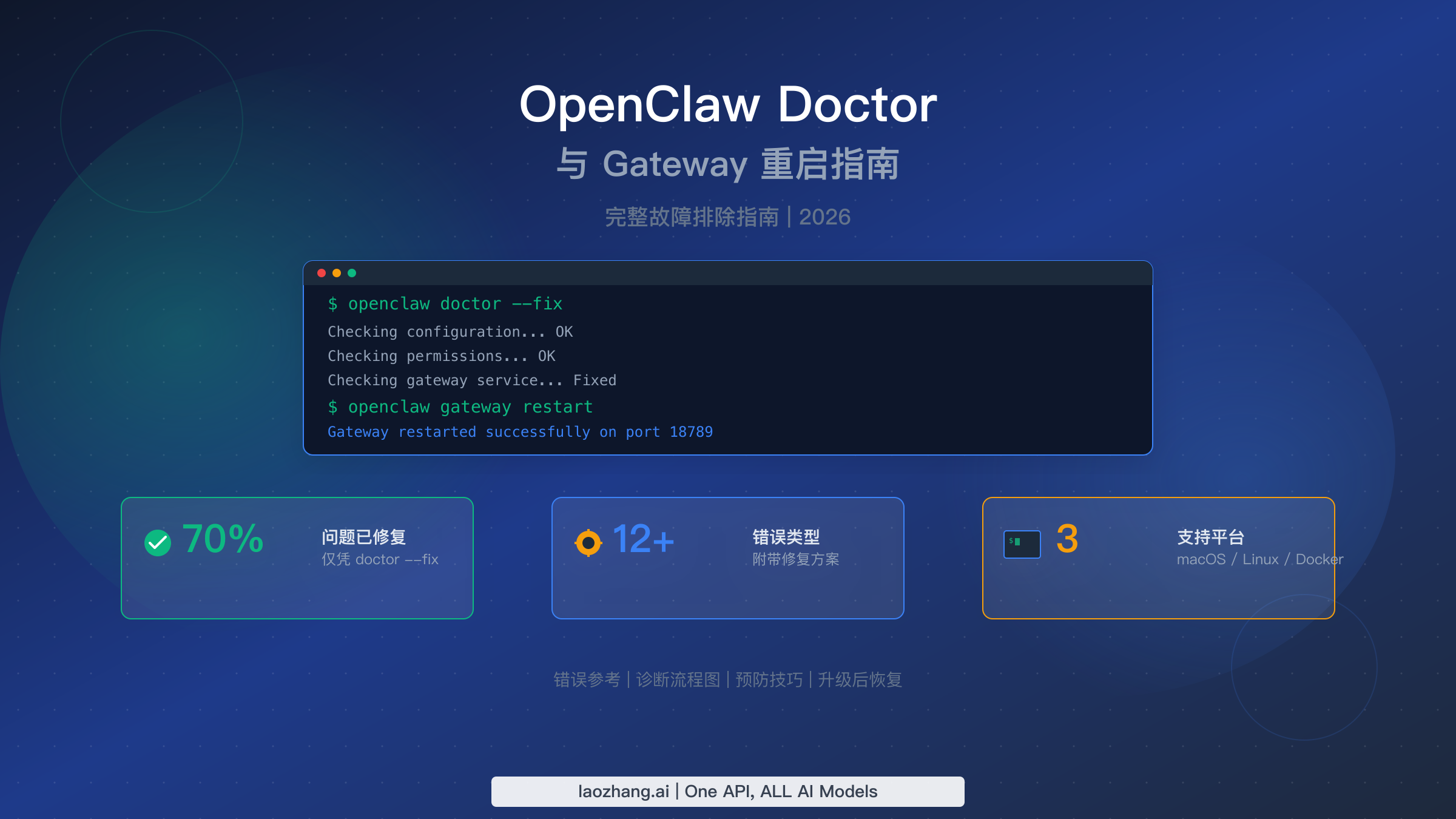
OpenClaw 的 openclaw doctor --fix 命令会审计并自动修复配置漂移问题,根据社区分析(ClawTank,2026 年 3 月),该命令可以解决大约 70% 的网关问题。配合 openclaw gateway restart,这两条命令构成了 OpenClaw 故障排除的基础。本指南涵盖你可能遇到的每一条错误信息、macOS、Linux 和 Docker 的平台专属修复方案、升级后的恢复流程,以及预防性维护策略——所有内容均已基于 2026 年 3 月的 OpenClaw 官方文档进行验证。
要点速览
运行以下两条命令即可修复大多数 OpenClaw 网关问题:
bashopenclaw doctor --fix openclaw gateway restart
这个组合可以自动解决大约 70% 的网关问题。如果网关仍然无法启动,请运行 openclaw gateway status 来确定问题属于服务已停止、RPC 探针失败还是配置错误,然后按照下方的诊断流程图操作。最常见的根本原因是端口冲突(45%)、服务未运行(30%)和配置错误(15%)。
30 秒修复——解决 70% 网关问题的万能方案
当你的 OpenClaw 网关停止响应时,本能反应是去翻日志文件和配置设置。请先忍住这个冲动三十秒。最快的恢复路径几乎总是同样的两条命令组合,而理解它为什么如此有效将在未来为你节省数小时的调试时间。
openclaw doctor --fix 命令会对你的 OpenClaw 安装执行全面审计。它检查目录结构、验证文件权限、校验 ~/.openclaw/openclaw.json 配置文件、确认所需服务已正确注册,并确保端口绑定与你声明的设置一致。当它发现问题时——在一个典型的故障网关中,通常有一到两个配置错误——它会自动修正这些问题。--fix 标志是让这个命令变得强大而不仅仅是提供信息的关键;没有它,doctor 只会报告问题而不会解决它们。
在 doctor 命令之后执行 openclaw gateway restart 可以确保网关进程加载刚刚应用的所有修正。重启过程是干净的:它优雅地停止现有网关进程(发送 SIGTERM,然后等待正在进行的 WebSocket 连接排空),然后使用修正后的配置启动一个全新的实例。你的渠道连接——WhatsApp、Slack、Discord、Telegram 等——会短暂断开并在几秒钟内自动重新连接。
这种两条命令的方式之所以经常有效,是因为大多数网关故障源于配置漂移而非根本性的系统问题。当你更新 OpenClaw、安装新插件、更改模型配置或修改渠道设置时,小的不一致性会逐渐积累。某个权限可能被收紧了,某个目录可能还不存在,或者某个配置键可能引用了已废弃的 schema。doctor 命令专门针对这些漂移场景,这就是为什么社区报告仅靠这种方式就有大约 70% 的成功率。
如果运行这些命令后网关成功启动,你的工作就完成了。如果没有,请继续阅读下方的诊断部分以确定具体的故障模式。
openclaw doctor 和 gateway restart 的实际工作原理
理解这些命令背后的机制可以消除故障排除中的神秘感,并帮助你决定何时独立使用每个命令。它们不是可互换的工具——它们服务于根本不同的目的,了解这个区别可以防止你运行不必要的命令,或者更糟的是,跳过你真正需要的那个命令。
openclaw doctor 命令作为配置审计器运行。当你运行它时,进程会读取你的安装目录(通常是 ~/.openclaw/)、系统服务配置和运行时环境。它会对照一组预期条件检查每个组件:配置文件是否能正确解析?所有引用的目录是否存在且可写?网关服务是否以正确的二进制路径注册?声明的端口是否与服务文件中指定的一致?每项检查会产生通过、警告或失败的结果。使用 --fix 标志时,失败会触发自动修正操作——创建缺失的目录、重写格式错误的服务文件或重置文件权限。不使用 --fix 时,你会得到一份诊断报告,可以手动处理,这在你想先了解问题再做更改时有时更可取。
相比之下,openclaw gateway restart 命令纯粹是一个服务生命周期操作。它不会检查或修复配置。它向正在运行的网关进程发送停止信号,等待其退出(默认超时 60 秒),然后启动一个新进程。网关可执行文件在启动时读取 ~/.openclaw/openclaw.json,绑定到配置的端口(默认 18789),并开始接受 WebSocket 连接。如果重启时配置文件包含错误,新进程将无法启动——这正是在重启之前运行 doctor --fix 如此有效的原因。
在此背景下还有一个值得一提的命令:openclaw gateway install --force。这个命令将网关重新注册为系统服务(macOS 上的 LaunchAgent,Linux 上的 systemd 用户服务),覆盖所有现有的服务定义。它比简单的重启更激进,在服务注册本身已损坏时特别有用——这种场景偶尔会在操作系统更新后或在 OpenClaw 版本之间切换时发生。如果你发现正在处理一个已更改的 OpenClaw API 密钥配置,运行 install --force 后再 restart 可以确保服务完全加载新设置。
一个重要区别:openclaw doctor 作为一次性诊断进程运行并退出。而网关是一个长时间运行的守护进程。运行 doctor 不会影响当前运行的网关,除非 --fix 标志重写了网关所依赖的服务文件,这种情况下需要重启才能应用更改。
60 秒内诊断你的问题
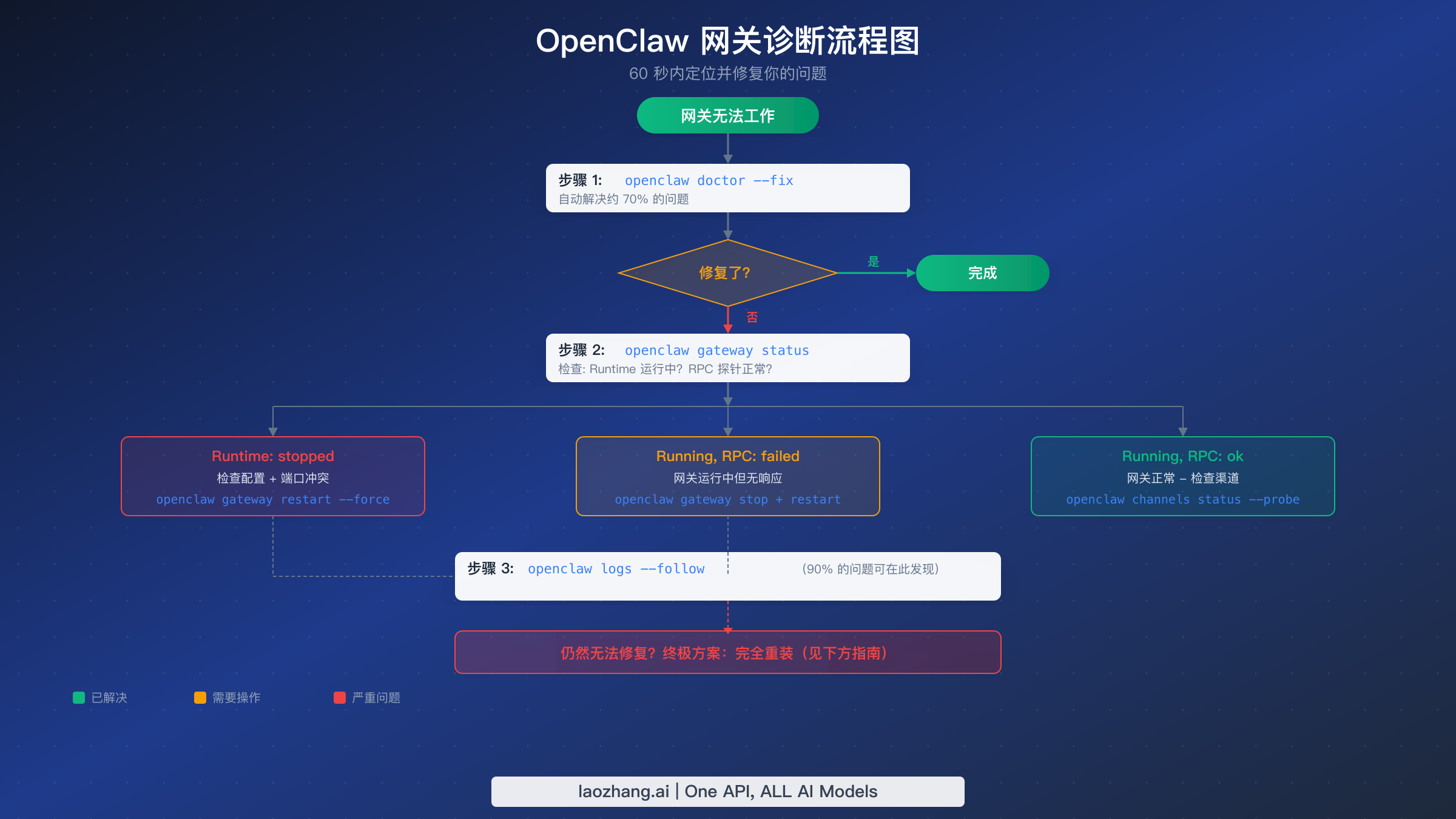
当万能修复方案无法解决你的问题时,下一步是系统性地确定到底是什么出了问题。OpenClaw 内置的诊断命令提供结构化输出,直接指向故障模式,所以你不需要猜测。本节将带你了解确切的命令序列及其输出的含义。
首先运行 openclaw gateway status。这是故障排除工具包中信息量最大的单条命令。它的输出告诉你两个关键信息:网关进程是否在运行,以及它是否接受连接。健康的网关会显示 Runtime: running 和 RPC probe: ok。任何偏离这个模式的情况都表明存在特定的问题类别。
如果你看到 Runtime: stopped,说明网关进程根本没有在运行。这通常意味着服务启动失败(检查配置错误)、进程崩溃了(检查日志中的崩溃输出),或者服务从未安装过。最常见的原因是阻止启动的配置问题,例如 gateway.mode 没有设置为 local(用于仅本地部署)。运行 openclaw config get gateway.mode 来验证这个设置,如果它返回空值或非 local 的值,请用 openclaw config set gateway.mode local 来设置。
如果你看到 Runtime: running 但 RPC probe: failed,说明网关进程存活但没有响应健康检查。这是一个更微妙的问题,通常表明以下三种情况之一:网关仍在初始化中(等待 60 秒,特别是在 Docker 上,初始化大约需要 40 秒)、网关绑定到了与预期不同的端口(检查 openclaw config get gateway.port),或者进程陷入了死锁状态。对于最后一种情况,解决方法是 openclaw gateway stop --force 后跟 openclaw gateway start。
检查网关状态后,下一个诊断命令是 openclaw logs --follow。这个命令实时追踪网关日志文件,根据社区报告,它能揭示大约 90% 剩余问题的根本原因。日志条目带有时间戳和分类,所以请在输出中查找标记为 ERROR 或 FATAL 的条目。常见模式包括权限拒绝错误(进程无法读取文件或绑定端口)、连接被拒绝错误(上游服务或 API 端点不可达),以及配置验证失败(缺少必需字段或格式错误)。
对于网关正在运行但消息未能传递的渠道特定问题,使用 openclaw channels status --probe。这个命令独立测试每个已配置渠道的连接,并报告哪些是健康的、哪些正在失败。如果所有渠道都显示已连接但消息仍然没有流动,问题可能是配对或提及配置问题而非网关故障——检查你的 DM 策略设置和群组提及模式。
每种网关错误及其修复方法

本节是一个查找表。找到你看到的错误信息,了解它为什么发生,然后应用有针对性的修复。每个条目都包含解决问题的确切命令和成功解决后的预期输出。所有修复方案均已基于 2026 年 3 月的 OpenClaw 官方文档和社区报告进行验证。
"Gateway start blocked: set gateway.mode=local"
这是首次安装中最常见的错误。OpenClaw 的网关在你明确声明操作模式之前拒绝启动。默认行为是阻止启动而不是假设一个潜在不安全的配置。要解决这个问题,运行 openclaw config set gateway.mode local,然后运行 openclaw gateway restart。local 模式将网关限制为仅接受回环连接,这适用于单机部署。如果你需要远程访问,请将 gateway.mode 配置为 remote,并使用 openclaw config set gateway.auth.token YOUR_TOKEN 设置适当的认证。
"Timed out after 60s waiting for gateway port 18789 to become healthy"
网关进程已启动,但在默认的 60 秒窗口内未开始接受连接。在资源受限的系统上——特别是小型 VPS 实例上的 Docker 容器——初始化确实需要超过 60 秒。首先要检查的是进程是仍在启动中还是在初始化期间崩溃了。看到此错误后立即运行 openclaw gateway status。如果运行时显示为 running,再等 30-60 秒后重新检查。如果显示为 stopped,请用 openclaw logs --follow 检查日志以查找具体的启动失败原因。在 Docker 部署中,仅容器初始化就需要大约 40 秒,只给网关留下 20 秒来启动——在 1 vCPU 的机器上很紧张。为你的 VPS 添加 1GB 交换空间通常可以永久解决这些超时问题。
"Another gateway instance is already listening on port 18789"
端口冲突发生在两个进程试图绑定同一端口时。这种情况最常发生在从旧的 Clawdbot 命名升级到 OpenClaw 之后,旧的 clawdbot-gateway 服务可能仍在与新的 openclaw-gateway 服务同时运行。要识别冲突的进程,运行 lsof -i :18789(macOS/Linux)或 ss -tlnp | grep 18789(Linux)。杀掉旧进程,然后重启:openclaw gateway restart。为防止再次发生,请确保旧服务已完全卸载:在 Linux 上,systemctl --user disable clawdbot-gateway.service && systemctl --user stop clawdbot-gateway.service;在 macOS 上,从 ~/Library/LaunchAgents/ 删除旧的 LaunchAgent plist 文件。
"Refusing to bind gateway on 0.0.0.0 without auth"
OpenClaw 正确地阻止了没有认证的非回环绑定,以防止未授权访问。如果你有意让网关可以从其他机器访问(用于通过仪表板或移动客户端远程访问),你必须先配置认证:openclaw config set gateway.auth.mode token 然后 openclaw config set gateway.auth.token YOUR_SECURE_TOKEN。如果你在本地运行且不需要远程访问,请将绑定设置为仅回环:openclaw config set gateway.bind loopback。
"AUTH_DEVICE_TOKEN_MISMATCH" 或 "PAIRING_REQUIRED"
网关重启后,现有的客户端连接可能会丢失设备配对。这是 GitHub Issue #22062 中记录的已知问题。修复很简单:在每个显示此错误的客户端上,重新执行配对流程。对于 CLI 客户端,使用 openclaw pair。对于 Web 仪表板,导航到配对页面并扫描二维码。为了在计划重启期间减少配对中断,可以考虑使用 gateway.auth.mode password 选项,它避免了每台设备的令牌轮换。
"HTTP 429: rate_limit_error: Extra usage is required for long context requests"
此错误来自上游的 Anthropic API,而非 OpenClaw 本身。当你使用的模型启用了 params.context1m: true 但你的 API 密钥没有长上下文访问权限时,就会出现这个错误。解决方法是禁用扩展上下文窗口(openclaw config set agents.defaults.models.context1m false),或者确保你的 Anthropic API 密钥有活跃的计费且具备长上下文资格。如果你需要可靠的 API 访问而不想管理各个提供商的密钥,可以考虑使用像 laozhang.ai 这样的聚合 API 服务,它处理提供商轮换并减少速率限制的影响面——你可以在我们的 OpenClaw 与 laozhang.ai 集成指南中找到完整的设置流程。更多关于修复 OpenClaw 429 速率限制错误的详情,请参阅我们的专用故障排除文章。
"NODE_BACKGROUND_UNAVAILABLE" 或 "SYSTEM_RUN_DENIED"
这些错误表示网关正在运行,但 OpenClaw 的节点工具(浏览器自动化、系统命令)无法执行。使用 openclaw nodes status 检查节点状态。如果节点离线,请重启它。如果节点在线但权限被拒绝,请检查节点的工具白名单和操作系统级权限(macOS 上的摄像头、麦克风、屏幕访问需要在系统偏好设置中明确授权)。
平台专属修复方案(macOS、Linux、Docker)
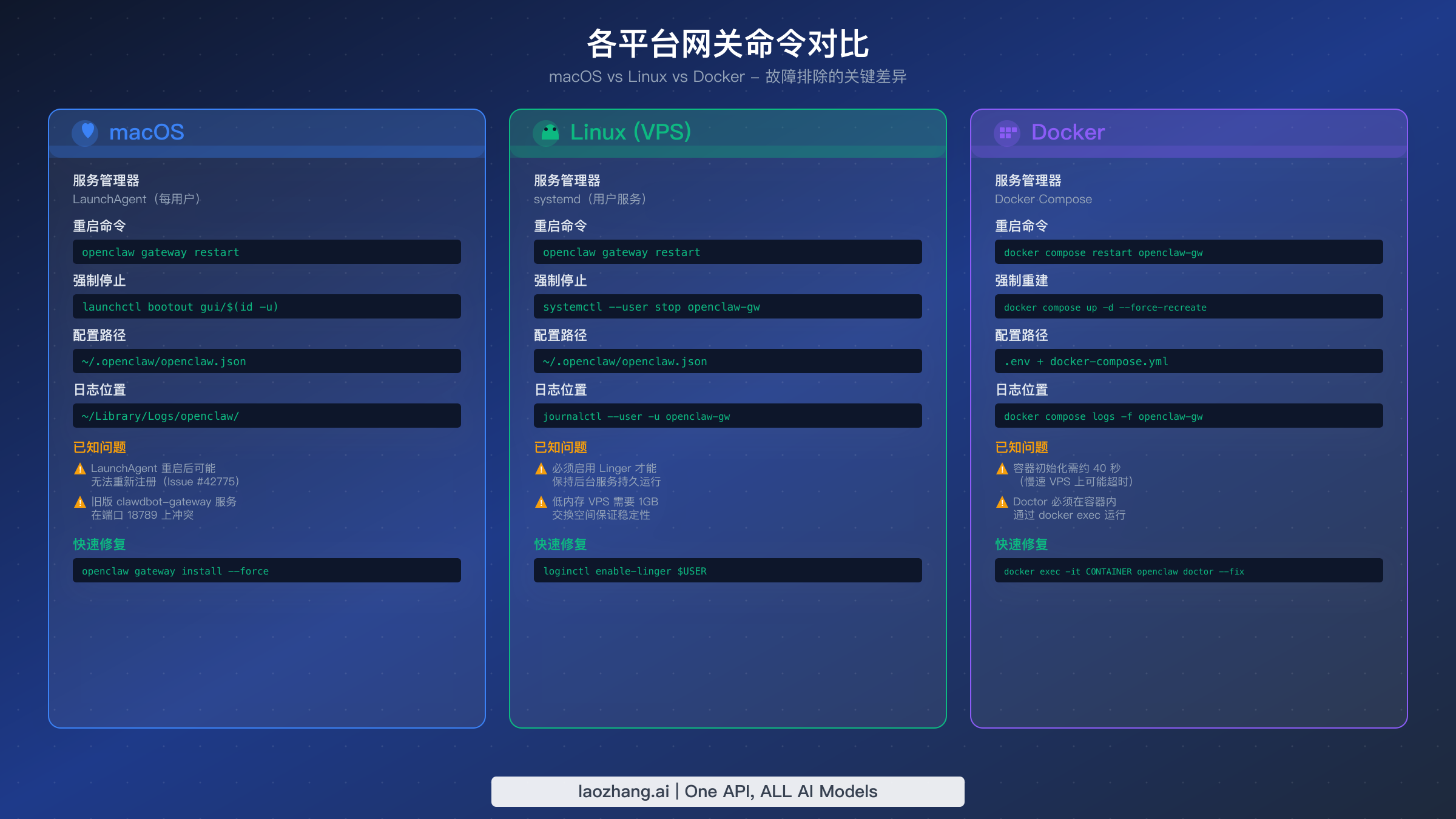
虽然核心故障排除命令在各平台上保持一致,但服务管理层在 macOS、Linux 和 Docker 之间存在显著差异。一个在 Linux 上完美运行的命令可能在 macOS 上静默失败,而 Docker 部署有其自身围绕容器生命周期管理的一系列约束。本节涵盖了通用故障排除指南经常忽略的平台专属细节。
macOS(LaunchAgent)
在 macOS 上,OpenClaw 网关作为 LaunchAgent 运行——这是一个由 launchd 管理的每用户后台服务。服务定义位于 ~/Library/LaunchAgents/com.openclaw.gateway.plist。当 openclaw gateway restart 在 macOS 上失败时,最常见的原因是 LaunchAgent 在停止阶段后没有正确地重新注册。这是 GitHub Issue #42775 中记录的已知问题,重启命令成功停止了网关,但由于 launchctl 没有重新引导服务,导致无法再次启动。
可靠的解决方法是在重启失败后使用 openclaw gateway install --force。这个命令会重新生成 plist 文件并将其显式加载到 launchd 中,绕过重新注册问题。如果这也失败了,请手动卸载并重新加载代理:launchctl bootout gui/$(id -u)/com.openclaw.gateway 然后 launchctl bootstrap gui/$(id -u) ~/Library/LaunchAgents/com.openclaw.gateway.plist。
macOS 上的网关日志写入 ~/Library/Logs/openclaw/,也可以通过 Console.app 按"openclaw"进程过滤来查看。对于实时日志监控,openclaw logs --follow 是最方便的选项。
Linux(systemd)
Linux 部署使用 systemd 用户服务。服务文件通常位于 ~/.config/systemd/user/openclaw-gateway.service。最关键的 Linux 专属注意事项是启用 lingering,它允许用户服务在用户注销后继续运行。没有 lingering,网关会在每次 SSH 会话结束时停止。使用 loginctl enable-linger $USER 启用它。
对于内存有限(1GB 或更少)的 VPS 部署,网关可能在峰值负载期间被 OOM(Out of Memory)杀手终止。添加交换空间可以防止这种情况:sudo fallocate -l 1G /swapfile && sudo chmod 600 /swapfile && sudo mkswap /swapfile && sudo swapon /swapfile。通过将 /swapfile none swap sw 0 0 添加到 /etc/fstab 使交换永久生效。
要在 Linux 上查看网关日志,使用 journalctl --user -u openclaw-gateway -f 进行实时监控,或使用 openclaw logs --follow,它封装了相同的底层机制。
Docker
Docker 部署引入了原生安装中不存在的容器生命周期考虑因素。最重要的区别是 openclaw doctor 必须在容器内部运行,而不是在宿主机上。使用 docker exec -it CONTAINER_NAME openclaw doctor --fix,其中 CONTAINER_NAME 是你的网关容器名称(用 docker ps 查找)。
重启通过 Docker Compose 而不是 openclaw gateway restart 命令来处理:docker compose restart openclaw-gateway。对于同时重置容器状态的更彻底重启,使用 docker compose up -d --force-recreate openclaw-gateway。请注意,容器初始化在网关自身启动时间之上增加了大约 40 秒的开销,因此超时在 Docker 部署中更为常见。
Docker 环境中的配置通常位于 .env 文件和 docker-compose.yml 中,而不是 ~/.openclaw/openclaw.json。在排障时,检查宿主机级别的 Docker 配置和容器内的 OpenClaw 配置,确保它们一致。
升级后的网关故障
升级 OpenClaw 是标准 doctor --fix 序列无法完全解决的网关故障的最常见触发因素。这是因为升级可能会更改服务注册路径、配置 schema 和认证机制——这些更改是 doctor 命令可能无法自动修正的,因为它们涉及有意的设计变更而非配置漂移。
最常被报告的升级后问题是双服务冲突。当 OpenClaw 从"Clawdbot"品牌过渡到"OpenClaw"时,安装程序在旧服务旁边创建了一个新服务。两个服务都试图绑定端口 18789,导致重启循环,每个服务都因为端口已被占用而反复失败。解决方案是在启动新服务之前完全移除旧服务。在 Linux 上:systemctl --user stop clawdbot-gateway.service && systemctl --user disable clawdbot-gateway.service。在 macOS 上:停止旧的 LaunchAgent 并从 ~/Library/LaunchAgents/ 删除其 plist 文件。
另一个常见的升级后问题涉及配置 schema 变更。较新版本的 OpenClaw 可能会废弃配置键或更改其预期格式。网关在启动时验证其配置,如果遇到未知或格式错误的键,则拒绝启动。运行 openclaw config validate 来识别已废弃的设置。输出将列出每个有问题的键及其推荐的替代方案。进行必要的更改后,重启网关。
升级后的认证更改也可能破坏现有的客户端连接。如果升级修改了认证机制(例如,从简单的 gateway.token 迁移到较新的 gateway.auth.token 结构),所有连接的客户端都需要重新认证。这表现为客户端侧的 AUTH_TOKEN_MISMATCH 错误。更新你的远程客户端以使用新的令牌格式,然后重启网关。
最安全的升级流程可以避免大多数这些问题,遵循升级前检查清单:在升级前停止网关(openclaw gateway stop),执行升级,然后运行 openclaw doctor --fix 来应用任何必要的迁移,最后启动网关(openclaw gateway start)。这个序列给了 doctor 命令在网关尝试解析配置之前修复 schema 迁移的机会。
在问题发生之前预防网关故障
最高效的故障排除就是你永远不需要做的故障排除。OpenClaw 网关的预防性维护很简单,每周不到五分钟,但大多数运维人员只在出问题时才会与网关配置互动。实施一个简单的监控例程可以消除绝大多数意外故障。
预防性维护的基础是健康检查命令:openclaw gateway status。每天运行这个命令——或者更好的是,编写脚本自动运行,当输出偏离预期的 Runtime: running, RPC probe: ok 模式时发出警报。一个简单的 cron 任务,运行 openclaw gateway status | grep -q "RPC probe: ok" || echo "Gateway unhealthy" | mail -s "OpenClaw Alert" you@example.com,无需任何外部工具即可提供基本监控。
在每次更改 OpenClaw 配置后都应运行配置验证。openclaw config validate 命令可以在问题导致运行时故障之前捕获它们,这比在凌晨 2 点发现一个打字错误导致你的 Bot 停止响应要好得多。养成习惯:更改设置、验证、然后重启。
磁盘空间是网关故障中一个经常被忽视的原因。网关持续写入日志,在小型 VPS 实例上,日志文件可以在几周内消耗所有可用磁盘空间。通过在配置中设置 gateway.logs.maxFiles 和 gateway.logs.maxSize 来配置日志轮换,或使用系统内置的日志轮换(Linux 上的 logrotate,macOS 上的 newsyslog)。
保持你的 OpenClaw 安装更新,但要有计划地进行。在生产环境中固定到特定版本,而不是追踪最新发布。升级时,遵循上一节的升级前检查清单:停止、升级、doctor、启动。订阅 OpenClaw 发布说明可以确保你在破坏性更改影响你的部署之前就了解它们。关于 OpenClaw 设置的成本效益运营,我们的优化 OpenClaw 成本指南涵盖了实用策略。
当一切方法都无效——终极方案
如果你已经完成了每个诊断步骤、应用了所有相关的修复方案,网关仍然拒绝配合,干净重装是最后的选择。这是最后手段,因为它会重置你的配置,但它保证了一个已知正常的状态。在继续之前,备份你的配置:cp -r ~/.openclaw ~/.openclaw.backup。
终极方案的操作流程:
bashopenclaw gateway stop --force # 2. 卸载服务 openclaw gateway uninstall # 3. 删除配置目录 rm -rf ~/.openclaw # 4. 重新安装 OpenClaw(使用你的包管理器或官方安装器) # npm 方式: npm install -g openclaw # brew 方式: brew install openclaw # 5. 运行初始设置 openclaw init # 6. 恢复你的配置(有选择地,不是整个目录) # 从 ~/.openclaw.backup/openclaw.json 复制特定设置 # 7. 安装并启动网关 openclaw gateway install openclaw gateway start
干净重装后,参考备份的配置从头重新配置你的渠道、API 密钥和模型设置。不要简单地将旧配置文件复制到新文件上——旧文件可能包含导致故障的确切问题。建议参考完整的 OpenClaw 安装指南来干净地设置每个组件。
常见问题
openclaw gateway restart 会导致消息丢失吗?
在重启窗口期间(通常 3-5 秒),传入的消息会被渠道提供商(WhatsApp、Slack 等)缓冲,并在网关重新连接后传递。消息不会永久丢失,但可能会有短暂的延迟。对于计划内的重启,建议安排在低流量时段进行。
openclaw restart 和 openclaw gateway restart 有什么区别?
openclaw restart 命令会重启整个 OpenClaw 技术栈,包括所有节点和服务。openclaw gateway restart 命令仅重启网关进程。对于排查网关特定问题,使用 openclaw gateway restart 可以最大限度地减少对其他组件的干扰。
可以在网关运行时运行 openclaw doctor 吗?
可以。doctor 命令是一个诊断工具,它读取配置文件并检查系统状态,不会修改正在运行的网关进程。但是,如果你使用了 --fix 并且 doctor 重写了服务定义,你应该随后重启网关以应用更改。
应该多久重启一次网关?
在正常运行下,网关不需要定期重启。它被设计为持续运行。只在配置更改、更新或排障时重启。如果你发现自己频繁重启,请调查根本原因,而不是将重启作为临时解决方案。
为什么 openclaw gateway restart 在 macOS 上会静默失败?
这是一个已知问题(GitHub #42775),macOS LaunchAgent 在停止阶段后没有正确地重新注册。使用 openclaw gateway install --force 后跟 openclaw gateway start 作为可靠的替代方案。