
If you need a model today, use GPT-5.4. Claude Mythos Preview may lead on Anthropic's published launch benchmarks, but it is still a gated research preview for invited participants rather than a normal public model you can choose from.
As of April 9, 2026, OpenAI ships GPT-5.4 across ChatGPT, the API, and Codex, while Anthropic restricts Mythos Preview to Project Glasswing partners and other invited organizations. That makes this a route decision before it is a benchmark showdown: ordinary users should stay on GPT-5.4 now and track Mythos only if they are already inside the preview audience or they run future-tier evaluations.
The Fast Answer
If the headline made this look like a normal "which model wins" comparison, the practical answer is much narrower.
| Your real question | Best move right now | Why |
|---|---|---|
| "Which model can I actually use today?" | GPT-5.4 | It is available now across ChatGPT, the API, and Codex. |
| "Is Mythos Preview a public self-serve alternative?" | No | Anthropic frames it as a gated research preview for invited participants. |
| "Should Mythos change my current GPT-5.4 plan?" | Usually no | Benchmark leadership does not erase the access gap. |
| "When is Mythos worth tracking?" | When you are invited or running future-tier evals | That is when the benchmark signal becomes operationally useful. |
The evidence note matters here because both sides publish real, current, official facts. Anthropic's Project Glasswing materials say Mythos Preview is restricted to partners and invited organizations, publish participant pricing, and show strong launch benchmark numbers. OpenAI's GPT-5.4 launch page says GPT-5.4 is available now across ChatGPT, the API, and Codex, with public pricing and long-context support. So the comparison is not fake, but it is operationally asymmetric.
What Claude Mythos Preview Actually Is Right Now

Claude Mythos Preview is real, but it is not a normal public model contract. Anthropic says access is currently limited to Project Glasswing partners and more than 40 additional invited organizations that build or maintain critical software infrastructure. That is enough to make Mythos important. It is not enough to treat Mythos like something an ordinary reader can simply switch to after finishing this article.
The pricing language reinforces the same boundary. Anthropic says Mythos Preview will be available to participants at $25 per million input tokens and $125 per million output tokens after the initial usage-credit period. Those numbers matter if you are already in the preview audience. They do not function like a normal public procurement surface in the same way GPT-5.4's API pricing does, because the reader still has to clear the access gate first.
Anthropic's current public position is even narrower than many rumor-driven comparison posts imply. As of April 9, 2026, Anthropic says it does not plan to make Claude Mythos Preview generally available. That does not mean Anthropic will never ship a Mythos-class public model under some future contract. It does mean that right now you should not treat Mythos Preview as if it were a broadly available menu option waiting one click away.
The clean mental model is this: Mythos Preview is a frontier signal, not a default route. It tells you Anthropic's top-end capabilities may be moving upward again. It does not, by itself, tell ordinary users to stop choosing among the models they can actually deploy today.
What GPT-5.4 Gives You Today
GPT-5.4 is the opposite kind of object. OpenAI launched it on March 5, 2026 and says it is available now across ChatGPT, the API, and Codex. That matters because availability is not a side detail in this comparison. Availability is part of the answer.
OpenAI also publishes a straightforward public price: $2.50 per million input tokens, $0.25 per million cached input tokens, and $15 per million output tokens. For long-horizon work, OpenAI says GPT-5.4 supports up to 1M tokens of context in API and Codex workflows. In other words, the current GPT-5.4 contract gives you a model you can budget, test, deploy, and document today without needing special preview status.
That is why GPT-5.4 remains the actionable default even if you believe Anthropic's benchmark story. A deployable default is the model you can route work to this week, not the model that produces the most interesting future-tier headline. If your next question is about the cheapest way to access GPT-5.4, our guide to the GPT-5.4 free API goes deeper on current access paths and cost tradeoffs. If your workflow specifically depends on Codex-side automation, the March 2026 OpenAI Codex update is the better operational follow-up.
This is the main reason the comparison should not collapse into abstract "model quality" language. For most readers, the decision surface is not "Which lab looks most impressive?" It is "Which route can I use today without pretending I already have access to a preview program?"
What the Official Overlap Benchmarks Do and Do Not Prove
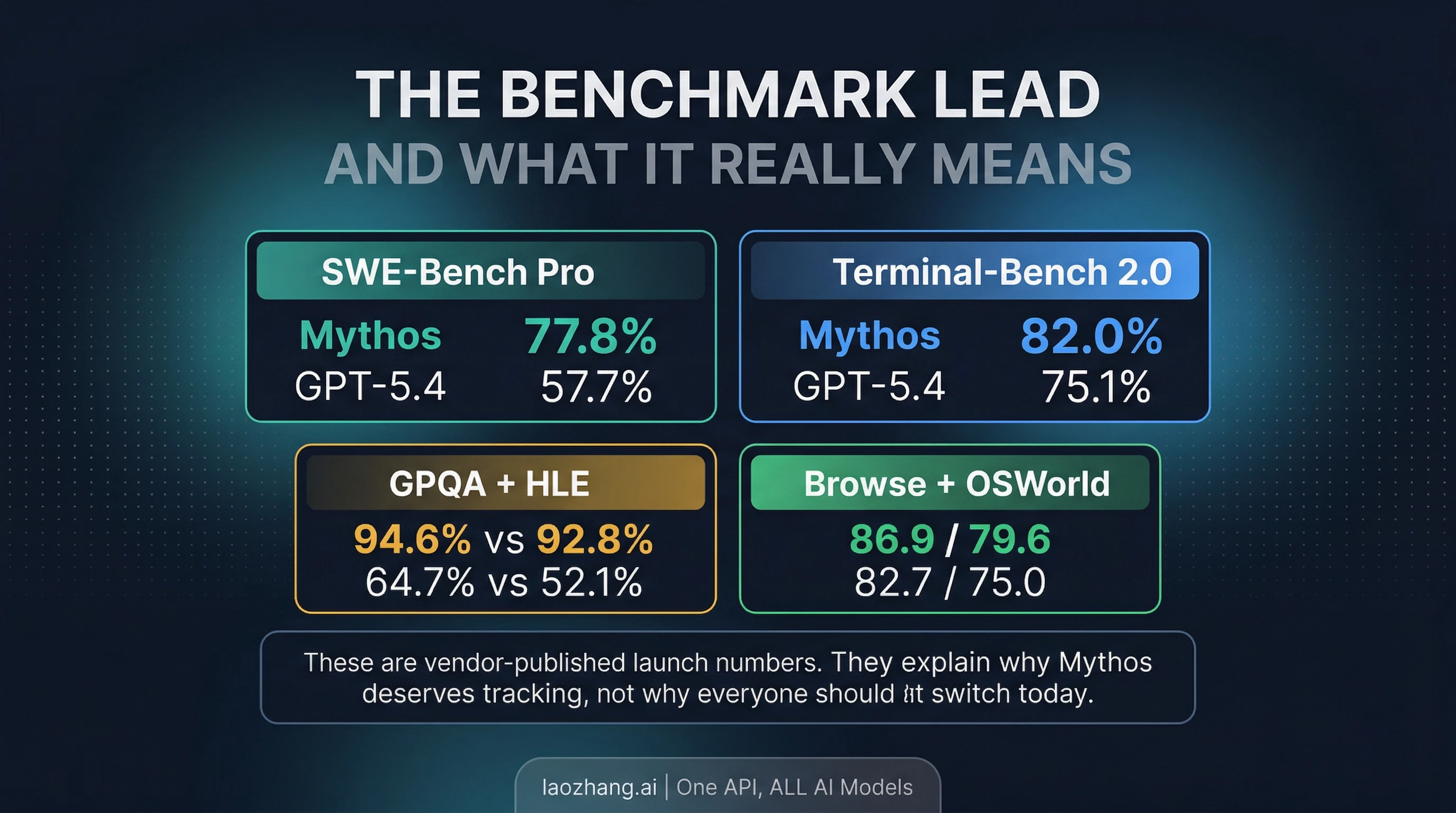
Mythos Preview does have a real official benchmark lead on overlapping evaluation names. Anthropic's Project Glasswing page publishes Mythos Preview at 77.8% on SWE-Bench Pro, 82.0% on Terminal-Bench 2.0, 93.9% on SWE-Bench Verified, 94.6% on GPQA Diamond, 64.7% on Humanity's Last Exam with tools, 86.9% on BrowseComp, and 79.6% on OSWorld-Verified. OpenAI's GPT-5.4 launch page publishes 57.7% on SWE-Bench Pro, 75.1% on Terminal-Bench 2.0, 92.8% on GPQA Diamond, 52.1% on Humanity's Last Exam with tools, 82.7% on BrowseComp, and 75.0% on OSWorld-Verified.
Those rows make Mythos Preview worth paying attention to. They are the reason this article exists at all. If Anthropic had launched a gated preview with no visible public lead on anything, the practical advice would barely change and the benchmark layer would not deserve much screen space. But the lead is there, and it is large enough across several overlapping eval names that it would be irresponsible to dismiss Mythos as mere leak residue or hype packaging.
At the same time, the benchmark table does not give you a clean, neutral, universal winner. Anthropic and OpenAI each publish their own launch numbers on their own official surfaces. That means the overlapping names are useful, but they are still vendor-published launch evaluations rather than one lab-neutral scoreboard with identical settings, tools, and budgets. The right reading is "the Mythos lead is real enough to matter" rather than "Mythos has conclusively replaced GPT-5.4 for every current buying decision."
That caveat is not a rhetorical escape hatch. It changes the route recommendation. The benchmark lead means Mythos should be on the watchlist of people who care about top-tier coding, reasoning, or security-adjacent evaluation performance. It does not automatically tell ordinary users to move away from the model they can actually access, deploy, and buy against right now.
When Mythos Should Actually Change Your Plan

For most readers, Mythos should not change the current plan. If you need a model today, GPT-5.4 is still the correct answer because it is broadly available now across the product and developer surfaces that matter. You do not gain much by turning a usable present-tense route into a waiting game for a preview contract you may never be admitted to.
Mythos does start to matter earlier for a narrower set of readers. If you are already inside the preview audience, then the comparison is no longer abstract. At that point you have a real evaluation question: does Mythos improve enough on your workloads to justify testing, workflow adjustments, or future migration planning? The same is true if your job includes maintaining frontier-model watchlists, security evaluation harnesses, or escalation paths for top-end coding systems. For those readers, Mythos is not just a headline. It is an early signal that Anthropic's future top tier may be worth preparing for.
Everyone else should treat Mythos as a tracking signal rather than a current destination. That means keeping your current GPT-5.4 work moving, preserving a clean evaluation baseline, and only spending extra time on Mythos if the access boundary changes or your organization receives preview access directly. This is a much better posture than suspending real work because a future-tier model looks stronger on launch-day boards.
There is also a boundary question here. If your real decision is broader than Mythos versus GPT-5.4, this page should stop being your only reference. A lot of search traffic really wants a broader public-model decision or an Anthropic-only route decision, and those are different reader jobs from the one this article is built to solve.
If Your Real Question Is Broader Than This Page
Use this page when the question is specifically, "Should the Mythos benchmark lead change what I use right now if GPT-5.4 is already available to me?"
If your real question is instead "Which public assistant should I use overall between ChatGPT and Claude?" then the better next read is our full ChatGPT vs Claude comparison. That page is built for the public-versus-public choice and goes deeper on coding, writing, pricing, and general product surface tradeoffs.
If your real question is "Inside Anthropic's world, should I use the current shipping Claude model or just track the preview tier?" then read Claude Capybara vs Opus 4.6. That page focuses on Anthropic's own route boundary rather than a cross-vendor mixed-contract decision.
Routing outward is not a dodge. It is what keeps this article useful. The page is strongest when it stays narrow: Mythos benchmark leadership is real, but GPT-5.4 remains the deployable default unless you are already inside the preview audience.
FAQ
Is "Claude Mythos" the same thing as Claude Mythos Preview?
In current public use, "Claude Mythos" is usually shorthand for the official name Claude Mythos Preview. The important distinction is not the nickname versus the full name. It is that the official Anthropic surface describes Mythos as a gated preview rather than a public self-serve product.
Does Mythos participant pricing make it a normal alternative to GPT-5.4?
No. Anthropic's participant pricing is real, but it is still participant-only pricing tied to a gated preview surface. GPT-5.4 pricing is attached to a public route you can actually buy and deploy today. Those are not equivalent procurement conditions.
Does Mythos beat GPT-5.4 overall?
It is more accurate to say Mythos leads on several overlapping vendor-published launch benchmarks. That is not the same thing as proving a universal overall winner across every workflow, tooling path, latency profile, and access condition.
Should I compare GPT-5.4 with Opus instead of Mythos?
Yes, if your actual choice is between models you can use publicly right now. In that case, ChatGPT vs Claude is the better cross-platform page, and Claude Capybara vs Opus 4.6 is the better Anthropic-only route page.
What is the bottom line?
The benchmark lead is enough to make Mythos worth tracking. It is not enough to displace GPT-5.4 as the current default for ordinary users. If you need a model today, use GPT-5.4 now. If you already have preview access or you run future-tier evaluations, keep Mythos on the watchlist and test it in that narrower context.