大多数搜索“Gemini 3.1 Pro vs Claude Opus 4.6”的开发者,其实不是在找一篇模型哲学文章,而是在问一个更直接的问题:我到底该先测谁?截至 2026 年 3 月,更实用的答案很简单。如果你的主要工作负载是长上下文处理和成本控制,先测 Gemini;如果你的核心问题是代码代理的可靠性,先测 Claude;如果你的系统天然分成“海量输入”和“高价值执行”两段,就两者都保留,按任务分流。
这个答案成立,是因为两家的官方证据虽然不对称,但已经足够实用。Google 给出了更清楚的价格、token 上限和长上下文定位;Anthropic 给出了更强的公开编码与自主执行论据。真正的误区不是看 benchmark,而是把混合 benchmark 表、Preview 标签、beta context 和不同 SKU 当成同一张可直接比较的总分榜。
如果你只想先知道答案
如果你的大多数生产流量来自文档分析、仓库摄入、检索增强研究,或者其他 prompt 很长且对成本敏感的任务,先测 Gemini 3.1 Pro Preview。如果你最难的任务是代码审查、补丁生成、多步工具调用和调试,而且一次失败就会带来明显的人力返工,先测 Claude Opus 4.6。如果你的系统本来就分成“广泛收集上下文”和“高质量执行”两个阶段,就不要强行选一个永久赢家,而是把 两者都保留,按任务分流。这是 2026 年 3 月最直接、也最诚实的结论,比单看排行榜更贴近官方定价、上下文限制和产品定位。
| 如果你的产品主要需要…… | 先从哪个开始 | 原因 |
|---|---|---|
| 长文档、仓库摄入、成本敏感分析 | Gemini 3.1 Pro Preview | 官方价格更低,且百万 token 输入能力更清晰 |
| 代码审查、调试、多步工具调用、补丁生成 | Claude Opus 4.6 | 官方公开证据更支持高强度编码自主性 |
| 宽入口摄入阶段 + 窄执行阶段 | 两者都保留 | Gemini 负责便宜的上下文重任务,Claude 负责高价值执行 |
Benchmark 到底该怎么看?
搜索用户会看 benchmark,这很正常。问题不是 benchmark 没用,而是这组对比并没有一张真正对称、干净的公开总分表。Anthropic 更像是在公开证明“Opus 适合高端编码和高自主任务”,它重点强调 Terminal-Bench 2.0、Humanity's Last Exam、BrowseComp 和 GDPval-AA。Google 更像是在公开证明“Gemini 适合长上下文、低成本、带检索支撑的分析”,它给出了更清晰的价格、百万 token 输入、token 效率和工程行为定位。所以更可靠的读法是:用 benchmark 判断 Claude 是否值得优先做编码评测,用价格和 token 上限判断 Gemini 是否该优先进入长上下文场景。真正不该做的,是把 Sonnet、Opus、Preview 变体和 beta context 混成一张总分榜。
快速总览:你真正比较的到底是什么?

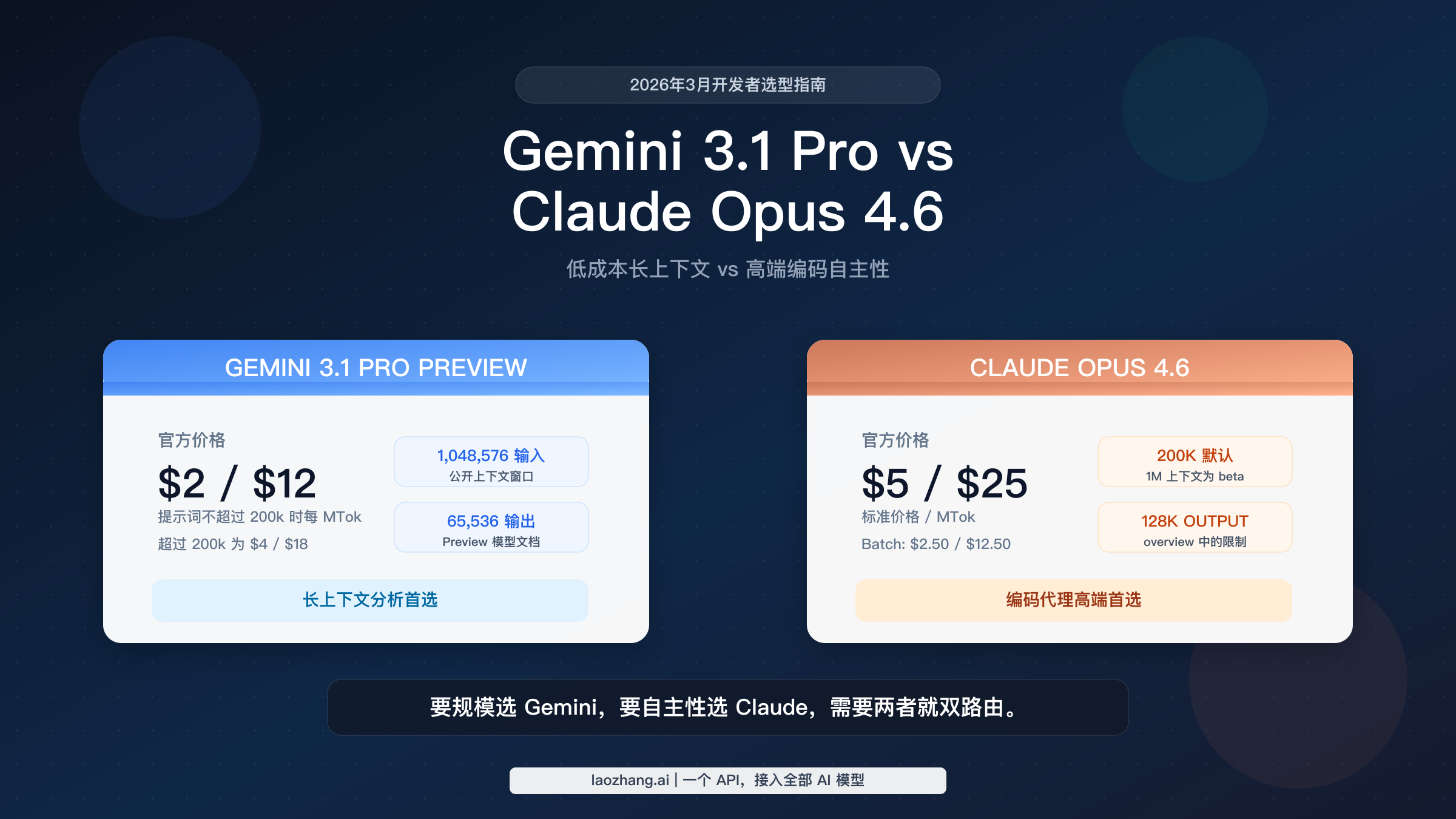
首先要纠正的是“比较对象”本身。很多人说“Gemini 3.1”时,实际上混用了几个不同产品:Gemini 3.1 Pro Preview、Gemini 3.1 Pro Preview Customtools,甚至论坛和第三方封装里提到的其他 Gemini 3.1 家族变体。如果要与 Claude Opus 4.6 做直接 API 对比,最干净的比较对象是 Gemini 3.1 Pro Preview,因为这是 Google 公开提供定价、token 限制与 software engineering 定位的旗舰长上下文模型。Anthropic 这一侧,真正对应的比较目标是 Claude Opus 4.6,而不是 Sonnet 4.6。Sonnet 往往是更省钱的 Claude 选择,但那是另一种产品决策。如果你在读完本文后还想把 Claude 全系价格层级看清楚,单独的Claude Opus 4.6 定价指南会更合适。
发布时间同样重要,因为这两款模型都新到足以让“陈旧认知”直接导致错误判断。Google 在 2026 年 2 月 19 日 发布 Gemini 3.1 Pro,而官方模型页仍将其标注为 Preview。Anthropic 则在 2026 年 2 月 5 日 发布 Claude Opus 4.6,将其定位为最新的 Opus 级模型,也是最适合复杂推理与编码的选项。这意味着这篇对比天然是 freshness-sensitive 的:如果一篇文章还是基于 Gemini 2.5 或 Claude 4.1 时代的价格和能力假设来写,它就不仅仅是“有点旧”,而是会把你引向完全不同的架构结论。
仅看硬规格,就已经能看出决策轮廓。Google 官方模型文档为 Gemini 3.1 Pro Preview 明确列出 1,048,576 输入 token 与 65,536 输出 token。Anthropic 的 model overview 表格则为 Opus 4.6 标注 200k context 和 128k max output,而 Anthropic 的发布文章又单独说明 Opus 4.6 提供 1M token context window in beta。这些不是装饰性参数。如果你的工作负载主要由超大 prompt 组成,Gemini 的公开文档更清晰,价格也更低。如果你的工作流依赖超长生成输出,Claude 的 128k max output 就是实实在在的优势。
| 维度 | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|
| 发布日期 | 2026-02-19 | 2026-02-05 |
| 状态 | Preview | 当前旗舰模型 |
| 输入价格 | <=200k 为 $2/MTok,超过 200k 为 $4/MTok | $5/MTok |
| 输出价格 | <=200k 为 $12/MTok,超过 200k 为 $18/MTok | $25/MTok |
| 输入上下文 | 1,048,576 tokens | overview 中为 200k;发布文中为 1M beta |
| 最大输出 | 65,536 tokens | 128k tokens |
| 公开性能信号 | 更适合长上下文与成本控制 | 更适合高强度编码与自主执行 |
| 官方定位 | 更强 thinking、token efficiency、grounded 行为、software engineering、精确 tool usage | 复杂编码、agentic work、computer use、tool use、search、finance |
如果你只记住这一节的一句话,那应该是:Gemini 3.1 Pro Preview 不是“廉价版 Claude”,Claude Opus 4.6 也不是“更贵的 Gemini”。两者分别被卖给不同的失败模式。Gemini 的定价和文档定位更像一个长上下文、工具精确使用的工作马,在你跨过 200k prompt 阈值后仍然保持较强性价比。Opus 的定价则更像一种假设:它应该通过降低最难编码与高自主任务中的失败率,来把溢价赚回来。
定价与上下文:Gemini 为什么天然是性价比默认项
结论: 当成本和 prompt 规模主导决策时,Gemini 应该是默认起点。
依据: Google 公开价格为 200k 以内 $2/$12,超过后为 $4/$18,并明确给出 1,048,576 的输入上限。
怎么选: 文档分析、仓库摄入、batch 提取和高流量评估回路,优先先测 Gemini。
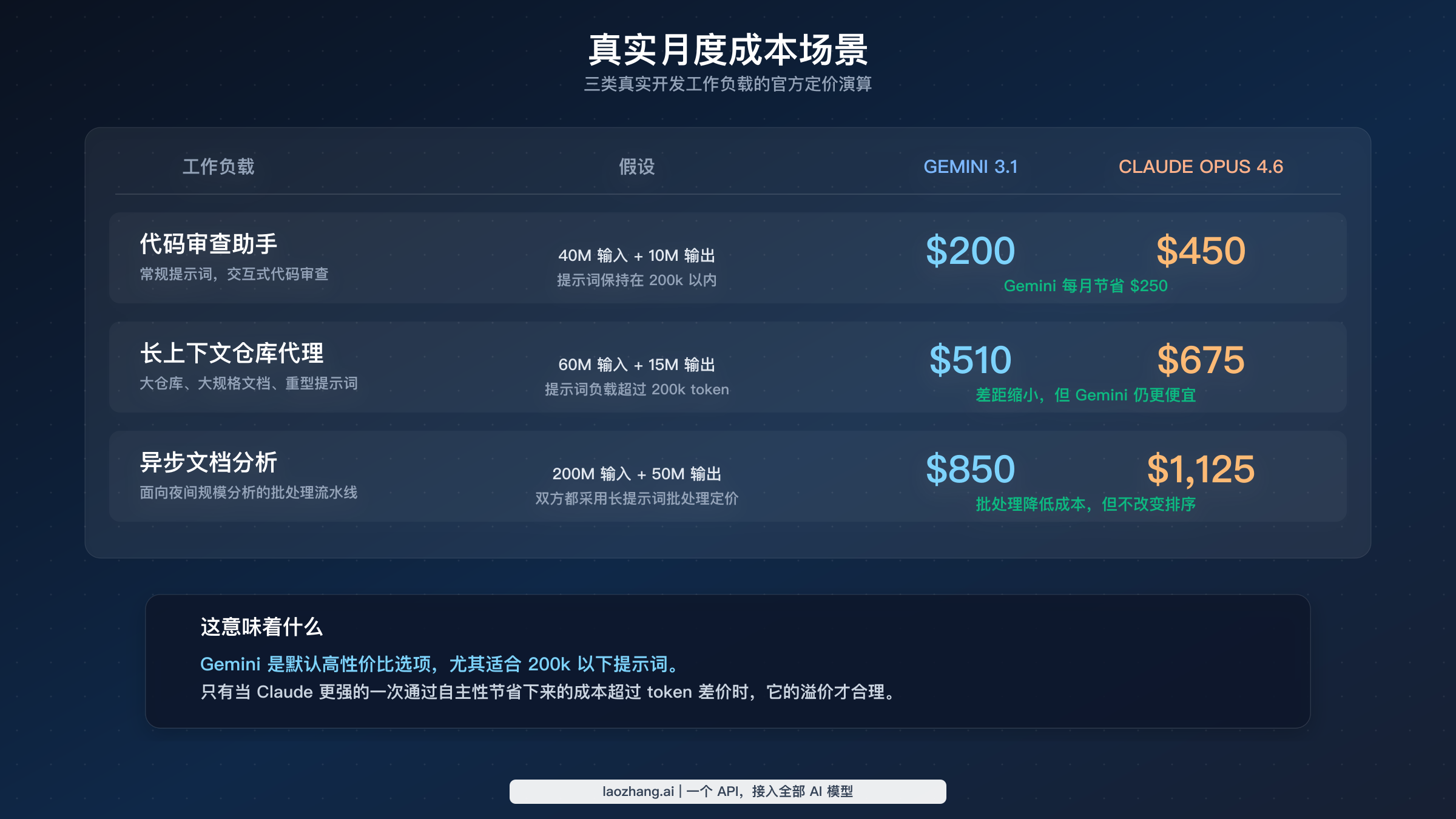
仅看 API 官方定价,Gemini 3.1 Pro Preview 一开始就拥有最明显的优势。根据 Google 的官方 Gemini 定价页,Gemini 3.1 Pro Preview 在 prompt 不超过 200k token 时,价格为 每百万 token 输入 $2.00 / 输出 $12.00;一旦超过 200k,则提升为 输入 $4.00 / 输出 $18.00。Anthropic 的官方定价文档则把 Claude Opus 4.6 定价为 输入 $5.00 / 输出 $25.00。这意味着,在常见的 <=200k 场景下,Gemini 的输入成本低 60%,输出成本低 52%。即使进入长 prompt 的高价档,Gemini 仍然在输入上便宜 20%,在输出上便宜 28%。
最重要的定价细节在于:Gemini 的优势是 带阈值的,不是绝对不变的。很多快餐式对比只引用低价档,于是会让 Gemini 看起来几乎“离谱地便宜”。但在真实生产里,关键在于你有多少请求会跨过 200k prompt token。如果你做的是普通交互式编码工具、support copilot、结构化文档问答,或者中等规模规划代理,很多请求都会停留在这个阈值以内,此时 Gemini 的价格优势会非常明显。如果你经常把巨大代码仓库、长法律材料,或者大批研究资料整体送入上下文,Gemini 的价格会提高。它仍然比 Opus 便宜,但差距就不再像“碾压”,而更像一个需要结合质量来解释的收窄优势。
Batch 与 caching 会让这个问题更有意思。Google 对 Gemini 3.1 Pro Preview 公布了 batch pricing:<=200k prompt 为 $1/$6,超过 200k 为 $2/$9。Anthropic 则把 Opus 4.6 的 batch 请求定价为 $2.50/$12.50。因此,在仓库索引、大规模提取、夜间分析等异步场景下,两家都比标准价友好得多,但 Gemini 依旧保持更低的直接成本。Caching 方面,Google 是显式的上下文缓存费用加存储费模型,Anthropic 则采用写入倍率与极低读取倍率。二者很难直接一句话比较,但结论很简单:如果你不再一遍遍发送相同的静态 prompt,上下文复用会让两家都更便宜。
把这个价格形状代入具体工作负载,会更容易理解:
| 工作负载 | 假设 | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|---|
| 代码审查助手 | 40M 输入、10M 输出,prompt <=200k | $200 | $450 |
| 长上下文仓库代理 | 60M 输入、15M 输出,prompt >200k | $510 | $675 |
| 异步文档分析(batch) | 200M 输入、50M 输出,长 prompt batch | $850 | $1,125 |
这些数字是故意做了简化的。它们 不包含 search grounding 费用、不包含缓存存储费用,也不包含任何模型质量判断。它们只是帮助你看清“价格曲线”。在普通 prompt 情况下,Gemini 的成本效率可以高出两倍以上;在长上下文场景中,Gemini 因为跨入更高价档而优势收窄;在 batch 模式下,Gemini 仍然更便宜,但已经没有便宜到让质量完全无关紧要。
上下文窗口则决定了你该如何解读这些价格。Gemini 3.1 Pro Preview 官方直接给出了 1,048,576 token 输入上限。Anthropic 的 model overview 仍然将 Opus 4.6 作为 200k context 模型呈现,这将会成为许多团队默认依据,哪怕 Anthropic 的发布文同时又说 1M-token context window 以 beta 形式存在。如果你的应用路线图把“百万 token 输入”视作正常、稳定、可依赖的生产能力,那么 Gemini 的文档显然更清晰。如果你的应用更依赖超长生成输出而不是超长输入,那 Claude 已公布的 128k 输出上限 就会成为另一边的重要理由。
还有一个经常被低估的定价细节:Google 对 Grounding with Google Search 采用单独收费,在每月一定免费额度之后另计费用;而 Anthropic 的价格页则更多强调 token、caching、fast mode、batch 与 regional inference 成本。这使得 Gemini 对 grounded search 工作流尤其有吸引力,但也意味着你在预算时不能把“token 价格”当成全部账单。对于只想先评估 Gemini 是否值得深入的人来说,单独的 Gemini 3.1 Pro Preview 访问指南 更适合作为下一步。
编码与代理工作流:Claude Opus 4.6 为什么仍然值得溢价
结论: 当一次失败的代价主要是人工返工,而不是 token 账单时,Claude Opus 4.6 更值得先测。
依据: Anthropic 围绕编码、工具调用、调试、代码审查和长时代理执行的公开论据,要比 Google 当前对 Gemini 的公开说法更直接。
怎么选: 编码代理、补丁生成、多步工具编排和调试流,优先把 Claude 放进首轮评测。
如果价格就是全部故事,那么 Gemini 早就自动获胜了。Opus 4.6 仍然值得认真评估,原因在于 Claude 的官方证据在很多昂贵 AI 系统最容易失败的地方异常强:编码、tool use 和多步代理行为。Anthropic 的发布文对此几乎没有含糊其辞。它明确说 Opus 4.6 改善了编码能力、更谨慎地规划、能更长时间维持 agentic 任务、在更大的代码库中更可靠,而且 code review 与 debugging 能力更强,能更好地发现自己的错误。这些不是泛泛的营销形容词,而是直接映射到“编码代理究竟是可靠助手还是昂贵返工源”的行为层面。
这很重要,因为选错模型的代价,很多时候 不是 token 账单,而是人工修复回路。一个长上下文模型即便便宜,如果它反复做出错误的工具调用、看漏跨文件副作用,或者需要多轮纠正才能收敛到可用修复,那么它在系统总成本上仍然可能更贵。在这种场景里,Opus 的溢价就完全合理,哪怕单看每百万 token 的价格很刺眼。一次高质量首轮结果,往往比三次中等质量的来回尝试更便宜,尤其当这些失败消耗的是开发者时间、CI 分钟和审查注意力,而不只是 token。
公开证据的不对称在这里再次变得关键。对于 Gemini 3.1 Pro Preview,Google 告诉你它在 software engineering behavior、token efficiency、groundedness 和需要精确 tool usage 的 agentic workflow 上做了优化。这当然重要,也确实相关。但至少就本文采用的官方资料而言,Google 并没有像 Anthropic 那样,公开提供同样强势、直接的“Gemini 是最佳 coding autonomy 模型”的证据。如果你正在决定:要把有限的高成本评估精力优先花在哪个模型上来测试编码产品,这种证明负担的差异就应该影响你的测试顺序。Opus 更值得优先接受高端编码评估,Gemini 更值得优先接受高性价比长上下文评估。
换句话说,Opus 4.6 的价值最强体现在模型需要 在单次请求中承担更多责任 的时候。如果模型要写 patch、协调工具、跨多个文件调试,或以用户愿意信任的方式综合高价值研究,而不是每一步都被人盯着,Opus 的溢价就更容易被证明合理。如果模型只是做长输入摄入、分类、筛选、第一轮分析,然后再交给第二个模型或人工,Gemini 的经济性通常更合适。
这也是为什么很多“赢家”文章会在真正重要的地方误导读者:它们把“编码”压缩成 benchmark 表里的一行。但真实的软件工程工作远不止生成代码。它涉及范围界定、工具选择、仓库导航、错误恢复、代码审查,以及在多步执行中保持一致性的能力。Anthropic 围绕 Opus 4.6 的叙事,正是对这个问题展开的。Google 围绕 Gemini 的叙事,则更接近长上下文、grounded、工具精确使用的工程工作流。这两者有重叠,但并不相同,而 Opus 的溢价只有在你的产品更贴近 Anthropic 这一侧时才真正成立。
长上下文、基于来源的分析与大输入:Gemini 真正领先的地方
结论: Gemini 最强的架构优势,是大输入任务里同时兼顾规模、成本和 grounded 行为。
依据: Google 公开了百万 token 输入窗口、更低的定价和清晰的 grounding 费用模型。
怎么选: 研究助手、长文档流水线、仓库解释器这类以摄入和综合为瓶颈的系统,优先先测 Gemini。
Gemini 最明确的架构优势并不是“便宜但够用”,而是它把 已公开的百万 token 输入能力、更低的价格与显式的 grounding 经济学结合在一起,使它非常容易被正当地选为大输入系统的默认模型。如果你要做内部研究工具、仓库解释器、合同分析流水线、长 transcript 智能层,或者任何那种难点在于“把大量源材料放进同一轮推理”里的工作流,Gemini 3.1 Pro Preview 从第一性原理上就极具吸引力。你不需要支付 Opus 级旗舰价格就能获得大上下文窗口,而且即便跨过 200k prompt 阈值,Gemini 的更高价格档依然在输入和输出上都低于 Claude Opus。
Google 自己的定位也强化了这种用途。模型页强调 improved token efficiency、更 grounded / factually consistent 的行为,以及需要跨真实世界任务精确 tool usage 的 agentic workflow。它读起来不像“最强自动编码器”,而更像“适合真实产品工作的强大长上下文推理引擎”。定价页还把 search grounding 的收费方式明明白白列出来,这对需要混合“大量上下文 + 最新外部信息”的应用尤其重要。不像一些厂商把 grounding 成本写得模糊,Google 迫使你在设计早期就面对这个问题。预算时它很烦,但在生产架构上它反而是好事。
而且,输入越大,Gemini 的优势就越明显。很多长上下文工作负载表面上是在“做推理”,底层其实被摄入与召回限制住:你能不能把足够多的源材料纳入同一个一致的上下文框架里。也正是在这里,官方公开的 1,048,576 输入上限,与默认 200k context 表述之间的差异变得非常重要。即使 Opus 的 1M beta context 最终在你的环境中表现良好,Gemini 依旧是那个“百万 token 故事”在公开文档中最容易被工程化落实的模型。
这并不意味着 Gemini 自动赢下最终步骤。很多系统的最佳架构恰恰是:用 Gemini 做摄入、筛选和大上下文综合,再把最难的编码或高自主动作交给 Claude。这不是过度设计,而往往是最理性的切分。长上下文分析与工具驱动执行,是两个不同瓶颈。一个模型完全可能在其中一项上更强,却不必然赢下另一项。
真正需要避免的微妙错误,是因为 Gemini 更便宜,就强行让它接管整个栈。从 Google 文档里应该得出的结论,不是“Gemini 可以替代 Claude”,而是“只要上下文规模、groundedness 和直接成本比高端首轮自主性更重要,Gemini 就应该成为默认候选项”。在很多工程组织里,这已经覆盖了相当大比例的生产流量。
生产现实:Preview、beta,以及这些标签真正意味着什么
结论: 状态标签是架构信号,不是页脚注释。
依据: Gemini 3.1 Pro 官方仍是 Preview;Opus 4.6 虽是当前旗舰,但 1M context 仍在 Anthropic 发布文中被写为 beta。
怎么选: 如果你的系统适合受控 rollout 和 fallback,Gemini 可以先上;如果你要依赖 Opus 的 1M context,应先按 beta 能力自行验证。
做出坏模型决策最快的方法,就是把状态标签当成营销边角料。它们不是。它们是部署信号。Google 官方材料仍然把 Gemini 3.1 Pro 标为 Preview,这本身就应该改变你的使用方式。Preview 并不等于“不能用”,而意味着你应该假设它会更快迭代、行为可能发生变化,而且比成熟生产基线更需要回归测试。这对内部工具、评估回路、带 fallback 的长上下文分析系统,或者你能严格控制 rollout 的产品来说完全可以接受;但如果模型是某个 mission-critical 外部流程中的唯一真相来源,这个标签就不能被轻描淡写地带过。
Anthropic 的情况不同,但并非没有风险。Opus 4.6 本身显然是当前旗舰 Claude 模型,Anthropic 的 model overview 也足够支撑正常的生产规划。但“百万 token”这件事在发布文里仍然被明确表述为 beta。这意味着团队不应在架构文档里直接写“Claude Opus 4.6 在所有环境下都拥有成熟稳定的 1M context”,除非你已在自己的环境里验证过 beta 路径。最安全、也最精确的说法仍然是:Opus 在 overview 表中的公开默认 context 为 200k,而在 Anthropic 发布文中则声明提供 1M beta context 能力。
于是,生产姿态其实很清楚:
| 部署关注点 | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|
| 官方状态信号 | Preview | 当前旗舰模型 |
| 最稳妥默认假设 | 百万 token 输入是文档产品能力的一部分 | 200k context 是公开默认值,1M 需要按 beta 能力对待 |
| 当前更合适的落点 | 长上下文内部工具、评估回路、基于来源的分析 | 高端编码代理、高自主任务、长输出综合任务 |
有意思的地方在于,只要工作负载匹配,这两个标签都不应该把你“吓退”。一个 Preview 模型完全可能是正确选择,只要它的已公开强项与你的问题高度一致,而且你为它构建了合理的回退与测试机制。一个 beta context 扩展也可以非常有用,只要你把它当成“可选容量”,而不是“隐含保证”。真正不应该做的,是把这些状态全部抹平成“都支持 1M,所以状态无关紧要”。状态很重要,因为它决定了你的架构中有多少部分,是建立在厂商仍在主动调整的行为之上。
如果你发现自己很难判断这种运维层面的细微差别到底有多重要,那通常反而说明你不该把选择写成单模型承诺。让两个模型都保持可达。在哪个阶段使用哪个模型,优先依据其文档最强的那一部分来设计。这比从不完整的对称性中硬挤出一个“永久赢家”要安全得多。
你到底该选哪一个?
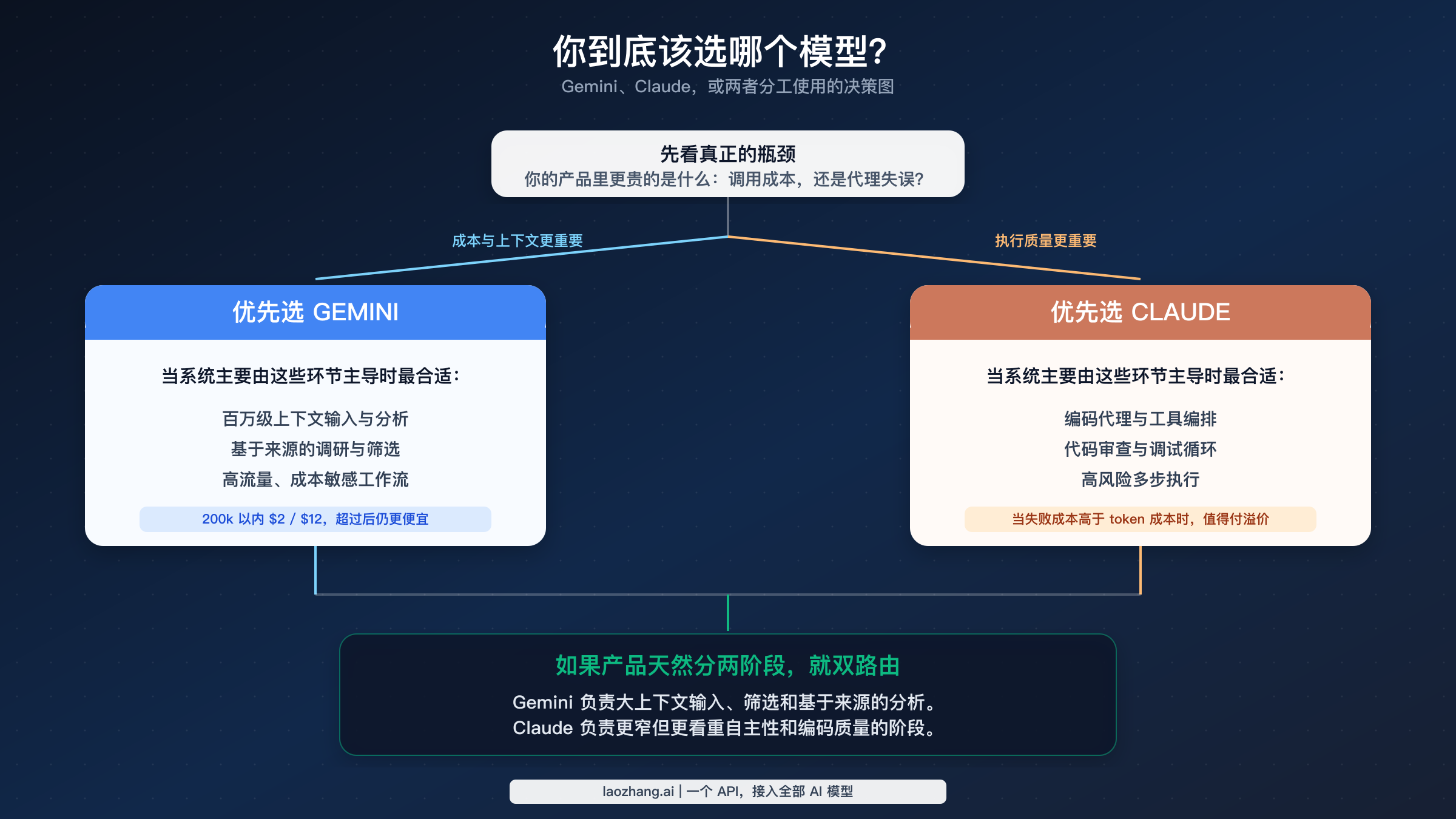
到这里,建议已经可以说得很直接了。优先选择 Gemini 3.1 Pro Preview,如果你的核心问题是:如何以合理成本处理超大 prompt 负载、构建 grounded research / 文档分析流,或者在不支付 Opus 级费用的情况下评估长上下文产品方向。对于那些大部分高流量请求都属于摄入、筛选、检索增强分析,或者第一轮工程辅助而非深度自主执行的系统,Gemini 也是更自然的起点。
优先选择 Claude Opus 4.6,如果你产品最难的部分是 agentic coding、tool orchestration、代码审查、跨大仓库 debugging,或者那种“一次高质量首轮结果比 token 账单更重要”的高价值推理任务。Anthropic 的官方证据在这里就是更强。如果模型的错误会引发人工修复、重试回路,或者让开发者迅速失去信任,那么 Claude 的溢价往往比价格表看起来更合理。
同时路由两者,如果你的系统天然就有两个阶段:一个高流量、大上下文阶段;另一个较窄但质量要求极高的执行阶段。对于 2026 年的很多技术团队来说,这很可能才是最佳答案。用 Gemini 吸收上下文、ground analysis,并便宜地处理宽漏斗输入;把 Claude 留给更窄但更高价值的那一层,在那里执行质量真正决定结果。最常见的错误,是因为“运维上更简单”,就强行让单个模型承担两种工作。
这里也恰好有一个真正有用、而不是营销式的产品切入点。如果你希望同时保留 Google 和 Anthropic,而又不想从第一天起就分别管理 key、账单和路由胶水层,那么像 laozhang.ai 这样的统一网关可以降低这部分操作开销。它的价值不是“神奇更便宜”,而是让双模型架构更容易测试与维护。
更大的规律是:2026 年最好的答案通常不是永久性的供应商选择,而是工作负载策略。如果你读到这里,发现真实问题其实比“双模型对比”更大,那下一步最有价值的不是继续找另一篇更窄的 benchmark 文章,而是回头看主流 AI 提供商 API 总对比。
怎样同时评估两个模型,而不是白白浪费一周
这类对比在网上之所以容易失真,很大原因在于团队试图靠抽象争论得出结论,而不是用严谨的评估计划。对于 Gemini 3.1 Pro Preview 与 Claude Opus 4.6,正确的评估方式绝不是“给两者各发一个炫酷 prompt,然后选看起来更顺眼的答案”。真正有意义的评估,是用那些你未来在生产里真会花钱的任务桶去同时测试它们。如果你不先把任务桶拆开,最终只会 benchmark 到错误的问题,并让架构决策过拟合 demo 任务。
最干净的做法,是建立 三条工作负载轨道。第一条是 长上下文综合轨道:长文档、长仓库、研究材料包、规格说明集合,用来暴露模型如何在大输入下摄入并推理。第二条是 编码与代理轨道:多文件修改、工具调用、debugging、代码审查,或那种需要在仓库中迭代推进的任务,用来测试模型能否在采取行动时保持一致性。第三条是 grounded analysis 轨道:模型需要使用外部信息,或交叉检查新鲜资料,而不是只在静态 prompt 内操作的任务。这三条轨道正好对应本文一直强调的取舍,也能真实测出 Gemini 的价值主张和 Claude 的高端优势各自落在哪些边界上。
一旦任务桶拆得足够干净,衡量的重点就应该是 首轮可用性,而不是抽象意义上的“回答好不好”。一个好用的评估表,通常至少包含四个数字:第一轮结果是否可用、需要多少次重试或纠正、总 token 成本,以及人工修复时间。前两项告诉你 Claude 的溢价是否真的换来了足够多的执行质量;第三项告诉你 Gemini 的低价在跨过 200k prompt 阈值后是否仍然有意义;第四项则是多数公开对比中完全缺失、但在真实团队里最重要的指标:API 账单更便宜的模型,并不一定是系统总成本更低的模型,如果你的团队每次都要花 20 分钟修正它的错误。
Gemini 的评估里还需要人为加入 prompt 长度分层。至少保留一组明确低于 200k token 的测试,再保留一组明显高于该阈值的测试。否则你很容易因为只看低价档,而得出“Gemini 便宜得离谱”这种失真的结论。对于 Claude,则要特别注意已公布的 128k max output 到底在多大程度上改变了“单次响应能完成多少工作”。如果你的产品频繁需要超长报告、超长代码改写,或者大型结构化输出,这个输出上限的重要性可能远远超过多一两行 benchmark。
评估设计最好从一开始就是 可逆的。尽量使用相同的说明、相同的评分标准,以及尽可能相同的外围基础设施。如果你已预期未来可能对两家做路由,那就让测试 harness 本身也保持 prompt 结构和成功标准的可移植性。这正是统一网关或适配层变得有价值的地方。无论你是自己做 router,还是通过像 laozhang.ai 这样的服务来完成,真正目标都不是“图省事”,而是在模型生态还在快速变化的当下,尽可能保留可选性。
认真做过这类评估之后,结果往往没有互联网标题党那么戏剧化。很多团队最终会发现:Gemini 在栈的一部分里明确更优,Claude 在另一部分里明确更优,而真正的收益来自于同时保留这两条路径。这比硬逼出一个总赢家更好,因为它给你的是一个能随价格、限制与模型行为持续变化而演进的系统设计。
真正会改变你架构的集成细节
这两款模型之间最有用的工程差异,往往不是 headline 能力,而是那些会改变你路由层、预算方式与生产监控方式的细节。
第一,Gemini 的价格阈值意味着你必须在路由前就知道 prompt 大小。 如果你的请求经常跨过 200k prompt token,就不能把 Gemini 的低 headline 价格当作常数。它并不会因此变成坏选择,只是意味着模型路由器必须把 prompt 大小纳入决策。如果系统忽略了这一点,最终很容易得到噪声很大的成本估算和错误的升级规则。
第二,Claude 的输出上限会实实在在改变你一次请求能做多少事。 Opus 4.6 公布的 128k max output 不是一个可有可无的规格表参数,它会影响你能否在单轮中完成大 patch、长报告综合,以及大型结构化输出。Gemini 的 65,536 输出限制已经不小,但它仍然明显更低。
第三,grounding 和 caching 的经济学是模型特有能力,不是笼统的“优化项”。 Google 明确列出了 search grounding 费用,这对依赖新鲜信息的应用尤为重要;Anthropic 更明确地暴露了 prompt caching 倍率与 regional inference 溢价。如果你真的关心生产经济性,就应该把这些项目单独建模,而不是把它们统统埋进“其他成本”里。
第四,在定死单一模型之前,应该先标准化你的评估 harness。 最稳妥的架构动作,是尽量让 prompt、测试用例与成功标准保持可移植。这样模型选择就始终可逆。如果你事先就知道未来可能跨两家路由,那么统一的接入层或网关——包括像 docs.laozhang.ai 这样的入口——会显著降低你维持这种可逆性的难度。
这部分真正的架构结论很简单:不要把模型选择设计成一次性的品牌归属。你应该假设上下文规模、自主性质量与价格曲线都还会继续移动,因为它们一定会继续变。
常见问题
Gemini 3.1 Pro Preview 比 Claude Opus 4.6 更便宜吗?
是的。按官方定价,Gemini 在两个价格层都更便宜。在 200k token 以内,Gemini 是 $2/$12 每 MTok,而 Opus 是 $5/$25。超过 200k 后,Gemini 升到 $4/$18,但仍然便宜,只是差距缩小。
Claude Opus 4.6 更适合编码吗?
就官方证据而言,Claude 在编码与 agentic execution 上的论据更强。Anthropic 的发布材料直接强调了 coding、debugging、code review、computer use 和长时多步代理工作。Google 也把 Gemini 定位到 software engineering,但在本文采用的官方资料里,它没有以同样强势的 benchmark 论证来支撑“最佳编码模型”的结论。
Claude Opus 4.6 到底是不是 1M context?
Anthropic 的发布文说 Opus 4.6 提供 1M token context window in beta,而 Anthropic 的 model overview 仍然在主表中写 200k context。最安全的生产解释是:200k 是公开默认值,1M 是你在依赖之前需要单独验证的 beta 能力。
Gemini 仍然是 Preview,我应该直接排除它吗?
不一定。Preview 状态应当改变你的 rollout 方式,而不是自动排除 Gemini。对于内部工具、评估回路、长上下文分析,以及那些其已公开优势高度匹配问题本身的工作负载,Gemini 仍然是很强的选择。
大多数团队应该二选一,还是同时路由两者?
很多团队最终会从路由中获益更多。Gemini 更适合作为高流量长上下文工作的第一候选,Claude 更适合作为高端编码与高自主执行的第一候选。如果你的系统同时包含这两类工作,强行给出一个永久单模型答案,通常不如把两者都保留下来更理性。