
Start with GPT-5.3-Codex if the first thing you want is a cheaper coding-agent test in terminal-heavy work. Start with Claude Opus 4.6 if the expensive part is a long task, a very large repo context, or a weak first attempt that creates a lot of cleanup. That is the most practical answer on April 3, 2026.
One clarification matters before any table. GPT-5.3-Codex is still a real current OpenAI model, but it is no longer a safe shorthand for the entire Codex product. OpenAI introduced GPT-5.4 into Codex on March 5, 2026, and on March 17, 2026 described a setup where a larger model such as GPT-5.4 handles planning and final judgment while GPT-5.4 mini takes narrower subagent work. So this article compares Claude Opus 4.6 and GPT-5.3-Codex as models, not the whole current Codex product. If your real question is product choice, read our OpenAI Codex March 2026 guide or the broader Claude Code vs Codex comparison.
| If your bottleneck looks like this... | Test first | Why |
|---|---|---|
| Cheap terminal and computer-use coding loops | GPT-5.3-Codex | Lower official API price and a clearer published first-party benchmark case |
| Repository-scale long-running execution | Claude Opus 4.6 | 1M context, 128k output, and a stronger case when retries are expensive |
| Your stack has both stages | Use both | Let GPT-5.3-Codex handle the cheaper first pass, then move to Opus 4.6 when context depth or cleanup risk rises |
Evidence note: this guide was verified against current official OpenAI and Anthropic model and product pages checked on April 3, 2026. Benchmark evidence is asymmetric: OpenAI publishes a richer launch appendix for GPT-5.3-Codex, while Anthropic publishes current public scores for Opus 4.6 on a smaller set of headline agent benchmarks. Read the table below as a decision guide, not as a perfectly matched laboratory scoreboard.
First, Define the Real Comparison
This comparison stays useful only if we keep the object of comparison tight. GPT-5.3-Codex launched on February 5, 2026, and OpenAI's current API model docs still list it as a live coding model with documented pricing, reasoning settings, endpoints, a 400,000-token context window, and 128,000 max output tokens. So the model name is real, current, and worth comparing directly to Claude Opus 4.6.
What changed is the surrounding product story. OpenAI's current model catalog now positions GPT-5.4 as the main family for agentic, coding, and professional work, and OpenAI's March 17, 2026 GPT-5.4 mini announcement explicitly describes a Codex setup where a larger model like GPT-5.4 handles planning, coordination, and final judgment while smaller models handle narrower support work. That is product guidance, not a statement that GPT-5.3-Codex stopped existing. But it does mean that many people who say "Codex" are no longer really asking a pure GPT-5.3-Codex question.
Why does that distinction matter? Because a model choice and a product choice solve different decisions. A model comparison should tell you which model to test first for coding work. A product comparison should tell you which toolchain and working style to adopt. Those are related, but they are not interchangeable. This page stays with the model question so it can answer a sharper one: which model should developers try first right now?
Fast Snapshot: Where the Measurable Split Really Lives

The first useful read is not "who wins more rows?" It is which failure profile each row points to. GPT-5.3-Codex is priced like a model you can evaluate aggressively. Claude Opus 4.6 is priced like a model that expects to save you from more expensive mistakes.
| Dimension | GPT-5.3-Codex | Claude Opus 4.6 | What the row means |
|---|---|---|---|
| Official API price | $1.75 input / $14 output per 1M tokens | $5 input / $25 output per 1M tokens | GPT-5.3-Codex is much easier to test in high-volume coding loops |
| Cached input | $0.175 per 1M tokens | Anthropic publishes standard pricing and cache behavior separately | OpenAI's pricing makes repeated evaluation loops cheaper |
| Context window | 400k | 1M | Opus can hold a much larger repo or spec set in one pass |
| Max output | 128k | 128k | Output size is not the main separator here |
| Public Terminal-Bench 2.0 score | 77.3 | 65.4 | OpenAI publishes the stronger first-party case for cheaper coding-agent evaluation |
| Public OSWorld score | 64.7 | 72.7 | Anthropic publishes the stronger public case for environment-heavy long-horizon execution |
That split already suggests the answer. GPT-5.3-Codex is easier to justify as the cheaper first test, especially when your immediate question is, "How far can I push a coding agent before I need premium pricing?" Claude Opus 4.6 is easier to justify when context depth and failure cost dominate the bill, because the model can keep much more state alive at once without sacrificing output headroom.
The trap is pretending these rows form one perfectly symmetrical benchmark story. They do not. OpenAI's headline numbers come from its February 5, 2026 launch appendix and were run with xhigh reasoning effort. Anthropic's current Opus 4.6 public case is narrower but still useful: its product and model pages emphasize 65.4% on Terminal-Bench 2.0, 72.7% on OSWorld, and public 1M context. That is enough to guide a first-model decision. It is not enough to support a fake "wins every coding benchmark" narrative for either side.
When GPT-5.3-Codex Should Get the First Test
Claim: GPT-5.3-Codex is the better first test when your near-term question is how much coding-agent capability you can buy at a lower price across repeated terminal or computer-use style loops.
Evidence: OpenAI's current model page prices GPT-5.3-Codex at $1.75 / $14 per million tokens, with $0.175 cached input, a 400k context window, 128k output, and adjustable reasoning effort. OpenAI's launch appendix also gives it the clearer published coding-benchmark case on the OpenAI side, including 77.3% on Terminal-Bench 2.0 and 64.7% on OSWorld-Verified.
Decision: If your team is still mapping the boundary of a coding agent and expects lots of iterations, retries, and evaluation runs, start with GPT-5.3-Codex.
That recommendation is less about leaderboard theater than about economics. A coding stack that spends its time in repeated terminal loops, patch attempts, tool calls, and self-correction burns money through repetition before it burns money through giant context. In that kind of system, GPT-5.3-Codex gives you a cheaper way to learn what your workload really demands. If the model fails, you have learned something without paying Opus rates on every pass. If it succeeds often enough, you may not need the premium route for large parts of the pipeline.
There is also a more specific reason to start here when the task is terminal-heavy. OpenAI's first-party public evidence is simply clearer on this dimension. You are not guessing from vague "best for coding" marketing copy. You have a current model contract, exact pricing, and a launch appendix that was explicitly framed around coding and environment-heavy benchmarks. For a first-pass evaluation program, that matters. It means the OpenAI side gives you a sharper public case for what the model is supposed to be good at.
The catch is equally important. GPT-5.3-Codex is not the whole current Codex product answer, and its public benchmark story should not be flattened into universal superiority. If your tasks start stretching far beyond a 400k context window, or if your human cleanup cost becomes the expensive part of the workflow, the cheaper first test can stop being the better test. This is why the cleanest use of GPT-5.3-Codex in 2026 is often as the first model to pressure-test a coding loop, not as the automatic permanent owner of every step.
When Claude Opus 4.6 Earns the Premium
Claim: Claude Opus 4.6 is the better first test when the real bottleneck is not token price but the cost of a weak first pass across long context, long-horizon orchestration, or large-output execution.
Evidence: Anthropic's current model docs list Opus 4.6 at $5 / $25 per million tokens, with 1M context and 128k max output. Anthropic's current public positioning also highlights 65.4% on Terminal-Bench 2.0 and 72.7% on OSWorld, alongside a broad "state-of-the-art across coding and agentic capabilities" story.
Decision: If a bad first attempt creates expensive human repair on a large repository or multi-step agent task, start with Claude Opus 4.6.

The strongest case for Opus is not "Claude is smarter." That phrasing hides the operational question. The stronger case is that some workloads become expensive because a model loses the thread over time, loses relevant context, or generates a result too shallow to survive review. If your agent is reading a large repository, holding a long design or incident document in memory, or producing a response large enough that the final artifact matters as much as the intermediate reasoning, then 1M context plus 128k output changes the job substantially.
This is where price stops being the whole bill. A model that costs more per token can still be cheaper at the workflow level if it saves retries, saves reviewer time, and avoids the kind of partial fix that looks promising but breaks three steps later. Anthropic's current public case is built around that style of work. Even though the benchmark set is not as symmetric as OpenAI's launch appendix, the current official story is consistent: Opus 4.6 is the premium model to reach for when you need sustained coding and agentic execution rather than a cheap first probe.
There is another practical advantage here that comparison tables often underplay: the larger context changes how you structure the work itself. A 1M-token context window lets you ask different questions of a repository or spec set before you lean on retrieval and chunking. That does not eliminate good tool use, but it can make the first pass far more coherent on tasks that are definitionally large. If your evaluation target is "Can one model hold the whole working set without collapsing?" then Opus deserves the first test sooner than a raw price table might suggest. For deeper Anthropic cost planning, the separate Claude Opus 4.6 pricing guide remains the better follow-up.
The Two-Model Setup Most Teams Should Actually Test
The cleanest 2026 answer for many teams is not a permanent winner. It is a division of labor.
Use GPT-5.3-Codex where you want a cheaper first pass through coding-agent work: terminal-heavy loops, broad evaluation batches, and early-stage automation where you are still learning the shape of failure. Escalate to Claude Opus 4.6 when the work expands into a large repository context, a long-running multi-step execution path, or a deliverable where a bad first pass creates expensive cleanup. That is not a diplomatic "both are good" conclusion. It is a concrete two-stage architecture.
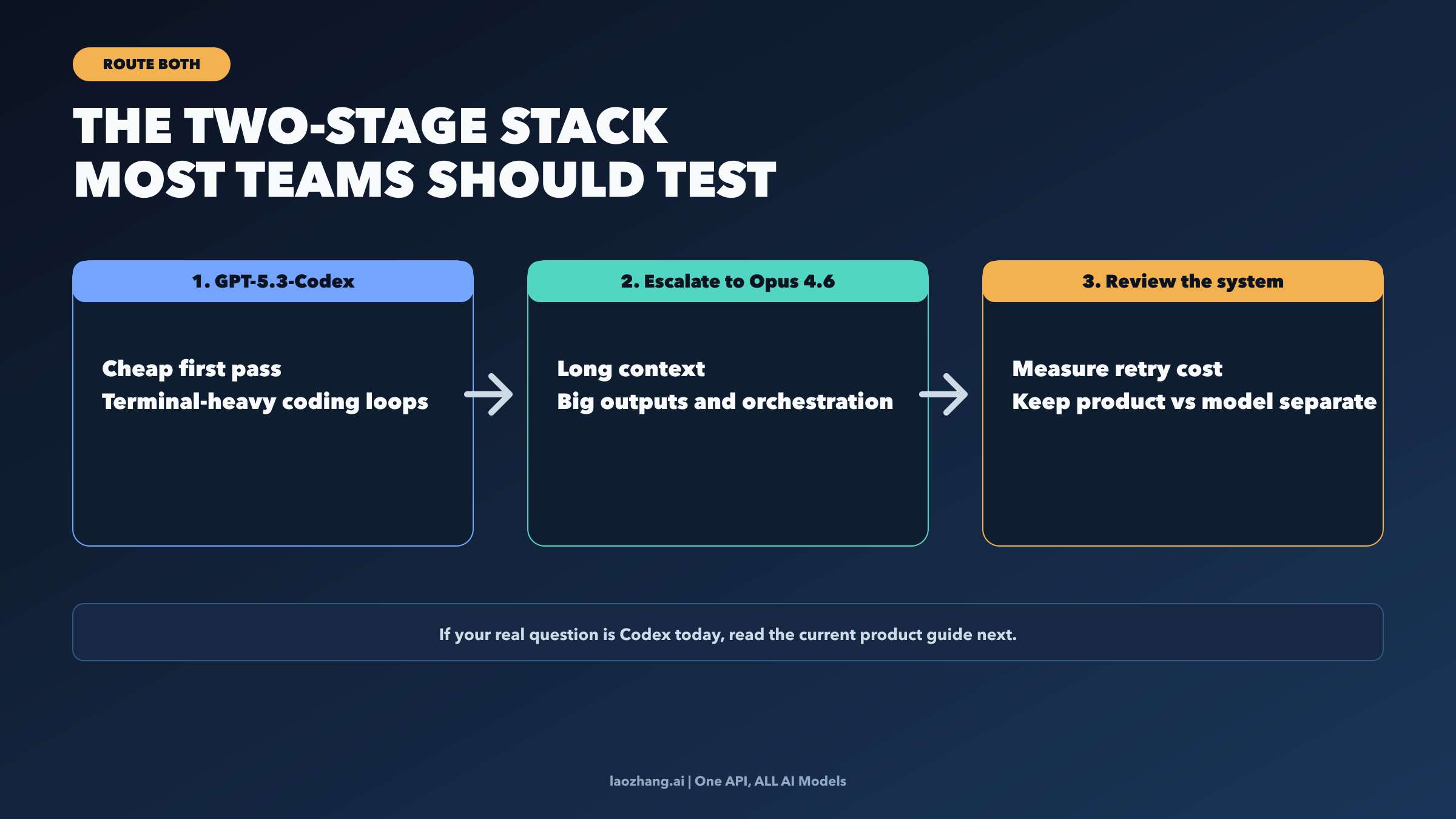
The crucial detail is the escalation rule. If your prompts are staying relatively narrow and you mostly care about price-sensitive evaluation loops, keep the work on GPT-5.3-Codex. If the task grows beyond the cheaper test stage because context grows, retries pile up, or the output itself becomes a high-value artifact, promote the task to Opus. Measure that promotion by retry cost and cleanup cost, not only by token price. Teams that only compare list prices miss the operational cost of a mediocre first pass.
This is also the point where a platform decision can become useful rather than decorative. If you know you want both OpenAI and Anthropic live in the same stack, a unified gateway such as laozhang.ai can reduce the friction of keeping both options available without separate billing, authentication, and integration overhead. The reason to mention it here is simple: the article's best practical answer is often a multi-model setup, and that setup is easier to operate when the integration layer is smaller.
The larger lesson is that model choice should follow the stage of the job. A cheap first-pass model and a premium execution model can coexist inside one coding system without contradiction. In 2026, that is often a stronger engineering answer than pretending one flagship model should own every job.
If Your Real Question Is About Codex Today
Many readers who type "GPT-5.3-Codex" are partly asking a different question: what does Codex actually mean now? On that question, this article should not overreach. OpenAI's current product framing already moved toward a GPT-5.4-era Codex story, with product surfaces across app, CLI, IDE, and cloud, and a clearer split between larger planning models and smaller support models. That is why GPT-5.3-Codex remains a valid comparator here but not the whole product answer.
So the practical redirect is straightforward. If you are choosing models, stay with this page and use the decision rule above. If you are choosing products or workflows, go next to the OpenAI Codex March 2026 guide. If your real decision is whether to adopt Anthropic's toolchain or OpenAI's toolchain, go to Claude Code vs Codex. And if your Anthropic-side question is really about premium cost and role separation inside the Claude family, the Claude 4.6 Agent Teams guide and the Opus pricing guide are the more precise next reads.
Bottom Line
If you want the shortest honest answer, it is this. Start with GPT-5.3-Codex when the job is a cheaper coding-agent loop and the point of the first round is to learn how much useful automation you can get without paying premium rates. Start with Claude Opus 4.6 when the workload is long enough that context depth, execution continuity, and output size are more expensive than token price. And if your stack clearly contains both stages, stop forcing a fake universal winner and split the work on purpose.