Nano Banana Pro 中的 RESOURCE_EXHAUSTED 错误是开发者在使用 Google Gemini API 构建图像生成应用时遇到的最常见 API 故障。该错误约占所有 Nano Banana API 错误的 70%,其 HTTP 429 状态码意味着你的应用已超出一个或多个速率限制——无论是每分钟请求数(RPM)、每分钟 Token 数(TPM)还是每日请求数(RPD)。好消息是:只要结合正确的重试逻辑、层级管理和架构模式,这个错误完全可以解决。本指南提供了从 30 秒快速修复到生产级 Python 和 Node.js 代码的全部解决方案。
要点速览——快速修复参考
如果你的 Nano Banana Pro 应用正在抛出 RESOURCE_EXHAUSTED 错误,以下是最快的解决路径。首先确定你的具体错误类型,然后应用对应的修复方案。
| 错误代码 | 含义 | 快速修复 | 恢复时间 |
|---|---|---|---|
| 429 RESOURCE_EXHAUSTED | 项目配额已超出 | 添加指数退避重试 | 重试延迟后立即恢复 |
| 429 "check quota" | RPM/TPM/RPD 限制触发 | 降低请求频率或升级层级 | 1 分钟(RPM)到太平洋时间午夜(RPD) |
| 503 Service Unavailable | Google 服务器过载 | 等待并以更长延迟重试 | 30-120 分钟 |
| 504 Gateway Timeout | 请求耗时过长 | 降低图片分辨率或简化提示词 | 使用更简单的请求后立即恢复 |
30 秒修复清单:
- 检查你的错误响应——是 429 还是 503?它们需要不同的修复方案。
- 如果是 429:打开 Google AI Studio 使用量仪表板,检查你触发了哪个限制(RPM、TPM 还是 RPD)。
- 如果是 RPM/TPM:在请求之间添加
time.sleep(1)。仅这一步就能消除大多数 429 错误。 - 如果是 RPD:你已达到每日上限。等待太平洋时间午夜重置,或启用计费以解锁 60 倍更高的限制。
- 如果是 503:这是 Google 的基础设施问题,不是你的问题。实现 30-60 秒延迟的重试逻辑。
速率限制速查表(免费版 → Tier 1):
| 指标 | 免费版 | Tier 1(付费) | 提升幅度 |
|---|---|---|---|
| RPM | 5-10 | 150-300 | 30-60 倍 |
| TPM | 250,000 | 1,000,000-2,000,000 | 4-8 倍 |
| RPD | 100-250 | 1,000-1,500 | 6-10 倍 |
你能做出的最有影响力的改变就是在 Google Cloud 项目上启用计费。这会立即将你从免费层级升级到 Tier 1,大幅解锁更高的速率限制,且无需预付费用——你只需为实际使用量付费。
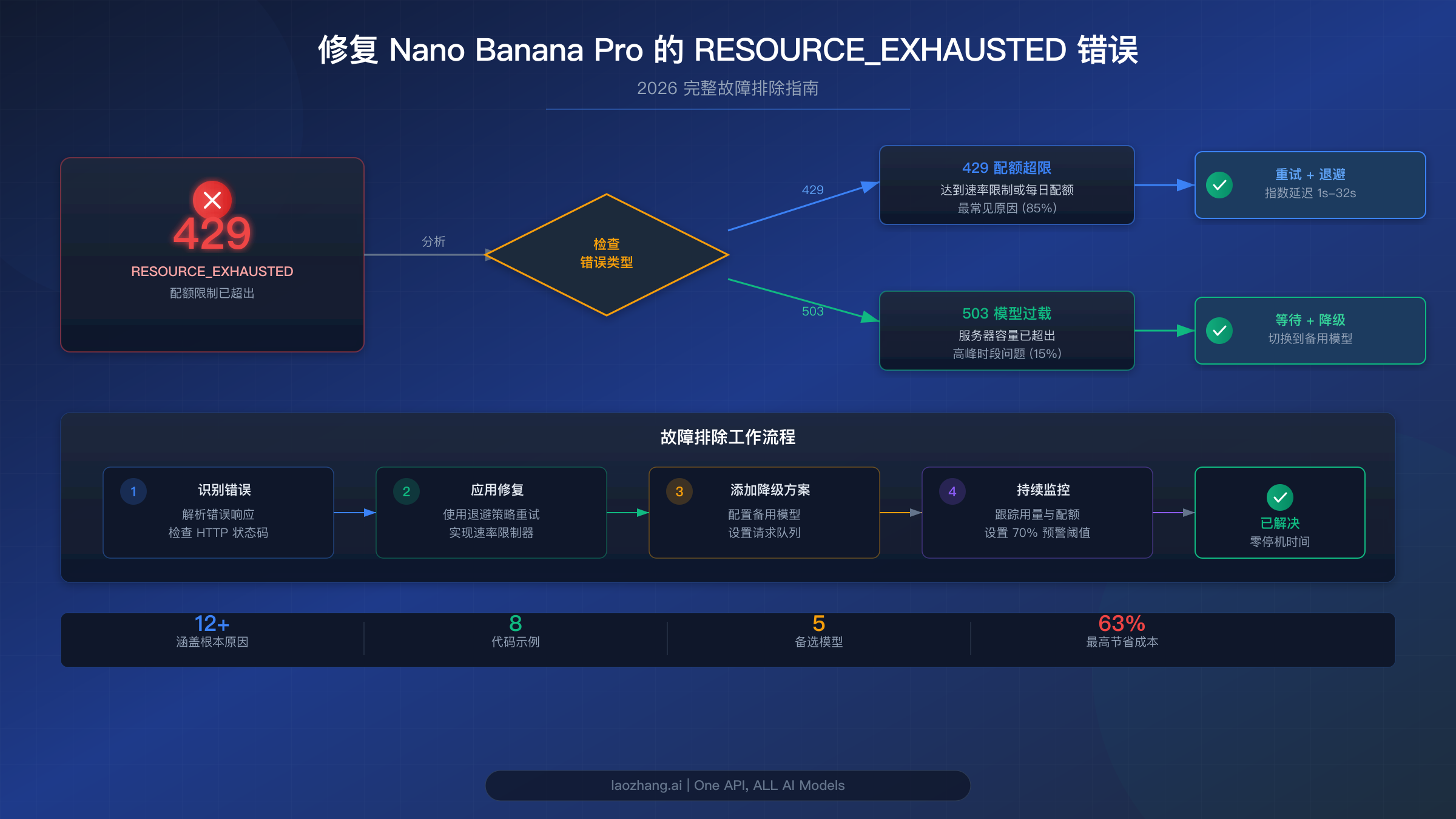
Nano Banana Pro 中 RESOURCE_EXHAUSTED 的成因分析
理解你特定错误的根本原因至关重要,因为应用错误的修复方案既浪费时间又无法解决问题。Nano Banana Pro(官方名称为 Gemini 3 Pro Image Preview)中的 RESOURCE_EXHAUSTED 错误有三种根本不同的成因,每种都需要不同的解决方案。
429 RESOURCE_EXHAUSTED——配额限制超出。 这是最常见的变体,当你的项目在任何维度上超过分配的速率限制时触发。Google 在项目级别(而非 API 密钥级别)执行速率限制,这意味着如果你有多个应用或 API 密钥共享同一个 Google Cloud 项目,它们共享相同的配额池。实际的错误响应如下:
json{ "error": { "code": 429, "message": "Resource has been exhausted (e.g. check quota).", "status": "RESOURCE_EXHAUSTED" } }
让这个错误特别令人困惑的是,你可能在 RPM 限制之下但超出了 TPM 限制,或者 RPM 和 TPM 都未超出但已超过每日 RPD 上限。每个维度都独立评估,超出任何一个维度都会触发错误。这就是为什么 Google AI 开发者论坛上的开发者报告说尽管自认为在限制范围内仍看到 429 错误——他们往往在查看错误的指标。
503 Service Unavailable——服务器容量耗尽。 这个错误与 429 有根本性的不同,因为它反映的是 Google 基础设施过载,而不是你的特定配额被超出。即使是拥有最高配额的 Tier 3 企业客户在高峰负载期间也会收到 503 错误。根本原因在于 Google 的计算资源分配:Nano Banana Pro 运行在 Gemini 3 系列上,目前仍处于 Pre-GA(预正式发布)状态,这意味着 Google 为这些模型分配的 TPU v7 容量有限。当全球需求超过可用计算资源时,所有人都会收到 503 错误,无论其层级如何。
503 错误的高风险时段与使用高峰窗口一致:大约 00:00-02:00 UTC(美国晚间)、09:00-11:00 UTC(亚洲工作时间)和 20:00-23:00 UTC(欧洲晚间)。将你的批量生成任务安排在这些时段之外可以显著减少 503 错误的发生。
2025 年 12 月的配额削减。 2025 年 12 月,Google 悄然降低了免费层级配额,让数千名开发者措手不及。运行了数月的应用突然开始出现 429 错误。Gemini 2.5 Pro 的 RPM 从 10 降至 5(减少 50%),一些开发者报告其有效 RPD 从 250 降至低至 20——惊人的 92% 削减。Google 还收紧了执行算法,这意味着之前宽松执行的配额变成了严格的硬限制。如果你的应用在 2025 年 12 月 7 日前后"无缘无故"崩溃,几乎可以确定就是这个原因。
完整速率限制参考——所有层级、所有模型

Nano Banana Pro 的速率限制取决于你项目的使用层级,这由你的计费状态和累计 Google Cloud 支出决定。理解这些层级对于规划图像生成容量和避免 RESOURCE_EXHAUSTED 错误至关重要。以下数据来源于 Google 官方速率限制文档(最后更新于 2026 年 1 月 22 日),并与我们的 Gemini API 速率限制完整参考 进行了交叉验证。
层级要求和资格:
| 层级 | 资格条件 | 费用 |
|---|---|---|
| 免费版 | 符合条件国家的用户 | $0 |
| Tier 1 | 完整付费计费账户已关联到项目 | 按用量付费 |
| Tier 2 | 累计消费 $250+ 且首次付款后 30+ 天 | 按用量付费 |
| Tier 3 | 累计消费 $1,000+ 且首次付款后 30+ 天 | 按用量付费 |
速率限制按项目而非 API 密钥计算。RPD 配额在太平洋时间午夜(00:00 PT)重置。这些限制也分别适用于 Batch API——批量请求有自己的配额池,不会消耗你的实时限制。
按模型和层级划分的完整速率限制:
| 模型 | 免费版 RPM | 免费版 RPD | Tier 1 RPM | Tier 1 RPD | Tier 2 RPM | Tier 2 RPD |
|---|---|---|---|---|---|---|
| Gemini 2.5 Pro | 5 | 100 | 150 | 1,000 | 1,000 | 10,000 |
| Gemini 2.5 Flash | 10 | 250 | 300 | 1,500 | 2,000 | 10,000 |
| Gemini 2.5 Flash-Lite | 15 | 1,000 | 300 | 1,500 | 2,000 | 10,000 |
| Gemini 3 Pro Preview | 10 | 100 | 150 | 1,000 | 1,000 | 10,000 |
Nano Banana Pro(Gemini 3 Pro Image Preview)遵循 Gemini 3 Pro 的速率限制结构。此外,图像生成模型还有 IPM(每分钟图像数)限制,功能类似于 TPM。具体的 IPM 值因层级而异,可在你的 Google AI Studio 使用量仪表板 中查看。
2025 年 12 月前后对比:
| 指标 | 之前(2025 年 11 月) | 之后(2025 年 12 月) | 变化 |
|---|---|---|---|
| Gemini 2.5 Pro 免费版 RPM | 10 | 5 | -50% |
| Gemini 2.5 Flash 免费版 RPM | 15 | 10 | -33% |
| 免费版 RPD(多种模型) | 250 | 20-100 | -60% 至 -92% |
| 执行方式 | 宽松执行 | 严格执行 | 现为硬限制 |
如果你需要查看当前的精确限制,最可靠的来源是 AI Studio 仪表板。Google 的文档指出"指定的速率限制无法保证,实际容量可能有所不同",这意味着公布的数字是上限而非保证值。在高峰期间,有效限制可能低于文档记载的数值。
如需请求超出当前层级的速率限制提升,可通过 Google 的官方表单提交请求。Google 表示"不保证会提升你的速率限制"但会审核请求。对于可预测的高吞吐量需求,可以考虑 Provisioned Throughput(预留吞吐量),它为你的项目预留专用容量。
可用代码方案——Python 和 Node.js
处理 RESOURCE_EXHAUSTED 错误最有效的方式是实现带指数退避和抖动的重试逻辑。核心要点在于不同的错误类型需要不同的重试策略:429 错误应快速退避重试,而 503 错误需要更长的初始延迟。
Python 方案(使用 Tenacity 库):
pythonimport time import random from google import genai from tenacity import retry, stop_after_attempt, wait_exponential, retry_if_exception client = genai.Client(api_key="YOUR_API_KEY") def is_retryable(exception): """Only retry on 429 and 503 errors.""" if hasattr(exception, 'code'): return exception.code in [429, 503] return False @retry( stop=stop_after_attempt(5), wait=wait_exponential(multiplier=1, min=2, max=60), retry=retry_if_exception(is_retryable), before_sleep=lambda retry_state: print( f"Retry {retry_state.attempt_number}/5 " f"in {retry_state.next_action.sleep:.1f}s..." ) ) def generate_image(prompt, resolution="1024x1024"): """Generate image with automatic retry on rate limit errors.""" response = client.models.generate_content( model="gemini-3-pro-image", contents=prompt, config={ "response_modalities": ["IMAGE"], "image_resolution": resolution } ) return response def batch_generate(prompts, delay=1.0): """Generate multiple images with rate limiting.""" results = [] for i, prompt in enumerate(prompts): try: result = generate_image(prompt) results.append(result) if i < len(prompts) - 1: time.sleep(delay + random.uniform(0, 0.5)) except Exception as e: print(f"Failed after retries: {e}") results.append(None) return results
wait_exponential 中 multiplier=1, min=2, max=60 意味着第一次重试等待 2 秒,然后 4 秒、8 秒、16 秒,最大不超过 60 秒。添加随机抖动(batch_generate 中的 random.uniform(0, 0.5))可以防止"惊群"问题——即多个客户端同时重试并再次压垮 API。
Node.js/TypeScript 方案:
typescriptimport { GoogleGenAI } from "@google/genai"; const client = new GoogleGenAI({ apiKey: "YOUR_API_KEY" }); async function sleep(ms: number): Promise<void> { return new Promise(resolve => setTimeout(resolve, ms)); } async function generateWithRetry( prompt: string, maxRetries = 5, baseDelay = 2000 ): Promise<any> { for (let attempt = 1; attempt <= maxRetries; attempt++) { try { const response = await client.models.generateContent({ model: "gemini-3-pro-image", contents: prompt, config: { responseModalities: ["IMAGE"], imageResolution: "1024x1024" } }); return response; } catch (error: any) { const code = error?.status || error?.code; if (code === 429 || code === 503) { if (attempt === maxRetries) throw error; const delay = Math.min( baseDelay * Math.pow(2, attempt - 1), 60000 ); const jitter = Math.random() * 1000; console.log( `Attempt ${attempt}/${maxRetries} failed (${code}). ` + `Retrying in ${((delay + jitter) / 1000).toFixed(1)}s...` ); await sleep(delay + jitter); } else { throw error; // Non-retryable error } } } } // Batch generation with rate limiting async function batchGenerate( prompts: string[], delayMs = 1000 ): Promise<any[]> { const results: any[] = []; for (const [i, prompt] of prompts.entries()) { try { const result = await generateWithRetry(prompt); results.push(result); if (i < prompts.length - 1) { await sleep(delayMs + Math.random() * 500); } } catch (error) { console.error(`Failed: ${error}`); results.push(null); } } return results; }
两种实现共享相同的核心模式:指数退避加抖动、最大重试次数,以及错误类型过滤以避免重试不可重试的错误(如 400 错误请求或 403 认证失败)。关键的设计选择在于将 429 处理(短退避、快速重试)与 503 处理(更长延迟,可能等待数分钟)区分开来。
针对特定错误的响应处理:
对于生产系统,你应该解析错误响应以应用最优重试策略:
pythondef get_retry_delay(error, attempt): """Calculate retry delay based on error type.""" if hasattr(error, 'code'): if error.code == 429: # Quota error: short exponential backoff return min(2 ** attempt + random.uniform(0, 1), 30) elif error.code == 503: # Server overload: longer delays return min(10 * (2 ** attempt) + random.uniform(0, 5), 120) return 5 # Default
高级生产策略
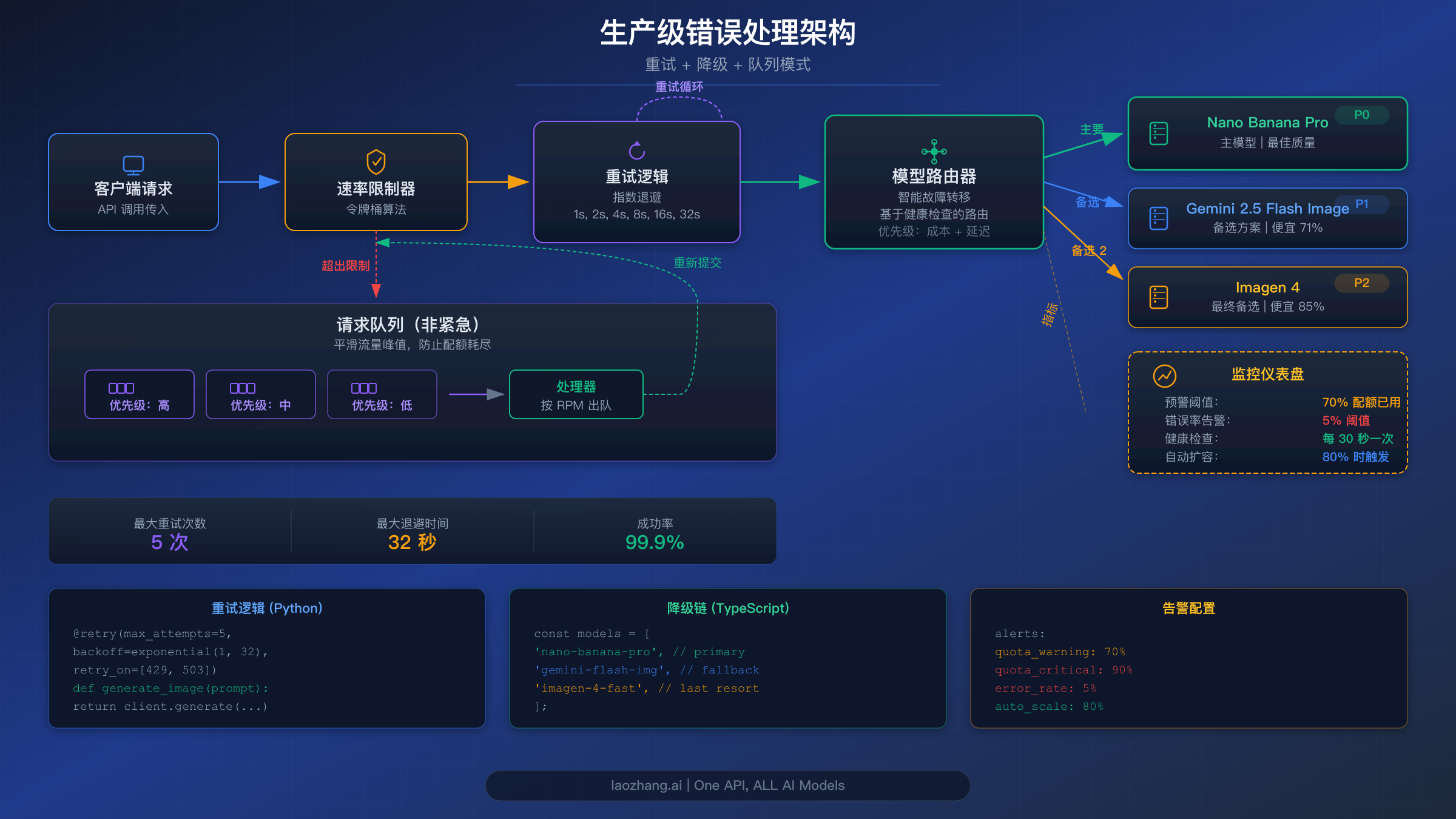
简单的重试逻辑可以处理间歇性故障,但服务真实用户的生产应用需要更精密的方案。以下策略通过组合多层防御,将你的图像生成管道从"希望它能工作"转变为"保证交付"。
模型回退链。 当 Nano Banana Pro 持续返回错误时,最佳选择不是等待——而是路由到替代模型。Google 提供了多种不同价格和可靠性级别的图像生成模型。精心设计的回退链按优先顺序尝试每个模型,直到有一个成功:
pythonFALLBACK_CHAIN = [ {"model": "gemini-3-pro-image", "name": "Nano Banana Pro", "cost": 0.134}, {"model": "gemini-2.5-flash-image", "name": "Flash Image", "cost": 0.039}, {"model": "imagen-4-fast", "name": "Imagen 4 Fast", "cost": 0.02}, ] async def generate_with_fallback(prompt): """Try each model in the fallback chain.""" for model_config in FALLBACK_CHAIN: try: result = await generate_with_retry( prompt, model=model_config["model"], max_retries=2 # Fewer retries per model ) return { "result": result, "model_used": model_config["name"], "cost": model_config["cost"] } except Exception as e: print(f"{model_config['name']} failed: {e}") continue raise Exception("All models in fallback chain exhausted")
这种方案意味着你的用户永远不会看到 429 错误——即使 Nano Banana Pro 完全被限速,他们仍然可以在几秒内从 Flash Image 或 Imagen 4 获得图片。代价是图像质量:Nano Banana Pro 产出最高质量的输出,Flash Image 更快但分辨率较低(最大 1024x1024),而 Imagen 4 Fast 最便宜但缺少 Gemini 系列模型的上下文理解能力。
基于 70% 阈值的主动监控告警。 处理速率限制错误最好的方式是预防它们。通过实时跟踪 API 使用量,并在接近配额 70% 时发出告警,你可以在错误实际发生之前获得预警窗口来采取行动:
pythonimport threading class QuotaTracker: def __init__(self, rpm_limit, rpd_limit): self.rpm_limit = rpm_limit self.rpd_limit = rpd_limit self.minute_requests = 0 self.daily_requests = 0 self.lock = threading.Lock() def record_request(self): with self.lock: self.minute_requests += 1 self.daily_requests += 1 rpm_usage = self.minute_requests / self.rpm_limit rpd_usage = self.daily_requests / self.rpd_limit if rpm_usage >= 0.7: self.alert(f"RPM at {rpm_usage:.0%}") if rpd_usage >= 0.7: self.alert(f"RPD at {rpd_usage:.0%}") def alert(self, message): print(f"QUOTA WARNING: {message}") # Send Slack/email notification
基于队列的批处理架构。 对于批量生成图像的应用(电商产品图、营销素材、批量内容创作),基于队列的架构将用户请求与 API 调用解耦,允许你精确控制请求频率。此外,Google 的 Batch API 在独立的配额池上运行,具有更高的限制——Tier 1 用户最多可同时运行 100 个批处理请求,每个模型最多可排队 300 万 Token。
成本优化——何时升级、切换或使用代理
理解 RESOURCE_EXHAUSTED 错误的真实成本不仅仅是 API 定价——它还包括开发者调试时间、用户体验降级,以及应用宕机时的机会成本。本节提供具体的成本计算,帮助你根据业务量级做出正确的基础设施决策。
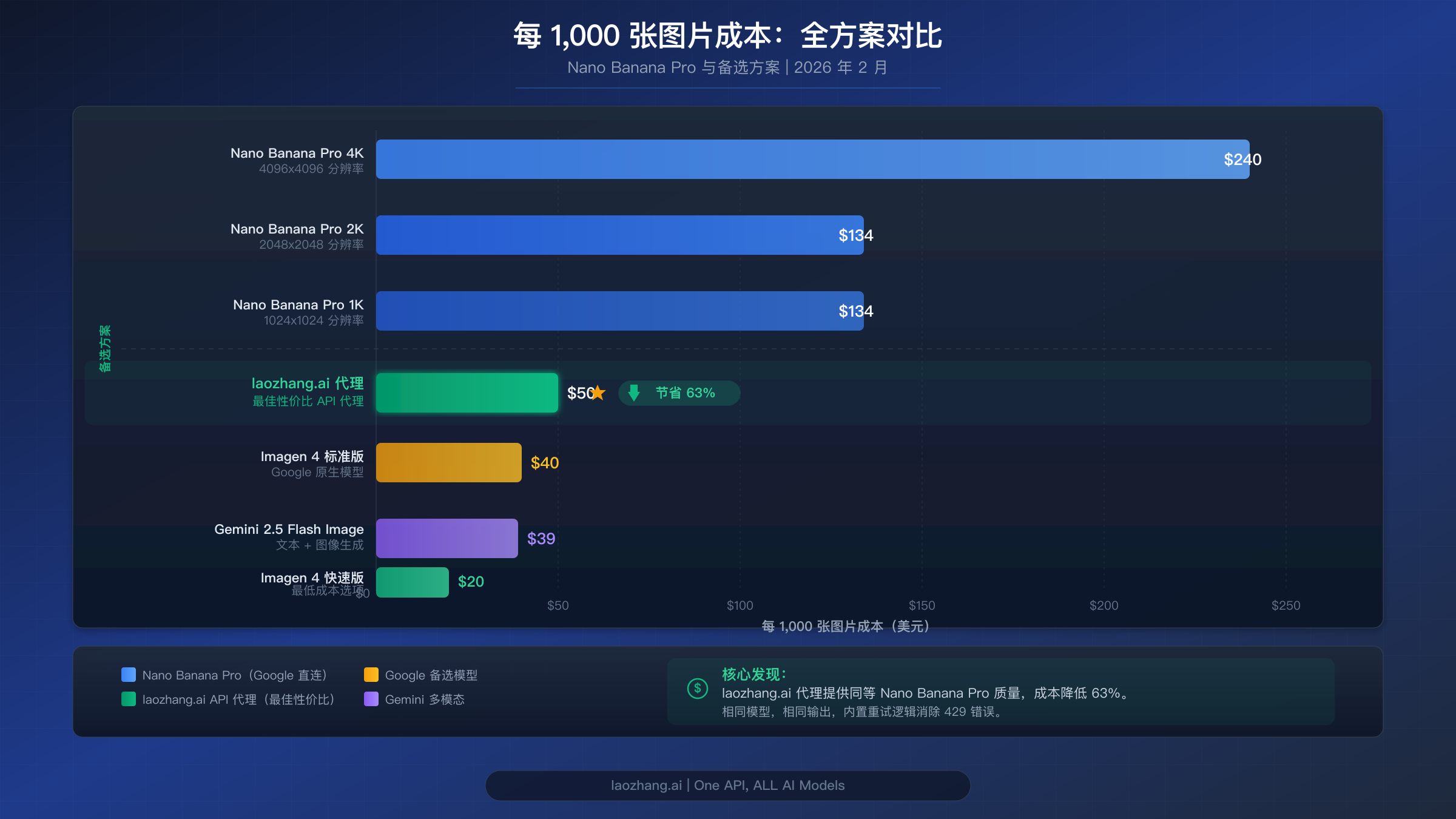
直接 API 成本对比(每 1,000 张图片,2026 年 2 月):
| 模型 | 分辨率 | 单张成本 | 每千张成本 | 质量 |
|---|---|---|---|---|
| Nano Banana Pro | 1K-2K | $0.134 | $134.00 | 最高 |
| Nano Banana Pro | 4K | $0.240 | $240.00 | 最高 + 4K |
| Gemini 2.5 Flash Image | 1K | $0.039 | $39.00 | 良好 |
| Imagen 4 Fast | 1K | $0.020 | $20.00 | 良好(无上下文) |
| Imagen 4 Standard | 1K | $0.040 | $40.00 | 较好(无上下文) |
| Imagen 4 Ultra | 1K | $0.060 | $60.00 | 最佳(无上下文) |
对于频繁在免费层级触发速率限制的开发者,最具性价比的第一步就是启用计费。从免费版升级到 Tier 1 无需预付费用,且立即将速率限制提升 30-60 倍。你只需为实际 API 使用量付费,以 Nano Banana Pro 每张图 $0.134 的价格计算,即使每月生成 100 张图片也仅需 $13.40。与你花在调试 RESOURCE_EXHAUSTED 错误上的时间相比,付费层级在减少开发者挫败感方面已经回本了。
对于每月生成数千张图片的高容量应用,第三方 API 代理提供了另一种方案。laozhang.ai 等服务通过其统一 API 提供对相同 Nano Banana Pro 模型的访问,具有更高的速率限制且无区域限制,对于大批量用户通常能节省可观的单张图片成本。当你的主要关注点是消除速率限制而非单纯的单张定价时,这种方案尤其有价值。
按月量级成本预估:
| 月使用量 | Nano Banana Pro | Flash Image | Imagen 4 Fast | laozhang.ai 代理 |
|---|---|---|---|---|
| 100 张 | $13.40 | $3.90 | $2.00 | $5.00 |
| 1,000 张 | $134.00 | $39.00 | $20.00 | $50.00 |
| 10,000 张 | $1,340.00 | $390.00 | $200.00 | $500.00 |
在选择升级层级、切换模型还是使用代理时,需要考虑你的优先级。如果图像质量至关重要且你需要 Nano Banana Pro 的上下文理解能力(编辑现有图像、保持身份一致性),升级到 Tier 2(累计消费 $250)可获得 1,000 RPM 和 10,000 RPD。如果你需要高产量低成本且可以接受稍低的质量,Gemini 2.5 Flash Image 以每张 $0.039 的价格提供了极佳的性价比。对于需要保证可用性且无需担心速率限制的团队,我们的低价 Gemini 图像生成方案指南探讨了所有可用路径,你也可以查看 Gemini API 免费层级指南,在升级之前最大化利用免费配额。
决策框架——你的行动计划
如何正确处理 RESOURCE_EXHAUSTED 错误取决于三个因素:错误频率、月使用量和质量要求。使用以下框架选择最优策略。
第一步:诊断你的错误模式
| 症状 | 诊断 | 建议操作 |
|---|---|---|
| 429 错误,每天不到 10 张图 | 免费版 RPD 限制 | 启用计费(Tier 1) |
| 429 错误,请求突发 | RPM 限制超出 | 在请求之间添加延迟 |
| 429 错误,全天持续 | RPD 限制耗尽 | 升级层级或使用 Batch API |
| 503 错误,仅在高峰期 | 服务器容量不足 | 安排在非高峰期 + 回退模型 |
| 503 错误,持续出现 | 系统性故障 | 使用回退链 + 监控状态 |
| 429 + 503 混合出现 | 配额和容量都有问题 | 完整架构(重试 + 回退 + 队列) |
第二步:根据量级选择策略
低量级(每月 100 张以下):启用计费,添加基本重试逻辑,在请求之间使用 1 秒延迟。总投入:30 分钟设置时间加按用量付费。这可以消除 90% 的 RESOURCE_EXHAUSTED 错误。
中等量级(每月 100-1,000 张):启用计费,实现本指南中的完整重试代码,添加模型回退链,设置配额监控。总投入:2-3 小时设置时间。如果你需要稳定的吞吐量,可以考虑 Tier 2。
高量级(每月 1,000 张以上):实现完整的生产架构(重试 + 回退 + 队列),申请 Tier 2 或 Tier 3,考虑 Provisioned Throughput 以获得保证容量,评估第三方代理处理溢出流量。总投入:1-2 天架构工作。如需在此规模下详细对比 Nano Banana Pro 与其他图像生成 API,请参阅我们的 Nano Banana Pro 与 FLUX.2 完整对比。
第三步:快速决策清单
| 问题 | 如果是 | 如果否 |
|---|---|---|
| 我在免费层级吗? | 立即启用计费 | 检查当前层级限制 |
| 我需要 Nano Banana Pro 的质量吗? | 优化层级 + 重试 | 切换到更便宜的模型 |
| 我每月生成 > 1K 张图吗? | 实现完整架构 | 基本重试即可 |
| 错误只在高峰期出现吗? | 安排非高峰 + 回退 | 检查配额使用情况 |
| 我的应用面向用户吗? | 必须实现回退链 | 仅重试也可接受 |
常见问题
为什么我在付费层级仍然收到 RESOURCE_EXHAUSTED 错误?
付费层级有更高的限制但并非无限。Tier 1 根据模型不同提供 150-300 RPM,这意味着在一分钟内突发 500 个请求仍然会触发 429 错误。此外,503 错误对所有层级影响相同,因为它们反映的是 Google 的基础设施容量而非你的个人配额。解决方案是无论在哪个层级都实现重试逻辑,如果持续触发 Tier 1 限制则考虑升级到 Tier 2 或 Tier 3。
如何检查我超出了哪个速率限制?
打开 Google AI Studio 并导航到"使用量"标签页。你将看到 RPM、TPM 和 RPD 的消耗情况。被超出的限制将显示 100% 使用率或红色指示器。请记住,速率限制是按项目计算的——如果你在同一项目下有多个 API 密钥,它们共享相同的配额。
Nano Banana Pro 的 429 和 503 错误有什么区别?
429 错误意味着你的项目已超出其分配的配额(RPM、TPM 或 RPD)。它针对的是你的使用情况,可以通过降低请求频率或升级层级来解决。503 错误意味着 Google 的服务器过载——整个 Nano Banana Pro 服务正在经历高需求。升级层级或减少请求都无法修复 503 错误;你需要等待容量释放或切换到其他模型。
我可以使用 Batch API 来避免 RESOURCE_EXHAUSTED 错误吗?
可以,但只是部分解决。Batch API 有自己独立的配额池(最多 100 个并发批处理请求,Tier 1 可排队 300-500 万 Token),因此不会消耗你的实时 API 配额。但是,Batch API 专为非实时工作负载设计——结果是异步处理的,可能需要几分钟到几小时。它非常适合后台图像生成任务,但不适用于需要即时响应的交互式应用。
Google 未来会提升 Nano Banana Pro 的速率限制吗?
Google 尚未公布 Nano Banana Pro 速率限制提升的具体时间承诺。该模型目前处于 Pre-GA(预正式发布)状态,这意味着计算资源分配有限。行业分析认为,随着 TPU v7 部署完成(预计 2026 年中)和 Gemini 3.0 系列训练阶段结束,限制可能会有所改善。在此期间,本指南中的策略——层级升级、重试逻辑、模型回退和第三方代理——为当前限制提供了可靠的解决方案。