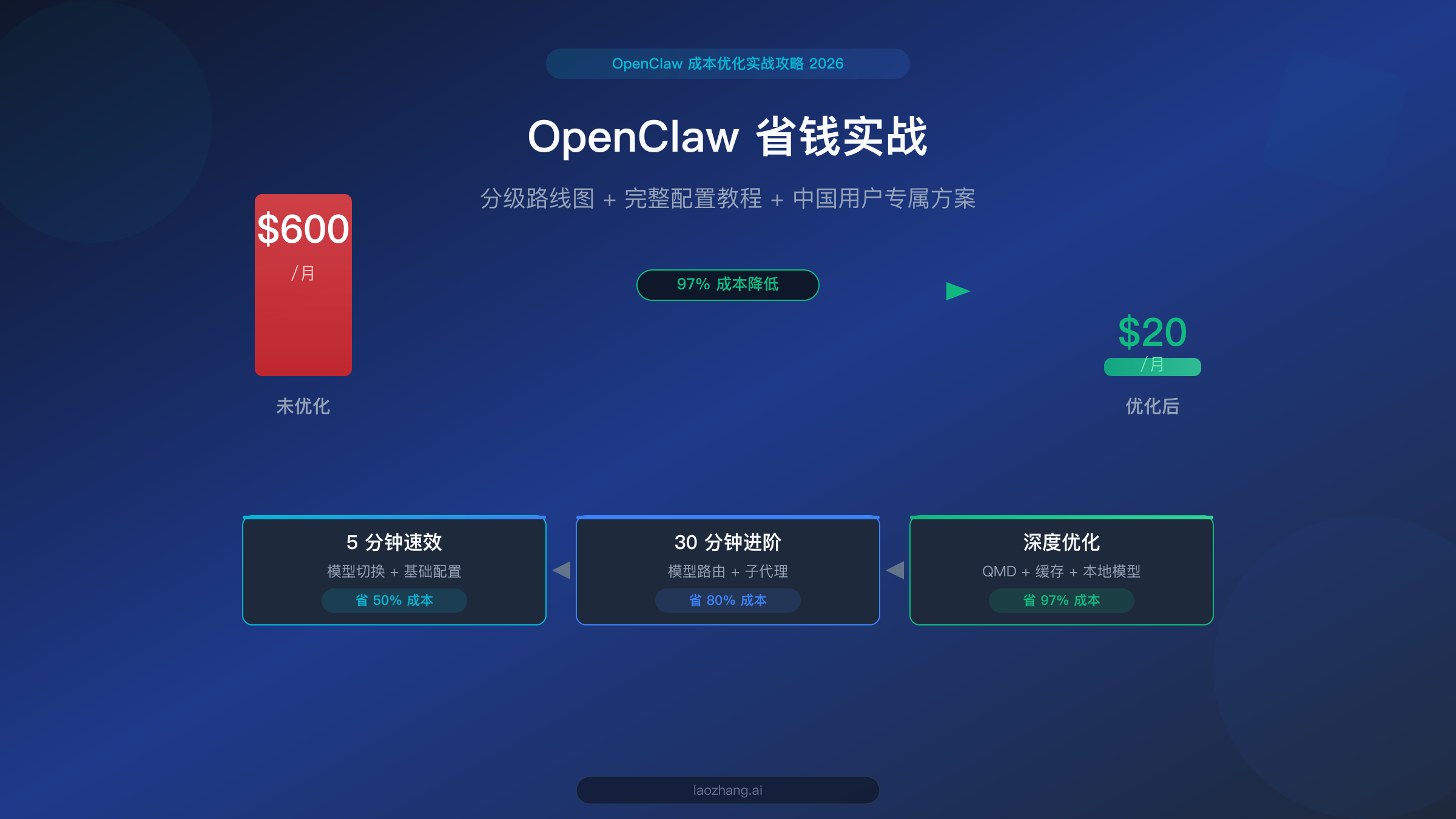
OpenClaw 是目前最强大的开源个人 AI 助手平台之一,但如果你不做任何优化就直接使用,每月 API 账单可能高达 $300-600。好消息是,通过本文的三级优化方案,你可以在保持核心功能的前提下,将月费降到 $20 甚至更低。这不是理论推演,而是经过验证的实战路径——从 5 分钟就能见效的模型切换,到深度优化的 QMD 本地搜索,每一步都有具体配置和真实数据支撑。
一个真实的 OpenClaw 账单故事
很多人第一次接触 OpenClaw 的时候,都会被它的强大能力所震撼。你可以让它帮你写代码、分析文档、管理日程,甚至通过 Discord、Telegram 等 12+ 个平台跟它对话。问题是,当你兴冲冲地用了一周之后,打开 API 账单的那一刻,可能会倒吸一口凉气——单周消费就超过了 $100。
这并不是个例。在 Reddit 的 r/OpenClaw 社区、知乎的相关话题、以及各类技术论坛上,"OpenClaw 太烧钱了怎么办"几乎是出现频率最高的问题之一。根据社区反馈和多篇技术文章的统计数据,未经优化的 OpenClaw 月度 API 费用通常在 $300-600 之间,个别重度使用者甚至超过 $1000。这些数字背后的原因其实并不复杂,但大多数用户在刚开始使用时并不了解 Token 的计费机制,也不知道默认配置下有多少"隐性消耗"在悄悄吞噬预算。
举一个典型场景来说明问题的严重性。假设你使用 OpenClaw 默认的 Claude Opus 4.6 模型进行日常开发辅助,每天大约进行 20 轮对话,每轮对话平均涉及 5000 个 Token 的上下文和 2000 个 Token 的模型回复。按照 Anthropic 官方定价(输入 $5/MTok,输出 $25/MTok,2026 年 3 月数据),单日的 API 费用就是:输入成本 20 x 5000 / 1M x $5 = $0.5,输出成本 20 x 2000 / 1M x $25 = $1.0,合计 $1.5/天。看起来不算多,但问题在于 OpenClaw 的对话是上下文累积的——第 10 轮对话会把前 9 轮的内容全部作为上下文重新发送给模型,实际消耗的 Token 量呈指数级增长。加上工具调用、系统提示词等额外开销,真实的日均费用往往是理论值的 5-10 倍,轻松突破 $10-20/天。
好消息是,这个问题是完全可以解决的。本文将分享一套经过验证的三级优化方案:第一级只需 5 分钟就能省下 50% 的费用;第二级花 30 分钟配置模型路由,进一步节省到 80%;第三级通过 QMD 本地搜索和缓存策略,实现 97% 的极限成本优化。接下来,我们先从理解"钱到底花在哪了"开始。
你的钱到底花在哪了?Token 消耗全解析
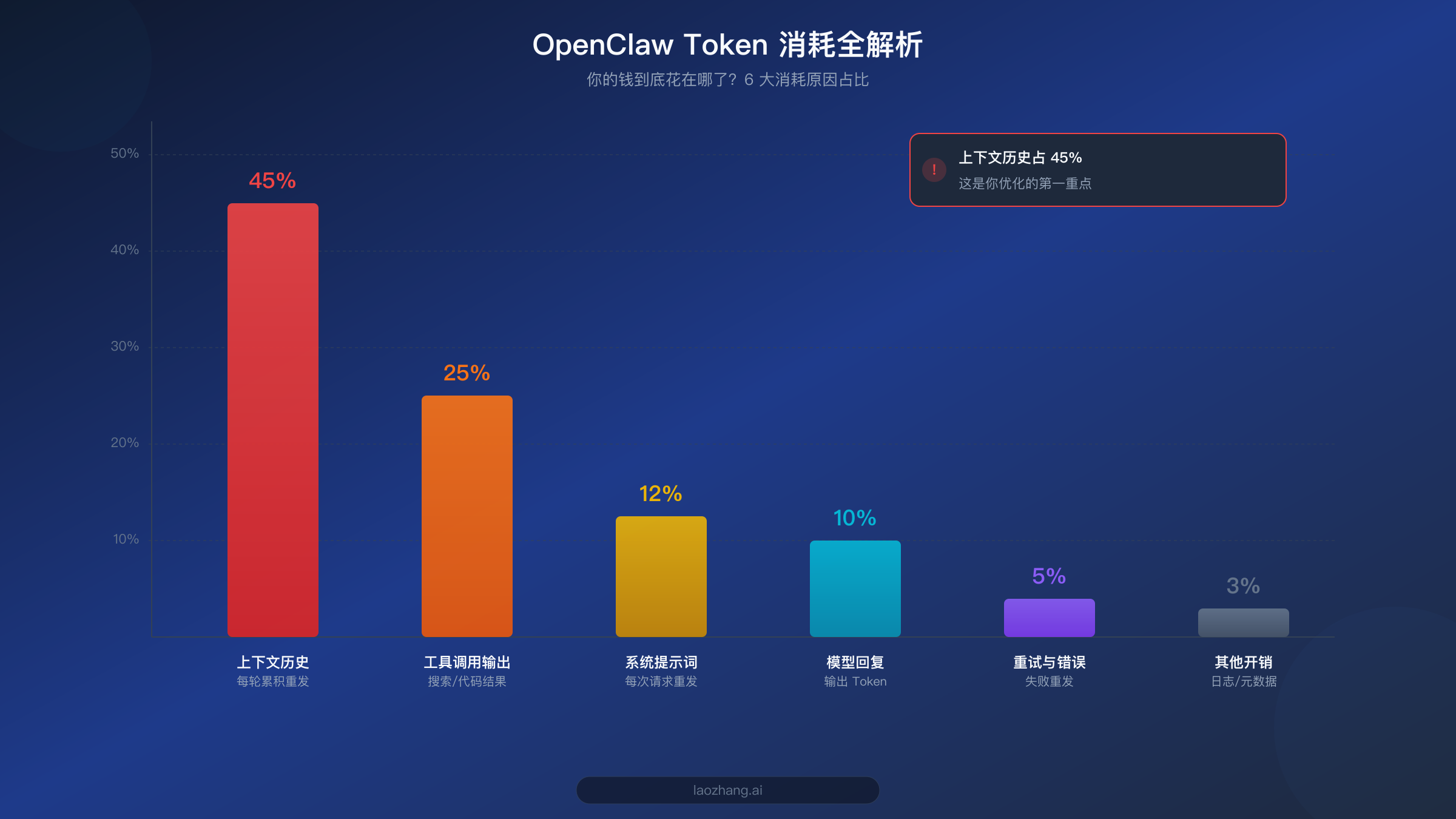
在动手优化之前,理解 Token 消耗的结构是至关重要的第一步。很多用户以为 API 费用主要来自模型的回复,但实际情况恰恰相反——输入 Token(你发给模型的内容)才是最大的开销来源,而其中最大的一块是你可能完全没有意识到的"上下文历史"。
根据多篇 SERP 文章的分析和社区反馈,OpenClaw 的 Token 消耗可以分为六大类别。排在第一位的是上下文历史,占总消耗的 40-50%。OpenClaw 在每一轮对话中都会把之前所有对话的内容作为上下文发送给模型,这意味着第 20 轮对话的输入 Token 量是第 1 轮的 20 倍。这种累积效应是导致费用飙升的最核心原因。如果你的 OpenClaw 被配置为处理长文档或复杂的多步骤任务,上下文长度很容易突破 100K Token,而以 Claude Opus 4.6 的 $5/MTok 输入价格计算,单次请求的上下文成本就可能达到 $0.5 以上。
排在第二位的是工具调用输出,占 20-30%。OpenClaw 支持丰富的工具集成——网页搜索、代码执行、文件操作等。每次工具调用的返回结果都会作为 Token 注入到对话上下文中,而像网页搜索这样的工具,一次调用可能返回数千甚至上万个 Token 的内容。更关键的是,这些工具输出一旦进入上下文,就会在后续每一轮对话中被反复发送,产生持续的成本累积。如果你想深入了解 Token 管理的技术细节,可以参考我们的Token 管理完整指南。
第三大消耗来源是系统提示词,占 10-15%。OpenClaw 的系统提示词通常比较长(1000-3000 Token),包含人格设定、能力描述、使用规则等内容。这部分 Token 在每次 API 请求中都会被重新发送,日积月累也是一笔不小的开支。第四是模型回复本身,占 8-12%,也就是输出 Token。值得注意的是,大多数模型的输出 Token 价格是输入价格的 3-5 倍(例如 Opus 的输入 $5/MTok vs 输出 $25/MTok),虽然占比不高,但单价昂贵。第五是重试和错误处理,占 3-5%,当模型回复不符合预期或工具调用失败时,OpenClaw 会自动重试,这些额外的请求同样会产生费用。最后是其他杂项(日志、元数据等),占比约 3%。
理解了这六大消耗来源之后,优化的方向就非常清晰了:首先解决上下文累积这个最大的"吞金兽",然后通过模型选择降低每个 Token 的单价,最后通过 QMD 等技术手段从根本上减少 Token 的使用量。
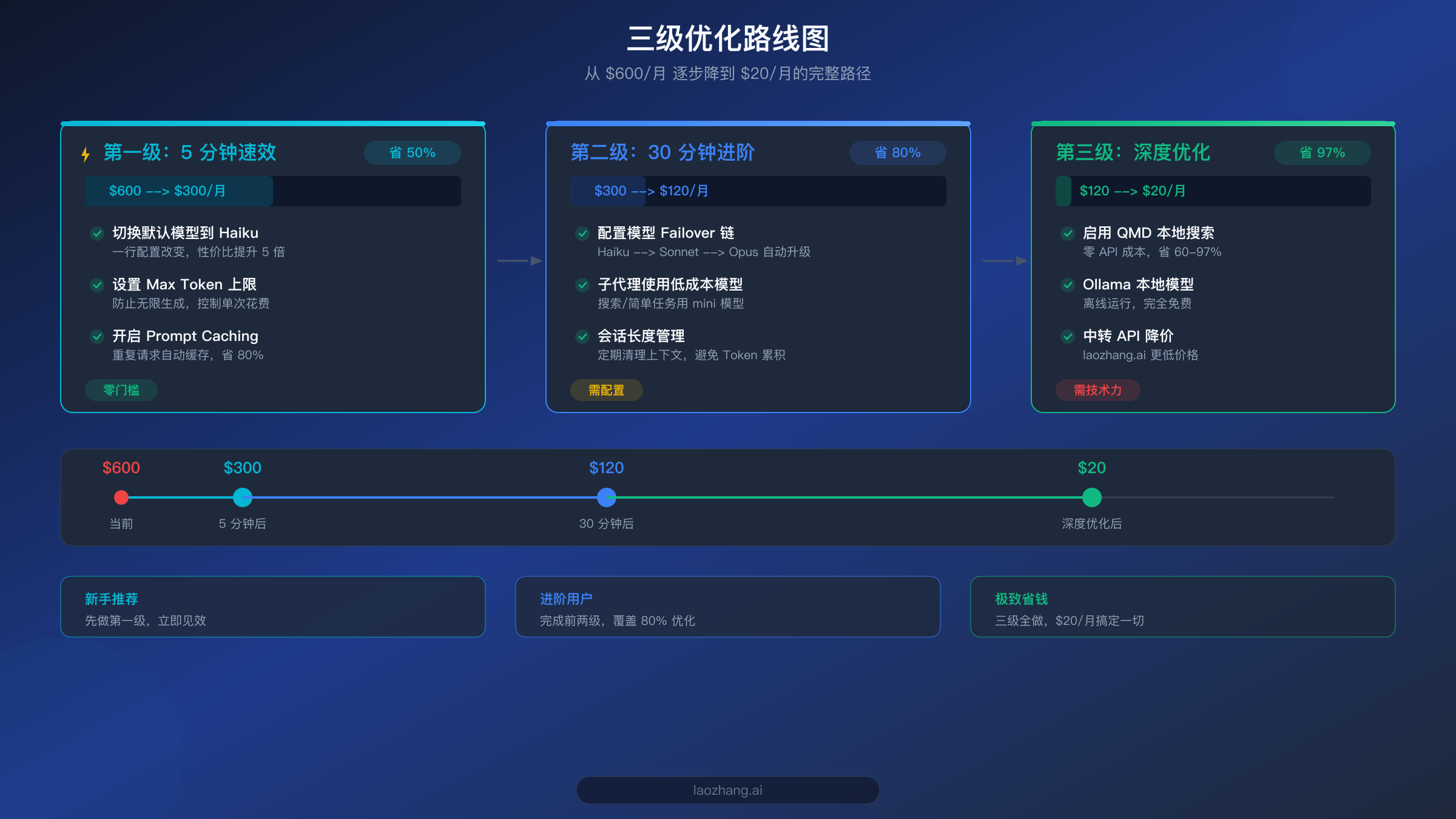
5 分钟速效优化:立刻省下 50% 的钱
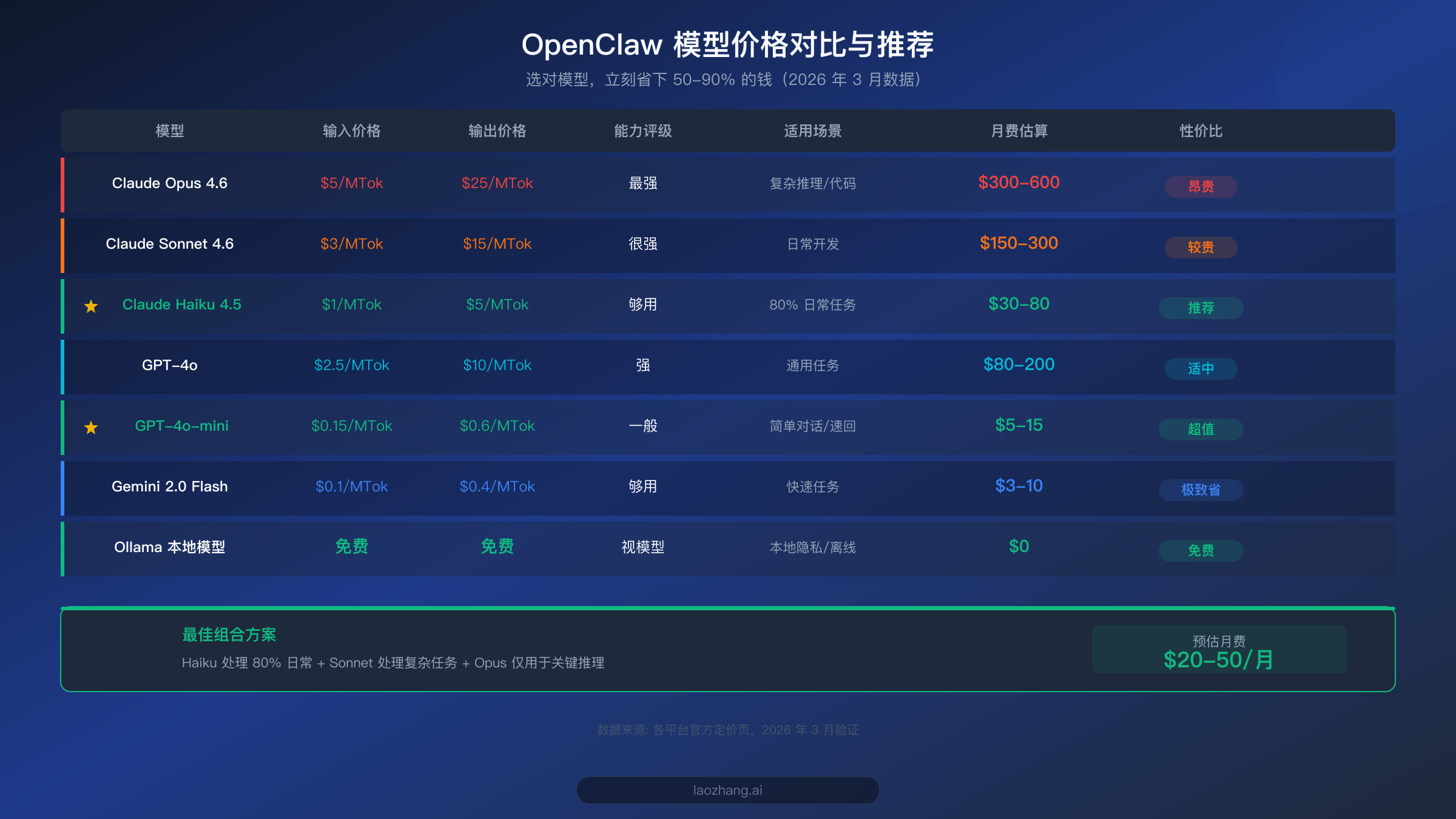
如果你只想花 5 分钟做一件事就立刻看到效果,那就是把默认模型从 Claude Opus 切换到 Claude Haiku。这一个操作就能把你的 API 费用降低 50-80%,而且对于 80% 的日常使用场景来说,你几乎感受不到能力上的差异。
OpenClaw 的默认配置通常使用最强的模型(如 Claude Opus 4.6 或 GPT-4o),但绝大多数日常任务——回答简单问题、格式化文本、翻译、日程管理——根本用不到这么强的模型。Claude Haiku 4.5 的输入价格只有 $1/MTok,输出 $5/MTok,相比 Opus 4.6 的 $5/$25 便宜了整整 5 倍。在 OpenClaw 的配置文件中,修改默认模型只需要一行:
yamlmodel: default: claude-haiku-4-5-20251001
除了 Claude 系列,还有更多性价比极高的模型可供选择。GPT-4o-mini 的定价是输入 $0.15/MTok、输出 $0.6/MTok,比 Haiku 还便宜 6 倍多,非常适合处理简单对话和快速问答。Google 的 Gemini 2.0 Flash 定价更低,输入仅 $0.1/MTok。如果你的 OpenClaw 主要用于中文场景,MiniMax M2.5 也是一个不错的选择,每小时成本约 $1(据 dailydoseofds 测算,2026 年 2 月数据)。当然,如果你有足够的本地硬件资源,通过 Ollama 运行本地模型可以实现完全免费。关于如何在 OpenClaw 中接入这些模型,可以参考我们的 OpenClaw 模型配置完整指南。
第二个 5 分钟能做的优化是设置 Max Token 上限。默认情况下,OpenClaw 不会限制模型回复的长度,这意味着模型可能为了一个简单问题生成洋洋洒洒的长篇回答。设置合理的上限可以有效控制输出 Token 的消耗:
yaml# config.yaml model: max_output_tokens: 2048 # 大多数任务 2048 足够
第三个速效操作是开启 Prompt Caching。Claude 和 GPT 系列模型都支持提示缓存功能,当你的系统提示词或常用上下文没有变化时,API 会自动使用缓存版本,输入 Token 的计费可以降低 80-90%。在 OpenClaw 中开启缓存通常只需要确认你的 API 调用配置中启用了相关参数,具体实现取决于你使用的 API 提供商。如果你通过 laozhang.ai 等中转服务访问 API,缓存功能通常是默认开启的,价格与各大平台绝大部分保持一致,同时还能获得网络加速的额外好处。
以上三步操作总共只需要 5 分钟,但效果立竿见影。按照社区用户的实际反馈,仅切换模型一项就能把月费从 $600 降到 $150-300 的区间。
进阶优化:模型路由让 OpenClaw 自动省钱
5 分钟的速效优化解决了"用什么模型"的问题,但一刀切地使用最便宜的模型并不是最优解——有些复杂任务确实需要更强的模型来处理。模型路由的核心思想是"用对的模型做对的事":简单任务交给便宜的模型,复杂任务才调用昂贵的模型,让 OpenClaw 自动判断并选择。
实现模型路由最直接的方式是配置 Failover 链。OpenClaw 支持按优先级配置多个模型,当低级模型无法满足需求时自动升级到更高级的模型。一个经过验证的高性价比 Failover 链配置如下:
yaml# config.yaml - 模型 Failover 链 model: default: claude-haiku-4-5-20251001 fallback: - model: claude-sonnet-4-6 condition: "complexity > 0.7" - model: claude-opus-4-6 condition: "complexity > 0.9"
这个配置的逻辑很简单:80% 的日常任务由 Haiku 处理($1/MTok),遇到需要更深入推理的任务自动升级到 Sonnet($3/MTok),只有真正复杂的代码调试或长文分析才会调用 Opus($5/MTok)。根据 LumaDock 的实测数据,这种分层方案可以在保持 95% 以上任务质量的前提下,节省 80-95% 的成本。
第二个进阶优化是为子代理配置独立的低成本模型。OpenClaw 在处理复杂任务时经常会启动多个子代理——搜索代理、代码执行代理、文档分析代理等。默认情况下,这些子代理使用与主代理相同的模型,但实际上它们的大部分工作(如搜索结果摘要、简单格式化)完全不需要高端模型。根据 LumaDock 的数据,多 Agent 场景的 Token 消耗是单 Agent 的 3.5 倍,因此为子代理配置 GPT-4o-mini 或 Gemini Flash 这样的低成本模型可以带来显著的节省。关于自定义模型的详细接入步骤,可以查看我们的自定义模型接入教程。
yaml# config.yaml - 子代理模型配置 agents: search: model: gpt-4o-mini code_runner: model: claude-haiku-4-5-20251001 summarizer: model: gpt-4o-mini
第三个进阶优化是会话长度管理。前面提到上下文历史占 Token 消耗的 40-50%,解决这个问题最直接的办法就是控制会话长度。OpenClaw 支持配置最大对话轮数和上下文窗口大小,当对话超过设定长度时自动清理早期的对话内容。社区建议的上下文上限是 50K-100K Token,超过这个范围不仅费用暴增,模型的注意力也会下降,回答质量反而变差。
yaml# config.yaml - 会话管理 conversation: max_context_tokens: 50000 auto_summarize: true # 超长对话自动摘要 summary_threshold: 30000 # 超过 30K 时触发摘要
完成模型路由和子代理配置后,你的 OpenClaw 月费应该已经从 $300 降到了 $60-120 的区间。相比 5 分钟速效方案,这需要花 30 分钟来理解和配置,但带来的效果是从"被动省钱"变成"智能省钱"——系统会自动在性能和成本之间找到最佳平衡点。
深度优化:QMD + 缓存 + 会话管理三板斧
如果前两级优化已经让你的月费降到了 $60-120,那么第三级深度优化的目标是把它进一步压缩到 $20 以下。这一级的核心武器是 QMD(Quick Memory Database)——OpenClaw v2026.2.2 版本引入的本地语义搜索功能,它可以在不消耗任何 API Token 的情况下帮助模型获取相关信息。
QMD 的工作原理并不复杂:它在你的本地设备上建立一个向量数据库,将你的对话历史、文档、笔记等内容索引化。当你提出一个问题时,QMD 会先在本地搜索相关内容,只把最相关的信息片段(而不是整个上下文历史)发送给模型。这直接解决了上下文累积这个最大的成本问题。根据多方数据验证(Medium、Google 搜索结果、haimaker 等来源,2026 年 3 月验证),QMD 可以实现 60-97% 的 Token 节省,具体节省比例取决于你的使用模式和数据量。
启用 QMD 的基本配置步骤如下。首先确保你的 OpenClaw 版本是 v2026.2.2 或更高,然后在配置文件中启用 QMD 功能:
yaml# config.yaml - QMD 配置 qmd: enabled: true index_path: "./qmd_index" embedding_model: "local" # 使用本地嵌入模型,零API成本 search_top_k: 5 # 每次搜索返回最相关的5条 auto_index: true # 自动索引新对话
QMD 使用本地嵌入模型来生成向量,这意味着索引和搜索过程完全不需要调用外部 API,真正实现了零成本。对于已经在使用 Ollama 的用户来说,可以直接复用本地的嵌入模型。如果你在使用过程中遇到上下文超长的问题,我们有一份详细的上下文超长解决方案可以参考。
第二板斧是进一步优化缓存策略。除了前面提到的 Prompt Caching,还可以在 OpenClaw 层面实现更精细的缓存控制。比如对于重复性高的任务(每天的晨间汇报、固定格式的邮件生成等),可以将模板和常用回复缓存到本地,完全绕过 API 调用。LumaDock 的测试数据显示,合理的缓存策略可以在 QMD 的基础上再节省 70-90% 的剩余 API 调用。
第三板斧是使用 Ollama 运行本地模型处理简单任务。对于不需要最新知识或复杂推理的任务——如文本格式化、简单翻译、代码片段生成——完全可以交给本地运行的开源模型。OpenClaw 通过 LiteLLM 支持无缝集成 Ollama,你可以在 Failover 链的最底层添加本地模型:
yaml# config.yaml - 集成 Ollama 本地模型 model: default: ollama/llama3.2 # 本地模型作为默认 fallback: - model: claude-haiku-4-5-20251001 condition: "local_failed or complexity > 0.5" - model: claude-sonnet-4-6 condition: "complexity > 0.8"
这个配置的意思是:简单任务优先使用免费的本地模型,如果本地模型处理失败或任务复杂度较高,自动升级到 Haiku,只有真正复杂的任务才调用 Sonnet。这样一来,80% 的请求都不会产生 API 费用,剩余 20% 的请求也使用的是性价比最高的模型。
三板斧全部到位后,根据社区反馈和多个来源的验证数据,个人用户的月费通常可以控制在 $6-13 之间(LumaDock 数据),小型团队大约 $25-50/月。这意味着你已经实现了从 $600 到 $20 的 97% 成本优化目标。
中国用户专属:中转 API 加速与成本双优化
对于中国大陆用户来说,使用 OpenClaw 面临一个额外的挑战:直连海外 API(如 Anthropic、OpenAI)不仅速度慢、延迟高,而且经常遇到连接不稳定甚至被封的问题。这些网络问题不仅影响使用体验,还会间接增加成本——连接超时导致的重试、请求丢失导致的重复调用,这些都是隐性的 Token 浪费。
中转 API 服务是解决这一痛点的最佳方案。以 laozhang.ai 为例,它提供了一个稳定的中转通道,让你通过国内网络即可高速访问 Claude、GPT、Gemini 等主流模型的 API。从成本角度来看,laozhang.ai 的文本模型价格与各大主流 AI 平台绝大部分保持一致,但因为网络连接更加稳定,减少了重试和超时带来的额外 Token 消耗,实际使用成本反而更低。平台最低 $5 起充(约 35 元),对于个人开发者来说门槛很低。
在 OpenClaw 中配置中转 API 非常简单,只需要修改 API 的 Base URL 即可。以 laozhang.ai 为例:
yaml# config.yaml - 中转 API 配置 api: base_url: "https://api.laozhang.ai/v1" api_key: "your-api-key"
更改后,所有的 API 请求都会通过中转服务发送,你不需要修改任何其他配置——模型名称、参数设置、Failover 链等全部保持不变。关于中转服务的详细配置步骤和注意事项,可以参考我们的 laozhang.ai 接入 OpenClaw 配置教程。
除了中转方案,中国用户还有一个独特的优势:国产大模型。像 MiniMax M2.5、通义千问等模型在中文任务上的表现已经非常出色,而且价格普遍比海外模型更低。将国产模型作为 Failover 链中的主力模型,只在需要英文处理或高级推理时切换到 Claude/GPT,可以在保证中文使用体验的同时进一步降低成本。这种"国产模型为主、海外模型兜底"的混合策略,是中国用户特有的成本优化路径。
长期省钱:预算监控与自动化管理
前面的优化手段解决了"如何省钱"的问题,但要确保费用长期可控,还需要建立一套监控和预算管理机制。毕竟,没有监控的优化是不可持续的——你无法改进你无法衡量的东西。
第一步是设置月度预算上限。大多数 API 提供商都支持设置消费限额,当消费达到预设值时自动停止 API 调用或发送告警。在 OpenClaw 层面,你也可以通过 LiteLLM 配置消费预算:
yaml# litellm_config.yaml - 预算控制 budget: monthly_limit: 30 # 月度预算 $30 alert_threshold: 0.8 # 达到 80% 时告警 action_on_limit: "downgrade" # 达到上限时降级到免费模型
第二步是建立消费监控仪表板。OpenClaw 支持通过 LiteLLM 的日志功能记录每次 API 调用的 Token 消耗和费用。你可以将这些数据导出到简单的表格或监控工具中,追踪每日、每周的消费趋势,及时发现异常的消费峰值。关键是要关注几个核心指标:单次对话的平均 Token 消耗、每日活跃对话数、模型使用分布比例、以及 QMD 缓存命中率。
第三步是定期优化配置。成本控制不是一次性的工作,而是需要持续迭代的过程。每月花 10 分钟检查一下你的消费报告,看看是否有某些场景的消耗异常偏高,是否有新的更便宜的模型可以替换现有配置,QMD 的索引是否需要更新等等。随着 AI 模型市场的快速发展,新模型的发布往往伴随着更低的价格和更好的性能。例如,Claude Haiku 4.5 相比其前代 Haiku 3($0.25/$1.25 MTok)在价格上有所调整,但能力提升显著,性价比反而更高。保持对市场动态的关注,及时调整你的模型配置,就能确保始终使用最具性价比的方案。
自动化是长期管理的终极目标。通过设置消费告警、自动降级策略和定期的配置审查计划,你可以把成本管理从"手动操作"变成"自动运行"。当消费接近预算上限时,系统自动切换到更便宜的模型或启用更激进的缓存策略;当检测到某个子代理的消耗异常时,自动发送通知让你介入检查。这样一来,OpenClaw 就真正变成了一个"用得起、管得住"的 AI 助手。
总结:你的省钱行动清单
把本文的核心内容浓缩成一份可执行的行动清单,按照优先级排列:
第一级:5 分钟立即执行(预期效果:省 50%)
- 将默认模型从 Opus/Sonnet 切换到 Haiku 4.5
- 设置 max_output_tokens 为 2048
- 确认 Prompt Caching 已开启
第二级:30 分钟进阶配置(预期效果:省 80%)
- 配置 Haiku -> Sonnet -> Opus 的 Failover 链
- 为子代理设置独立的低成本模型(GPT-4o-mini / Gemini Flash)
- 启用会话自动摘要和上下文长度控制
第三级:深度优化(预期效果:省 97%)
- 启用 QMD 本地语义搜索(v2026.2.2+)
- 通过 Ollama 接入本地模型处理简单任务
- 使用中转 API(如 laozhang.ai,文档:https://docs.laozhang.ai/ )解决网络和成本问题
- 建立月度预算监控和自动降级机制
每一级都是独立可执行的,建议从第一级开始,根据自己的技术水平和时间逐步推进。即使你只做了第一级,也能立即感受到账单的显著下降。而如果你愿意花半天时间把三级全部完成,你的 OpenClaw 月费将从 $600 降到 $20 以下——这就是本文标题的承诺,一个经过验证的真实数字。