Kimi K2.6 和 Claude Opus 4.7 不是在争一个永远有效的冠军。更实用的问题是:你的下一轮编码 agent 或 API 测试,应该先把钱花在哪条路上。
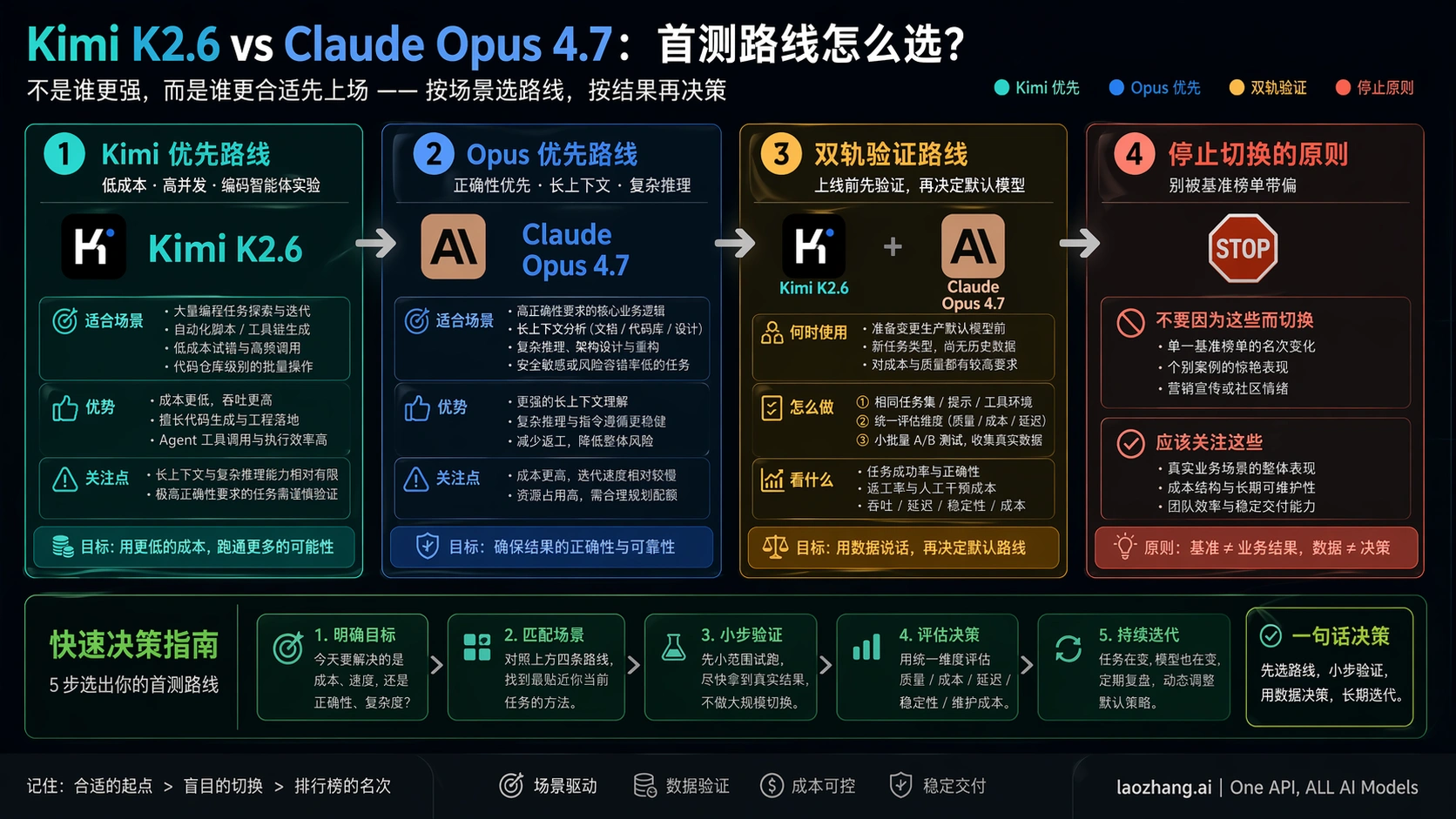
如果你要跑大量低风险代码实验、批量修补、测试脚手架或开放模型路线评估,先测 Kimi K2.6。如果你的任务是迁移、支付相关代码、安全敏感逻辑、长上下文生产分析,或者一次错误补丁会比 token 账单贵很多,先保留 Claude Opus 4.7。如果你准备把团队默认模型从 Opus 切到 Kimi,不要只看一张 benchmark 图,必须在同一仓库、同一 spec、同一工具预算、同一 review 规则下双跑。
| 路线 | 什么时候先走 | 为什么 | 停止规则 |
|---|---|---|---|
| 先测 Kimi | 成本、批量和试错次数最重要 | 官方价格差距足够大,能让更多尝试成为策略的一部分 | 不能因为一次测试通过就叫它 Opus 替代品 |
| 先留 Opus | 正确性、长上下文、迁移风险和隐藏 bug 成本最重要 | Anthropic 的高级路线、1M context 和 API 迁移说明更适合高风险工作 | 不要因为 Kimi 便宜就直接改生产默认 |
| 双跑 | 准备改默认模型、路由策略或团队规范 | 替代质量是工作流结果,不是单行分数 | 没有预设失败阈值就不切默认 |
截至 2026-04-23,官方合同已经把这条分界线写得很清楚:Kimi K2.6 标出 cache hit $0.16/MTok、input $0.95/MTok、output $4.00/MTok 和 262,144 token context;Claude Opus 4.7 标出 input $5/MTok、output $25/MTok、1M context 和 128k max output。这些数字证明的是成本路线和上下文路线,不是“谁在所有编码任务里稳赢”。
先看结论
中文读者最容易被三类信息混在一起:视频横评会给出很快的观感,论坛讨论会混入套餐和中转路线,第三方对比页会把价格、速度、上下文和 benchmark 放进同一张表。真正能帮你决策的不是把这些信息照抄一遍,而是先把问题改成“我现在应该先测谁,什么时候不能切默认”。
最稳的起步规则很简单:低风险、高批量、可人工 review 的工作先测 Kimi;高风险、难回滚、长上下文或迁移类工作先留 Opus;任何默认模型切换都先双跑。这样写不是给 Kimi 降级,而是给它一个更公平的赢法。Kimi 的价格优势只有在你记录真实缺陷、重试次数、工具循环和 reviewer 时间之后,才会变成生产价值。
如果你的团队现在已经在用 Opus 做高价值编码,不要问“Kimi 能不能替代 Opus”这么宽的问题。更好的问题是:Kimi 能不能在这个仓库、这类任务、这些测试和这位 reviewer 面前,把真实缺陷控制在你预设的阈值里。如果答案是能,它可以先吃掉低风险批量任务;如果答案是不能,它仍然可以做探索和草稿路线,而不是生产默认。
官方合同先把边界划清

| 合同点 | Kimi K2.6 | Claude Opus 4.7 |
|---|---|---|
| 第一方归属 | Moonshot / Kimi | Anthropic |
| API 标识 | Kimi 平台公开的 K2.6 路线 | claude-opus-4-7 |
| 2026-04-23 价格 | cache hit $0.16/MTok,input $0.95/MTok,output $4.00/MTok | input $5/MTok,output $25/MTok |
| 上下文/输出 | 262,144 token context | 1M context,128k max output |
| 决策含义 | 低成本扩大实验量 | 高风险任务保留 premium control |
Kimi 的价格和上下文来自 Moonshot/Kimi 自己的 K2.6 页面和平台信息,Claude 的价格、模型 ID、上下文、输出和迁移说明来自 Anthropic 自己的 Opus 4.7 页面与模型文档。这个归属要写清楚,因为供应商页、聚合页、套餐页和转发路线经常把官方事实和第三方合同放在同一个页面里。
用一个粗略的一百万输入加一百万输出的形状看,Kimi 非缓存输入加输出大约是 $4.95,Opus 是 $30。这个差距足以让 Kimi 成为认真 pilot 的第一候选。但这还不是最终成本:真实任务里还会有缓存命中、输出长度、重试、工具调用、超时、人工 review 和隐藏 bug 返工。便宜模型如果多出很多错误,可能在高风险任务里反而不便宜。
Opus 侧也有一个不能省的细节:Anthropic 说明同样文本在 Opus 4.7 上可能按内容类型映射成约 1.0x 到 1.35x 的 token。这个信息不能写成固定加价,但它要求团队用真实 prompt 计量,而不是只拿列表价格做预算。
证据边界:什么能证明,什么不能证明
Kimi K2.6 的官方材料可以证明它是当前、低价、值得测试的强模型。它不能单独证明 Kimi 在你的 coding-agent 工作流里已经打败 Claude Opus 4.7,因为 Kimi 官方表格并没有把 Opus 4.7 作为直接列。把 Opus 4.6 的行当成 Opus 4.7 证据,是会让页面失真的做法。
第三方横评也有价值,但价值在方法而不在结论所有权。一个同任务测试、一个论坛复现、一个 provider 对比页,都可以提醒你要看哪些失败:测试通过但代码形状很差,重构范围过宽,迁移漏步骤,工具循环过长,或者模型自己总结“已修复”但 reviewer 能复现 bug。它们不能替你决定生产默认。
| 证据类型 | 能支持什么 | 不能支持什么 |
|---|---|---|
| Kimi 第一方价格与发布材料 | 证明 Kimi 低价、当前、值得进入 pilot | 证明 Kimi 是 Opus 4.7 的通用替代品 |
| Anthropic Opus 4.7 文档 | 证明 Opus 的模型 ID、价格、1M context、128k output 和迁移边界 | 证明每个任务都值得付 premium 价格 |
| 第三方对比页或视频 | 给测试项、失败类型和复现方式提供线索 | 直接拥有官方价格或生产路由结论 |
| 自己的双跑 pilot | 判断 Kimi 能不能替代你当前的 Opus 工作流 | 判断所有团队都该做同样切换 |
编码 agent 应该这样双跑
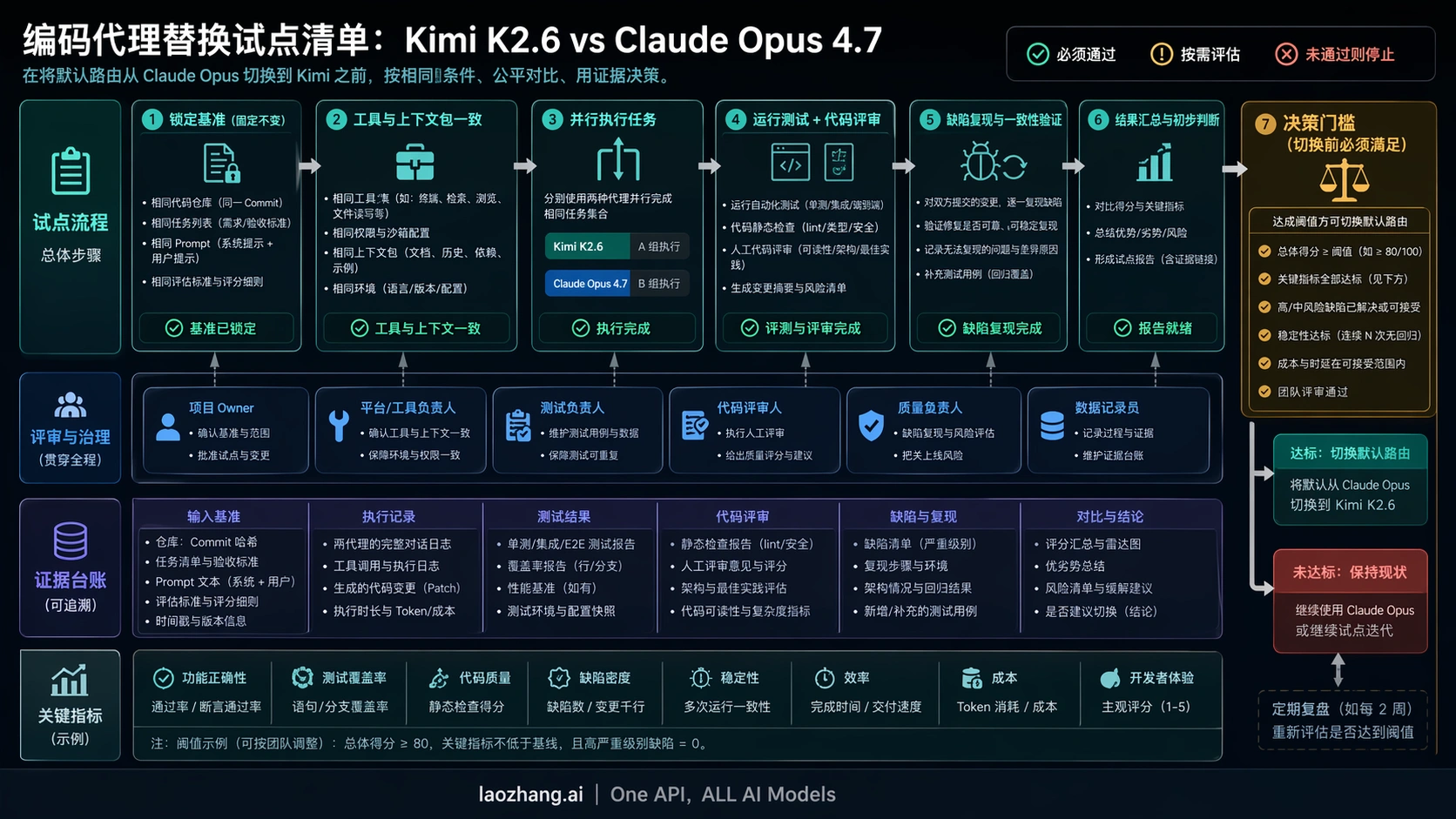
双跑计划越无聊越好。目标不是制造一个漂亮榜单,而是减少借口。先从 Opus 已经帮你完成过的真实任务里抽出 control pack:一个小 bug fix,一个中等重构,一个测试补全,一个长上下文分析,一个需求不完整、模型必须反问或拒绝错误假设的任务。agentic coding 要包含工具调用和仓库导航;API batch 要包含真实 prompt、timeout、retry 和 logging。
然后把两边约束锁死:同一仓库快照,同一任务说明,同一成功条件,同一工具预算,同一停止条件,同一套 lint、unit、integration 或 smoke check,同一位 reviewer。不要只数 token,也要记录 wall-clock 时间、重试次数、工具循环、人工干预、隐藏 bug 严重性和 reviewer 改动量。
切换阈值必须在测试前写下。比如低风险批量修改可以接受 Kimi 的真实缺陷不超过 Opus 的 10%,只要成本下降超过一半;但 repo-wide migration 或支付代码可能要求接近无损,甚至必须让 Opus 继续做控制组。阈值不对称很正常,因为不同工作负载的失败价格不同。
工作负载路由
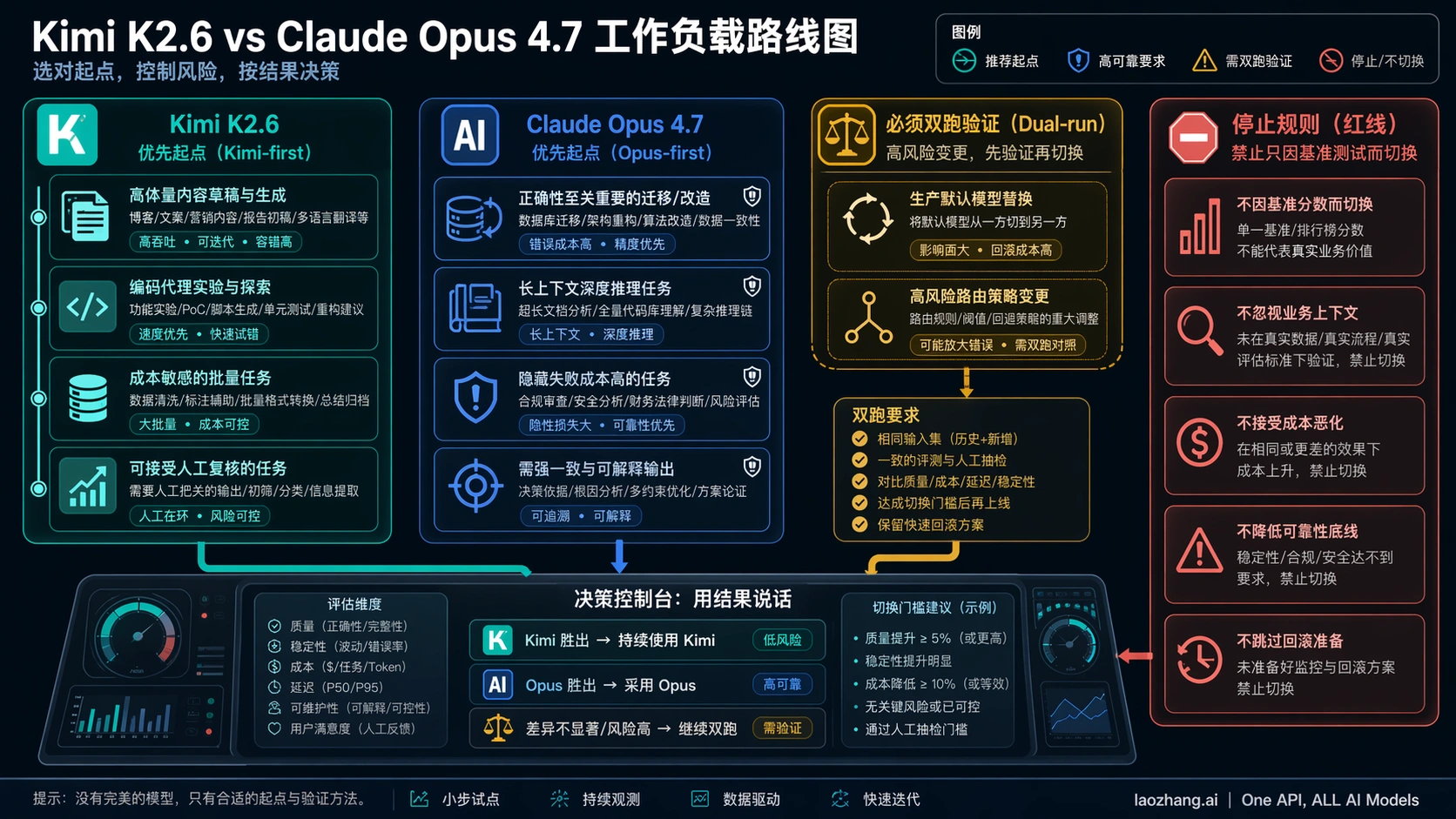
| 工作负载 | Kimi 先测 | Opus 先留 | 默认切换前双跑 |
|---|---|---|---|
| 大量低风险 agent 实验 | 是 | 只抽样做质量控制 | 重要仓库前需要 |
| 测试脚手架、低风险清理 | 是 | reviewer 时间变成瓶颈时 | 自动合并前需要 |
| repo-wide migration | 先 control run | 是 | 是 |
| 安全、支付、权限相关代码 | 通常不先 | 是 | 是 |
| 长上下文生产分析 | 262k 足够且成本主导时 | 需要 1M 或 128k output 时 | 替代 Opus 决策前需要 |
| 开放模型或自托管评估 | 自然先看 Kimi | Opus 不适用为开源路线 | 输出竞争生产结论前需要 |
如果你的问题其实是 Anthropic 内部迁移,去看 Claude Opus 4.7 vs Claude Opus 4.6。如果你要在 Anthropic、OpenAI、Google 之间选第一轮模型,去看 Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro。当前页面只解决 Kimi 能否先测、何时不能替代 Opus。
API 切换前要检查
API 细节不是附录。Kimi 第一方、OpenRouter、Microsoft Foundry、其他 provider、内部套餐或中转路线都可能使用相似模型名,但价格、quota、延迟、日志、失败扣费和支持责任不是同一个合同。内部文档必须标明哪一条路线拥有价格和可用性。
Claude 侧也不要只做模型 ID 替换。Anthropic 对 Opus 4.7 写了 sampling 参数、extended thinking、tokenizer、high-resolution image 和 task budget 等行为变化。如果你的 harness 仍然传旧的 top_p、top_k 或 temperature 组合,迁移工作可能在 client code,而不在 prompt。
一条稳妥的 rollout 记录应该有四张表:成本表分开 cache hit、input、output;质量表按缺陷严重性而不是缺陷数量记分;人工表记录 reviewer 时间和返工;路由表记录哪些任务先交给 Kimi,哪些仍然要 Opus 控制组。没有这些记录,切默认就是猜。
可复用评估模板
| 记录项 | 记录方法 | 为什么重要 |
|---|---|---|
| 成本 | input、cached input、output、retry、工具调用分开 | 避免把便宜 token 误读成便宜 workflow |
| 质量 | 按 blocker、major、minor、style 分类 | 让一个严重 bug 不被多个小问题稀释 |
| 时间 | wall-clock、reviewer minutes、rerun 次数 | 编码 agent 的真实成本常在人工侧 |
| 路由 | Kimi-only、Opus-only、dual-run、rollback | 方便把 pilot 变成团队默认规则 |
如何把 pilot 变成团队规则
一次双跑结束后,不要只留下“感觉 Kimi 可以”或“Opus 更稳”这种结论。更好的做法是把任务分成三层:第一层是 Kimi-only,包含可回滚、可人工复查、失败成本低的批量工作;第二层是 Opus-only,包含迁移、权限、支付、复杂重构和长上下文生产分析;第三层是 dual-run,包含边界正在变化、团队准备改默认模型、或者历史上 review 成本很高的任务。
这个路由表还应该带有复查周期。Kimi 的价格、上下文、供应商路线和开源状态可能变化,Opus 的 API 行为、tokenization、task budget 和可用 surface 也可能变化。每次价格或 API 行为改变,都需要重新跑一小组 control tasks,而不是让旧 pilot 永久生效。
对管理者来说,最有用的汇报不是“哪个模型更强”,而是“哪些任务已经可以交给 Kimi,哪些任务继续需要 Opus,哪些任务仍然需要双跑”。这样团队可以真实降低成本,同时保留高风险任务的正确性边界。
还有一个容易被忽略的细节:不要把“便宜”只理解成单次调用便宜。Kimi 的优势在于它可以让团队多做几轮候选解、多保留一个失败样本、多让 reviewer 看见不同修复路径;Opus 的优势在于它可能减少高风险任务里的返工、回滚和事故调查。两个模型的价值单位并不完全一样,所以 pilot 报告必须同时写出 token bill、人工 review、缺陷等级和回滚成本。只有这些数字放在一起,路线表才不会变成情绪化偏好。
当某个任务从 dual-run 移到 Kimi-only,也要保留回退条件。例如连续三次 major defect、一次 blocker defect、review 时间超过 Opus 两倍、或者工具循环超过预算,都应自动把任务拉回 dual-run 或 Opus-only。这样 Kimi 的低价不会把风险悄悄转嫁给 reviewer,Opus 的高价也不会阻止团队在低风险区域节省预算。
最后,把每次结论写成日期化的合同快照。价格、上下文、可用入口、API 参数和供应商行为都会变;模型能力也会被后续小版本、缓存策略、工具预算和提示模板影响。日期化不是装饰,而是让下次复查知道哪些判断仍然有效,也能避免旧结论被误当成新的生产依据。
常见问题
Kimi K2.6 比 Claude Opus 4.7 便宜吗?
按 2026-04-23 的第一方价格,是的。Kimi 标出 $0.95/MTok input、$4.00/MTok output 和 $0.16/MTok cache hit;Anthropic 标出 Opus 4.7 为 $5/MTok input、$25/MTok output。供应商路线可能不同,必须分开标。
Kimi K2.6 能替代 Claude Opus 4.7 吗?
只能在你的同一工作流里证明之后替代。正确说法是 Kimi 值得先进入低成本 pilot,而不是默认成为 Opus 的 drop-in 替代。
哪个更适合 coding agent?
高风险、迁移、长上下文和隐藏 bug 代价高的任务,Opus 4.7 更适合作为第一选择。低风险批量任务和大量试错,Kimi K2.6 更适合先测。
Kimi 官方 benchmark 证明它赢 Opus 4.7 吗?
不能。Kimi 官方表格能证明 K2.6 当前且强,但不能把没有直接列出的 Opus 4.7 关系说成 head-to-head 结论。
默认模型切换前最少要做什么?
同一仓库、同一 spec、同一工具预算、同一测试、同一 reviewer 双跑,并在开始前写好可接受缺陷阈值和回滚规则。
第三方对比页能不能直接用来决策?
可以用来找测试思路、指标和风险点,但官方模型 ID、价格、上下文、输出和 API 行为要回到 Kimi 与 Anthropic 第一方来源。
如果我必须要 1M context 呢?
先看 Claude Opus 4.7。Kimi 的 262,144 token context 很大,但不是同一个合同。只有当任务装得进 Kimi context 且成本主导时,Kimi 才更适合先测。