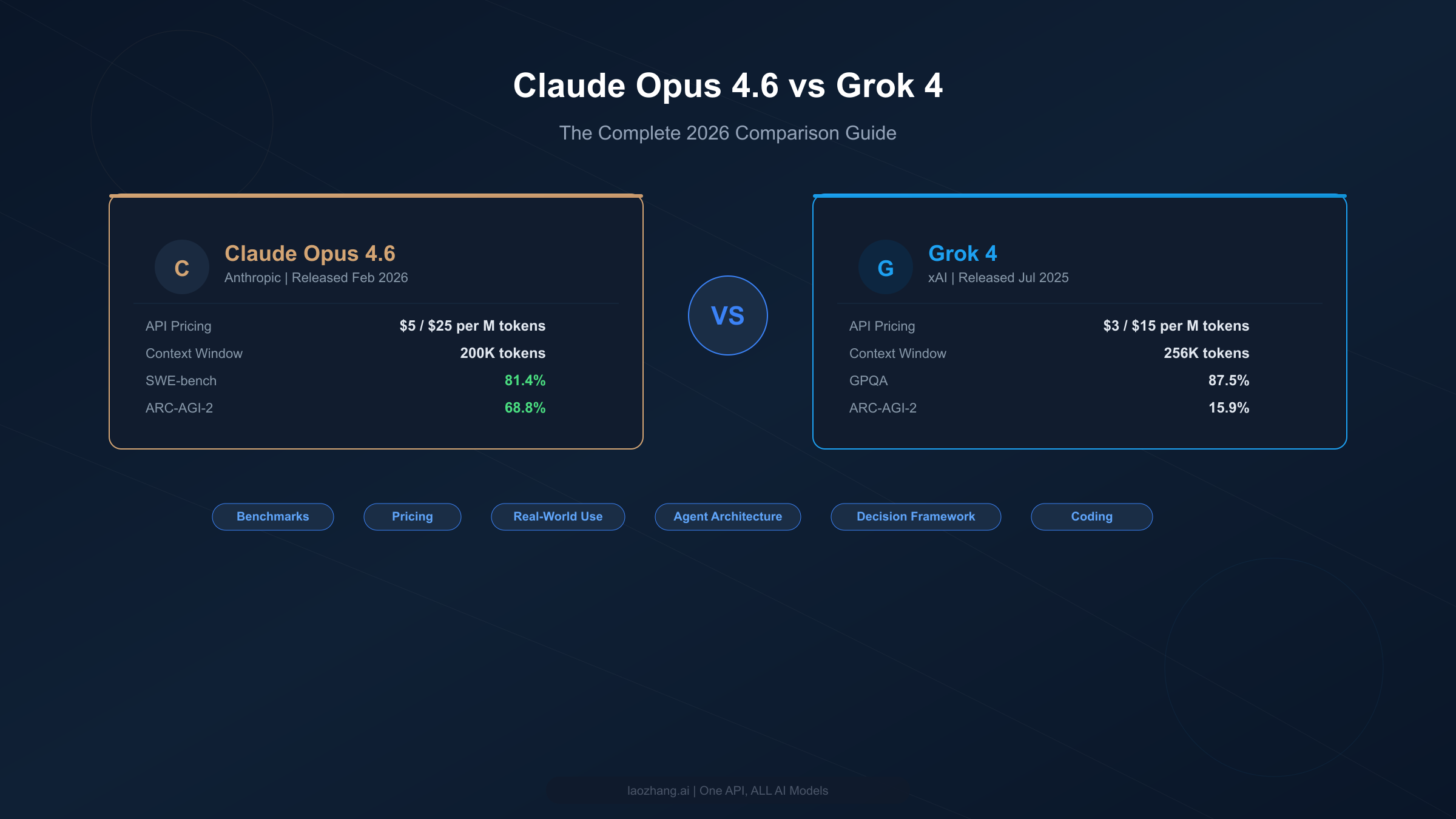
Claude Opus 4.6 outperforms Grok 4 on most benchmarks — including SWE-bench (81.4% vs comparable), ARC-AGI-2 (68.8% vs 15.9%), and reasoning tasks — but costs 67% more at $5/$25 per million tokens compared to Grok 4's $3/$15. For budget-conscious developers, Grok 4 Fast variants offer API access at just $0.20/$0.50 per million tokens with a 2M-token context window, making them among the most cost-effective frontier model options available in 2026.
TL;DR — Quick Comparison Table
Choosing between Claude Opus 4.6 and Grok 4 ultimately comes down to what you prioritize: raw coding and reasoning performance, or cost-efficiency with strong mathematical capabilities. Both models represent the frontier of AI capability in 2026, but they serve distinctly different audiences and use cases. The table below gives you a snapshot of how they compare across the dimensions that matter most, from API pricing to benchmark performance and ecosystem maturity. Use this as your starting point, then dive into the sections that match your specific needs.
| Feature | Claude Opus 4.6 | Grok 4 | Winner |
|---|---|---|---|
| API Input Price | $5.00/M tokens | $3.00/M tokens | Grok 4 |
| API Output Price | $25.00/M tokens | $15.00/M tokens | Grok 4 |
| Context Window | 200K tokens | 256K tokens | Grok 4 |
| SWE-bench | 81.4% | ~72% (est.) | Claude |
| ARC-AGI-2 | 68.8% | 15.9% | Claude |
| GPQA | 84.0% | 87.5% | Grok 4 |
| Math Index | ~88% | 92.7% | Grok 4 |
| Speed | ~80 tok/s | 40.6 tok/s | Claude |
| Coding CLI | Claude Code (native) | None | Claude |
| Multi-Agent | Agent Teams (API) | 4.20 Beta (consumer) | Claude |
| Consumer Sub | $20/mo (Pro) | $30/mo (SuperGrok) | Claude |
| Budget API | Haiku 4.5 ($1/$5) | Fast ($0.20/$0.50) | Grok 4 |
The pattern is clear: Claude dominates software engineering and reasoning benchmarks, while Grok offers better pricing and stronger mathematical performance. But the real story is more nuanced than any table can show — particularly when you factor in the dramatically different approaches each company takes to agent architecture and developer tooling, which we'll explore in detail below. One critical caveat about the "Budget API" row: Grok 4 Fast isn't just a cheaper version of Grok 4 — it's a fundamentally different model with a massive 2M-token context window that makes it suitable for entirely different use cases than the flagship Grok 4. Similarly, Claude Haiku 4.5 makes different quality-speed tradeoffs than Opus. Comparing budget tiers against each other is useful for cost planning, but they shouldn't be treated as direct substitutes for their flagship counterparts in performance-critical applications.
Understanding the Model Landscape in 2026
Before comparing Claude Opus 4.6 and Grok 4 directly, it's essential to understand where each model sits within its respective family. This is particularly important for the Grok side, where the model lineup has become genuinely confusing — even for experienced developers. xAI has released multiple variants across different access tiers, and understanding which "Grok 4" you're actually evaluating against Claude makes a significant difference in any fair comparison.
Claude Opus 4.6 sits at the top of Anthropic's model hierarchy as of March 2026. Released on February 5, 2026, it represents Anthropic's most capable reasoning model, positioned above Claude Sonnet 4.6 (the balanced option at $3/$15 per million tokens) and Claude Haiku 4.5 (the speed-optimized option at $1/$5 per million tokens). The naming is straightforward: Opus for maximum capability, Sonnet for the best balance of performance and cost, and Haiku for speed and efficiency. When people discuss "Claude" in the context of frontier AI capabilities, they're almost always referring to the Opus tier. For a deeper look at how Opus compares to Sonnet within the Claude family, see our Claude Opus vs Sonnet comparison.
The Grok Model Family (Essential Context)
The Grok landscape is where most confusion arises, and no other comparison article in the current TOP 10 search results adequately explains this. Here's the complete breakdown of the Grok 4 family as of March 2026 (verified from docs.x.ai):
Grok 4 (grok-4-0709) is the flagship model, released July 9, 2025. It features always-on reasoning (there's no non-reasoning mode), a 256K context window, and pricing at $3.00 input / $15.00 output per million tokens. This is the model that competes directly with Claude Opus 4.6. One important distinction: Grok 4's reasoning is always active, meaning you're always paying for the deeper thinking process. Claude Opus 4.6, by contrast, offers extended thinking as an optional feature, giving developers more granular cost control.
Grok 4 Fast variants include both reasoning and non-reasoning modes (grok-4-fast-reasoning and grok-4-fast-non-reasoning), plus their 4.1 counterparts. These share a massive 2M-token context window and cost just $0.20/$0.50 per million tokens — making them 15-25x cheaper than Claude Opus 4.6. They sacrifice some capability for dramatic cost savings, but for many applications, the performance is more than adequate. The 2M context window is particularly valuable for processing entire codebases or long documents that would require chunking with other models.
Grok 4.20 Beta is the consumer-facing multi-agent system, launched February 17, 2026. Available through SuperGrok ($30/month) and SuperGrok Heavy ($300/month), it features four specialized agents — Captain, Research, Logic, and Creative — that work together on complex tasks. This is xAI's answer to Claude's Agent Teams, but with a fundamentally different philosophy that we'll explore in the architecture section. Notably, Grok 4.20 Beta has no API access yet, making it purely a consumer product for now.
Why This Matters for Your Comparison
When you see benchmark comparisons online, most auto-generated comparison tools pit "Claude Opus 4.6" against "Grok 4" without specifying which Grok variant or whether they're comparing API capabilities, consumer features, or raw model performance. A fair comparison should match Claude Opus 4.6 against the standard Grok 4 API for benchmark and pricing analysis, while acknowledging the Fast variants as compelling budget alternatives and the 4.20 Beta as an interesting consumer competitor to Claude Pro.
Pricing Breakdown — Every Dollar Counts
Understanding the true cost of these models requires looking beyond per-token pricing to examine what you'll actually spend in real-world usage scenarios. The headline numbers — $5/$25 for Claude versus $3/$15 for Grok — only tell part of the story. The way each model handles reasoning tokens, caching, and tiered access creates significant cost differences that depend entirely on your specific use case. For a comprehensive look at Claude's pricing across all tiers, check our detailed Claude Opus 4.6 pricing guide.
API Pricing: The Complete Picture
The core API pricing comparison reveals Grok 4's 40% cost advantage on both input and output tokens. But several factors complicate this simple math. Claude Opus 4.6 charges $5.00 per million input tokens and $25.00 per million output tokens (verified from platform.claude.com, March 2026). Grok 4 charges $3.00 input and $15.00 output per million tokens, with cached input tokens available at $0.75 per million (docs.x.ai, March 2026). Grok 4's prompt caching discount to $0.75 per million tokens is more aggressive than Claude's caching tier, which can significantly reduce costs for applications that reuse system prompts or reference documents across multiple API calls.
The budget tier comparison is where the gap becomes dramatic. Anthropic's most affordable option is Claude Haiku 4.5 at $1.00/$5.00 per million tokens — a solid value proposition but still 5x more expensive than Grok 4 Fast's $0.20/$0.50 pricing. For high-volume applications where you need frontier-adjacent capability without frontier pricing, the Grok 4 Fast variants represent some of the best value in the market. They also offer a 2M-token context window, compared to Haiku's more modest context.
Consumer Subscription Pricing
For users who prefer subscription access over API integration, Claude Pro costs $20/month, providing access to Opus 4.6 with generous usage limits. SuperGrok, xAI's comparable offering, costs $30/month and includes access to Grok 4 plus the 4.20 Beta multi-agent system. SuperGrok Heavy at $300/month targets power users and enterprises needing higher rate limits and priority access. From a pure subscription value perspective, Claude Pro offers frontier-tier access at a lower monthly cost, though SuperGrok bundles the multi-agent capability that Claude doesn't include in its subscription tier.
Cost-Per-Task Analysis: What You'll Actually Pay
Raw token pricing becomes meaningful only when mapped to real tasks. Here's what five common developer tasks actually cost with each model, based on typical token consumption patterns. A standard code review of a 500-line pull request (approximately 4,000 input tokens and 2,000 output tokens) costs roughly $0.07 with Claude Opus 4.6 versus $0.04 with Grok 4 — a difference of about 3 cents that barely registers at individual task level. Document analysis of a 50-page technical document (approximately 25,000 input tokens, 5,000 output tokens) runs about $0.25 with Claude and $0.15 with Grok. A chatbot conversation averaging 10 turns costs approximately $0.05 with Claude versus $0.03 with Grok. Bug debugging sessions with extended context typically cost $0.50-$1.00 with Claude and $0.30-$0.60 with Grok. Full codebase analysis using the maximum context window costs approximately $1.00 with Claude (200K tokens) versus $0.77 with Grok (256K tokens).
The cost difference becomes meaningful at scale. A development team making 1,000 API calls per day would save approximately $30-$50 daily by choosing Grok 4 over Claude Opus 4.6 — roughly $900-$1,500 per month. However, if Grok 4 Fast is sufficient for a portion of those calls, the savings compound dramatically. Using Grok 4 Fast for 80% of tasks and reserving Grok 4 for complex reasoning could reduce the monthly bill to under $200, compared to $1,500+ for all-Claude-Opus usage.
It's worth noting that Anthropic also offers tiered pricing within the Claude family. A practical cost optimization strategy for Claude users is to route simple tasks to Claude Haiku 4.5 ($1/$5 per million tokens), medium-complexity tasks to Sonnet 4.6 ($3/$15), and reserve Opus 4.6 for tasks that genuinely need frontier-level reasoning. This approach can reduce Claude-family costs by 60-70% compared to using Opus for everything. The same principle applies on the Grok side: use Fast variants as your default and escalate to standard Grok 4 only when needed.
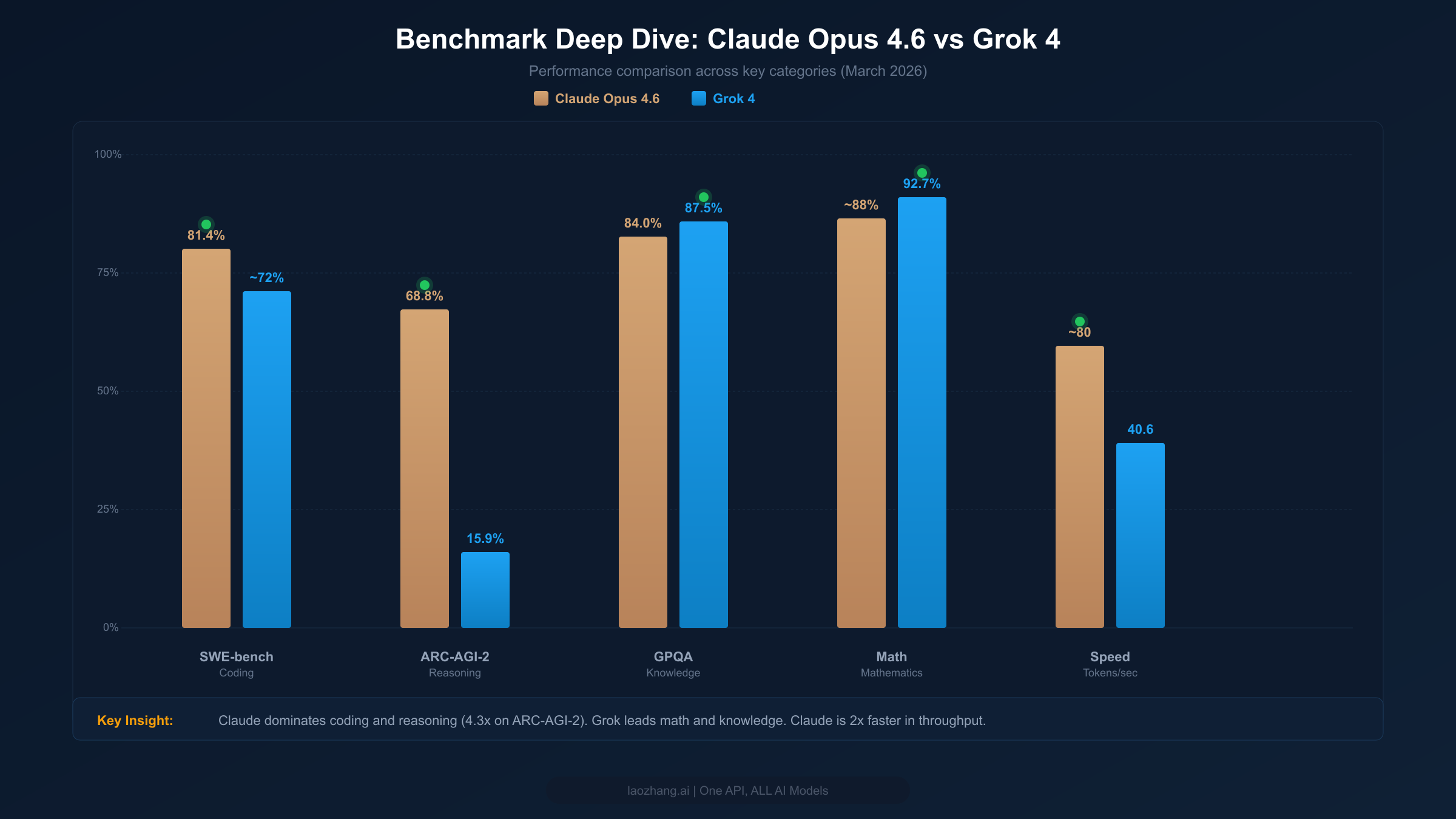
Benchmark Deep Dive — What the Numbers Actually Mean
Benchmark scores are everywhere in AI model comparisons, but raw numbers without context are worse than useless — they're misleading. A 5-percentage-point difference on GPQA has completely different practical implications than the same gap on SWE-bench. This section breaks down what each major benchmark actually measures, what the scores tell us about real-world capability, and where each model genuinely excels versus where the differences are negligible.
Coding Benchmarks: Where Claude Leads
SWE-bench Verified is the gold standard for evaluating a model's ability to solve real software engineering tasks — fixing actual bugs from popular open-source Python repositories. Claude Opus 4.6 scores 81.4% on this benchmark (Anthropic official announcement, February 2026), which represents a significant lead over Grok 4's estimated ~72%. This isn't a trivial gap: it means Claude successfully resolves roughly one in ten additional real-world coding tasks that Grok fails on. For development teams evaluating these models for code assistance, this difference translates directly into fewer manual interventions and faster iteration cycles.
Terminal-Bench measures agentic coding capability — how well a model can operate autonomously in a terminal environment, executing commands, interpreting outputs, and iterating on solutions. Claude Opus 4.6 scores 43.2% here, a benchmark where Grok 4 hasn't published official results. This metric matters increasingly as developers adopt agentic coding workflows where the AI acts as a semi-autonomous pair programmer rather than just a code completion tool. The absence of Grok 4 scores on Terminal-Bench is itself telling — xAI has not positioned Grok as an agentic coding model, while Anthropic has built an entire product (Claude Code) around this capability. For teams considering which model to use for autonomous development tasks, this difference in strategic focus matters as much as the benchmark numbers themselves.
Reasoning Benchmarks: The Dramatic Gap
ARC-AGI-2 is designed to test novel reasoning ability — the kind of fluid intelligence that requires genuine understanding rather than pattern matching. The gap here is extraordinary: Claude Opus 4.6 scores 68.8% compared to Grok 4's 15.9%. This 4.3x difference is the single largest performance gap between these two models on any major benchmark. What does it mean practically? ARC-AGI-2 tasks require the model to identify abstract patterns and apply them in novel contexts — precisely the kind of reasoning that matters for complex software architecture decisions, creative problem-solving, and tasks where the solution path isn't well-defined. If your work regularly involves novel reasoning challenges, this benchmark gap is highly predictive of real-world performance differences.
Knowledge and Math: Where Grok Excels
GPQA (Graduate-level Professional Quality Assurance) tests expert-level knowledge across multiple scientific domains. Grok 4 leads here with 87.5% versus Claude's 84.0% — a meaningful but not dramatic advantage. This suggests Grok has a slight edge in tasks requiring deep domain knowledge in science, medicine, and technical fields. The Math Index tells a similar story: Grok 4's 92.7% versus Claude's approximately 88% indicates stronger mathematical reasoning. For applications heavily weighted toward mathematical computation, statistical analysis, or scientific reasoning, Grok's advantage is real and consistent across multiple math-focused benchmarks.
Speed and Latency: The Production Factor
For production applications, raw benchmark scores matter less than the combination of quality and speed. Claude Opus 4.6 generates approximately 80 tokens per second, roughly double Grok 4's 40.6 tokens per second (pricepertoken.com, March 2026). The time-to-first-token (TTFT) difference is even more striking: Claude's response begins in approximately 1.5 seconds, compared to Grok 4's 10.79 seconds. That nearly 10-second difference in TTFT is critical for interactive applications — chatbots, coding assistants, and real-time analysis tools where users expect immediate responsiveness. Grok 4's always-on reasoning contributes to its higher latency, since every request goes through the deep reasoning pipeline regardless of whether the task requires it.
Coding and Development: Where Claude Excels

For developers evaluating these models as coding assistants, the comparison extends well beyond benchmark scores into the ecosystem of tools, integrations, and developer experience that each platform provides. This is where the gap between Claude and Grok becomes most pronounced — not because Grok 4 is a poor coding model, but because Anthropic has invested heavily in building a comprehensive developer workflow around Claude.
Claude Code is Anthropic's native command-line tool that gives Claude direct access to your terminal, file system, and development environment. It's not just an API wrapper — it's an agentic coding system that can read your codebase, write and edit files, run tests, manage git operations, and iterate on solutions autonomously. No equivalent tool exists in the Grok ecosystem. This single product creates a category of developer experience that Grok simply cannot match with API access alone. For teams already using Claude Code, the switching cost to Grok includes losing this entire agentic coding workflow.
Agent Teams, introduced with Claude 4.6, enable developers to orchestrate multiple Claude instances working in parallel on different aspects of a task — one agent handles code writing, another manages testing, a third reviews for quality. This multi-agent capability operates through the API with fine-grained permission controls and supports isolated git worktrees per agent, preventing interference between parallel workstreams. For a deep dive into these capabilities, see our Claude Agent Teams guide.
Grok 4's coding capability, while not as extensively benchmarked, brings its own advantages. The always-on reasoning means every coding request gets deep analysis by default, which can be beneficial for complex algorithmic problems and mathematical code where Grok's 92.7% Math Index advantage translates into better solutions. The 2M context window available through Grok 4 Fast variants is genuinely useful for large-scale code analysis — processing entire repositories or lengthy dependency chains that would exceed Claude's 200K limit. Additionally, Grok 4 Fast's $0.20/$0.50 pricing makes it economically viable to run extensive automated code analysis pipelines that would be prohibitively expensive with Claude Opus 4.6.
The practical recommendation for most development teams is to consider a multi-model approach. Use Claude Opus 4.6 (and Claude Code specifically) for interactive coding sessions, complex debugging, and tasks requiring agentic behavior. Reserve Grok 4 or Grok 4 Fast for batch processing, mathematical computation, and high-volume analysis tasks where cost efficiency matters more than peak coding performance. This blended approach captures the best capabilities of each model while managing costs effectively.
Agent Architecture — Two Different Philosophies
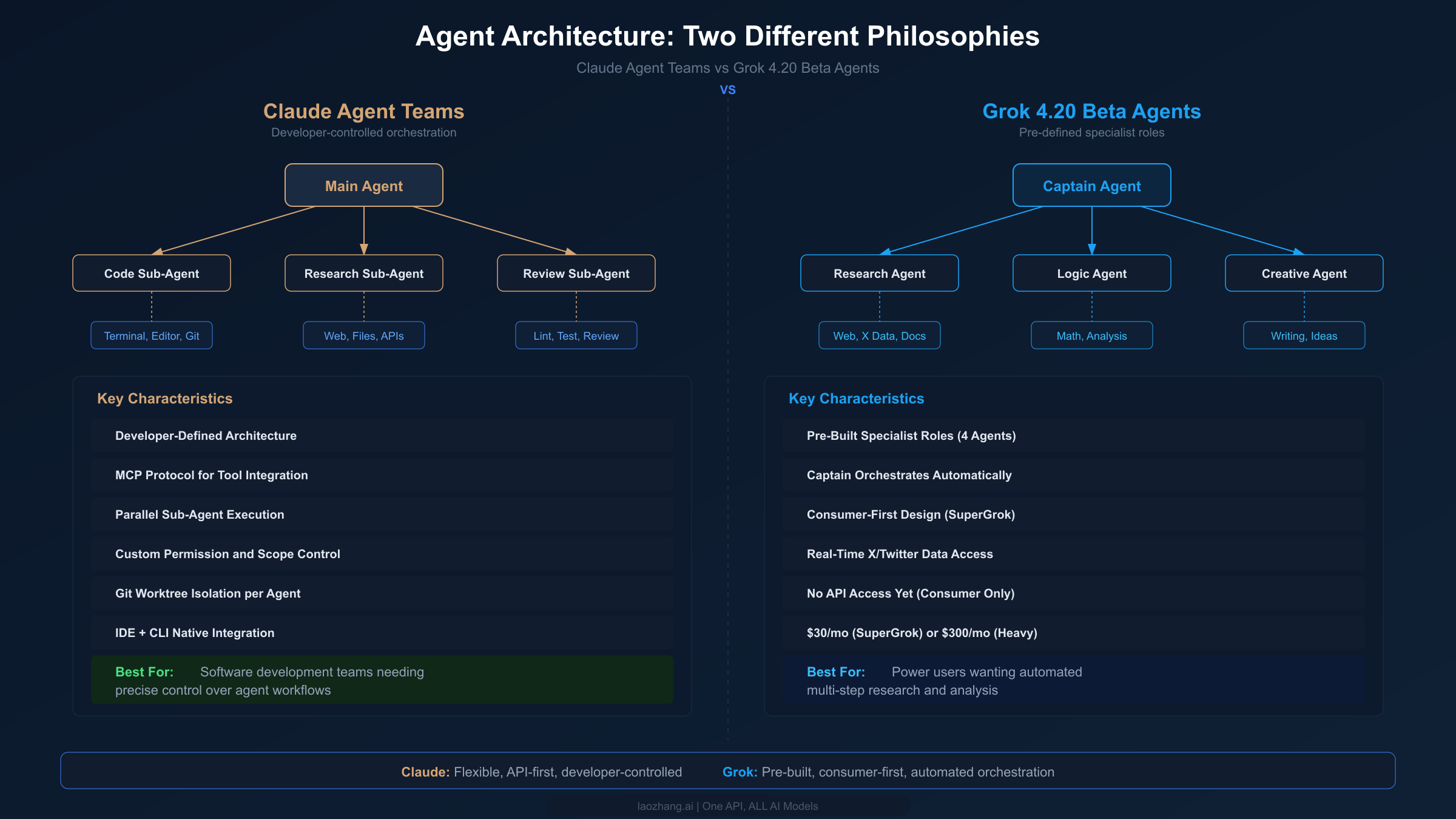
The most forward-looking comparison between Claude and Grok isn't about benchmark scores or pricing — it's about how each company envisions multi-agent AI systems. Both Anthropic and xAI have released multi-agent capabilities in early 2026, but their approaches reveal fundamentally different philosophies about who should control the orchestration, how agents communicate, and what problems multi-agent systems should solve. Understanding these architectural differences is critical for anyone planning to build on these platforms long-term.
Claude Agent Teams: Developer-Controlled Orchestration
Claude's Agent Teams, launched as part of the Claude 4.6 release, follow a developer-first philosophy. The main agent (or "lead") can spawn sub-agents with specific instructions, tools, and permission scopes. Developers define the architecture — which agents exist, what tools each can access, and how they coordinate. The system operates entirely through the API, meaning you have full programmatic control over every aspect of the orchestration. Sub-agents can run in parallel, each in isolated git worktrees to prevent conflicts, and the main agent synthesizes their results. The Model Context Protocol (MCP) enables agents to integrate with external tools — databases, APIs, file systems, and IDEs — through a standardized interface. This composability means developers can build exactly the multi-agent workflow their use case requires, from simple two-agent code-and-review pipelines to complex five-agent systems handling different aspects of a large project.
The trade-off is complexity. Building an effective Agent Teams workflow requires understanding orchestration patterns, defining clear agent scopes, managing token budgets across parallel agents, and handling failure modes when sub-agents produce conflicting results. It's a powerful tool, but it demands developer investment to use effectively. The payoff comes in precision: well-designed Agent Teams workflows can dramatically outperform single-model interactions on complex tasks because each agent can be optimized for its specific role with appropriate context and tools.
Grok 4.20 Beta Agents: Pre-Built Specialist Roles
Grok's approach with the 4.20 Beta is consumer-first. Instead of requiring developers to design agent architectures, xAI provides four pre-built specialist agents — Captain, Research, Logic, and Creative — that automatically coordinate on complex tasks. The Captain agent serves as the orchestrator, routing subtasks to whichever specialist is best suited. Users don't need to understand multi-agent architecture; they simply submit a complex request and the system handles decomposition and coordination internally. This approach aligns with xAI's consumer-focused SuperGrok platform, where the goal is making advanced AI capabilities accessible without technical expertise. The Research agent has direct access to X/Twitter data, giving it real-time information capabilities that Claude's agents don't natively possess. The Logic agent handles mathematical and analytical tasks, leveraging Grok 4's strong math performance. The Creative agent focuses on content generation and ideation.
The trade-off is flexibility. You can't customize which agents participate, define new specialist roles, or control the orchestration logic. The system works well for general-purpose complex tasks but lacks the precision that developers need for specialized workflows. And critically, there's no API access yet — Grok 4.20 Beta agents are only available through the SuperGrok consumer interface, limiting their usefulness for production applications.
Which Architecture Wins?
For developers and engineering teams, Claude's Agent Teams is the clear winner in 2026 — it's available through the API, offers full customization, and integrates with existing development tools through MCP. For power users and researchers who want multi-agent capabilities without writing code, Grok 4.20 Beta provides an accessible, if less flexible, alternative. The real question is whether xAI will release API access for its multi-agent system, which would make this comparison much more competitive. Until then, any team needing programmatic multi-agent workflows has only one option: Claude.
Looking at the trajectory of both companies reveals important signals for long-term planning. Anthropic has systematically expanded Claude's developer ecosystem — from the initial API, to Claude Code, to Agent Teams, to MCP integrations — each building on the previous layer. This suggests continued investment in developer tooling that makes Claude increasingly sticky within engineering workflows. xAI's trajectory is more consumer-focused, with SuperGrok and the 4.20 Beta agent system prioritizing accessibility over programmability. Neither trajectory is inherently better, but they serve different audiences. If you're building products that depend on AI agent capabilities, Claude's developer-first approach offers more stability and composability. If you're creating consumer-facing AI experiences, Grok's pre-built agent system offers faster time-to-value without custom engineering.
Which Model Should You Choose?
Making the right choice between Claude Opus 4.6 and Grok 4 depends less on which model is "better" in absolute terms and more on which model best fits your specific use case, budget, and technical requirements. Based on our comprehensive analysis across benchmarks, pricing, coding capabilities, and architecture, here are six scenario-based recommendations designed to help you make a confident decision.
Scenario 1: Software Development Team (5-20 developers). Choose Claude Opus 4.6. The combination of superior SWE-bench performance (81.4%), Claude Code for agentic coding, Agent Teams for parallel workflows, and strong IDE integrations creates an ecosystem purpose-built for professional software development. The higher API cost ($5/$25 vs $3/$15) is offset by productivity gains — resolving one additional bug per day that Grok would miss easily covers the cost difference. Budget tip: use Claude Sonnet 4.6 ($3/$15) for routine tasks and reserve Opus for complex reasoning.
Scenario 2: Budget-Conscious Startup or Solo Developer. Choose Grok 4 Fast ($0.20/$0.50). At 25x cheaper than Claude Opus 4.6, Grok 4 Fast provides frontier-adjacent capability at a fraction of the cost. The 2M context window is a bonus for processing large codebases. For the 10-20% of tasks that need maximum capability, consider spot-using Claude Opus 4.6 or standard Grok 4 rather than paying for the premium tier on every request.
Scenario 3: Data Science and Mathematical Analysis. Choose Grok 4. Its 92.7% Math Index and 87.5% GPQA scores indicate stronger performance on mathematical reasoning and scientific knowledge tasks. The always-on reasoning mode, while adding latency, ensures deep analytical rigor on every request. For teams doing heavy statistical analysis, model training, or scientific computation, Grok's mathematical edge translates into tangible quality improvements.
Scenario 4: Enterprise with Multi-Agent Workflow Needs. Choose Claude Opus 4.6 with Agent Teams. As of March 2026, Claude is the only option with API-accessible multi-agent orchestration. If your enterprise roadmap includes building autonomous workflows, automated code review pipelines, or complex multi-step analysis systems, Claude's Agent Teams provides the programmable foundation you need. Grok 4.20 Beta's multi-agent system remains consumer-only.
Scenario 5: Real-Time Applications and Chatbots. Choose Claude Opus 4.6. The 2x speed advantage (~80 tok/s vs 40.6 tok/s) and dramatically faster TTFT (~1.5s vs 10.79s) make Claude the only viable option for applications where response latency matters. A 10-second wait for the first token is unacceptable in most interactive use cases.
Scenario 6: High-Volume Processing on a Tight Budget. Choose a mixed approach with Grok 4 Fast as the primary model. Route 80% of requests through Grok 4 Fast ($0.20/$0.50), escalate complex tasks to standard Grok 4 ($3/$15), and use Claude Opus 4.6 only for tasks requiring maximum coding or reasoning capability. This tiered approach can reduce costs by 85-95% compared to all-Claude-Opus usage while maintaining high quality for the tasks that matter most.
The common thread across all six scenarios is that the best strategy is rarely "use one model for everything." The frontier AI landscape in 2026 rewards intelligent routing — matching model capabilities and costs to specific task requirements. Even within a single product, you might use Claude for user-facing coding assistance while running Grok 4 Fast for background document processing and data extraction. The days of committing exclusively to a single AI provider are over; the competitive advantage goes to teams that leverage the right model for each job. Implementing this multi-model strategy does require additional engineering effort for model routing logic and managing multiple API relationships, but the cost savings and quality improvements justify the investment for any team making more than a few hundred API calls per day.
Getting Started and Optimizing Costs
Both Claude and Grok offer straightforward API access, but optimizing your implementation for cost and performance requires understanding each platform's specific features. Here's a practical guide to getting started with either model and extracting maximum value from your API budget.
Getting started with Claude Opus 4.6 requires an Anthropic API key from console.anthropic.com. The API follows a standard REST pattern with SDKs available in Python and TypeScript. The setup process is straightforward: create an account, generate an API key, and make your first request within minutes. Enable extended thinking only for tasks that require deep reasoning — leaving it on by default inflates costs without proportional quality gains for simpler tasks. Use prompt caching by including a cache_control block in your system prompts to reduce input token costs on repeated calls. For coding workflows, install Claude Code (npm install -g @anthropic-ai/claude-code) to get the full agentic development experience without writing custom API integrations. Claude Code supports direct terminal access, file editing, git operations, and multi-agent orchestration right from your command line, making it the fastest path from "I have an API key" to "I have an AI-powered development workflow."
Getting started with Grok 4 requires an xAI API key from console.x.ai. The API is OpenAI-compatible, making migration straightforward for teams already using the OpenAI SDK format. Leverage Grok 4's cached input pricing ($0.75/M vs $3.00/M standard) aggressively — any system prompt or reference document that's reused across calls should be cached. For budget-sensitive applications, start with Grok 4 Fast and only escalate to standard Grok 4 when the task complexity demands it. The 2M context window on Fast variants means you rarely need the full Grok 4 for document processing tasks.
Cost optimization strategies that work across both models include implementing intelligent routing that analyzes task complexity before selecting a model tier, batching similar requests to maximize cache utilization, and setting token budget caps per request to prevent runaway costs on tasks that generate excessive output. A well-designed routing system might use a lightweight classifier (or even a rule-based heuristic) to determine whether each incoming request needs frontier-level capability or whether a budget model will suffice. This single optimization can reduce total API spend by 50-70% for most applications.
For a broader perspective on how these models compare to other frontier options including GPT-4o and Gemini, see our comprehensive AI API comparison guide. The AI model landscape in 2026 rewards flexibility — the teams that perform best are those that match models to tasks rather than committing exclusively to a single provider. Both Claude Opus 4.6 and Grok 4 are excellent models, and the ideal strategy for most organizations is using both where each excels.
Frequently Asked Questions
Is Claude Opus 4.6 better than Grok 4?
Claude Opus 4.6 outperforms Grok 4 on coding benchmarks (81.4% vs ~72% SWE-bench), reasoning tasks (68.8% vs 15.9% ARC-AGI-2), and response speed (~80 vs 40.6 tokens/second). However, Grok 4 leads in mathematical reasoning (92.7% Math Index) and knowledge tasks (87.5% GPQA), while costing 40% less. Neither model is universally "better" — the right choice depends on whether your primary use case is coding/reasoning (Claude) or math/knowledge at lower cost (Grok).
How much cheaper is Grok 4 than Claude Opus 4.6?
Grok 4's API pricing is $3/$15 per million tokens compared to Claude's $5/$25, making it 40% cheaper on input and output. The budget Grok 4 Fast variants at $0.20/$0.50 per million tokens are 25x cheaper than Claude Opus 4.6, making them among the most affordable frontier-adjacent models available. Grok also offers cached input pricing at $0.75 per million tokens.
Can I use both Claude and Grok through the same API?
Yes.
What is Grok 4.20 Beta and how does it compare to Claude Agent Teams?
Grok 4.20 Beta is xAI's consumer multi-agent system featuring four specialist agents (Captain, Research, Logic, Creative) available through SuperGrok ($30/month). Claude Agent Teams is Anthropic's developer-focused multi-agent framework available through the API. The key difference: Claude's system offers full programmatic control and customization, while Grok's is pre-built and consumer-only with no API access yet.
Which model is faster for production applications?
Claude Opus 4.6 is significantly faster: approximately 80 tokens/second versus Grok 4's 40.6, with a time-to-first-token of ~1.5 seconds versus Grok 4's 10.79 seconds. For interactive applications and chatbots, Claude's speed advantage is decisive. Grok 4's higher latency results from its always-on reasoning mode, which processes every request through deep reasoning regardless of complexity.