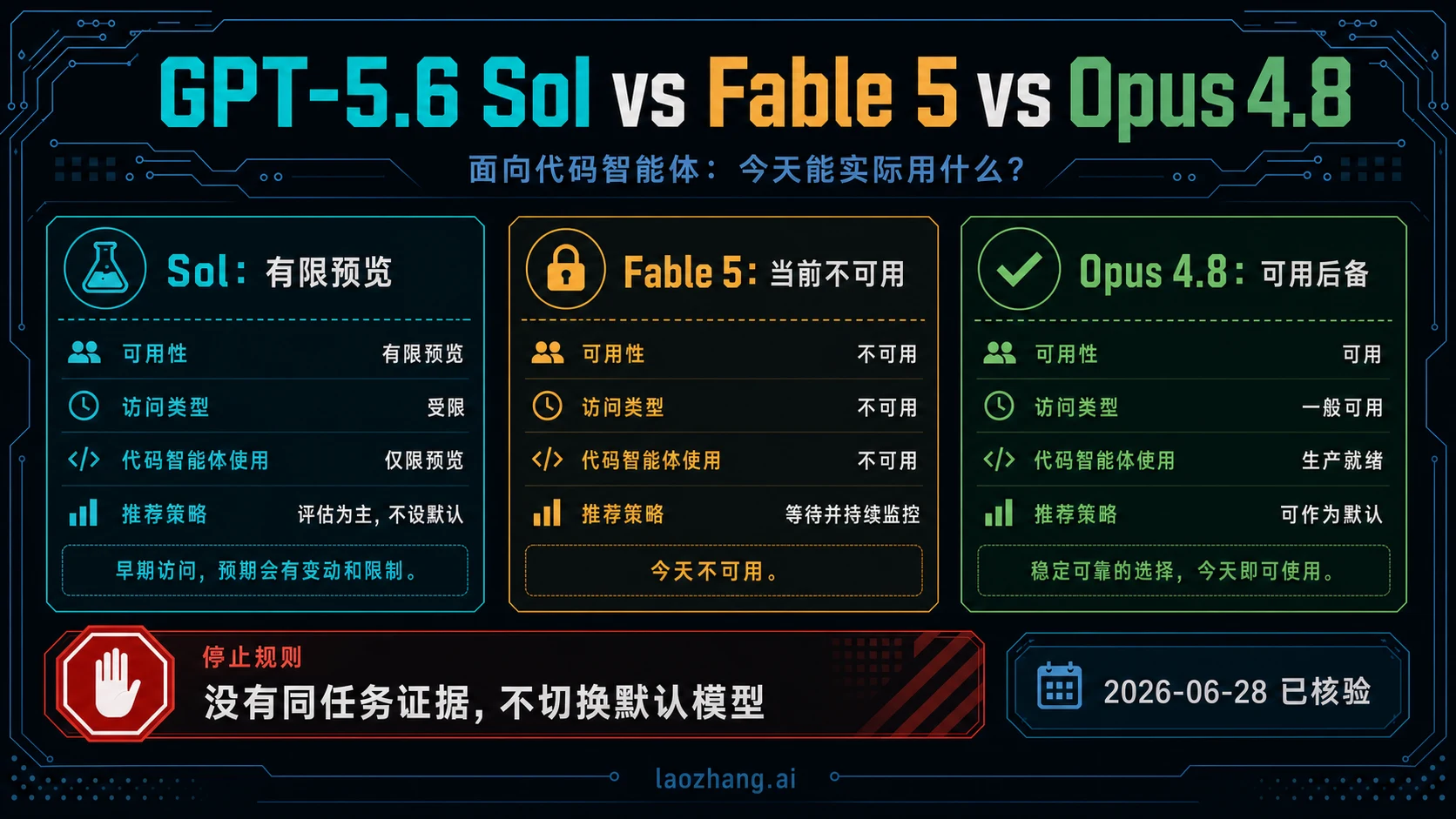
GPT-5.6 Sol、Claude Fable 5 和 Claude Opus 4.8 现在不是三条同等可用的生产路线。截至 2026 年 6 月 28 日,OpenAI 把 GPT-5.6 Sol 描述为面向已批准组织的 limited preview;Anthropic 当前材料说明 Claude Fable 5 处于不可用状态;Claude Opus 4.8 则是今天可以放进编码 agent 评估的 live Anthropic 路线。
所以先别问“谁最强”。更实际的答案是:如果你的组织和工作区已经拿到 GPT-5.6 Sol 的对应预览权限,可以把 Sol 放进高难编码任务测试;如果目标是 Fable 5,先等待并复查 Anthropic 官方访问状态;如果今天就要稳定 endpoint、日志、权限和回滚路线,先以 Opus 4.8 作为 live baseline。
| 2026-06-28 的当前路线 | 第一动作 | 理由 | 停止规则 |
|---|---|---|---|
| 已有 Sol API 组织或 Codex workspace 预览权限 | 用 Sol 跑高难编码 agent 任务 | OpenAI 把 Sol 定位为 GPT-5.6 旗舰,并强调 terminal-driven coding 能力。 | 不要把预览 workspace 的结果推广给没有权限的团队。 |
| 正在考虑 Claude Fable 5 | 等待并复查 Anthropic 官方访问页 | Anthropic 当前说明是 Fable 5 unavailable。 | 不要把 list price 或旧演示当成可部署证明。 |
| 今天需要生产可用模型 | 以 Claude Opus 4.8 做 live baseline | Anthropic 当前列出 Opus 4.8 可通过 Claude 和合作平台使用。 | 没有同任务证据,不切默认模型。 |
快速答案
这类 coding model 对比要先看访问状态,再看跑分。Sol 是值得测试的预览模型,Fable 是暂时不能作为生产路线的 premium promise,Opus 4.8 是今天可以实际运行的 live fallback。这个顺序可能变化,所以所有访问、价格和平台判断都要带上 2026 年 6 月 28 日这个复查日期。
如果你已经有 Sol 预览权限,而且任务确实是 repo edits、终端恢复、工具调用和多步 coding agent,Sol 应该进入第一轮 pilot。如果你需要的是今天能在服务端调用、能记录日志、能给客户交付、能回滚的模型,Opus 4.8 应该先坐稳基线。Fable 5 在当前访问恢复前,只能放在待复查栏,不能写成生产推荐。
很多精确匹配的对比页会先放跑分表,这对快速浏览有帮助,但也容易掩盖最关键的判断:访问不到的强模型不是默认生产模型。不可用模型的高价或高分也只能用于规划,不能替代可调用 endpoint。
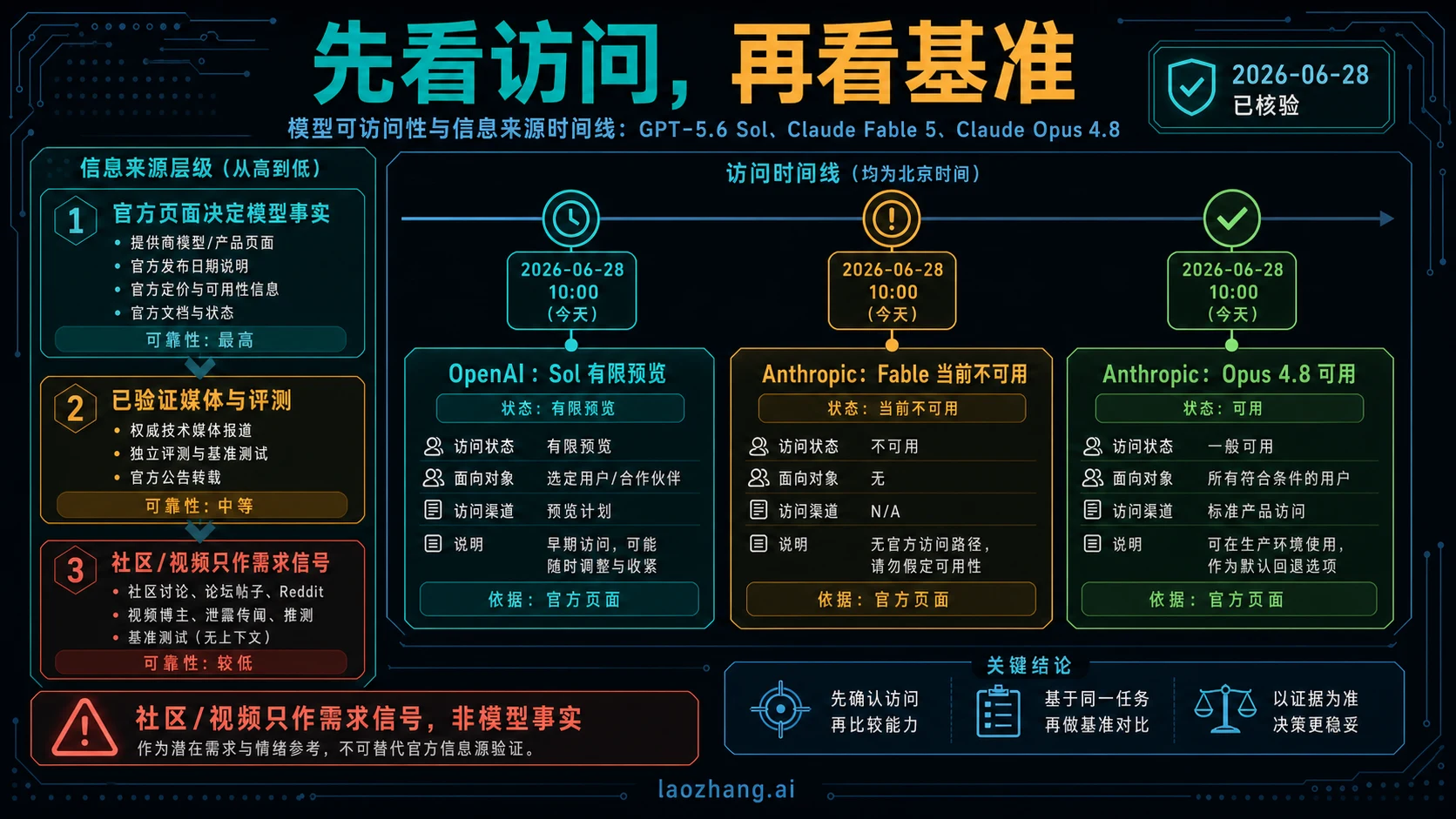
访问状态才是第一分叉
OpenAI 关于 GPT-5.6 Sol 的材料讲的是 limited preview,不是公开自助开通。OpenAI 帮助页还把 API organization 权限和 Codex workspace 权限分开说明,所以“组织拿到预览”不等于“你的 Codex 工作区可以直接用”。如果你的迁移依赖 Codex,先验证 workspace 权限,再安排测试。
Anthropic 的 Fable 页面和 Fable/Mythos 访问声明给出的是相反边界。Fable 5 可以有产品页、价格行和跑分讨论,但 Anthropic 当前访问声明说它对客户不可用。因此 Fable 5 是 watchlist,不是流量路线。旧截图、视频和第三方演示都不能覆盖当前官方访问状态。
Claude Opus 4.8 今天的可部署合约最清楚。Anthropic 的 Opus 页面和模型概览把它列为 Claude 产品、Claude Platform、AWS、Google Cloud 和 Microsoft Foundry 可用路线。实现时要复核的模型 ID 是 `claude-opus-4-8`,不要用社媒简称或旧 Opus ID 代替。
| 合约项 | GPT-5.6 Sol | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|---|
| 当前访问 | 已批准组织和特定工作区的有限预览。 | Anthropic 当前材料显示 unavailable。 | Anthropic 和列出的合作平台一般可用。 |
| 今天角色 | 有权限时做 preview test。 | 等待并复查。 | live baseline 或 fallback。 |
| API/model ID | 在已批准 OpenAI org 中复查后再编码。 | 访问禁用期间不规划生产调用。 | `claude-opus-4-8`。 |
| 主要风险 | 预览权限、surface 不匹配、推广过度。 | 把旧演示或价格行当成 live access。 | 没有同任务验证就默认它赢。 |
成本要按同一任务比较
官方标价只有放到同一任务单位里才有意义。OpenAI 当前材料列出 GPT-5.6 Sol 预览价格为每百万输入 `5\`、输出 \`30`。Anthropic 列出 Fable 5 的 list price 为输入 `10\`、输出 \`50`,但当前不可用。Anthropic 模型文档列出 Opus 4.8 为输入 `5\`、输出 \`25`。

用一个 200k input 加 40k output 的 coding-agent 任务做粗算,在不考虑 cache、batch、重试和地区条款前,Sol 约 `2.20\`,Fable 的 list row 约 \`4.00` 但不可用,Opus 4.8 约 `$2.00`。这不等于 Opus 永远赢,而是说明 Opus 是当前可运行的价格基线,Sol 需要用质量、时间节省或失败率降低来证明自己值得切入。
真正应该比较的是 task cost。一个模型 token 行贵一点,但一次完成、格式稳定、人工审查少,最终可能更便宜。另一个模型表面便宜,却反复调用工具、输出格式漂移、需要人工修复,真实成本会更高。记录 input、cached input、output、retry、tool call、耗时和人工审查分钟,才可以谈默认模型切换。
跑分只能决定先测谁
跑分是测试理由,不是跳过访问表的理由。OpenAI 对 Sol 的发布叙事强调 terminal-driven agentic coding,并给出强势结果。对于已经有 Sol 预览权限、任务又接近仓库编辑、终端恢复、多步工具调用的团队,这是很强的 pilot 信号。
但 provider benchmark 回答的问题比生产决策窄。它不能证明你的账号有权限,不能证明你的工具 harness 兼容,不能证明长上下文 prompt 不漂移,也不能证明总审查时间降低。它更不能让 Anthropic 当前标为 unavailable 的 Fable 5 变成可部署模型。
正确用法是把跑分拆成 workload hint。终端编码任务且有 Sol 权限,就把 Sol 放进第一测试车道。客户可见的 API agent、日志、限流、回滚和稳定性优先,就把 Opus 4.8 放进稳定车道。Fable 相关研究可以保留测试 harness,但访问页没有恢复前不要安排生产切换。
编码 agent 测试计划
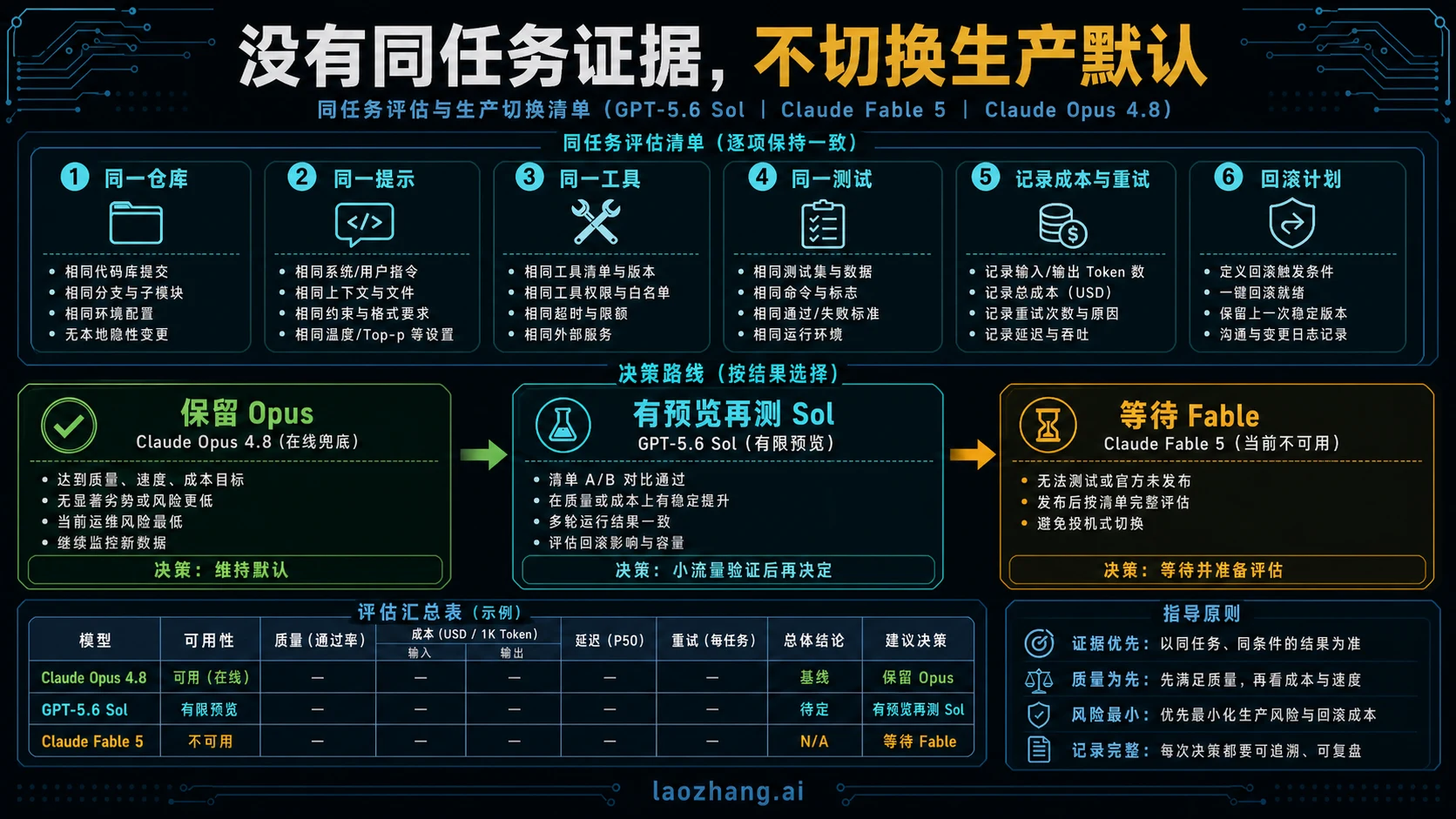
公平比较不是让模型跑同一个标题,而是跑同一批真实任务。选 10 到 20 个已经消耗审查时间的任务:失败测试修复、带隐含约束的重构、长上下文 bug hunt、需要验证代码的文档更新、工具调用失败后的恢复任务。不要选只会让某个模型好看的 demo prompt。
Opus 4.8 要通过你今天能部署的 endpoint 跑。Sol 只能通过你实际获批的 OpenAI surface 跑。Fable 在访问恢复前只留未来测试栏。每次都记录首轮正确率、工具恢复、格式稳定、输出长度、总 token、重试次数、延迟和人工审查分钟。
默认模型切换阈值要保守:只有模型在同一任务集上减少总工作量,并且有回滚路线,才可以进入默认。Sol 如果只在预览 workspace 里赢,就先作为 specialist route。Opus 如果凭可靠性和 live support 赢,就继续做 baseline。Fable 之后如果恢复,也用同一套 harness 重跑,而不是复用旧比较结论。
如果你已经看过相邻模型对比
如果你刚看过 GPT-5.5 或 Opus 4.7 的文章,应该继承的是 route-first 方法,而不是旧事实。旧的 GPT-5.5 对比 Claude Opus 4.7 对评估结构仍有帮助,但访问状态、模型名和价格行已经变化。任何价格、context 或可用性行都必须重新看官方页面。
如果你的真实问题是 Fable 值不值得等,更窄的 Claude Fable 5 对比 GLM 5.2 可以补充之前的 Fable 语境。但在本文的当前判断里,Anthropic 仍标注不可用时,Fable 5 不能被推荐成下一步生产路线。
稳定的判断规则很短:保留今天支持系统运行的 live 模型;只在权限存在且风险可接受的地方加入预览模型;把不可用模型放进 watchlist;没有同任务证据,什么都不提升为默认。
常见问题
GPT-5.6 Sol 公开可用了吗?
没有。OpenAI 把 GPT-5.6 Sol 描述为已批准组织的有限预览,而且 API organization 和 Codex workspace 权限需要分别确认。没有对应权限时,Sol 不是今天的生产路线。
Claude Fable 5 现在能用吗?
Anthropic 当前 Fable 材料显示 unavailable,6 月 12 日访问声明也说 Fable 5 和 Mythos 5 需要对所有客户停用。它现在应该被当作等待并复查的模型。
Claude Opus 4.8 是最稳默认吗?
在这三个模型里,Opus 4.8 是今天 live 状态最清楚的 Anthropic baseline。它仍然需要同任务评估,才能替换另一个已经工作的默认模型。
哪个更便宜?
按 200k input 加 40k output 的简单 list math,Opus 4.8 约 `2.00\`,Sol 预览约 \`2.20`,Fable list row 约 `$4.00` 但不可用。真实成本还要看 cache、batch、重试、延迟和人工审查时间。
跑分能直接决定赢家吗?
不能。跑分只能决定先测谁;访问状态、任务适配、成本日志、失败率和回滚安全才决定谁能成为生产默认。