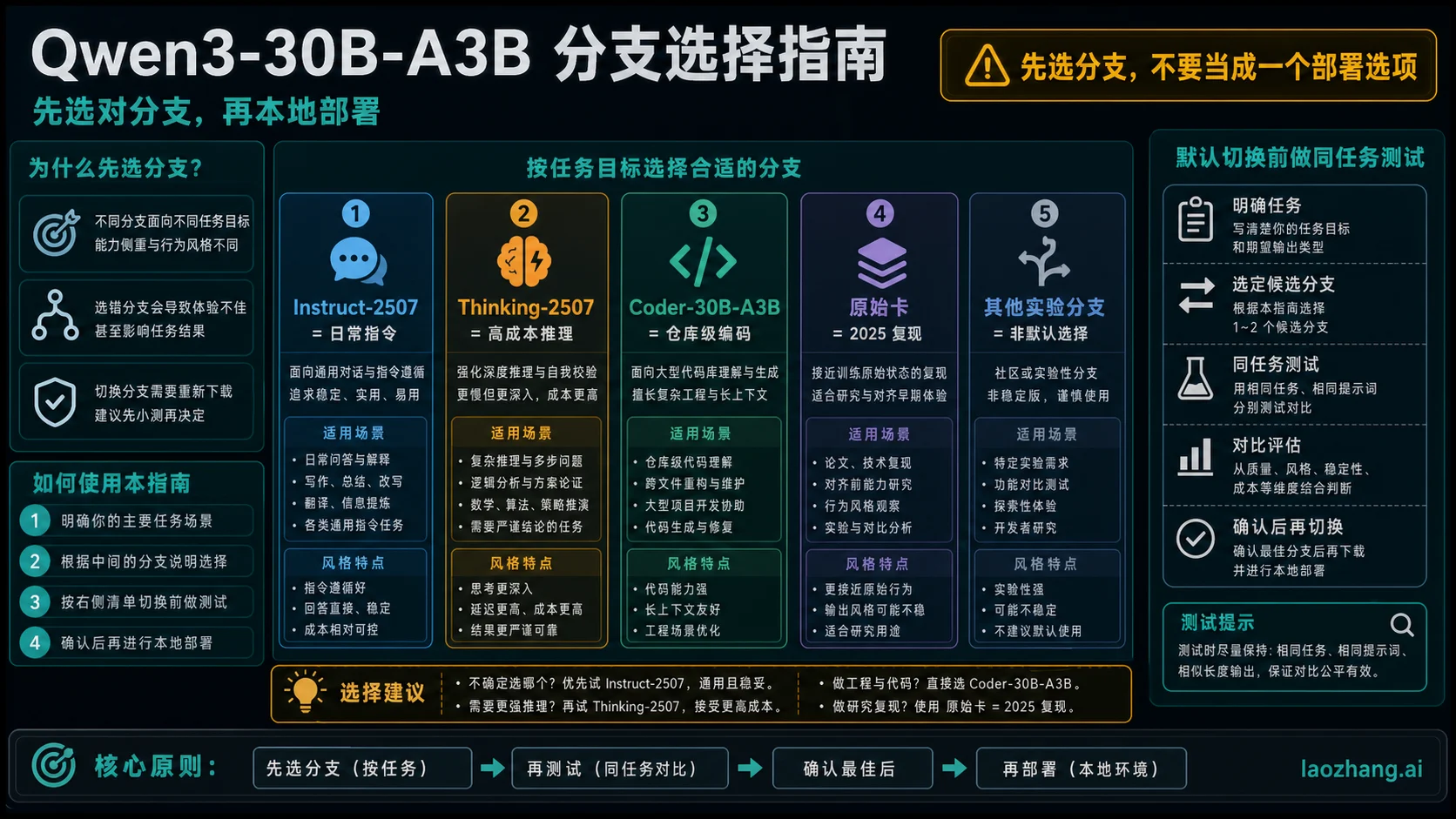
截至 2026 年 5 月 22 日,Qwen3-30B-A3B 不能再被当成一个简单的本地部署选项。第一步要先选分支:日常指令和摘要先测 Qwen/Qwen3-30B-A3B-Instruct-2507,高成本推理先测 Qwen/Qwen3-30B-A3B-Thinking-2507,仓库级编码先测 Qwen/Qwen3-Coder-30B-A3B-Instruct,只有做 2025 年 4 月原始混合模型复现时才优先回到 Qwen/Qwen3-30B-A3B 原始卡。
A3B 只说明这是稀疏 MoE 的激活参数形态,不等于一个固定硬件答案,也不等于一个固定运行时标签。真正影响部署判断的是分支、上下文长度、量化方式、KV cache、推理框架、batch 和你要跑的任务。
| 你的任务 | 先测的分支 | 切换默认前要验证 |
|---|---|---|
| 日常本地问答、摘要、分类、普通 Agent 指令 | Qwen/Qwen3-30B-A3B-Instruct-2507 | 它是非 thinking 分支,不要期待 <think> 输出。 |
| 多步推理、计划、复杂审阅、长文综合 | Qwen/Qwen3-30B-A3B-Thinking-2507 | 记录延迟、输出长度、人工审阅成本和真实正确率。 |
| 仓库级编码、工具调用、长上下文代码任务 | Qwen/Qwen3-Coder-30B-A3B-Instruct | 把它当 Coder 分支测,不要当原始通用卡的别名。 |
| 复现 2025 年 4 月的 Qwen3 结果或旧评测 | Qwen/Qwen3-30B-A3B | 使用原始 owner card 和 32K native context 边界。 |
| 想看更新的 Qwen 本地路线 | 单独评估 Qwen3.6-35B-A3B | Qwen3.6 是后续边界,不是同一模型行。 |
停止规则:不要因为一次演示、一个运行时标签或一句“30B 只激活 3B”就替换当前默认模型。只有在同一提示词、同一文件、同一工具、同一上下文预算、同一测试命令、同一延迟预算和同一 reviewer 标准下,候选分支持续不输当前默认,才进入默认切换讨论。
快速答案
日常本地使用先测 Instruct-2507。它适合总结、改写、分类、普通问答、轻量 Agent 提示和需要干净输出的工作。Hugging Face 分支卡把它定位为非 thinking 分支,并记录 262,144 token 的 native context。这个定位对默认模型很重要:多数团队想要的是低摩擦完成任务,而不是每次都处理很长的思考痕迹。
复杂推理先测 Thinking-2507。它适合多步数学、规划、长文综合、对抗式审阅和需要显式推理行为的任务。它不应该因为名字更“聪明”就替代所有聊天任务。推理分支的成本包括更长输出、更慢审阅和更高延迟;如果额外推理没有减少返工,它就不是更好的默认。
代码任务先测 Coder-30B-A3B。Qwen3-Coder 的材料围绕编码和工具使用展开,天然更适合仓库搜索、跨文件修改、补测试、重构和长上下文代码任务。它仍然需要真实仓库验证,不能靠分支名保证通过更多测试,但首测路线应该从 Coder 分支开始。
原始 Qwen/Qwen3-30B-A3B 仍然有价值。它适合复现 2025 年 4 月 Qwen3 发布时的混合 thinking / non-thinking 行为,或者把新分支和旧评测放在同一基线下比较。它不适合被静默当作 2026 年新的默认本地模型。
A3B 到底说明什么
Qwen3 官方发布材料和 Qwen/Qwen3-30B-A3B 模型卡把原始模型描述为稀疏 mixture-of-experts。owner card 记录了 30.5B 总参数、3.3B 激活参数、48 层、128 个专家和 8 个 active experts。这个形态解释了为什么它对本地实验很有吸引力:总模型规模较大,但每个 token 激活的是较小专家切片。
激活参数不是部署成本的完整答案。实际内存压力还包括加载权重、量化格式、上下文长度、KV cache、推理框架开销、batch、并发和 prompt 模板。短上下文 4-bit 聊天、长上下文代码 Agent、多并发服务和推理型长输出,是完全不同的部署场景。只问“需要多少 VRAM”很容易得到看似确定但不可迁移的答案。
上下文边界也必须分开。原始卡记录 32,768 native context 和 131,072 with YaRN;Instruct-2507 和 Thinking-2507 分支记录 262,144 native context;Coder-30B-A3B 记录 262,144 native context,并带有 1M with YaRN 的边界。把这些分支混成一行,会让速度、质量和内存比较都失真。

分支应该怎么选
选择顺序取决于任务失败的代价。日常指令失败通常是多改一句、重跑一次,优先要低延迟、干净输出和稳定格式;推理任务失败可能带来错误结论,优先看多步可靠性;编码任务失败可能污染仓库、漏测、引入隐藏缺陷,优先看工具纪律和测试通过。
Instruct-2507 是最像默认助手的分支。它适合每天大量出现的普通请求:解释日志、总结文档、改写邮件、生成结构化列表、做小规模 Agent 计划。测试时不要只看回答是否“聪明”,还要看格式是否稳定、是否愿意承认边界、是否会在不该展开时过度输出。
Thinking-2507 应该独立测。适合它的任务通常有一个共同点:更长的中间推理能减少最终错误。比如多约束计划、复杂故障排查、长文综合、反例审查和推理题。它的风险也很具体:如果输出更长但人工审阅时间翻倍,生产效率可能下降。
Coder-30B-A3B 应该承担代码首测。仓库级任务要看能不能找对文件、改动范围是否克制、是否保留现有风格、是否运行正确测试、失败后是否能收敛。一个通用聊天分支可以写代码片段,但不等于适合多文件 repo loop。
原始卡适合历史对齐。旧 benchmark、早期 quantized build、Qwen3 发布周文章和混合模式复现,都需要原始 owner card。把原始卡继续当基线是合理的,把它当新默认则需要额外证明。
Qwen3.6 要单独处理。Qwen3.6-35B-A3B 是更新的 Qwen local / coding 边界。如果问题已经变成“Qwen3.6、Kimi K2.6、GLM-5.1 谁先测”,应该转到 Qwen3.6、Kimi K2.6、GLM-5.1 首测路线,不要把 Qwen3-30B-A3B 拉成跨模型对比。
运行时不是事实归属
Ollama、LM Studio、llama.cpp、vLLM 和 SGLang 很有用,因为它们把模型选择变成可运行的本地环境。它们不是上游模型事实的 owner。一个运行时标签可能包含量化选择、prompt template、默认上下文、分支映射和服务端参数。比较质量之前,先确认上游模型 ID 和分支。
Ollama 的 qwen3:30b-a3b 这类页面适合作为启动入口。它能让本地用户快速拉起模型,验证基础可用性,观察推理速度和显存压力。参数数量、专家数、分支行为和 context 边界仍然要回到 Qwen 和 Hugging Face owner card。
社区量化包也是同样逻辑。某个 GGUF、AWQ 或 GPTQ 版本可能正适合你的 GPU,但一旦量化、模板、上下文或 server 改了,你测试的就是完整部署栈,不只是模型卡。把“模型质量”和“部署栈行为”拆开,后续定位问题会容易很多。

硬件与上下文怎么测
诚实的硬件答案一定是条件句。量化越低,权重占用越小,但质量和兼容性可能变化;上下文越长,KV cache 越大;batch 和并发越高,峰值内存越紧;框架不同,offload、attention 实现和分页策略也不同。固定数字只能对应固定配置,不能当作所有 Qwen3-30B-A3B 场景的答案。
日常聊天测试可以先从短上下文开始,观察加载、首 token、输出速度和稳定性。代码 Agent 测试要加入真实仓库文件、工具输出、失败重试和较长上下文。推理分支测试要记录输出长度、审阅时间和是否真的减少错误。三类任务的瓶颈不同,不能用一条命令的速度决定所有默认。
安全试点从小任务开始。先用真实但可控的短任务验证分支和运行时,再逐步扩大上下文,记录内存压力、崩溃、降速、分页和错误恢复。不要在还没确认短任务稳定时直接把最大上下文拉满,也不要在单次成功后把它写进团队默认。
同任务试点清单
模型比较只有落到同一任务才有决策价值。选 5 到 10 个已经知道正确答案或验收标准的任务:一条日志解释、一个摘要、一个多步推理题、一个小 bug 修复、一个跨文件重构、一个测试补齐、一个长上下文阅读任务。当前默认模型和候选 Qwen 分支必须拿到同一份材料。

| 测试项 | 必须保持一致 | 记录什么 |
|---|---|---|
| 提示词 | 用户任务、系统规则、输出格式 | 是否一次解决任务,是否需要额外修补 |
| 上下文 | 文件、日志、片段、token 预算 | 长上下文下是否漏引用、丢约束或跑偏 |
| 工具 | 命令、权限、重试策略 | 工具调用是否准确,是否有多余动作 |
| 测试 | 单测、评测集、人工检查 | accepted diff、失败检查、隐藏缺陷 |
| 运行 | 硬件、运行时、量化、batch | 延迟、内存压力、崩溃和恢复时间 |
候选分支只有在任务完成率、人工修改量、重试次数、隐藏缺陷和运行成本上持续不输当前默认,才适合进入默认切换。更快但需要更多人工修正,不是真的更快。更聪明但跑不进你的内存和延迟预算,也不是更好的默认。
维护时看哪些官方来源
维护模型笔记时要把来源分层。Qwen 的 Qwen3 发布材料负责原始家族 framing、开放权重 MoE、Apache 2.0 背景和模型表。Qwen/Qwen3-30B-A3B Hugging Face 卡负责原始模型事实:参数、专家、激活专家、混合行为和原始 context。Instruct-2507、Thinking-2507 卡负责对应分支行为和 262K native context。
Qwen3-Coder-30B-A3B 卡和 Qwen3-Coder 材料负责 coding branch 的定位。Ollama 和其他运行时负责安装便利性和部署标签。Qwen3.6 材料负责 successor boundary。保持这些 owner lane 分开,下一次分支更新时只需要改受影响的行,而不是重写整套判断。
常见问题
Qwen3-30B-A3B 现在还值得本地跑吗?
值得,但要看分支。Instruct-2507 适合日常本地指令,Thinking-2507 适合推理重任务,Coder-30B-A3B 适合代码循环。原始卡主要用于 2025 年 4 月复现和旧比较。
A3B 是 3B 模型吗?
不是。A3B 指的是稀疏 MoE 中每个 token 激活的参数切片。原始 owner card 记录 30.5B 总参数和 3.3B 激活参数。部署内存仍然受完整运行栈影响。
Instruct-2507 和 Thinking-2507 该怎么选?
普通输出、低延迟和格式稳定优先选 Instruct-2507。任务足够难,并且额外推理能减少错误时,再测 Thinking-2507。
Qwen3-Coder-30B-A3B 是同一个模型吗?
它是相关的 Coder 分支,不应被当成原始 Qwen/Qwen3-30B-A3B 的同义词。代码、工具和长上下文仓库任务应该优先测它。
Ollama 能告诉我自己跑的是哪个分支吗?
Ollama 能提供实用运行入口,但仍要核对上游模型 ID、量化、上下文设置和 prompt template。运行时便利性不等于官方模型身份。
需要多少 VRAM?
没有一个数字适合所有配置。量化、上下文长度、KV cache、框架开销、batch 和并发都会改变内存压力。先用最小真实上下文测,再逐步扩大窗口。
什么时候该看 Qwen3.6?
当真正问题是更新的 Qwen local / coding 路线,而不是精确的 Qwen3-30B-A3B 分支选择时,再看 Qwen3.6-35B-A3B。它是后续比较,不是这个模型 ID 的静默替代。