If your Claude API request returns API Error: 500 with api_error and Internal server error, the real branch behind "Claude API error 500" is a returned server-side API error first, not proof that your API key, billing, prompt, or account is broken.
Your first minute should stay small: check current Claude Status, retry only with a capped jittered budget, keep the same model, endpoint, auth route, and request shape stable, and preserve request_id or request-id before changing anything else.
Status is a dated signal. This refresh checked Claude Status at 2026-05-03T11:23Z and the public status API reported All Systems Operational. A green page narrows the live-incident branch, but it does not prove your exact model, account route, SDK, gateway, or request shape has recovered.
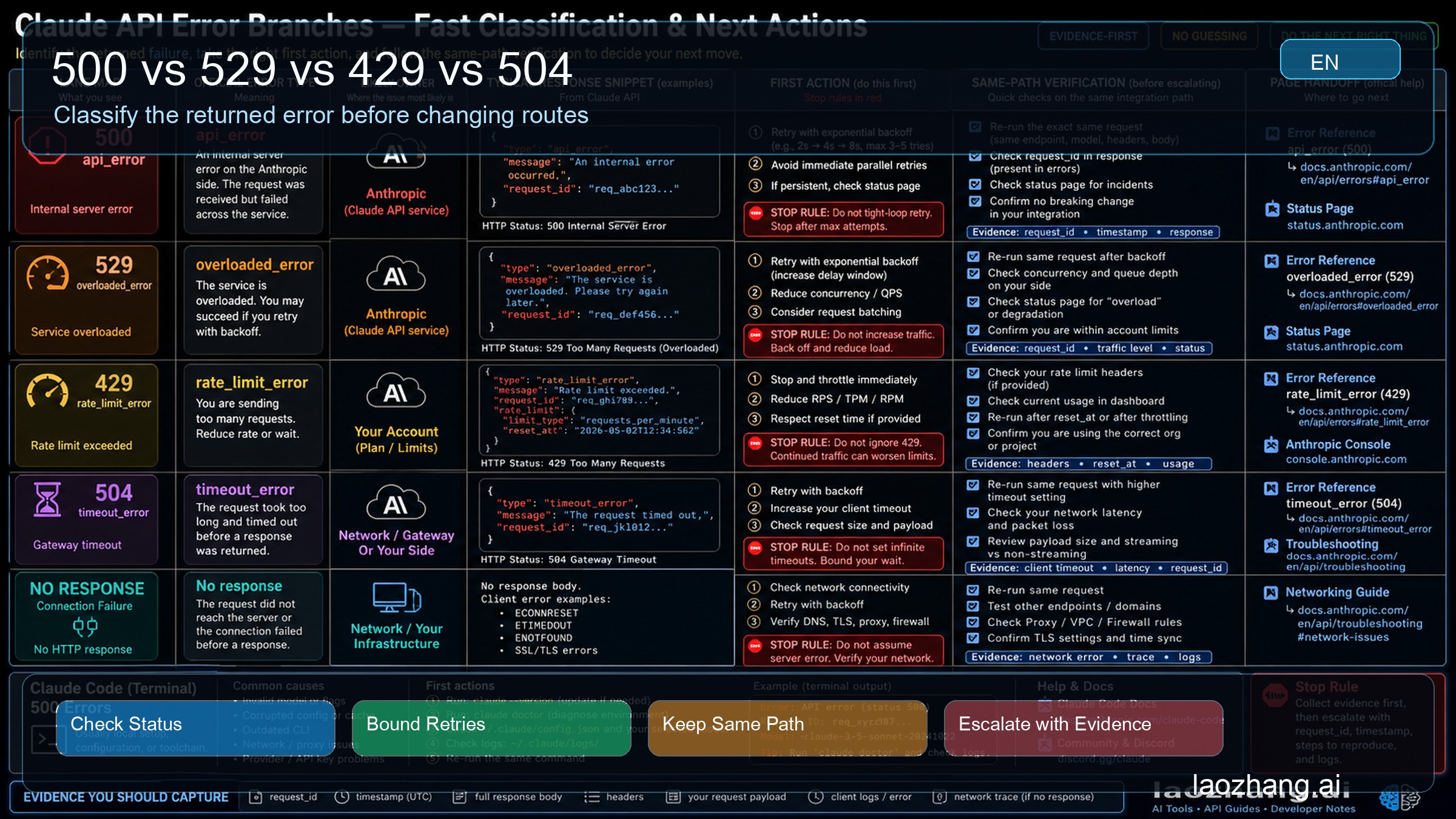
60-Second Branch Board
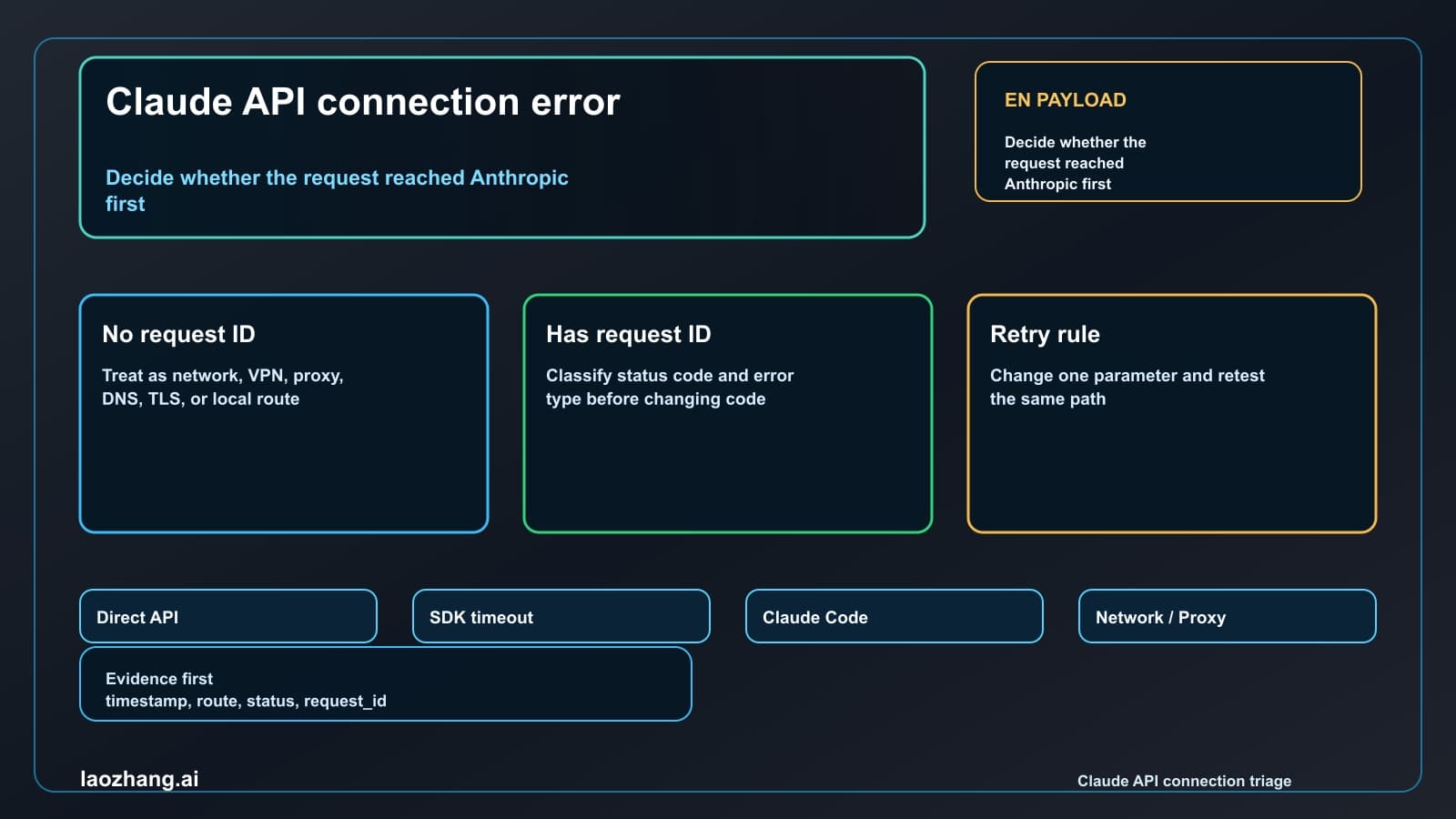
Use this board before you rotate keys, rewrite prompts, change billing, or switch providers. A returned error object means the request reached an API layer. That makes it different from a connection failure where no HTTP response, body, or request ID came back.
| Exact signal | Treat it as | First move | Same-path verification | Better next branch |
|---|---|---|---|---|
500, api_error, Internal server error | Returned Claude API server-side error | Check live status, capture request_id, retry with a short capped budget | Same model, endpoint, auth route, and request shape | Continue the 500 branch |
529, overloaded_error | Capacity overload | Check status, add jitter, reduce pressure | Same path after cool-down and pressure reduction | Claude API 529 overloaded error |
429, rate_limit_error | Rate limit, acceleration, quota, or route-owner ceiling | Inspect limit headers and active credential route | Retry only after the allowed window or route correction | Claude API rate-limit reached |
504, timeout_error | Timeout or long-running request branch | Stream, shorten, split, or move long work into batches | Same task after one intentional shape change | Stay in timeout handling before changing auth |
No status, no body, no request-id | Connection-layer failure | Test network, VPN, proxy, firewall, DNS, TLS, SDK timeout, and route | Same payload after changing one network variable | Claude API connection error |
Claude Code terminal shows API Error: 500 | Claude Code surface over the API | Check /status, login/session state, auth owner, and route | Same terminal path after one branch-specific fix | Claude Code API Error 500 |
| Gateway or provider route returns 500 | Route-owner or compatibility branch | Compare direct Anthropic and gateway path without changing prompt | Same prompt, model intent, timeout, and input size | Use route comparison, not blind switching |
The useful answer is narrow: a clean Claude API Internal Server Error belongs to the 500 api_error branch. It can be transient. It can also persist on one route, model, or request shape. Your job is to preserve enough evidence to tell the difference.
What 500 api_error Means in the Claude API
Anthropic's API error reference defines HTTP 500 as api_error. The same reference separates 429 rate_limit_error, 504 timeout_error, and 529 overloaded_error, and says error responses include error.type, error.message, and request_id. It also notes that every API response includes a request-id header.
That official taxonomy gives you the recovery boundary. A returned 500 api_error is an unexpected internal API failure, not a normal account-state message. Do not treat it as proof that your prompt is invalid, your billing is empty, your key is expired, or your local browser cache is broken. Those branches have their own signals. If the API already returned api_error, start from server-side error handling and evidence capture.
The request_id boundary is more important than it looks. A screenshot of "Internal server error" is useful for a human, but the request identifier is what lets support or your internal platform team trace one failed API call. If your SDK exposes response headers, capture request-id. If the JSON body includes request_id, capture it. If neither exists, you may not be in the returned-error branch at all, and the connection guide is a better path.
Keep 500 separate from 529. Both can feel like Anthropic-side trouble because both can block a working integration without a local code change. But they imply different client behavior. A 529 branch asks you to reduce pressure and avoid retry storms during overload. A 500 branch asks you to confirm live status, retry briefly, preserve identifiers, and escalate if the same path keeps returning a server error after a small budget.
Keep 500 separate from 504 too. A 504 points toward timeout behavior. Anthropic's API reference warns that long requests can hit network timeouts or idle drops and suggests streaming or Message Batches for long-running work. If the exact response is timeout_error, do not keep calling it an Internal Server Error. Change the request shape intentionally, then verify.
Safe Recovery Loop
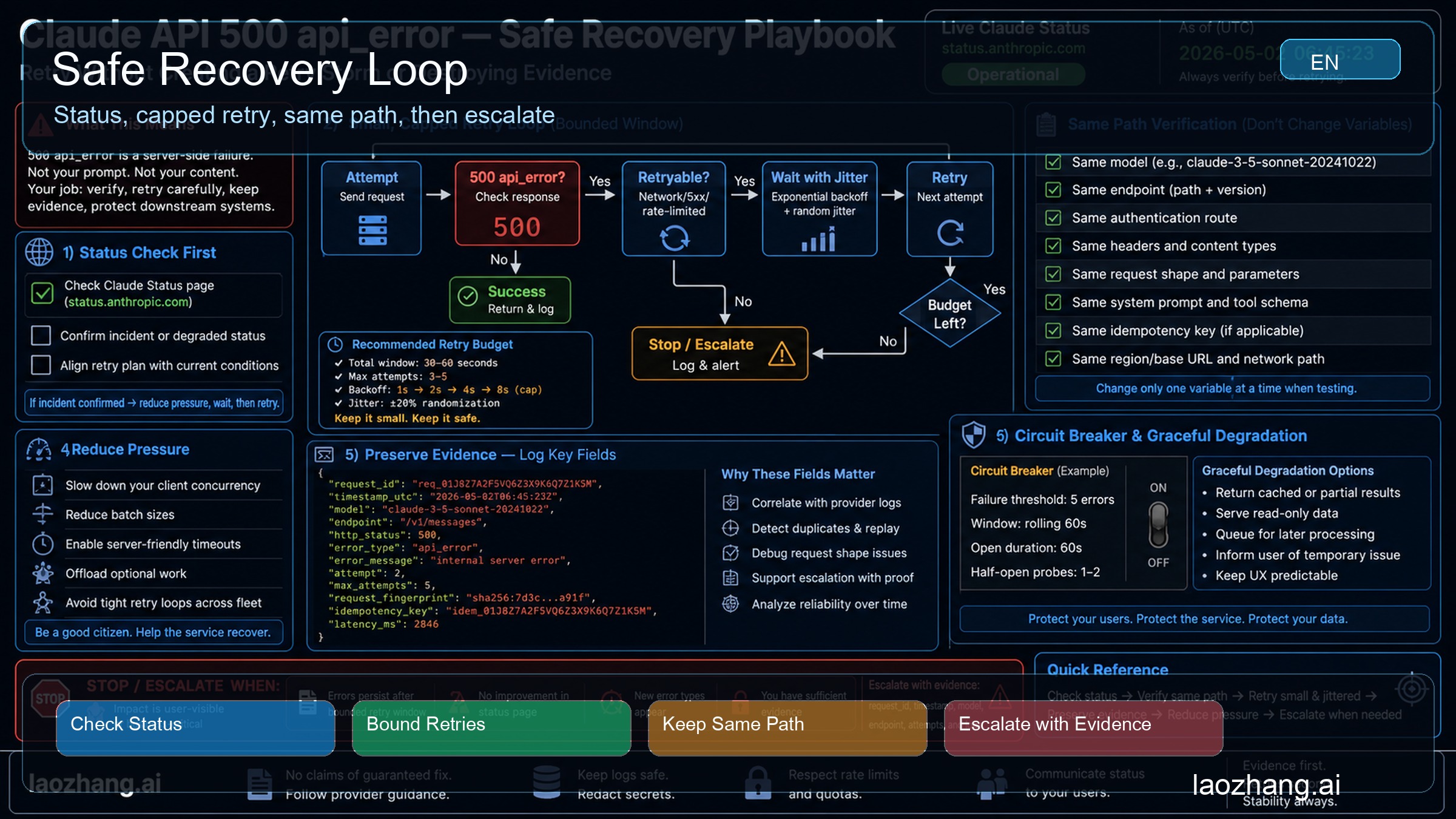
A good Claude API 500 recovery loop is intentionally boring:
- Check current Claude Status and write down the timestamp.
- Preserve the full error body and
request_idorrequest-id. - Retry with a capped jittered budget only if the work is safe to repeat.
- Keep model, endpoint, auth route, SDK or gateway path, and request shape stable.
- Stop changing variables when the same path still returns 500 after the budget.
- Escalate with a compact evidence packet.
The first check is status, not code surgery. If Claude Status has an active API incident, stop changing local variables and wait for the incident to clear. Then retry the same path that failed. The same-path retry tells you whether the incident was the whole story. If you changed model, prompt, key, gateway, and timeout during the incident, you lost that clean comparison.
If status is green, use a small retry budget. "Small" depends on the job. A user-facing chat turn may deserve one or two retries over a few seconds. A background batch can wait longer. A side-effecting workflow may need de-duplication before any retry is safe. The point is not a universal attempt count. The point is that the retry policy should have a cap, jitter, and a stop condition.
Then verify on the same path. Same model. Same endpoint. Same auth owner. Same request body. Same SDK or gateway route. Same network path if you can keep it fixed. If the same path succeeds after a short pause, you likely hit a transient API error. If the same path keeps returning 500 api_error, you have a stronger escalation case. If it only succeeds after you changed five variables, you do not know what fixed it.
Do not turn a 500 into a provider-shopping exercise too early. A gateway can be useful for isolation when production needs a degraded route, but switching routes changes the evidence. Use it as an explicit comparison only after you have preserved the original failure.
Production Controls for Repeated 500s
Manual triage helps once. Production controls keep the same branch discipline during a spike.
Use a retry budget instead of open-ended retries. Cap attempts, cap elapsed time, and include jitter. Log the retry count and final outcome. The service should be able to answer whether the first failure was recovered by retry or whether the same path kept failing.
Separate idempotent and non-idempotent work. A read-only classification call, a deterministic internal batch item, and a user-visible purchase-related action should not share the same retry policy. If the API call is part of a workflow with side effects, add caller-side de-duplication before retrying. A server error does not always tell you whether downstream work happened.
Add a circuit breaker for repeated 500 api_error on the same route. If the error rate crosses your threshold, pause non-urgent work, queue background jobs, or show a degraded user-facing state. Probe recovery with a small same-path request before reopening the path fully. This prevents one incident from turning into a retry storm.
Make logs branch-aware. At minimum, capture HTTP status, error.type, error.message, request_id or request-id, model, endpoint, SDK version, auth route, gateway route if any, request size class, retry count, and timestamp. Do not log secrets or full private prompts. You need enough to route the failure, not enough to leak user data.
Treat model switching as a product decision, not a first diagnostic move. If one model-specific path is failing and another route is acceptable for the user job, a temporary fallback can be reasonable. But label it as degraded-mode routing. Keep the original 500 api_error evidence so you can tell whether the model path recovered later.
Surface and Route Split
The phrase "Claude API Internal Server Error" often appears in mixed environments. The first-screen branch board is there because direct API, Claude Code, SDK, gateway, timeout, and no-response connection failures can all look similar when a reader is under pressure.
If the visible surface is Claude Code, route it differently. Claude Code calls the Claude API, but the terminal adds login state, resumed sessions, OAuth versus API-key ownership, shell environment variables, proxies, and command-level diagnostics. The Claude Code API Error 500 guide is the better fit when the terminal is the product surface. For mixed Claude Code 500, 529, and 429 symptoms, use the broader Claude Code 500, 529, and rate-limit router.
If the visible surface is an SDK exception, inspect whether it is a returned API status or a connection exception. A returned APIStatusError style object with status 500 and headers belongs here. An APIConnectionError style failure with no HTTP status belongs to the no-response branch. That is why the Claude API connection error guide starts with the request-ID boundary.
If the visible surface is a gateway or provider route, compare rather than guess. Run the same prompt, model intent, input size, timeout class, and environment on direct Anthropic if you have access. Then run the gateway route. If direct succeeds and the gateway fails, the branch may be route mapping, provider capacity, credential ownership, proxy behavior, or compatibility. If both fail with the same returned 500, you have a broader signal, but you still need request identifiers from the original path.
If the exact error changes, change branches. 529 overloaded_error belongs to overload recovery. 429 rate_limit_error belongs to limits and credential-route diagnosis. 504 timeout_error belongs to duration and request-shape recovery. A no-response failure belongs to network, proxy, TLS, SDK timeout, or route-owner diagnosis. Keeping those exits explicit prevents one generic "try again later" answer from failing every real operator.
Escalation Packet
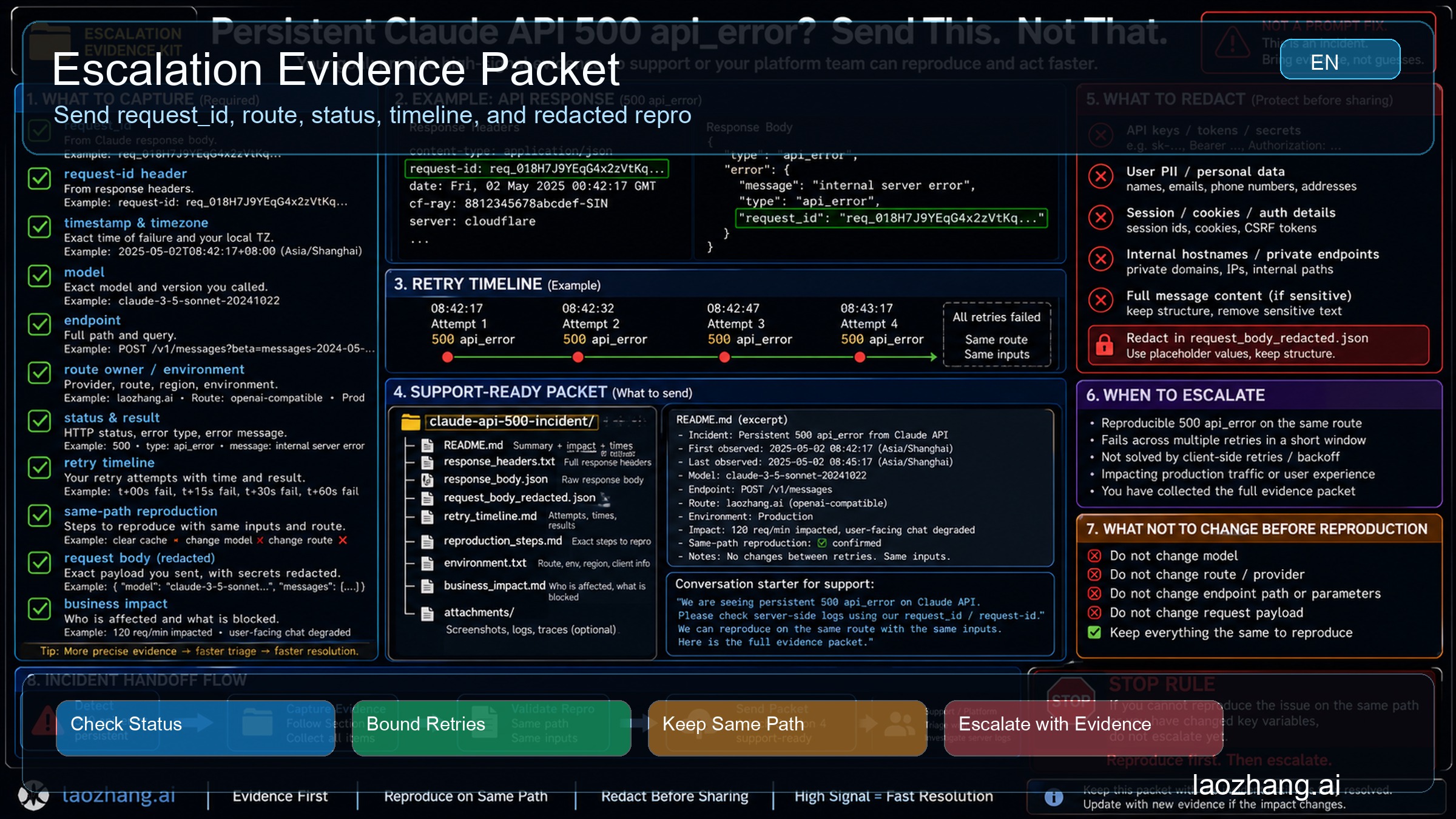
Escalate after the small loop is complete: current status checked, request evidence captured, retry stayed bounded, and the same path still returns 500 api_error. At that point, more random changes usually lower evidence quality.
Send a compact packet:
- exact HTTP status and error type, including
500 api_error - full error body with
request_id, or response headerrequest-id - timestamp and timezone for each failed attempt
- model, endpoint, SDK, SDK version, and runtime
- direct Anthropic, gateway, proxy, or provider route owner
- auth owner, without exposing secrets
- request size class and whether the request was streaming
- retry count, backoff window, jitter behavior, and final result
- Claude Status result at the time and any relevant incident link
- smallest redacted reproduction shape
- business impact in one sentence
Keep secrets out. Do not paste API keys, raw customer data, private prompts, full proxy logs, or unredacted environment dumps. The packet should prove the branch and give support enough trace handles. It should not become a data spill.
Escalation is also where same-path discipline pays off. "500 happened, then I changed providers and it went away" is weak evidence. "Status green at 2026-05-02T13:51Z, same model and endpoint returned 500 api_error three times over a 40-second jittered budget, request IDs attached" is actionable.
FAQ
Is Claude API Internal Server Error the same as 529 overload?
No. Anthropic defines HTTP 500 as api_error and 529 as overloaded_error. A clean 500 belongs to returned server-side error handling. A clean 529 belongs to overload-aware recovery, pressure reduction, and retry-storm prevention.
Does a green Claude Status page prove the problem is local?
No. A green page is a timestamped signal for public components. It narrows the active-incident branch, but it does not prove your exact model, endpoint, account route, region, SDK, gateway, or request shape has recovered. Keep checking live status and preserve same-path evidence.
Should I rotate my API key first?
No. Key rotation is a weak first move for a returned 500 api_error. Rotate or replace credentials only when the evidence points to auth, key ownership, leakage, or route mismatch. A clean 500 does not make billing, key age, or account state the default owner.
How many retries are safe?
Use a budget rather than a universal number. Cap attempts or elapsed time, add jitter, and retry only work that is safe to repeat. One user-facing request may deserve a shorter budget than a background batch. Side-effecting work needs de-duplication before retry.
What if the error happens in Claude Code?
Use the Claude Code branch. Claude Code can add login state, resumed-session state, OAuth versus API-key routing, shell proxy variables, and command diagnostics. Start with /status and the Claude Code API Error 500 guide instead of treating the terminal as a plain SDK call.
What should I send to Anthropic support?
Send the status code, error.type, error.message, request_id or request-id, timestamp, model, endpoint, SDK version, route owner, retry timeline, status result, and a redacted reproduction. Keep it short enough that the 500 api_error branch is obvious.
Working Rule
Claude API Internal Server Error is a 500 api_error recovery branch, not a reason to panic-change keys, billing, prompts, or providers. Check live status, preserve request identifiers, retry with a capped jittered budget, verify the same path, and escalate only when the same path still fails with clean evidence.