
If you are switching between Codex and Claude Code without losing context, do not move the whole chat. Move the durable project state: repo instructions, the current task contract, files touched, commands run, failing evidence, decisions already made, and the next best action. The code state should live in Git, the durable rules should live in AGENTS.md and CLAUDE.md, and the handoff should be a short packet a human could review in two minutes.
Claude Code and Codex are both strong enough that the wrong choice is no longer "the weaker model." The wrong choice is paying for the wrong operating shape, misreading the limit meter, and trusting one vendor's hidden transcript as the only memory of the work. A five-hour window is not five hours of usable coding. A low message count is not automatically worse than a higher one. The real question is how much reviewable work you get before context, model choice, tools, retries, or cloud setup burn the allowance.
The practical answer is tiered. At $20/month, start with Codex if you want visible usage categories and more ways to turn prompts into branches, reviews, and cloud tasks. Start with Claude Code if your real work is a long local session where you keep steering the agent through messy repo state. At $100 or $200/month, compare Claude Max against Codex Pro by the work hours you actually recover: Claude Max buys more room for interactive Claude Code sessions, while Codex Pro buys larger Codex windows across local messages, cloud tasks, and reviews. For teams, stop asking for one winner and set a routing rule: messy local investigation to Claude Code, clear delegated implementation and review to Codex.
Quick Routing Answer
| Situation on 2026-06-14 | Better first move | Why |
|---|---|---|
| Switching mid-project without losing context | Write the handoff packet first | Neither tool can safely infer all prior decisions from a pasted transcript or a vague "continue." |
| $20/month, several focused coding sessions each week | Codex | OpenAI lists Plus at $20/month with Codex on web, CLI, IDE extension, iOS, cloud integrations, GPT-5.5, GPT-5.4, and GPT-5.4 mini local-message allowances. |
| $20/month, one long local repo session with many corrections | Claude Code | Pro includes regular Claude use and Claude Code, and the local tool has strong context and permission controls. |
| $100/month, frequent coding with interactive Claude sessions | Claude Max 5x | Anthropic lists Max 5x at $100/month with 5x Pro capacity per session; the value rises when Claude Code is the main work surface. |
| $100/month, more Codex local messages and reviewable delegated work | Codex Pro 5x | OpenAI lists Pro from $100/month and shows larger model-specific Codex ranges than Plus. |
| $200/month, heavy parallel or delegated work | Compare Max 20x with Codex Pro 20x | Claude Max 20x buys larger Claude sessions; Codex Pro 20x buys larger five-hour Codex windows across task types. |
| Team workflow with both messy and clear work | Use both with routing rules | Put ambiguous local investigation in Claude Code; send scoped implementation, review, and backlog tasks to Codex. |
The most important correction is that context is not a transcript, and usage allowance is not one number. Codex has model and plan-specific local-message ranges, plus separate behavior for cloud, reviews, credits, and API-key usage. Claude Code separates subscription-included usage from API/token billing, and context size changes how fast a session burns through its limit. The right comparison starts with the handoff layer, then the work pattern, then the plan.
Context Handoff: Switch Tools Without Losing The Work
The shared context should be boring enough to survive both tools. Codex reads AGENTS.md guidance files through its documented discovery chain. Claude Code reads CLAUDE.md, not AGENTS.md; when a repo already uses AGENTS.md, create a small CLAUDE.md that imports @AGENTS.md, then add only Claude-specific notes below it. That keeps one repo contract instead of two drifting instruction files.
Use this split:
| Context layer | Durable place | Codex surface | Claude Code surface | Handoff rule |
|---|---|---|---|---|
| Repository rules | AGENTS.md, with CLAUDE.md importing @AGENTS.md | Codex loads AGENTS guidance | Claude loads CLAUDE guidance and imports AGENTS | Keep the shared rules in one place; do not manually duplicate them. |
| Current task state | Issue, PR note, or HANDOFF.md | /compact, /copy, /mention, /goal, /status help turn session state into a packet | /compact, /memory, /usage, claude --continue, and /resume help resume or summarize | Move a short packet, not the full transcript. |
| Code truth | Git branch, diff, tests, logs | /diff, cloud branch, local workspace | local repo, worktrees, permissions | The next tool should start from files and verification output, not vibes. |
| Access and safety | Permission notes, no secrets | /permissions, sandbox, cloud setup boundaries | permission modes, hooks, local rules | Describe required access; never paste API keys, tokens, private logs, or unrelated chat. |
| Long-term learning | Repeated rules only | AGENTS and project memory where appropriate | CLAUDE.md, auto memory, skills | Promote stable corrections; discard one-off task chatter. |
Use this packet when moving from one agent to the other:
md## Agent handoff packet Goal: Current state: Files touched: Commands/tests run: Known failures: Decisions already made: Do not redo: Next best action: Safety/permissions:
The packet should be specific enough that the next tool can act, but short enough that a reviewer can reject it. "Continue from the chat above" is weak. "Fix the failing auth/session.test.ts case; last run failed on expired-token refresh; files touched are src/auth/session.ts and src/auth/session.test.ts; do not change billing middleware; next action is to add the missing refresh guard and rerun npm test -- auth/session.test.ts" is a handoff.
Compaction is useful, but it is not a magic archive. Codex /compact summarizes visible conversation so the session can keep moving; Claude Code project-root CLAUDE.md is reloaded as instruction context, while nested or conversation-only notes can disappear unless they live in a file the tool reads again. If a decision matters after the switch, put it in the handoff packet or repo instructions.
Limits, Tokens, And Real Work Hours
Developer discussions now repeat claims such as "Claude Code 100 hours vs Codex 20 hours" and "5-hour usage limit" because users are trying to translate plan language into work time. Treat those numbers as anecdotes, not as a calculator. Real work hours depend on four variables: how much context is resent, which model is selected, whether the task is local or cloud, and how much human review is needed after the agent returns a diff.
Codex is easier to turn into a visible allowance model. OpenAI's Codex pricing page, checked on June 14, 2026, lists Plus at $20/month and shows model-specific local-message ranges per five hours, including GPT-5.5, GPT-5.4, and GPT-5.4 mini. It also says usage depends on model, task size, complexity, and whether the task runs locally or in the cloud, with weekly limits possible. That means one "message" can be a tiny local prompt or a costly long-running repo task. If you are comparing real hours, log finished tasks, accepted diffs, failed runs, and review time rather than only the remaining percentage.
Claude Code is easier to steer during the hour but easier to overrun when the session grows. Anthropic's Claude Code usage docs say every turn sends the conversation so far, project context, and the new prompt. In a long debugging session, previous messages, files, and diffs ride along on later turns. That is why /clear, /compact, model choice, and disabling unneeded tools are not housekeeping. They directly affect how quickly a five-hour window or subscription allowance feels consumed.
Use this comparison table when the question is "how long can I actually work?"
| Metric to log | Claude Code interpretation | Codex interpretation |
|---|---|---|
| Active coding minutes | Best when minutes are spent steering one uncertain local task | Best when minutes create scoped tasks that can run outside the current conversation |
| Token burn | Rises as conversation history, read files, tools, and Opus use grow | Rises with model choice, codebase complexity, cloud setup, fast mode, and image/agentic features |
| Limit pain | Usually appears as an interrupted local session or a model/plan tradeoff | Usually appears as a five-hour window, weekly limit, or task-type bucket constraint |
| Output value | Measure by whether the session found the right fix path | Measure by accepted diffs, passing checks, useful reviews, and disposable failed branches |
The best normalization is not "hours per dollar." It is "accepted work units per limit hit." If Claude Code gives you two decisive local investigations before the meter hurts, and Codex gives you six acceptable branches with two failed attempts, those are different kinds of productivity. Pick the tool whose limit failure is easiest to recover from in your workflow.
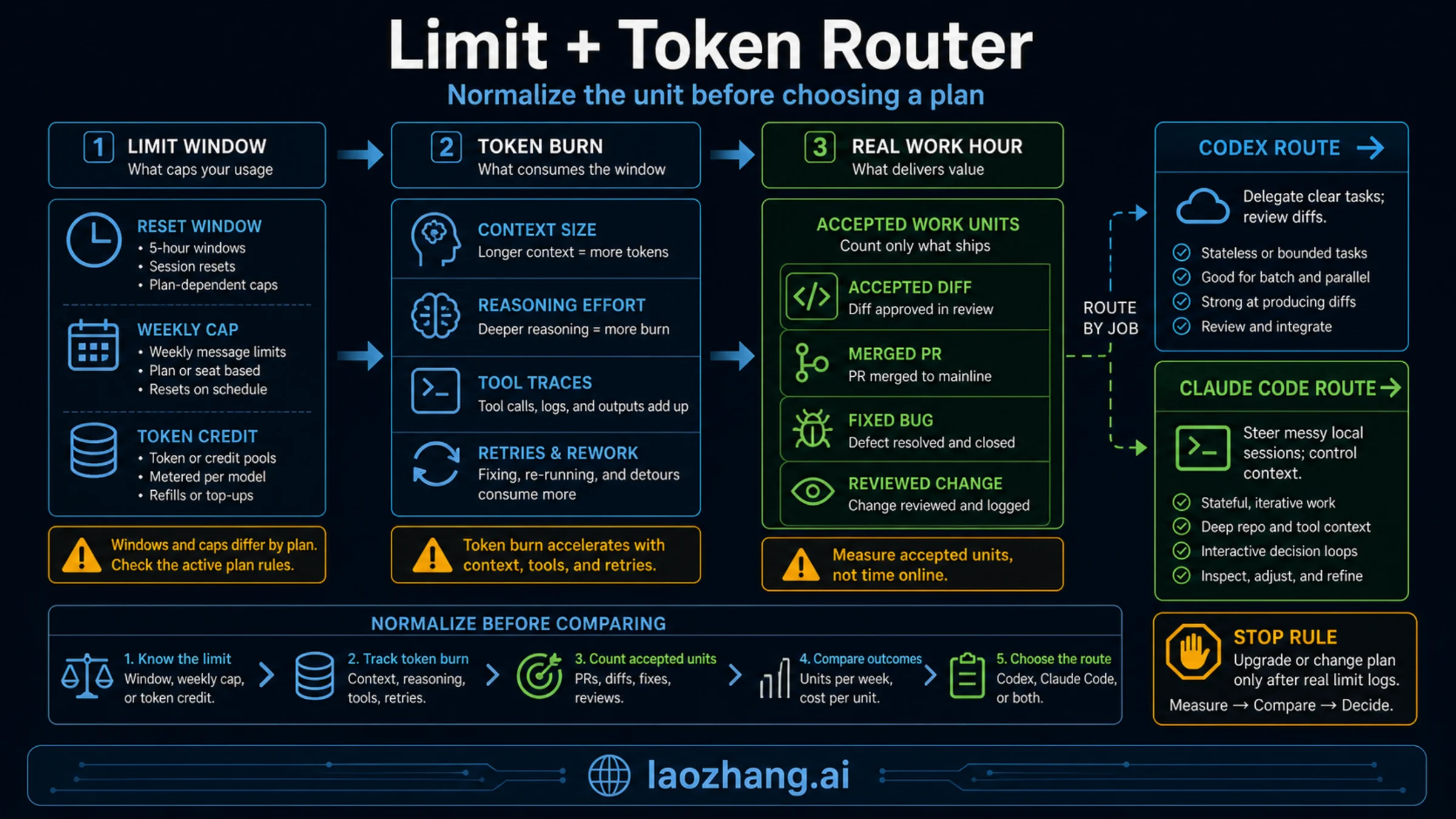
Quotas: Do Not Flatten Either Product Into One Limit
OpenAI now publishes Codex plan allowances in a way that makes the old "is Codex limited?" question too vague. On the current Codex pricing page, Plus is a $20/month plan for a few focused coding sessions each week. It includes Codex on the web, CLI, IDE extension, iOS, and cloud integrations. The visible June 14 table lists GPT-5.5, GPT-5.4, and GPT-5.4 mini local-message ranges per five hours, with GPT-5.4 mini positioned for higher routine usage.
The same page shows why serious users should read the rows instead of repeating a forum number. GPT-5.5, GPT-5.4, and GPT-5.4 mini each have their own local-message behavior; Pro 5x and Pro 20x expand the ranges. OpenAI states that local and cloud tasks share the same five-hour window, that weekly limits may apply, and that Enterprise/Edu usage can scale with credits. That makes Codex easier to budget when you care about task type, but it also means a single allowance claim becomes stale quickly.
Claude Code is different. The Claude Code usage guide says how you sign in decides how usage is metered. A Claude Enterprise seat gets included usage with a rolling reset window, while API-key usage is pay-as-you-go and billed per token to the relevant cloud or Console account. The same guide tells users to manage context with '/clear' and '/compact', because long wandering sessions resend previous context and can degrade both allowance and quality.
Anthropic also changed the capacity story in May. On May 6, 2026, Anthropic said it was doubling Claude Code five-hour rate limits for Pro, Max, Team, and seat-based Enterprise plans, removing the peak-hour limit reduction for Pro and Max, and increasing Opus API limits. That means older complaints about Claude Code allowance should be treated as dated, but it does not turn Claude Code into an unlimited surface. Claude Code's own cost and memory docs still tell you to manage context with /clear, /compact, /usage, and memory hygiene.
The decision rule is simple: choose Codex when you want allowance categories you can reason about across local messages, cloud tasks, and reviews. Choose Claude Code when the session itself is the work and you are willing to manage context, model choice, and permission rules actively.
Cost: Subscription Price Is Only The First Layer
The published sticker prices looked symmetrical in the June 14, 2026 check. Anthropic's current plan help lists Claude Pro at $20/month or $200/year, Max 5x at $100/month, and Max 20x at $200/month. OpenAI's Codex pricing page lists Plus at $20/month and Pro from $100/month, with larger Pro allowance ranges. At that level, both companies appear to offer the same three consumer price anchors.
The real cost split is underneath the sticker. Claude Code can be used under a Claude plan, but it can also run through API-key billing. Anthropic's cost-management docs say Claude Code charges by API token consumption for API usage, while Pro and Max subscribers have usage included in the subscription and see plan usage bars instead of a billing-relevant session cost. The same page gives enterprise averages around $13 per developer per active day and $150-250 per developer per month, while warning that codebase size, model choice, multiple instances, automation, and context shape all move the number.
Codex has a cleaner subscription path for many individual users because Codex usage is attached directly to ChatGPT Plus and Pro plans. That does not make it free in an operational sense. A GPT-5.5 task that consumes a scarce local-message window, a cloud task that runs through setup, and a code review all belong to a budget. The good news is that OpenAI exposes those buckets more explicitly than it did in earlier Codex eras.
For a solo developer, the cheapest honest experiment is one month at $20. Use Codex Plus if you want to test local CLI, IDE, web, cloud tasks, and reviews under one plan. Use Claude Pro if your main question is whether Claude Code's local steering loop fits how you actually work. Do not jump to $100 before you have a week of usage notes: how often you hit limits, which model you use for hard tasks, how many tasks are actually delegate-ready, and how much rework each tool leaves behind.
Stability: Read Incidents As Routing Signals

Stability is not the same as brand trust. On June 14, 2026, the OpenAI status page showed fully operational status and Codex aggregate uptime of 99.96% for the March-June window; on May 23, it had shown an ongoing Codex rate-limit issue while still showing high aggregate uptime. The useful interpretation is not "Codex is unstable" or "Codex is fine." The useful interpretation is that aggregate uptime and the exact surface you need can diverge.
Claude's status page told a similar caution story. On June 14, Claude Code was operational and no June 14 incident was listed, but the page still showed several recent resolved model incidents from June 8-13 and a lower 90-day Claude Code aggregate than Codex's product aggregate. Again, the conclusion should be operational rather than tribal. Claude can be excellent for long reasoning sessions and still have recent service interruptions. Codex can publish high uptime and still have a rate-limit incident on the day you are trying to ship.
For production work, set a stability rule before you start. If the work is interactive and a live outage would break your focus, keep a smaller fallback task or alternate model ready. If the work is async, use branch isolation and review checkpoints so a failed background run is a recoverable attempt rather than a blocked day. For teams, log incidents against workflow type: local session interruption, cloud task failure, review delay, login failure, or model degradation. That history is more useful than a generic reliability opinion.
Code Quality: Judge The Workflow, Not Just The Model
Both vendors can point to strong coding evidence. OpenAI's GPT-5.5 release says the model is stronger in agentic coding, uses fewer tokens on Codex tasks, and improves on GPT-5.4 across coding evaluations such as Terminal-Bench 2.0, SWE-Bench Pro, and long-horizon internal coding tasks. OpenAI also describes GPT-5.5 in Codex as better at holding context across large systems, reasoning through ambiguous failures, checking assumptions with tools, and carrying changes through surrounding code.
Anthropic's Claude Opus 4.7 release makes a different but equally relevant claim. It says Opus 4.7 improved over Opus 4.6 in advanced software engineering, handles complex long-running tasks with rigor and consistency, follows instructions more precisely, and verifies its outputs before reporting back. It also says Claude Code raised the default effort level for Opus 4.7 to xhigh across plans, which matters because quality and token usage are now tied to effort control.
The safest conclusion is that neither product wins every codebase. Codex has the strongest case when the task can be delegated, validated, and reviewed as a diff. Claude Code has the strongest case when code quality depends on close interactive steering, permission rules, context management, and a developer catching the agent's direction early. Quality is not only "does the model know the answer?" It is also "does the tool make the right work loop easy?"
Use a four-part quality test before standardizing:
- Give both tools the same bug with tests already present.
- Give both tools a messy refactor with local unstaged context.
- Give both tools a scoped async implementation task.
- Give both tools a review task where the correct answer is to reject a plausible but unsafe change.
Keep the tool that produces fewer false starts, cleaner diffs, better test behavior, and clearer uncertainty notes for that task type.
Permissions And Safety Controls
Claude Code currently has the richer permission vocabulary. Its permissions docs describe allow, ask, and deny rules; rules can be checked into version control and distributed across an organization. The documented modes include 'default', 'acceptEdits', 'plan', 'auto', 'dontAsk', and 'bypassPermissions', with 'bypassPermissions' reserved for isolated environments because it skips prompts for risky areas such as '.git', '.claude', '.vscode', '.idea', and '.husky'.
Codex has a simpler and clearer split. OpenAI's agent approval and security docs say Codex cloud runs in isolated OpenAI-managed containers with a setup phase that can access the network and an agent phase that is offline by default unless internet access is enabled. The same docs say Codex CLI and IDE use OS-level sandbox policies, with default no network access and writes limited to the active workspace. In the Auto preset, Codex can read files, make edits, and run commands in the working directory automatically, while approvals are requested for out-of-workspace edits or network commands.
That means Claude Code is better when a team needs granular local permission policy. Codex is better when a team wants a smaller set of presets and a documented local-versus-cloud trust boundary. The difference is not "safe" versus "unsafe." It is policy richness versus operational simplicity.
Plan-By-Plan Recommendation
| Budget | Start here | Switch when |
|---|---|---|
| $20/month | Codex Plus for broad Codex access; Claude Pro for local-first Claude Code use | Switch from Codex to Claude if local steering dominates; switch from Claude to Codex if quota visibility and async tasks dominate. |
| $100/month | Codex Pro 5x for heavier Codex windows; Claude Max 5x for heavier Claude sessions | Upgrade only after a week of real usage logs. |
| $200/month | Codex Pro 20x for parallel delegate-and-review work; Claude Max 20x for large Claude Code sessions | Keep the other tool available if reliability or task shape demands it. |
| API / enterprise | Compare billing owner, logs, data controls, rate limits, and admin governance | Do not compare consumer subscriptions to token-billed automation as if they were the same product. |
The default $20 recommendation is Codex if the reader has no prior preference, because it exposes more coding-agent surfaces under one plan and gives clearer current allowance categories. The exception is important: choose Claude Code first when the job is local, exploratory, permission-heavy, and likely to need many corrections before the solution shape is obvious.
Hybrid Workflow That Actually Works
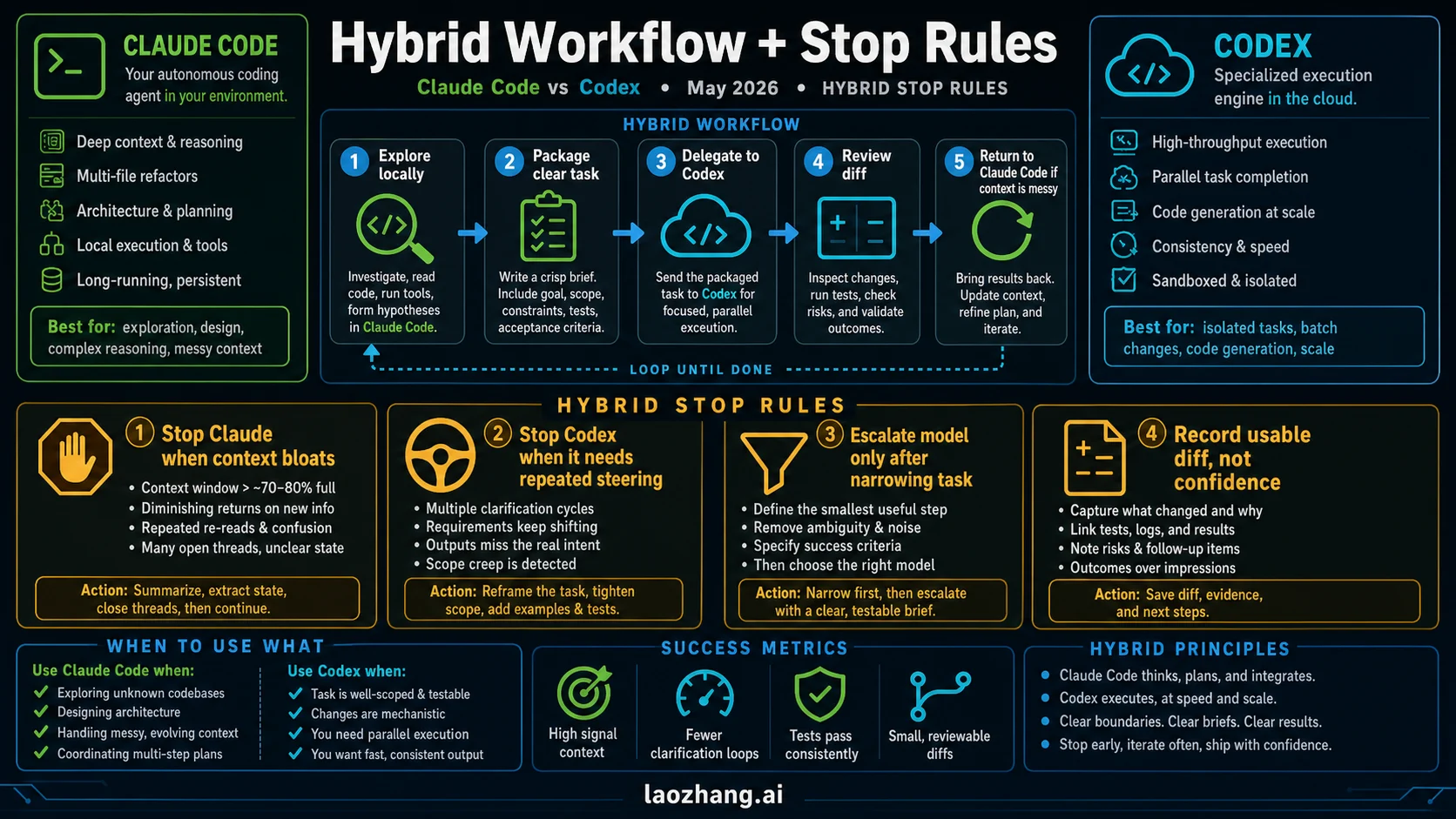
Use Claude Code for the first uncertain hour of a hard change: read the repo, inspect failures, test assumptions, and decide where the fix should land. Keep context lean with /clear between unrelated tasks and /compact during long runs. When the task becomes clear, write the handoff packet before moving to Codex as a branch, review, or scoped implementation.
Use Codex for the work that benefits from isolation and review: backlog fixes, mechanical refactors with a written contract, dependency cleanup, generated tests, review passes, and cloud tasks where a failed attempt is easy to discard. Move back to Claude Code when the task starts depending on local uncommitted state, when the diff needs a richer permission conversation, or when the handoff packet proves the task was still ambiguous.
The stop rules matter more than the starting tool:
- Stop a Claude Code session when context is bloated, the model is looping, or the task has become a clean implementation ticket.
- Stop a Codex task when it keeps missing repo-specific context, needs repeated steering, or the resulting diff is harder to review than to write locally.
- Stop any switch when there is no current Git state, no test status, or no written next action.
- Escalate model strength only after you have reduced context waste, narrowed the task, and verified that the failure is reasoning rather than setup.
- Record which tool produced a usable diff fastest, not which one sounded more confident.
If you already pay for both, do not run the same task twice and pick the prettier answer. Set a primary path and a verification path. Security-sensitive or permission-heavy changes can start in Claude Code for local investigation, then go to Codex for independent review. Mechanical dependency or test updates can start in Codex as a branch, then come back to Claude Code only when a failing test needs repo-specific explanation. The second tool should answer one explicit verification question, not redo the entire implementation.
FAQ
Is Codex cheaper than Claude Code at $20?
For a new user whose main goal is coding-agent breadth, Codex Plus is usually the stronger $20 experiment because it includes Codex across local and cloud surfaces plus current Codex models. Claude Pro can still be better if the user mainly wants Claude Code inside a local repo and expects long interactive sessions.
Can Claude Code read AGENTS.md?
Not directly as its primary instruction file. Claude Code reads CLAUDE.md. If the repo already uses AGENTS.md for Codex, create a CLAUDE.md that imports @AGENTS.md, then add Claude-specific notes below that import. A symlink can also work, but an import keeps the shared contract explicit.
Should I paste the whole Codex transcript into Claude Code?
No. Paste a handoff packet, not the whole transcript. Include the goal, files touched, commands and tests run, known failures, decisions already made, what not to redo, and the next best action. The next tool should ground itself in the repo, Git diff, and verification output.
What survives compaction?
Codex /compact summarizes the visible conversation so the session can keep moving. Claude Code reloads project-root CLAUDE.md as instruction context, but nested or conversation-only details are not a durable handoff unless they live in a file the next session reads. Important decisions belong in AGENTS.md, CLAUDE.md, an issue/PR note, or the handoff packet.
Does Claude Code still hit usage limits after Anthropic raised capacity?
Yes. Anthropic doubled Claude Code five-hour rate limits for several plan types on May 6, 2026 and removed the peak-hour reduction for Pro and Max, but Claude Code still has usage windows, context behavior, and model-cost tradeoffs. Treat the increase as more headroom, not unlimited usage.
Which one produces better code?
Codex has a strong current claim through GPT-5.5 in delegated engineering work, especially when the task can be validated and reviewed as a diff. Claude Code has a strong current claim through Claude Opus 4.7 and its interactive local workflow, especially for complex reasoning and instruction-sensitive work. Better code depends on the workflow: tests, review, context hygiene, permission control, and the moment you stop a bad run.
Which one is more stable?
Neither should be treated as always stable. On May 23, 2026, OpenAI showed an ongoing Codex rate-limit incident while still showing high aggregate Codex uptime. Claude showed no incident that day but many recent resolved incidents in May. Read status pages before critical work and keep a fallback route.
Should a team standardize on one tool?
Only if the team's work shape is unusually uniform. Most teams should standardize the routing rule instead: Claude Code for messy local reasoning and permission-heavy exploration; Codex for scoped delegation, code review, cloud tasks, and branch-based work.