
If Claude Code shows API Error: 500, do not treat it as one universal retry situation. The fastest safe fix is to check the status page first, then decide whether you are looking at a live Anthropic incident, a login or OAuth failure, a broken resumed session, or an auth path you did not expect.
Those branches do not want the same first move. A red status page usually means you should stop changing local settings and wait. A green status page means your next useful test is not another blind retry. It is a clean login check, a fresh session, or a route check for the path that is actually sending requests.
The exact wording still matters because Internal server error can appear during login and because a resumed Claude Code session can keep failing after status has already recovered. That is why this page stays narrower than broader usage, rate-limit, or install guides.
Your same-path verification move is simple: after one branch-specific fix, retry the same failing path instead of changing several things at once. If the error survives a green status route, capture request_id, /status, and /debug evidence before you escalate.
Use the route board below to pick the right branch quickly. If your issue turns out to be a usage, billing, or install problem instead of a 500 recovery problem, jump to the sibling guide only after the branch test makes that clear.
Start Here: Which 500 Branch Are You In?
The exact symptom is narrow, but the safe first move is not. Anthropic's API docs define HTTP 500 as api_error, which means an unexpected internal Anthropic error occurred, while 529 is a separate overloaded_error branch. That is useful as a baseline, but it still does not tell you whether your next best move is to wait, reauthenticate, start fresh, or check the route Claude Code is actually using.
| What you are seeing | Most likely owner | Safest first move | Verify on the same path | Escalate when |
|---|---|---|---|---|
| Claude Status is red or a fresh incident is active | Anthropic-side outage or auth incident | Stop changing local settings and wait for recovery | Retry the same failing path after the incident clears | Status is green again but the same path still throws 500 |
Internal server error appears during login or OAuth | Expired OAuth, auth degradation, clock issue, or local token/keychain trouble | Run /status, then /login, then claude doctor if needed | Confirm the same login path now succeeds | Login still fails on a green status route |
| Status is green but one resumed session keeps failing | Broken resumed-session state or stale context | Start a fresh session instead of hammering the old one | Run the same task in the fresh session | The fresh session still fails the same way |
| Claude Code may be using an API key, proxy, or alternate provider route | ANTHROPIC_API_KEY override, route mismatch, or unexpected auth owner | Check /status, environment variables, and route config first | Compare the same request on a known-good path | The same route still fails with fresh credentials and debug evidence |
The route board is the whole point of the page. A lot of community advice for this error compresses every 500 into "Anthropic is down" or "just try again later." That is too shallow for a reader who needs service back now. A current outage is one real branch. It is not the only branch.
If Claude Status Shows an Incident Right Now

Status comes first because it can save you from unnecessary local debugging. Claude Status was green when this guide was rechecked on April 10, 2026, but the status history also showed recent April 8-9 incidents affecting authentication, Claude Code, Claude.ai, and elevated error rates. That recent history matters because it proves the exact symptom string can be tied to real platform incidents, not just local misconfiguration.
The practical rule is simple. If the relevant Claude component is red or an active incident is underway, stop changing your setup. Reinstalling, rotating settings, or force-switching routes during a live incident usually gives you extra noise, not a faster fix. Wait for the incident to clear, then retry the same path that failed before. The same-path retry matters because it tells you whether the incident was the whole story.
This is also where 500 and 529 should stay separate in your head. A 500 is the generic internal-error bucket in Anthropic's API docs. A 529 means overloaded traffic. To the reader, both can feel like "Anthropic is having a bad moment," but the distinction is still useful when you collect evidence later. If you have the exact code or log line, keep it.
What this branch should not become is a universal explanation. If status is green and stays green, the right next move is not "wait harder." It is branch diagnosis. That is the difference between an outage-aware guide and a generic outage post dressed up as Claude Code troubleshooting.
If the Error Appears During Login or OAuth
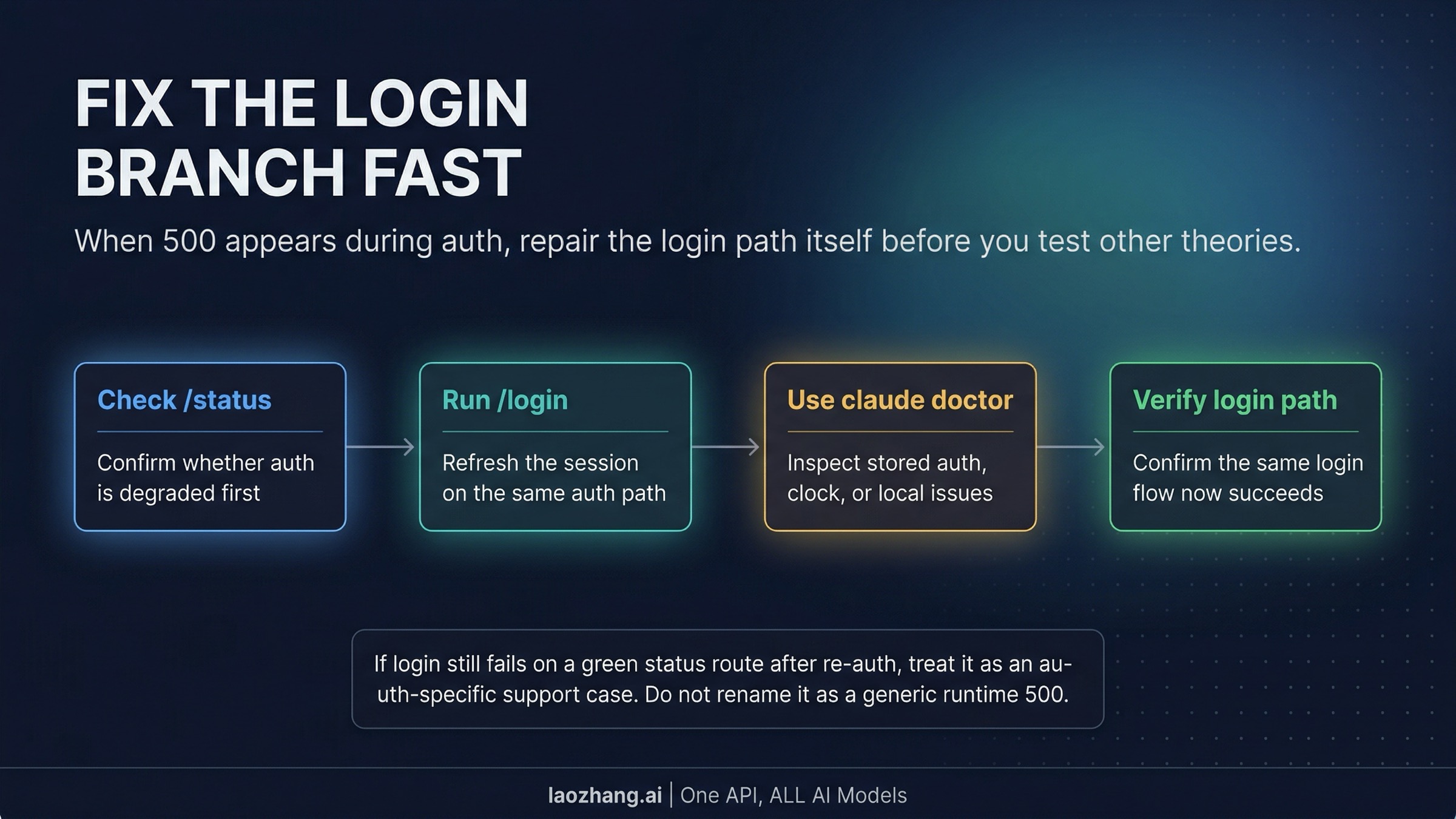
This branch is easy to miss because the user still sees "internal server error" and assumes it must be the same as an in-session runtime failure. Claude Code's troubleshooting docs point to a narrower auth path: check /status to confirm the active authentication method, use /login to refresh the session, and use claude doctor when repeated login prompts suggest expired tokens, clock skew, or local keychain trouble.
That official flow matters because login failures and runtime failures are not the same recovery job. If the error appears while signing in, your question is no longer "is Claude Code generally broken?" It is "is the login path broken because auth is degraded, the token expired, the local machine clock is off, or the stored credential state is damaged?" The page should answer that directly, not bury it under broad Claude Code background.
Run the auth checks in order. Start with /status so you know whether the route is already degraded or whether Claude Code is using a different auth owner than you thought. Then re-run /login. If that still looks wrong, claude doctor is the documented next step because it checks the local environment instead of making you guess between OAuth, machine time, and keychain state.
The verification boundary stays narrow here too: verify the same login path. Do not log in through some other surface and assume that proves Claude Code is healed. If the same Claude Code login path still fails after reauthentication on a green status route, that is when the issue stops being "probably just a login refresh" and becomes a support case with a clean auth-specific story.
If Status Is Green but the Resumed Session Still Fails
A green status page does not guarantee the current session is healthy. That is the branch most generic advice misses. A current anthropics/claude-code issue report tied the exact API Error: 500 symptom to a resumed session where context had already collapsed to zero percent, and starting a new chat helped. That does not prove one universal root cause, but it is a strong enough branch clue to change the first move.
The right test is to stop treating the old session as precious. Start a fresh session and rerun the same task with the smallest necessary context. If the fresh session works, you have learned something valuable: the old session state was likely part of the failure. If the fresh session still fails in the same way, then the issue probably lives elsewhere and you can move on without wasting more retries on the same stale context.
This is where readers often lose the most time. They see a green status page, assume that waiting is no longer useful, and then keep pounding the same broken resumed session because it already "knows the context." That instinct is understandable and often wrong. Old context can be the problem. A fresh session is a better control test than another identical retry in the unhealthy one.
If your deeper problem turns out not to be a 500 at all but a fast-drain, shared-usage, or billing-path confusion problem, stop here and switch pages. Our Claude Code usage limits diagnosis guide is the better follow-up when the real symptom is disproportionate consumption rather than a clean 500 recovery problem.
If You May Be on an API Key, Provider, or Proxy Route
Some Claude Code users assume the tool is always using their subscription OAuth path. Anthropic's troubleshooting docs say otherwise: if ANTHROPIC_API_KEY is present, Claude Code uses that key instead of the subscription OAuth credentials. That single fact explains a lot of confused debugging. The user thinks they are on one contract. Claude Code is actually sending requests on another.
That is why /status belongs so early in the recovery flow. It tells you which authentication method is active. If the active path is not the one you thought you were testing, every conclusion after that gets shaky. A green subscription status does not automatically explain an API-key route. A provider proxy or alternate route can fail differently even when the official status page looks fine.
The safe move here is not to shop for a different provider immediately. It is to identify the active route, clear stale or wrong credentials, and compare the same request on a known-good path. If you remove the unexpected API key or switch back to the intended auth owner and the failure disappears, the route mismatch was the real branch. If the same route still fails after fresh credentials and a clean comparison, now you have a sharper escalation case.
This section should also stay narrower than the install problem. If your branch turns out to be broken local setup, missing prerequisites, or first-time configuration trouble rather than a clean 500 recovery path, the better sibling is our Claude Code install guide. The point is to route cleanly, not to make one page answer every adjacent Claude Code job.
Verify the Fix and Know When to Escalate
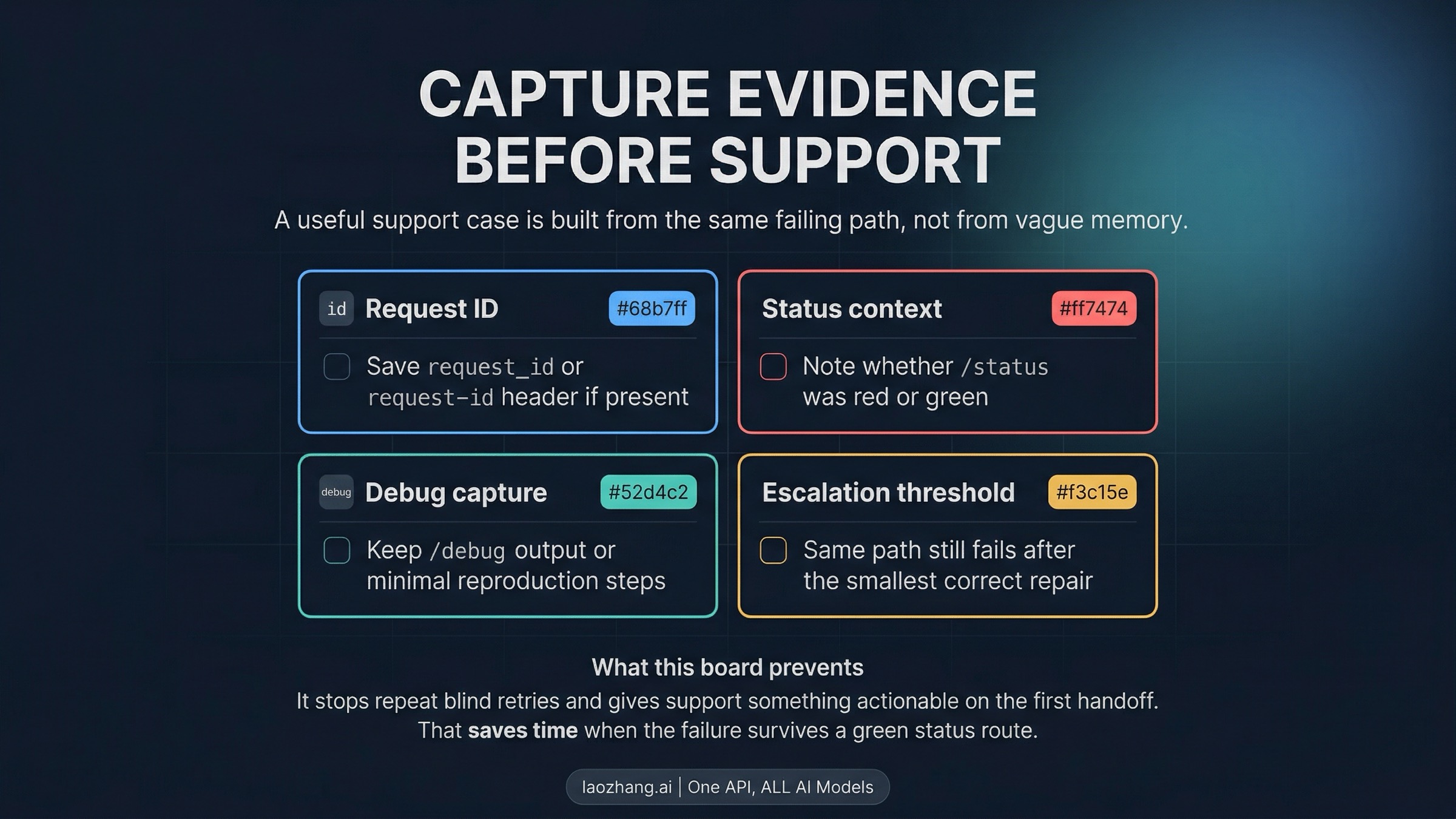
Anthropic's API docs say error responses include request_id, and the request-id header appears on every API response. Keep that data when you have it. Claude Code's official command docs also give you /status, /debug, and /cost as current diagnostic surfaces. You do not need a giant packet. You do need enough evidence that support can tell which branch you already tested.
Before you escalate, capture these items from the same failing path:
- the exact error string and any
request_idorrequest-idvalue - whether
/statuswas red or green when the failure happened - whether the problem happened during login, in one old resumed session, or on a specific auth route
/debugoutput or the smallest clean reproduction steps you can provide
That evidence changes the quality of the conversation. "Claude Code gave me 500" is a weak report. "Green status, same login path still fails after /login, request_id attached" is actionable. "Green status, fresh session succeeds but the old resumed session still throws 500" is actionable too. The job is not to sound dramatic. It is to reduce ambiguity.
The escalation boundary is explicit: if the same path still fails after the smallest correct branch-specific fix on a green status route, stop improvising. Escalate with evidence. That is the point where another random retry is less likely to help than a clean handoff.
If the branch you uncover is really about usage exhaustion or explicit rate limits instead of a 500 recovery path, switch to our Claude Code token usage guide. That page is for billing path, shared usage, and cost interpretation. This one is for getting the right 500 fix first.
Frequently Asked Questions
Is Claude Code API Error: 500 the same as 529 overloaded_error?
No. Anthropic's API docs define 500 as api_error and 529 as overloaded_error. Both can feel like platform instability, but they are different documented branches.
Why can I still see a 500 when Claude Status is green?
Because status only rules out the live-incident branch. You can still be in a login-path problem, a broken resumed session, or an unexpected auth-route branch that needs a different first move.
Should I reinstall Claude Code right away?
Usually no. Reinstalling is a poor first move for this symptom. Check status, test the right branch, and verify on the same path first. Reinstalling before that mostly destroys signal.
What is the best first test if the old session keeps failing?
Start a fresh session and rerun the same task with only the necessary context. That is the fastest way to tell whether the problem lives in the old session state.
What should I send to support?
Send the exact error wording, any request_id, what /status showed, which branch you tested, and the smallest reproduction you can describe. Clean branch evidence is more useful than a long general complaint.
The Working Rule
Claude Code API Error: 500 is worth treating as a branch-first recovery problem, not as a generic retry message. Check status, choose the branch, apply one small fix, verify on the same path, and escalate with evidence if that path still fails on green.