GPT-5.4 launched on March 5, 2026 as OpenAI's most powerful model to date, combining coding, reasoning, and native computer use in a single frontier model. The official API costs $2.50 per million input tokens with no free tier whatsoever. But that does not mean there is no path to free or near-free access. Developers have five legitimate methods to call the GPT-5.4 API at zero or minimal cost, ranging from third-party gateway credits to a prompt caching strategy that reduces bills by up to 90%. This guide covers every option with exact quota numbers, working Python code, and real cost calculations for three typical use cases.
TL;DR
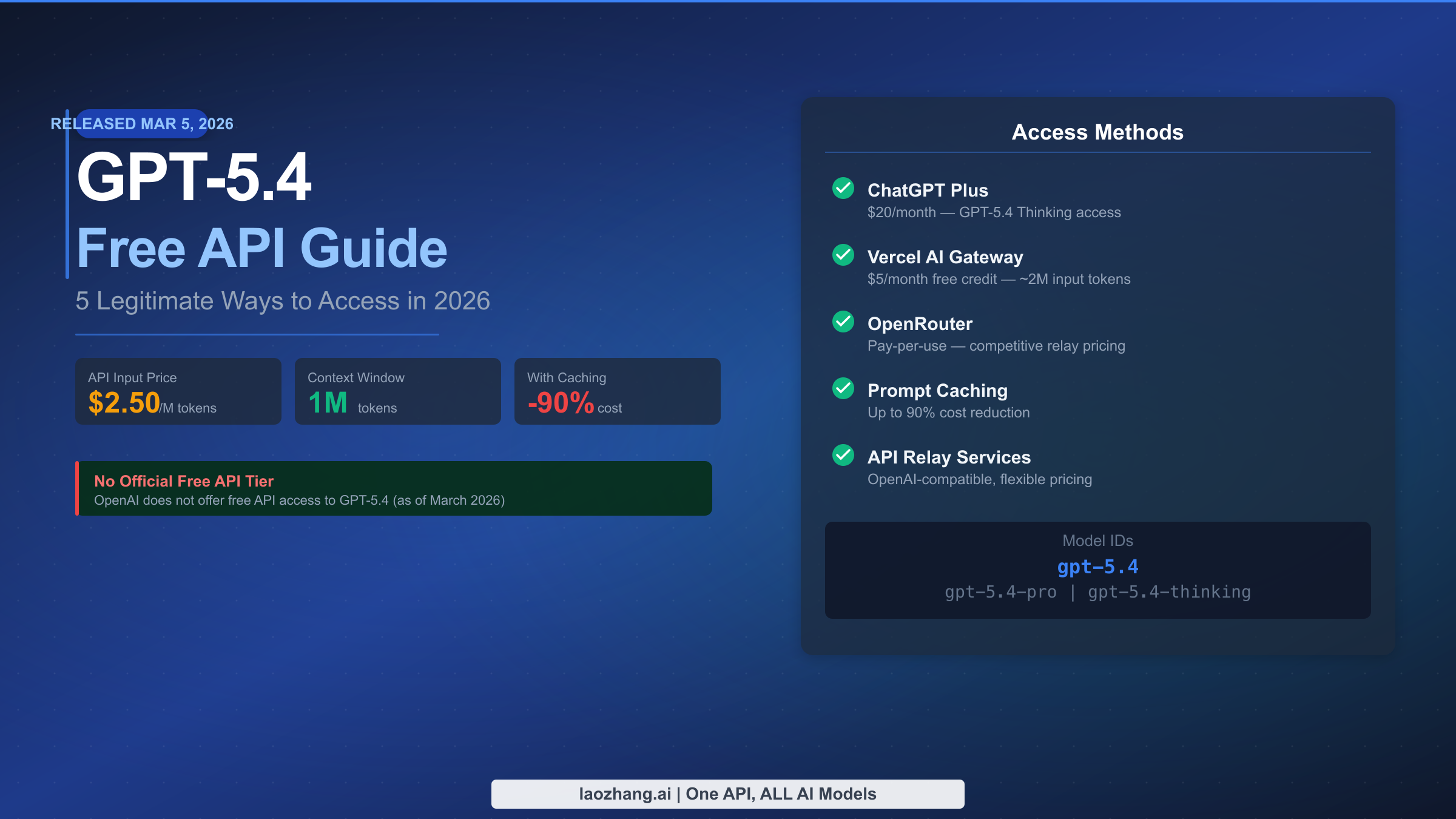
- GPT-5.4 API: $2.50/M input, $0.25/M cached input, $15.00/M output — no official free tier
- ChatGPT Free: Only GPT-5.3 (10 messages per 5 hours) — GPT-5.4 is NOT included
- ChatGPT Plus ($20/month): Includes GPT-5.4 Thinking; UI access only, no API key
- Vercel AI Gateway: $5/month free credit covers approximately 2 million GPT-5.4 input tokens
- Prompt caching: Reduces input costs from $2.50 to $0.25 per million — a 90% reduction
- Model IDs:
gpt-5.4(standard),gpt-5.4-pro(enterprise),gpt-5.4-thinking(reasoning)
Does GPT-5.4 Have an Official Free API? The Honest Answer
OpenAI does not offer a free API tier for GPT-5.4. This is not a new policy — OpenAI deprecated its automatic $5 free credit for new accounts in mid-2025, and GPT-5.4 continues that trajectory as a premium, paid-only API model. When the model launched on March 5, 2026, OpenAI positioned it explicitly for professional work and enterprise automation, not hobbyist experimentation on a free plan. The ChatGPT Free tier does not include GPT-5.4 either — free accounts get limited access to GPT-5.3 only, capped at ten messages every five hours, with GPT-5.4 Thinking reserved for Pro, Business, Enterprise, and Education subscribers.
This reality frustrates many developers who saw the launch coverage and wanted to immediately test the model's reported 83.0% score on the GDPval benchmark or its new native computer-use capabilities. The excitement is understandable — GPT-5.4 is 33% less likely to generate erroneous responses compared to GPT-5.2, and it uses up to 47% fewer tokens on certain tasks, which are the kinds of improvements that meaningfully change what you can build. But OpenAI's commercial structure means that access to these capabilities requires either a paid subscription or pay-as-you-go API spend.
That said, "no official free tier" is not the same as "impossible to access for free." The distinction matters enormously for developers who are evaluating whether GPT-5.4 fits their use case before committing budget. Three of the five access methods below require zero upfront payment, and two of them provide genuine free credit that can be used for real API calls with a proper API key. The table below summarizes all five options at a glance before the sections below walk through each in detail.
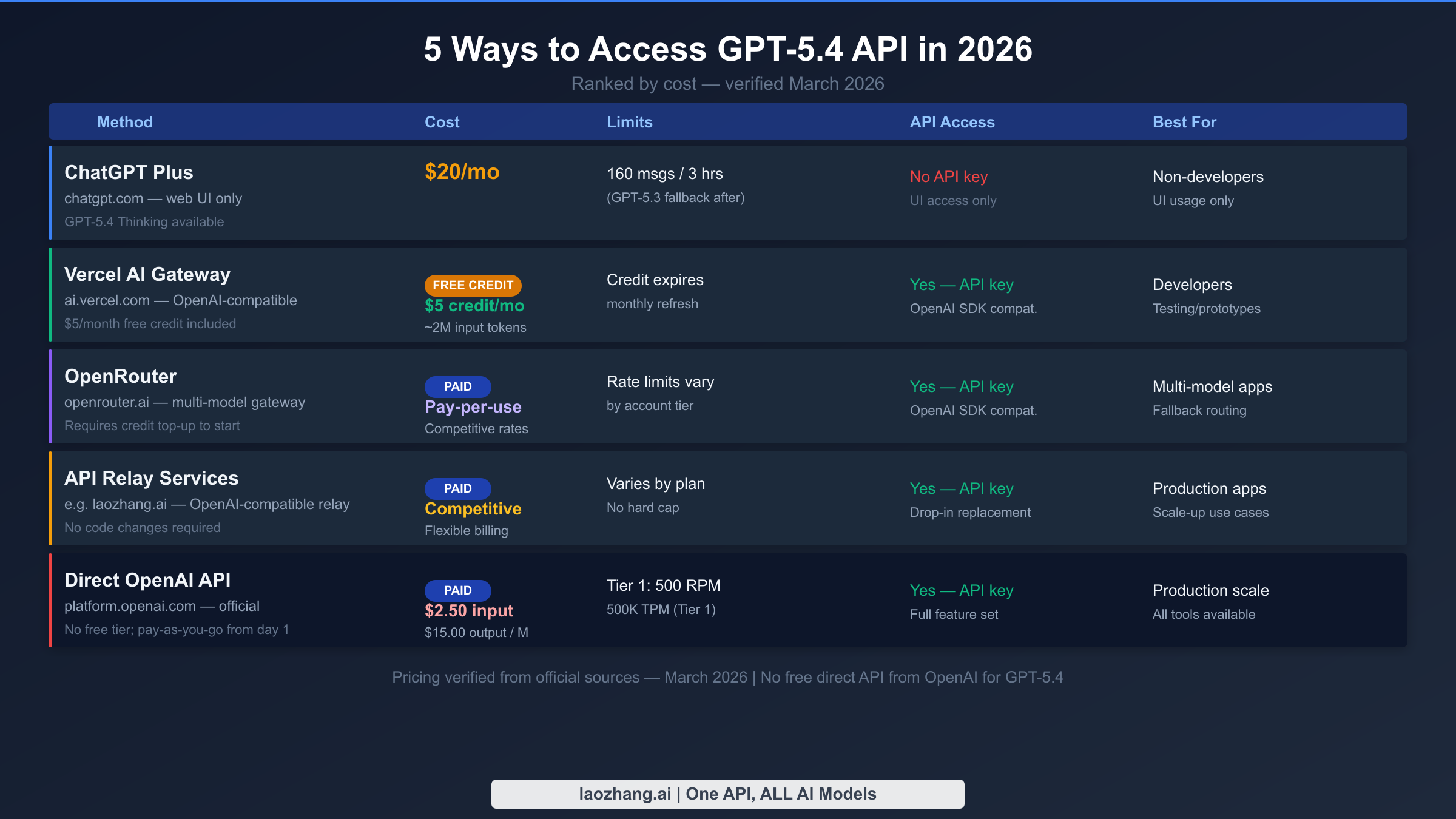
| Method | Cost | API Key | GPT-5.4 Access Level | Best For |
|---|---|---|---|---|
| ChatGPT Plus | $20/month | No (UI only) | GPT-5.4 Thinking (limited quota) | Non-developer exploration |
| Vercel AI Gateway | $5 free credit/month | Yes | Full GPT-5.4 (standard) | Developer testing |
| OpenRouter | Pay-per-use | Yes | Full GPT-5.4 (standard) | Multi-model routing |
| API Relay Services | Competitive rates | Yes | Full GPT-5.4 (standard) | Production scale |
| Direct OpenAI API | $2.50/M input | Yes | Full + all tools | Maximum control |
5 Ways to Access GPT-5.4 API at Low or Zero Cost
The five methods below are ranked from most accessible to most powerful, though "most accessible" and "best for developers" are not the same thing. If you are a non-technical user who just wants to experience GPT-5.4 right now, ChatGPT Plus is the right answer. If you are a developer who needs to integrate GPT-5.4 into an application without paying before you know the model works for your use case, Vercel AI Gateway's monthly free credit is the correct starting point. And if you are already running AI infrastructure at scale and need a stable, OpenAI-compatible endpoint without IP restrictions, a relay service may offer better economics than the direct OpenAI API for your specific pattern of usage.
ChatGPT Plus ($20/month) gives non-developers the most immediate access to GPT-5.4 Thinking through the ChatGPT web interface and mobile apps. Subscribers get access to GPT-5.4 Thinking within their standard message quota, though the exact allocation shifts as OpenAI balances platform load. ChatGPT Plus is not an API solution — there is no API key, no programmatic access, and no way to integrate it into an application. Its value is in hands-on evaluation of GPT-5.4's reasoning capabilities, particularly for tasks like complex document analysis, multi-step research, or code review where you want a human in the loop.
Vercel AI Gateway is the most practical free option for developers who need actual API access. Vercel provides $5 in monthly gateway credit with no credit card required for the initial signup, which translates to approximately 2 million GPT-5.4 standard input tokens at $2.50/M. The gateway is OpenAI SDK-compatible, meaning you can use the standard Python openai library by changing only the base_url parameter — no other code changes required. The credit renews monthly, making it a repeatable resource for ongoing prototype testing. The limitation is that $5 covers meaningful exploration but will not sustain a production workload above a few thousand calls per month.
OpenRouter provides pay-per-use access to GPT-5.4 and hundreds of other models through a single API endpoint. It requires a credit top-up before making calls, so there is no truly free tier, but the minimum deposit is low and the rates are competitive. OpenRouter is particularly useful when you want to build routing logic that falls back to a cheaper model like GPT-5.3 Instant when your use case does not require GPT-5.4's full capability. It is also valuable for teams that want to A/B test different models without managing multiple API keys or integrations.
API relay services like laozhang.ai offer OpenAI-compatible endpoints that proxy requests to GPT-5.4 at competitive rates without the IP restrictions that sometimes affect direct OpenAI access from non-US server locations. For developers outside North America or those running high-volume workloads that benefit from flexible billing structures, relay services often provide better practical economics than going direct to OpenAI. The critical requirement is that you verify the relay service uses legitimate API access and does not violate OpenAI's terms of service — established relay providers with published documentation and clear billing are the right choice here.
Direct OpenAI API at platform.openai.com remains the gold standard for maximum control, access to all GPT-5.4 tools including computer use, and the highest rate limits at upper tiers. If you have payment set up and are building a production application, this is likely where you will end up. Tier 1 accounts start at 500 requests per minute and 500,000 tokens per minute, scaling to 15,000 RPM and 40 million TPM at Tier 5. The tradeoff is that there is no trial period — your first API call generates a charge against your credit card or prepaid credits.
Your First GPT-5.4 API Call: Complete Setup Guide
Getting your first GPT-5.4 API response is straightforward if you have already worked with the OpenAI Python SDK on earlier models. The model ID is gpt-5.4 for the standard version and gpt-5.4-pro for the high-performance variant. Both use the same chat completions endpoint format that has been consistent across all GPT models. The code below uses the Vercel AI Gateway with the $5 monthly free credit, but the same code works identically with a direct OpenAI API key — just swap the base_url parameter.
Installing and Configuring the SDK
First, install the OpenAI Python SDK if you have not already:
bashpip install openai
Then set your API key as an environment variable. For Vercel AI Gateway, you use your Vercel API key:
bashexport OPENAI_API_KEY="your-vercel-or-openai-api-key"
Making Your First GPT-5.4 API Call
pythonfrom openai import OpenAI client = OpenAI( api_key="your-vercel-api-key", base_url="https://ai-gateway.vercel.sh/v1" ) # For direct OpenAI API (swap base_url): # client = OpenAI(api_key="your-openai-api-key") response = client.chat.completions.create( model="gpt-5.4", messages=[ { "role": "system", "content": "You are a helpful assistant specializing in code review." }, { "role": "user", "content": "Review this Python function for bugs: def divide(a, b): return a/b" } ], max_tokens=500, temperature=0.3 ) print(response.choices[0].message.content) print(f"Tokens used - Input: {response.usage.prompt_tokens}, Output: {response.usage.completion_tokens}")
The same call using curl, which requires no SDK installation:
bashcurl https://ai-gateway.vercel.sh/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -d '{ "model": "gpt-5.4", "messages": [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "What are the key improvements in GPT-5.4 over GPT-5.2?"} ], "max_tokens": 300 }'
One detail worth noting: GPT-5.4's 1,050,000-token context window is available in the Codex environment for experimental use, but the standard API context window is 1,050,000 tokens as well, making it the largest context window of any general-purpose model available as of March 2026 (verified from the official OpenAI API docs). For most use cases, you will stay well within this limit, but it matters enormously for document processing pipelines where you are feeding entire codebases or lengthy reports into a single prompt.
Slash Your GPT-5.4 Costs by 90%: Prompt Caching Explained
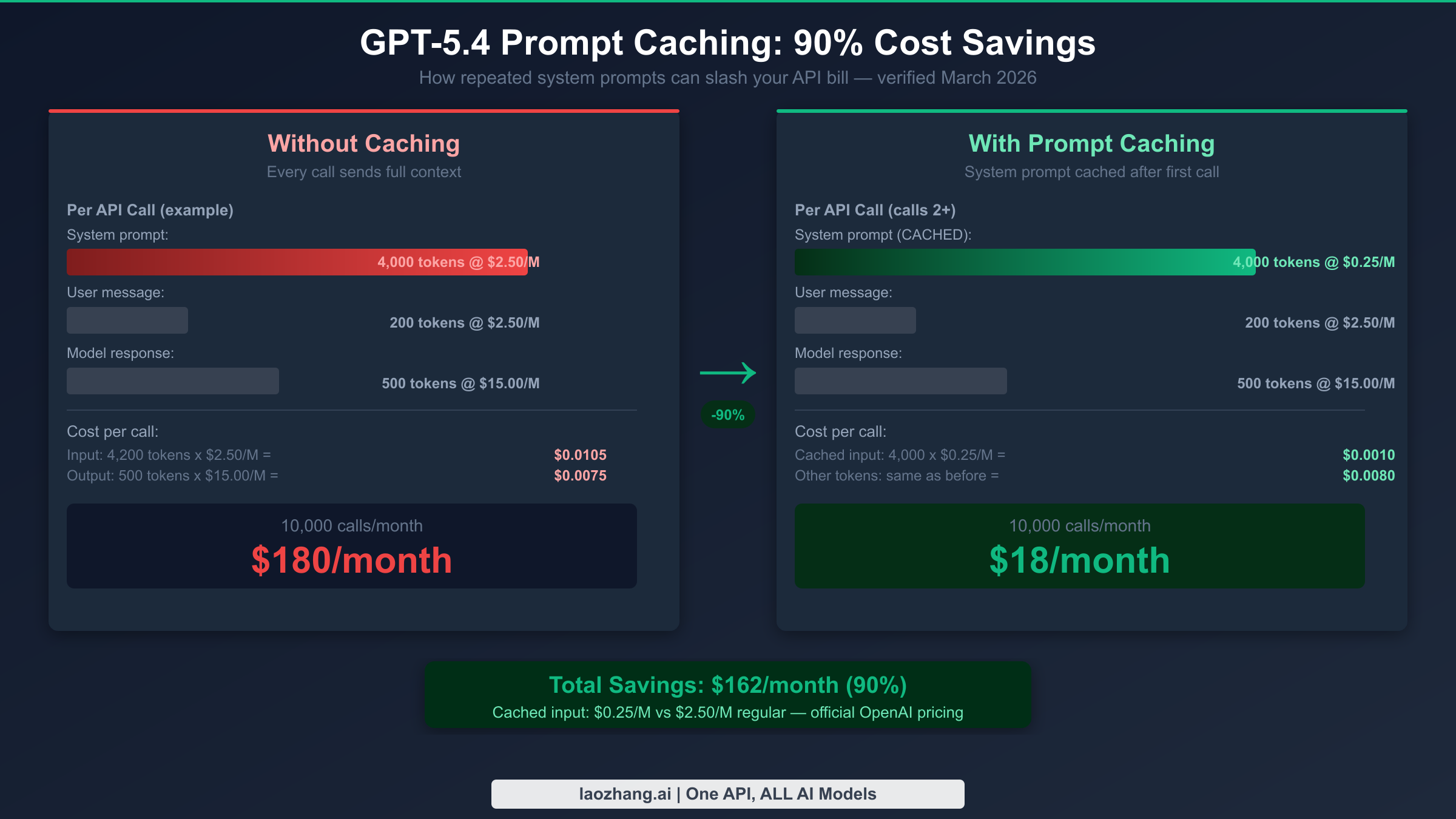
Prompt caching is the single most underutilized cost-reduction tool available to GPT-5.4 API users, and the pricing difference is substantial. Cached input tokens cost $0.25 per million rather than $2.50 per million — a 90% reduction for the portions of your prompt that repeat across calls. OpenAI's caching system automatically caches prefixes of prompts that exceed 1,024 tokens when the same prompt prefix appears in subsequent requests, so most applications with a fixed system prompt benefit from caching without any configuration changes.
The mechanics work like this: when you send a request with a system prompt of 4,000 tokens followed by a user message, OpenAI's infrastructure checks whether the first 1,024+ tokens of that prompt have been seen recently. If they have — which will be true for any application that uses a consistent system prompt — those cached tokens are billed at $0.25/M instead of $2.50/M. Only the new, uncached portions (the user message and any dynamic context) are billed at the full input rate. The cache has a maximum lifetime that resets during periods of low usage, so applications with steady traffic benefit more than those with sporadic call patterns.
Calculating Your Actual Caching Benefit
Here is a concrete example for an application making 10,000 API calls per month with a 4,000-token system prompt and an average 200-token user message:
Without caching, each call costs: (4,200 input tokens × $2.50/M) + (500 output tokens × $15.00/M) = $0.0105 + $0.0075 = $0.0180 per call, or $180 per month for 10,000 calls.
With caching (assuming 95% cache hit rate after warmup), each call costs: (4,000 cached tokens × $0.25/M) + (200 fresh input tokens × $2.50/M) + (500 output tokens × $15.00/M) = $0.0010 + $0.0005 + $0.0075 = $0.0090 per call, or approximately $90 per month. And in high-cache scenarios with longer system prompts, the savings push closer to the theoretical 90% reduction on the input side.
Enabling Explicit Caching in Your Code
While automatic caching handles most cases, you can explicitly mark prompt sections for caching using the cache_control parameter when working with the Responses API:
pythonfrom openai import OpenAI client = OpenAI() # Long system prompt that will be cached SYSTEM_PROMPT = """You are an expert financial analyst with deep knowledge of public market valuations, DCF modeling, and comparative company analysis. Your analysis should be data-driven, cite specific metrics, and flag uncertainty when relevant data is unavailable. [...additional context - total ~4000 tokens...]""" response = client.responses.create( model="gpt-5.4", input=[ { "role": "system", "content": [ { "type": "input_text", "text": SYSTEM_PROMPT, "cache_control": {"type": "ephemeral"} } ] }, { "role": "user", "content": "Analyze the valuation of Nvidia given current market conditions." } ] ) # Check how many tokens were served from cache print(f"Cached tokens: {response.usage.input_tokens_details.cached_tokens}") print(f"Fresh input tokens: {response.usage.input_tokens - response.usage.input_tokens_details.cached_tokens}")
The usage object in the response includes a breakdown showing how many tokens came from cache versus fresh processing, which lets you verify that caching is working as expected and calculate your actual savings per call.
What Does GPT-5.4 API Actually Cost? Real-World Scenarios
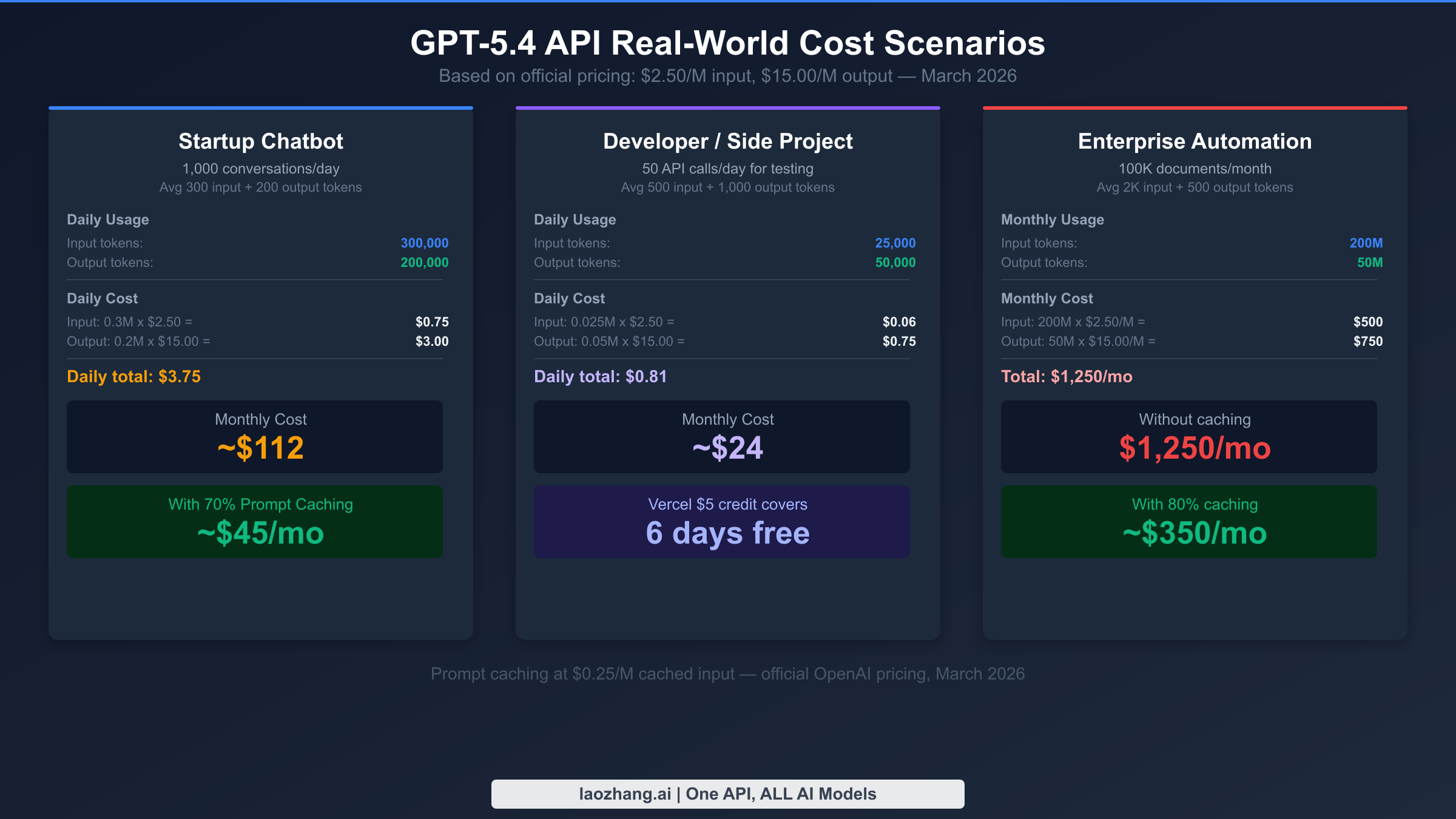
Abstract per-token pricing is difficult to reason about without grounding it in realistic workloads. The three scenarios below represent common developer use cases, using official OpenAI pricing as of March 2026: $2.50 per million input tokens, $0.25 per million cached input tokens, and $15.00 per million output tokens for gpt-5.4. The gpt-5.4-pro variant at $30/M input and $180/M output is excluded from these scenarios because it targets enterprise automation workloads, not the developer-scale use cases this article primarily addresses.
Scenario 1: Startup customer support chatbot. A startup running 1,000 customer conversations per day with an average of 300 input tokens and 200 output tokens per exchange spends approximately $3.75 per day without prompt caching — the system prompt accounts for most of the input token count. With a 4,000-token system prompt cached at 70% hit rate, that drops to roughly $1.50 per day, or $45 per month. This is the scenario where the Vercel $5 monthly credit makes the most sense as a starting point: it covers roughly three days of this traffic level before you need to add payment.
Scenario 2: Developer building a coding assistant. A solo developer running 50 API calls per day for a personal coding tool, averaging 500 input tokens and 1,000 output tokens per call, spends about $0.81 per day or $24 per month. The output token count is high because coding responses tend to be verbose — generating full function implementations, explaining reasoning, and including usage examples. At this scale, the Vercel free credit covers approximately six days of usage per month, and even without caching, $24/month is manageable for a serious side project. Adding prompt caching for a fixed system prompt describing the coding context typically brings this to $12–$15/month.
Scenario 3: Enterprise document processing pipeline. A business processing 100,000 documents per month with 2,000 input tokens and 500 output tokens per document faces a very different cost picture. Without caching, input costs alone reach $500/month (200M tokens × $2.50/M), with output adding $750/month (50M tokens × $15.00/M), for a total of $1,250 per month. With aggressive prompt caching — achievable when the document classification system prompt is consistent across all 100,000 documents — input costs drop to around $100/month, bringing the total to approximately $350/month. At this scale, switching to gpt-5.4-pro for the highest accuracy requirements would cost $6,500+/month, which is why tiered model selection (see the next section) becomes critical.
These scenarios illustrate something important: GPT-5.4's pricing is actually competitive when you factor in its efficiency gains. The model uses up to 47% fewer tokens than its predecessors on certain task types (per OpenAI's benchmarks from the March 5, 2026 announcement), meaning the same output requires less input in many common cases. For complex reasoning tasks where GPT-5.2 needed multiple long prompts to converge on an answer, GPT-5.4 often reaches the same result in fewer turns — which directly reduces your API spend per successful task completion.
GPT-5.4 vs GPT-5.3 vs GPT-5.2: Which Should You Call?
Choosing the right model matters both for cost and for output quality, and the GPT-5 family now spans a range from fast and cheap to maximally capable. As of March 2026, OpenAI offers three primary models with different capability and cost profiles, plus several specialized variants. Making the wrong choice — using GPT-5.4 when GPT-5.3 Instant would suffice, or using GPT-5.3 when a task genuinely requires GPT-5.4's reasoning — is one of the most common ways developers waste API budget.
| Model | API ID | Input | Output | Context | Best For |
|---|---|---|---|---|---|
| GPT-5.3 Instant | gpt-5.3-instant | ~$0.30/M | ~$1.20/M | 400K | Real-time chat, simple Q&A |
| GPT-5.2 Thinking | gpt-5.2 | $1.75/M | $14.00/M | 256K | Research, analysis, coding |
| GPT-5.4 | gpt-5.4 | $2.50/M | $15.00/M | 1.05M | Complex multi-step tasks |
| GPT-5.4 Pro | gpt-5.4-pro | $30.00/M | $180.00/M | 1.05M | Enterprise critical workflows |
The key differentiator between GPT-5.3 Instant and GPT-5.4 is not just performance — it is the nature of the task. GPT-5.3 Instant handles high-volume, lower-complexity tasks at a fraction of the cost and with faster response times. For a customer-facing chatbot that answers FAQ-style questions, routes support tickets, or provides simple product recommendations, GPT-5.3 Instant will deliver better economics with acceptable quality. GPT-5.4 begins to justify its price premium when tasks require multi-step reasoning across long documents, complex code generation that integrates multiple files, or agentic workflows where the model needs to plan and execute a sequence of actions.
For context on how GPT-5.4 compares to competing models: how GPT-5.4 compares to other major AI APIs, including Gemini 3.1 Pro and Claude Opus 4.6 at $5/M input and $25/M output. GPT-5.4 at $2.50/M input is meaningfully cheaper than Claude Opus 4.6 on input while offering comparable or superior performance on many professional benchmarks according to the data released at launch. The right model ultimately depends on your specific task profile, but the price-performance positioning of gpt-5.4 makes it a strong default choice for complex tasks that previously required the most expensive models from any provider.
A practical rule of thumb for model selection in production systems: use GPT-5.3 Instant for any task that a capable human assistant could handle in under 30 seconds with no specialized knowledge, use gpt-5.4 for tasks that require sustained reasoning or integration of multiple information sources, and reserve gpt-5.4-pro for tasks where accuracy is so critical that a 10x cost premium is justified by the business value of getting it right.
GPT-5.4 Computer Use API: What Developers Should Know
GPT-5.4 is the first general-purpose model released with native, state-of-the-art computer-use capabilities, which allows the model to operate a computer interface through mouse clicks, keyboard inputs, and screen reading. This is not a minor feature addition — it represents a fundamentally different class of automation that was previously only available through specialized models like Claude's computer use capability or purpose-built RPA tools. GPT-5.4 scored 75.0% on the OSWorld Verified benchmark for computer use tasks, compared to GPT-5.2's 47.3%, and this improvement enables new categories of automated workflows that were previously too error-prone to deploy reliably.
For developers, the computer use capability is accessed through the computer_use_preview tool in the Responses API. The model can take screenshots, identify UI elements, click buttons, type text, and navigate between applications — all through programmatic control rather than traditional UI automation frameworks that depend on element locators or DOM selectors. This makes GPT-5.4 computer use significantly more resilient to UI changes than traditional automation, because the model interprets the visual state of the screen rather than depending on stable HTML structure or accessibility tree identifiers.
The practical implications for developers are significant: document processing workflows that previously required custom OCR + structured extraction pipelines can now be handled through screen-based interaction; legacy software without APIs can be integrated into modern workflows by having GPT-5.4 operate the GUI directly; and multi-application data entry tasks that previously required human operators become automatable at API cost rates. OpenAI has recommended that developers start with lower-stakes automation tasks and validate the model's decision-making before deploying it to workflows with significant downstream consequences. The computer use API endpoint and detailed implementation documentation are available in the official OpenAI developer portal.
FAQ: GPT-5.4 API Access, Limits, and Common Questions
Does OpenAI offer a free trial for GPT-5.4? No. OpenAI discontinued automatic free credits for new API accounts in 2025 and has not reinstated them for GPT-5.4. New API accounts require payment setup before making any calls. The most practical alternative for zero-cost API testing is the Vercel AI Gateway's $5 monthly free credit, which provides approximately 2 million GPT-5.4 input tokens per month.
What is the rate limit for GPT-5.4 on a new (Tier 1) account? New OpenAI accounts start at Tier 1 with a limit of 500 requests per minute and 500,000 tokens per minute for gpt-5.4. This is sufficient for development and testing but may become a bottleneck for production workloads. Accounts automatically advance to higher tiers based on API spend history, with Tier 5 allowing 15,000 RPM and 40 million TPM.
Can I use the existing openai Python SDK with GPT-5.4, or do I need to update anything? GPT-5.4 uses the same API format as all previous GPT models and requires no SDK updates. Set model="gpt-5.4" in your existing code and it will work immediately. If you are coming from GPT-5.2 or GPT-5.3, the response format, tool calling syntax, and streaming API are all identical.
What happens when I exceed the Vercel AI Gateway's $5 monthly free credit? Once the $5 credit is exhausted, additional API calls are billed to your payment method on file, or calls fail if no payment method is configured. The credit resets monthly, so it is genuinely renewable free access as long as your monthly usage stays within the $5 threshold.
Is GPT-5.4 available through Microsoft Azure OpenAI Service? As of March 6, 2026, GPT-5.4 availability on Azure OpenAI Service has not been officially announced. Microsoft typically announces Azure availability for major OpenAI models within weeks to months of the OpenAI.com release. Enterprise customers with Azure commitments should check the Azure OpenAI model availability documentation for the most current status, as this will change rapidly.
Summary: Getting Started with GPT-5.4 Today
GPT-5.4 is a meaningfully better model than its predecessors for complex, multi-step professional work, and its pricing at $2.50/M input is competitive with alternatives when you account for its efficiency gains. The absence of a free tier is a genuine obstacle for developers who want to evaluate it before spending, but the five access pathways in this guide provide real options at every budget level — from zero cost through third-party gateway credits to full-scale production access through the direct OpenAI API.
The decision tree is straightforward: if you need to explore GPT-5.4 capabilities without any budget, use the Vercel AI Gateway free credit ($5/month) to get a real API key and make real calls. If you are building a production application, start with prompt caching enabled from day one — the 90% reduction in cached input token costs is not a premature optimization, it is the correct baseline for any application with a fixed system prompt. If your use case does not actually require GPT-5.4's reasoning depth, gpt-5.4-mini or gpt-5.3-instant will serve you better at a fraction of the cost. And if you need the maximum available performance without rate limit concerns and with stable access across regions, an OpenAI-compatible API relay service like laozhang.ai (docs: docs.laozhang.ai) can provide production-ready GPT-5.4 access with flexible billing.
The most important first step is making that first API call. Once you see GPT-5.4's responses for your specific use case, you will have the data you need to decide whether the capability justifies the cost at your expected scale — and with the free credit options available, that first call should not cost you anything.