If your Claude API request returns 529 overloaded_error, treat it as Anthropic-side overload first, not as proof that your key, account, billing, or quota is broken. The nearby trap is 429 rate_limit_error: 429 is the rate-limit branch, while 529 is the capacity branch.
Your first minute should be small and ordered: check Claude Status with a timestamp, run a bounded retry with jitter, reduce traffic pressure if you control the caller, and verify the same model, route, auth path, and request shape before changing anything else. If the same path still returns 529 after that, escalate with the exact error body and request_id.
Status is only a timestamped signal. At 2026-04-29 11:02 UTC, the public status API reported all systems operational, while the incident feed still showed recently resolved elevated-error events on April 28 and April 29 UTC. That means a green page can narrow the branch, but it does not prove your exact path has recovered.
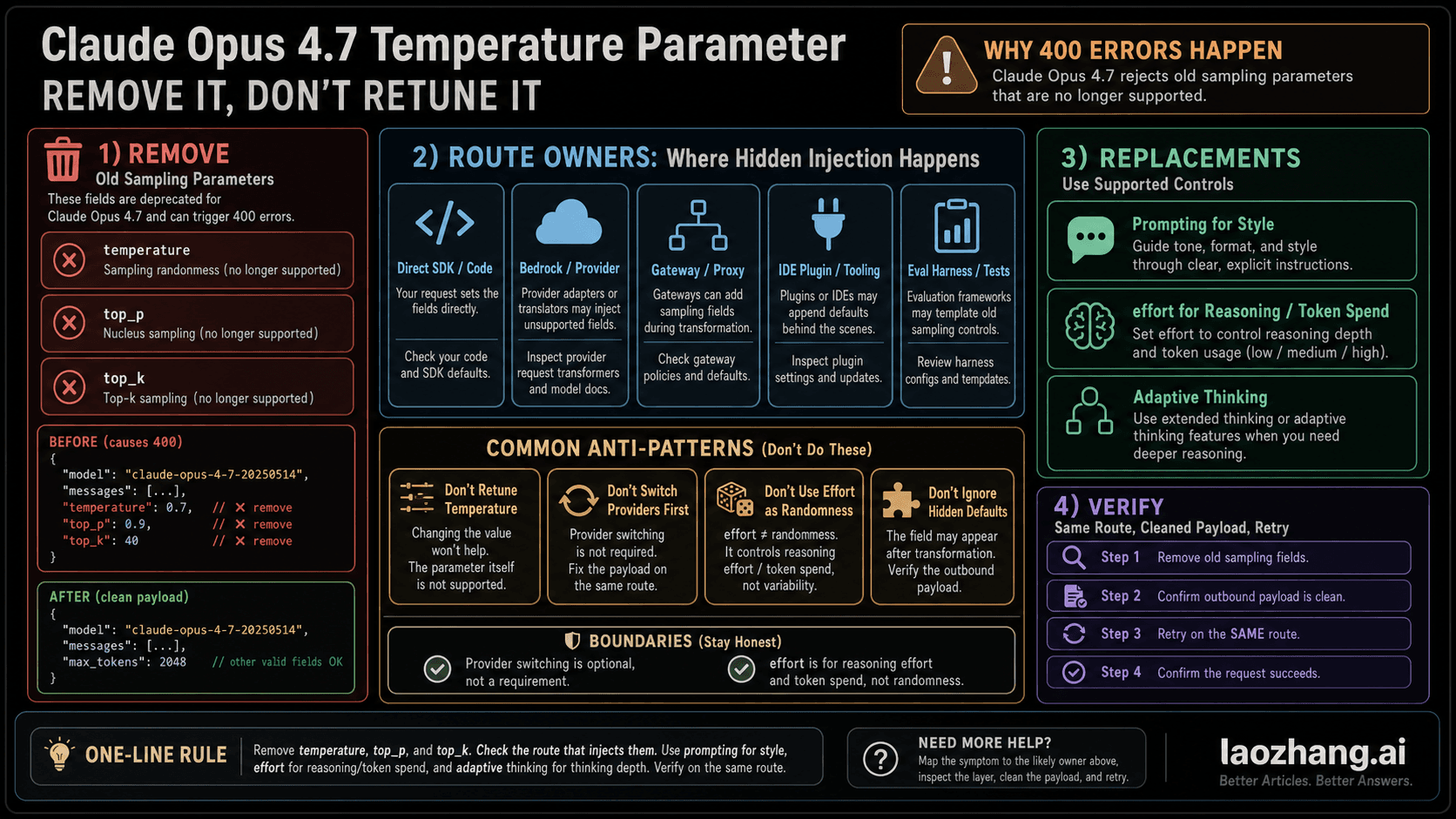
60-Second Route Board
Use this table before you touch keys, billing, model settings, or provider routes.
| Exact signal | Treat it as | First move | Same-path verification | Stop or escalate when |
|---|---|---|---|---|
529 or overloaded_error | Anthropic capacity overload | Check live status, then retry with capped jitter | Same model, endpoint, auth route, and request shape | It persists after status check, retry budget, and pressure reduction |
429 or rate_limit_error | Rate limit or quota branch | Inspect retry-after, limits, and active credential route | Retry only after the allowed window or route correction | Headers and Console state still point to exhausted limits |
500 or api_error | Server-side error branch | Check status, keep request evidence, retry once with budget | Same request after a short pause | No incident is posted and repeated same-path failure continues |
504 or timeout_error | Timeout branch | Reduce request duration, stream, or split work | Same task after one intentional shape change | Long request still times out after the shape change |
| Claude Code terminal shows repeated 529 | Claude Code overload surface | Use the Claude Code branch guide after API-level meaning is clear | Same session and route after cool-down | The terminal symptom persists after status and route checks |
That is the working answer: 529 is overload first. Do not start with key rotation, plan upgrades, or random prompt rewrites unless the exact response changes to a branch that justifies those moves.
What 529 Means in the Claude API

Anthropic's API error documentation defines 529 as overloaded_error. The same table separates 429 rate_limit_error, 500 api_error, and 504 timeout_error. Use that official split as the recovery boundary.
The important recovery difference is ownership. A true 529 says the service is overloaded or at capacity. Your code may still need to behave better during that condition, but the first interpretation is not "my account is out of quota." By contrast, a true 429 points toward request rate, acceleration limits, model limits, or account/provider ceilings. A 500 points toward server error handling and evidence capture. A 504 points toward request duration and shape.
Most bad 529 fixes come from collapsing those branches. Developers see a blocked request and jump to the most familiar blocked-request fix: slow down as if it were 429, rotate a key as if auth were broken, or switch providers as if route ownership were already proven. Those moves can be useful in other branches. They are not the first move for a clean 529.
Also keep the request_id boundary visible. Anthropic's API docs say error responses include a request_id, and response headers may include request-id. When 529 persists, that identifier is more useful than a long narrative about everything you changed locally.
The Safe Recovery Loop
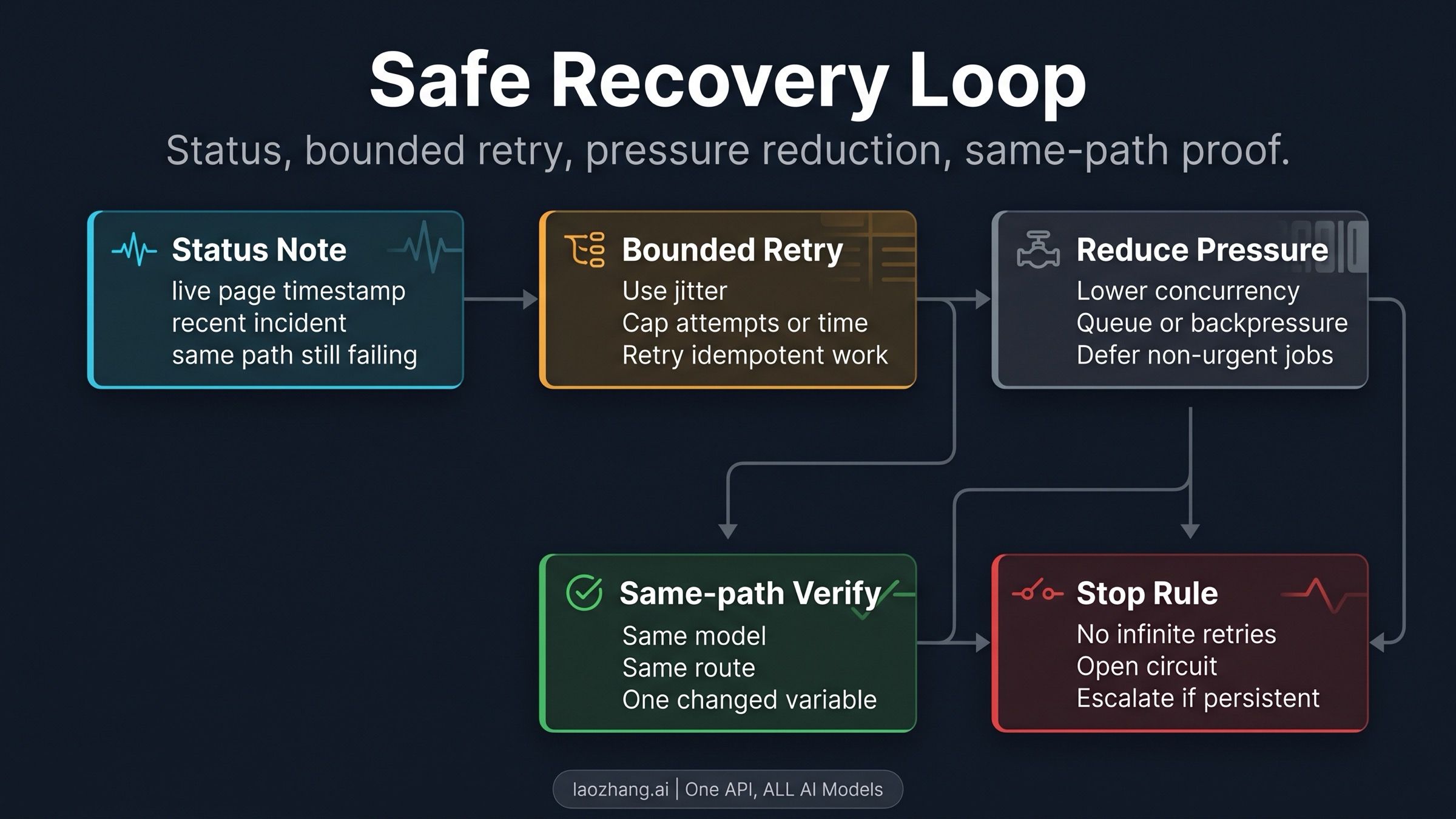
A production-grade 529 handler should be boring. It should confirm status, retry briefly, reduce pressure, verify the same path, then stop or escalate. The goal is not to make the client "try harder." The goal is to avoid making an overload event worse while preserving enough evidence to prove what happened.
Start with a live status check. Record the page result and time in UTC or your operating timezone. If there is an active incident, do not create noise by changing unrelated local variables. Hold the failing request shape, pause, and retry after the incident or degradation improves.
If status is green or there is no posted incident, use a bounded retry budget. A reasonable implementation uses exponential backoff with jitter, caps either attempts or total elapsed time, and retries only requests that are safe to retry. Idempotent reads and generation attempts with a clean caller-side de-duplication strategy are easier to retry than side-effecting workflows.
Then reduce caller pressure. Lower concurrency, pause non-urgent batch jobs, add queue backpressure, or switch a non-critical user flow into a degraded mode. This is not because 529 is your fault. It is because every client that retries aggressively during provider overload adds pressure to the same constrained system.
Finally, verify on the same path. Keep the model, route, auth owner, endpoint, region or proxy path, and request shape stable unless one of those variables is the intentional recovery step. If you change five variables and the next call succeeds, you no longer know whether overload cleared, route changed, or the request simply became easier.
Production Controls for Repeated 529
The manual playbook above is the human version. Your service should automate the same discipline.
Use a retry budget, not infinite retries. Cap attempts, cap elapsed time, and stop retrying after the caller-side value of the request has expired. A chat turn, background batch, and transactional workflow should not share the same retry policy.
Add jitter. Fixed retry intervals synchronize traffic, which is exactly what an overloaded API does not need. Jitter spreads requests and makes recovery less spiky.
Install a circuit breaker around repeated 529 responses. If the error rate crosses your threshold, open the breaker, queue non-urgent work, degrade optional features, and show a clear user-facing message. Close the breaker only after a small same-path probe succeeds.
Separate "reduce pressure" from "change route." Reducing pressure means fewer concurrent calls, smaller batch windows, or deferred jobs. Changing route means a different model, endpoint, provider, or auth owner. Route changes are valid when the workload can tolerate them, but they should be explicit because they change your evidence trail and sometimes your product behavior.
Keep observability simple: error type, HTTP status, model, endpoint, auth route, request size class, retry count, final outcome, and request_id when present. Those fields are enough to answer the question that matters during a 529 spike: did the same path recover after the retry budget, or is this still a provider-side overload case?
When Claude Code Is the Surface
Start with the API-level meaning of 529 overloaded_error. If the symptom is inside Claude Code, the API meaning still matters, but the terminal surface adds its own branch rules.
Claude Code documentation describes repeated 529 as temporary capacity across users, says Claude Code already retried before showing the message, and separates it from usage-limit or quota wording. That is why the deeper terminal-focused handoff is the Claude Code overloaded error guide, not a generic billing or plan page.
If the terminal line mixes 500, 529, 429, temporary limiting, or route confusion, use the broader Claude Code 500 vs 529 vs rate limit router. That guide is intentionally broader because the terminal wording can collapse several branches into one stressful moment.
API teams still need one warning from the Claude Code world: route ownership can be surprising. A shell environment variable, proxy, or provider wrapper can make a request take a path you did not mean to test. If a 529 appears only on one wrapper path, compare the same request on the intended route before you conclude that the whole Claude API surface is failing.
Escalation Packet

Escalation starts after you have done the small, ordered recovery path. That means current status is recorded, retry stayed bounded, pressure was reduced where possible, and the same path still returns 529.
Send a compact packet:
- exact HTTP status and error type, including
529 overloaded_error - full error body with
request_idwhen present - model, endpoint, SDK or gateway route, and auth owner
- timestamped Claude Status result and any relevant recent incident note
- retry count, backoff window, and whether jitter was used
- concurrency or batch pressure at the time of failure
- minimal reproduction request shape, with secrets removed
- business impact in one sentence, such as blocked production job, degraded user flow, or non-urgent batch delay
That packet is short on purpose. Support does not need every local experiment. They need proof that the exact branch is 529, that the client did not create an unbounded retry storm, and that the same path still failed after reasonable recovery controls.
The escalation boundary is equally short: if you have a clean 529, current status evidence, a bounded retry result, pressure-reduction evidence, and the same-path failure still persists, stop improvising. Further random changes usually destroy the evidence you just worked to create.
FAQ
Is Claude API 529 the same as 429?
No. Anthropic defines 529 as overloaded_error and 429 as rate_limit_error. A true 529 is overload first. A true 429 belongs to the rate-limit branch.
Does a 529 mean my account or billing is broken?
Not as the first interpretation. A clean 529 overloaded_error points to capacity overload. Billing, key, or quota investigation becomes relevant only if the exact error changes, the route is not what you expected, or another signal points there.
What should I do if Claude Status is green but I still get 529?
Treat the green page as a timestamped signal, not as proof the exact path is fixed. Run a short same-path retry with jitter, reduce pressure if you control traffic, and escalate with request_id evidence if the same model, route, auth path, and request shape keep failing.
How many retries are safe?
Use a budget rather than a universal number. Cap attempts or elapsed time, add jitter, and retry only work that is safe to repeat. If the request has user-visible value only for a short time, the retry budget should be short too.
Should I switch models or providers when 529 appears?
Only as an explicit route decision. If the workload can tolerate a different model or route, switching can keep a non-critical flow alive. But do not use switching as the first diagnostic move because it hides whether the original path recovered.
What should I send to Anthropic support?
Send the error body, request_id, model, endpoint or gateway route, auth owner, status timestamp, retry timeline, pressure level, and a minimal reproduction. Remove secrets. Keep the packet short enough that the branch is obvious.
Working Rule
Claude API 529 is an overload-first recovery branch. Check live status with a timestamp, retry with a capped jittered budget, reduce caller pressure, verify the same path, and escalate only after the same path still returns 529 overloaded_error with clean evidence.