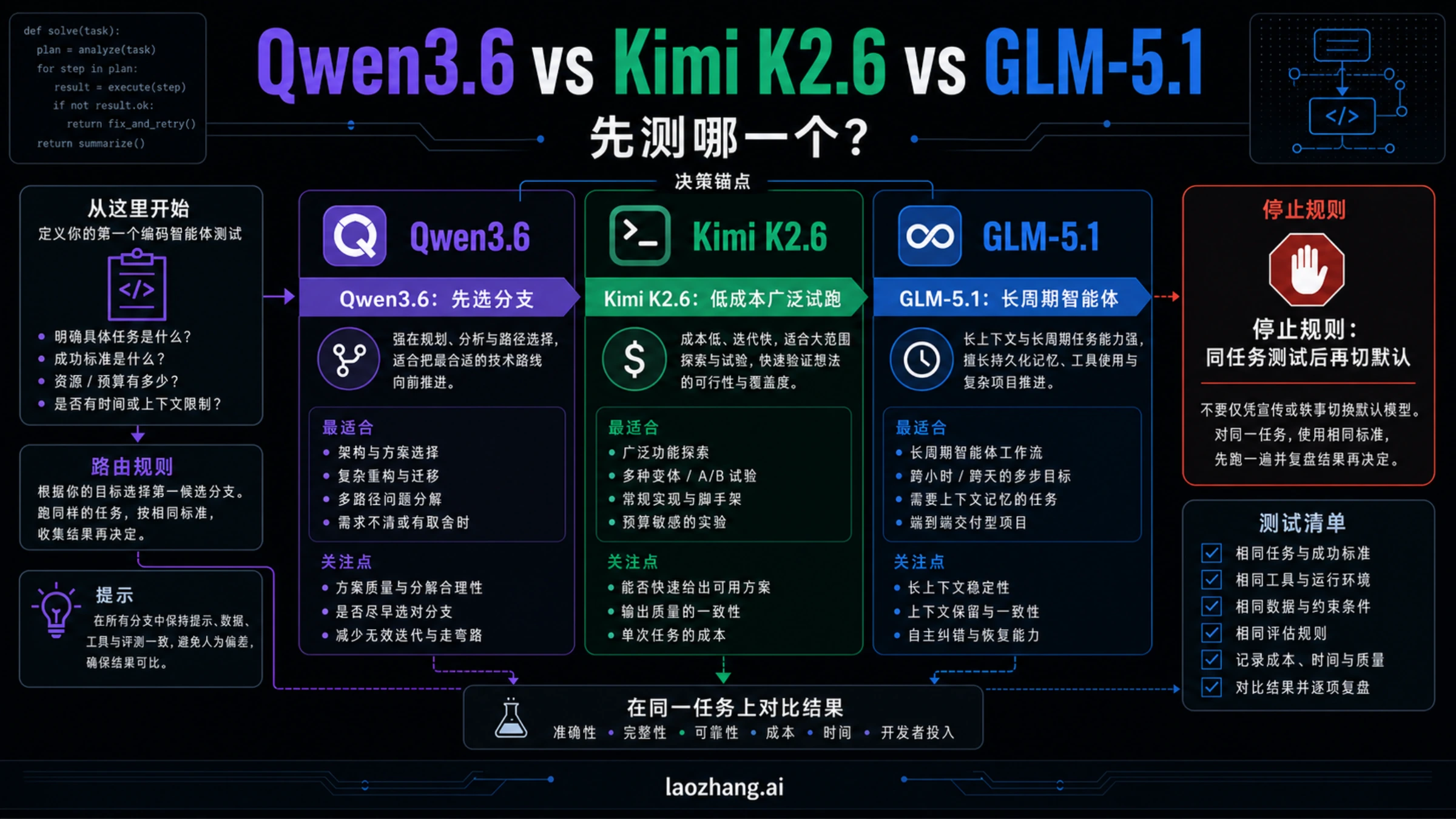
截至 2026 年 5 月 7 日,如果你的任务是长周期编码 Agent、跨文件修复和持续上下文执行,先测 GLM-5.1;如果你需要低成本、多轮试错和大量候选补丁,先测 Kimi K2.6;如果你想测 Qwen3.6,第一步不是问它强不强,而是先说明分支:Qwen3.6-35B-A3B 是开放权重控制路线,Qwen3.6 Plus、Flash、Max Preview 是托管路线。
这三个名字不能放进一张简单排行榜。kimi-k2.6 和 glm-5.1 是可以直接按官方文档核对的模型 ID;Qwen3.6 在这次决策里是分支标签。把 Qwen3.6-35B-A3B 的本地部署结果、Qwen3.6 Plus 的托管体验和 Qwen3.6 Max Preview 的发布周测试混成一行,会让首测决策看起来更整齐,但也更危险。
| 首测路线 | 适合先测的场景 | 切换默认前要确认 |
|---|---|---|
| GLM-5.1 | 长周期自主编码、跨文件迁移、大上下文追踪、工具调用需要长时间保持一致。 | 核对 glm-5.1、Z.AI 上下文与输出上限、工具行为、当前价格和迁移边界。 |
| Kimi K2.6 | 低成本批量试错、前端变体、脚手架、候选补丁和低风险代码清理。 | 核对 kimi-k2.6、Moonshot/Kimi 价格行、托管路线和开放权重条款是否适合你的栈。 |
| Qwen3.6 | 需要 Qwen 家族行为、本地控制、开放权重部署或阿里托管分支实验。 | 先命名分支:35B-A3B、Plus、Flash、Max Preview 不是同一合同。 |
停止规则:不要因为一次演示、一次榜单或一行更低价格就替换当前默认模型。只有在同一仓库快照、同一提示、同一工具、同一测试命令和同一 reviewer 标准下,候选路线在可接受 diff、测试通过率、隐藏缺陷、重试成本和 review 时间上连续不输,才进入默认切换讨论。
快速答案
GLM-5.1 最适合先放到长周期 Agent 任务里测。它的 Z.AI 路线给了清晰的模型 ID、上下文与输出边界,以及迁移说明;这类任务关心的是计划能不能跨很多步保持一致、能不能从中间错误恢复、能不能在大仓库上下文里不丢关键引用。
Kimi K2.6 最适合先放到低成本试点里测。它的价值不是一句“更便宜”就结束,而是让团队用更多尝试覆盖更多候选方案:UI 变体、重复修复、脚手架、普通重构、代码扫描和低风险批量修改。真正要看的不是单次 token 账单,而是通过 review 的任务成本。
Qwen3.6 只有在分支被命名后才适合进入对比。Qwen3.6-35B-A3B 适合本地部署、可复现控制、开放权重试验和自定义编排;Qwen3.6 Plus、Flash、Max Preview 则属于托管路线实验。两类结果都可能有价值,但不能互相代替。
先拆开 Qwen3.6
Qwen3.6 在这类比较里首先是一个家族入口。Qwen 官方材料和 Hugging Face 模型卡把 Qwen3.6-35B-A3B 描述为面向编码 Agent 的 MoE 开放模型,35B 总参数、3B 激活参数,模型卡记录 Apache-2.0 许可,并给出 262,144 token 级的服务示例。这些事实对需要本地控制、复现实验或自建推理路线的团队很重要。
但这不等于所有 Qwen3.6 公开比较都在谈 35B-A3B。很多页面和视频讨论的是 Qwen3.6 Plus、Flash 或 Max Preview。托管分支可能正是阿里路线用户要测的东西,但它们不是本地开放权重分支。团队如果要把 Qwen3.6 和 Kimi K2.6、GLM-5.1 放在一起测,第一句内部需求应该写成“我们测哪个 Qwen3.6 分支”,而不是“Qwen 是否赢”。
官方合同路线

官方合同能把发布周噪音压下来。2026 年 5 月 7 日核对时,三个路线应该这样拆:
| 合同项 | Qwen3.6 | Kimi K2.6 | GLM-5.1 |
|---|---|---|---|
| 先核对的官方归属 | Qwen 官方博客、Qwen 模型卡、阿里托管分支文档。 | Moonshot/Kimi 平台与 Kimi 模型文档。 | Z.AI GLM-5.1 文档、迁移文档和价格文档。 |
| 部署标签 | 开放权重分支写 Qwen3.6-35B-A3B;托管分支要单独写 Plus、Flash 或 Max Preview。 | kimi-k2.6 | glm-5.1 |
| 首测理由 | 本地控制、开放权重、自建推理或阿里路线分支实验。 | 低成本广泛试点、更多尝试和 Moonshot/Kimi 路线。 | 长周期自主编码、持续上下文和 Z.AI 路线兼容。 |
| 上下文与输出 | 分支相关;35B-A3B 模型卡有 262,144 token 服务示例。 | 以 Moonshot/Kimi 当前文档为准。 | Z.AI 文档列出 200K 上下文和 128K 最大输出。 |
| 价格归属 | 托管分支价格随分支或提供方变化;开放权重成本是你的基础设施成本。 | 平台行核对为 cache hit $0.16/MTok、input $0.95/MTok、output $4.00/MTok。 | 价格行核对为 input $1.4、cached input $0.26、output $4.4 / 1M tokens。 |
| 开放权重边界 | Qwen3.6-35B-A3B 是开放权重路线。 | Kimi 文档有开放可用性说法,但路线、许可和自托管条款仍要核对。 | 这里按 Z.AI 托管路线处理。 |
Qwen3.6-35B-A3B 的事实以 Qwen 官方帖子和 Hugging Face 模型卡为准;Kimi 路线以 Kimi 平台 和 Kimi 模型文档 为准;GLM 路线以 Z.AI GLM-5.1 文档、迁移文档 和 价格文档 为准。价格、上下文和可用性都是易变事实,进入生产默认前要重新核对。
编码 Agent 工作负载

真正的分界不是“哪个模型最强”,而是哪个路线先承受你的任务失败成本。长周期自主编码优先测 GLM-5.1,因为这类任务需要模型保留计划、追踪依赖、跨很多工具调用保持一致,并在出错后恢复。典型样本是多文件迁移、大型 bug hunt、长上下文重构和需要模型连续数小时推进的仓库任务。
低成本广泛试点优先测 Kimi K2.6。它适合让团队一次跑更多变体:前端布局替代方案、常规实现、重复修复、低风险批量修改和候选 patch 生成。便宜的 token 行只有在“被接受的任务成本”也低时才成立。如果每个合并补丁都要三次返工和大量人工 review,低价路线只是把成本转移给了人。
Qwen3.6 优先测的是控制权或路线匹配。Qwen3.6-35B-A3B 适合本地部署、自定义工具链、私有推理、可复现基准和开放权重实验。托管 Qwen3.6 分支适合阿里路线用户测延迟、集成、配额和管控体验。两者都可以参加同任务试点,但评估表必须分开写。
同任务试点清单
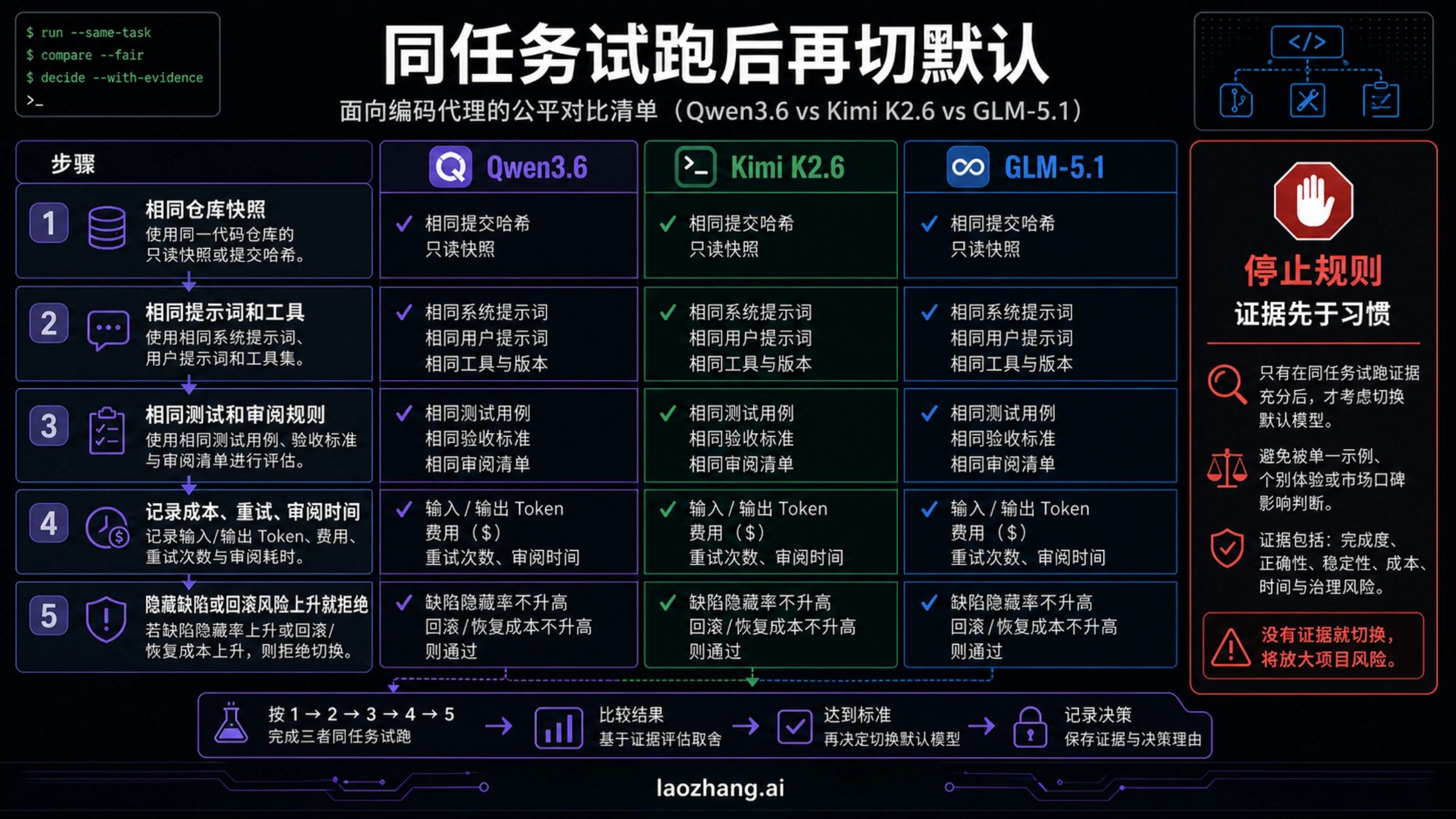
模型对比只有落到同任务试点才有决策价值。先选 5 到 10 个真实任务:小 bug 修复、多文件重构、测试补齐、前端 UI 改造、长上下文分析,以及一个需求故意不够明确的任务。每条候选路线都用同一仓库快照、同一提示、同一工具权限、同一超时、同一测试命令和同一 reviewer。
记录项不要只写“感觉更好”。至少要记录 accepted diff、测试是否通过、漏改引用、隐藏缺陷、reviewer 修改量、重试次数、工具调用漂移、延迟、计费归属和回滚风险。候选模型如果在一次 demo 里表现惊艳,但在重复任务里制造不稳定格式、漏文件或多余假设,它仍然只能留在试点池。
阈值也要提前写好。一个 blocker 缺陷就停止默认提升;三个 major 缺陷就只保留低风险试点;review 时间超过当前默认两倍,说明 token 省下的钱被转给了 reviewer;同一任务需要三次以上重试才可接受,也不应该成为默认。
什么时候不该先测
如果任务只是十几个小变体,而且团队还没有 Z.AI 路线,不必先从 GLM-5.1 开始。它的长周期优势在短小低风险任务里未必能体现。
如果任务是高风险生产迁移,也不该只因为 Kimi K2.6 便宜就先把它设为默认。Kimi 可以进入试点池,但隐藏缺陷成本高于模型账单时,控制路线必须保留。
如果没有人能说清 Qwen3.6 分支,不该先测 Qwen3.6。一条 Qwen3.6 Flash 结果、一条 Qwen3.6 Max Preview 结果和一条 Qwen3.6-35B-A3B 本地结果不是同一个证据。Qwen 的规则很简单:先分支,后比较。
与现有对比页怎么分工
这篇页面只处理 Qwen3.6 家族分支、Kimi K2.6 和 GLM-5.1 的三路线首测问题。它不应该变成所有中国模型的榜单,也不应该替代 Kimi 与 Claude 的生产默认替换判断。
如果你的真实问题是 Kimi K2.6 能不能替代 Claude Opus 默认路线,看 Kimi K2.6 对比 Claude Opus 4.7。如果你的候选集合还包含 DeepSeek V4、GPT-5.5 和 Claude Opus 4.7,看更宽的 Kimi K2.6、DeepSeek V4、GPT-5.5、Claude Opus 4.7 对比。把边界分清,三路线决策才不会退化成泛泛排行榜。
常见问题
Qwen3.6 是一个模型吗?
不是。实际选型里,Qwen3.6 是分支标签,直到你说明具体路线。Qwen3.6-35B-A3B 是 Qwen 和 Hugging Face 材料里的开放权重分支;Plus、Flash、Max Preview 等托管分支需要单独核对路线、价格和限制。
Kimi K2.6 比 GLM-5.1 便宜吗?
按 2026 年 5 月 7 日核对的官方价格行,Kimi K2.6 的 listed input/output token 价格低于 GLM-5.1。这只说明它适合低成本试点,不等于可以替换默认模型。最终成本还取决于重试、review、隐藏缺陷、工具行为和封装计费。
GLM-5.1 更适合编码 Agent 吗?
当任务是长周期、上下文重、需要 Z.AI 路线,并且模型要在多步工具调用中保持一致时,GLM-5.1 是第一条应该测的路线。它不是所有低成本探索、本地控制或小任务的默认首选。
什么时候应该先测 Qwen3.6?
当决策重点是本地控制、开放权重部署、Qwen 家族行为、阿里托管路线或自定义编排时,先测 Qwen3.6。前提是先写清具体分支,否则结果无法解释。
它们能替换我现在的默认模型吗?
只能在同任务试点通过后考虑。候选路线必须在可接受 diff、测试通过率、隐藏缺陷严重度、review 时间、重试成本、工具稳定性和回滚风险上不输当前默认模型。