
Gemini 在 2026 年提供了五种不同的图片生成模型,每种模型在错误行为、速率限制和水印策略上各有不同。无论你是遇到了四种完全不同问题却返回相同 429 RESOURCE_EXHAUSTED 错误码的困境,还是搞不懂免费层 API 为什么一张图都生成不了,又或者在纠结为什么生成的图片带着客户不想要的 Gemini 星形标志——这份指南将所有问题一网打尽。所有数据均已核实,来源为 2026 年 3 月 ai.google.dev 官方定价和速率限制文档。
要点速览
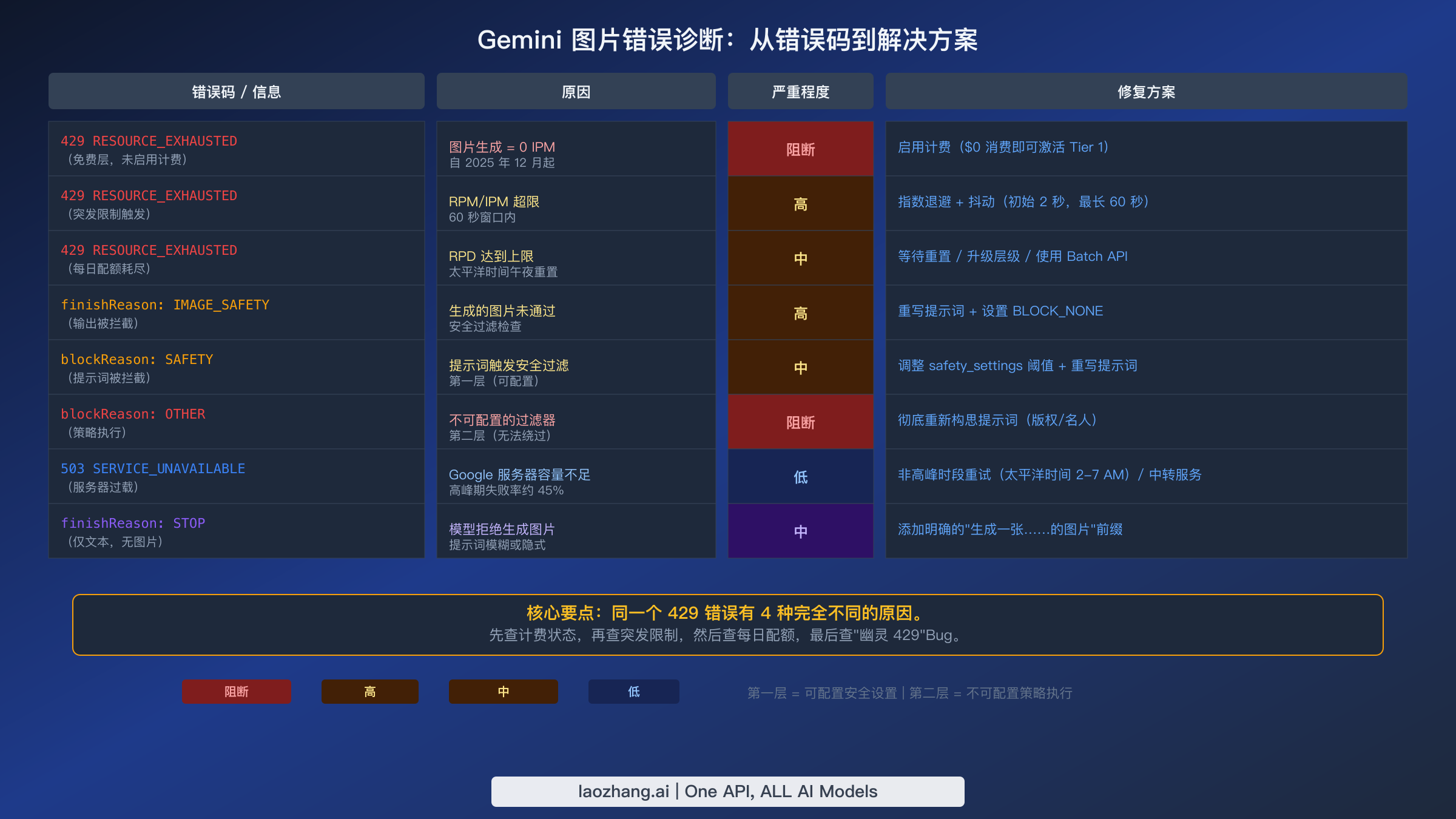
- 429 错误有 4 种不同原因,但表现完全一样:未启用计费(免费层自 2025 年 12 月起图片生成 IPM 为 0)、RPM 突发限制、每日 RPD 配额耗尽,以及影响最近升级账户的"幽灵 429"Bug。
- 五个模型、三个层级、限额天差地别。 Imagen 4 Fast($0.02/张)有免费层可用。Gemini 3.1 Flash Image($0.067/张)和 Gemini 3 Pro Image($0.134/张)免费层 IPM 为 0。Tier 1 只需启用计费即可。Tier 2 需累计消费 $250 以上。
- IMAGE_SAFETY 和 blockReason 是两回事。 IMAGE_SAFETY 在图片生成后拦截输出。blockReason SAFETY 在生成前拦截提示词(可配置)。blockReason OTHER 是不可配置的策略过滤器,无法绕过。
- 两种水印,两种现实。 可见的 Gemini 星形标志可以用工具去除,也可以通过使用 API 来完全避免。不可见的 SynthID 水印在像素生成过程中嵌入,不破坏图片就无法去除。
- 最佳免费方案: 通过 AI Studio 使用 Imagen 4 Fast(免费层可用),或启用 $0 计费解锁 Gemini 模型的 Tier 1。
Gemini 图片生成所有错误码详解
Gemini 图片生成最令人困惑的地方在于,同一个错误码可能意味着完全不同的问题,具体取决于你的账户配置。理解每个错误背后的真正原因,是几秒钟解决问题与浪费数小时走弯路之间的关键区别。基于对 Gemini API 官方文档、Google 开发者论坛反馈以及多个生产应用的日志分析,以下是每个错误的真正含义和修复方法。
429 RESOURCE_EXHAUSTED:一码四因的难题
429 错误是目前 Gemini 图片生成中最常见的错误,也是最具误导性的。Google 对四种根本不同的问题返回完全相同的 RESOURCE_EXHAUSTED 状态码,而每种问题的修复方法截然不同。第一种也是最常见的原因是你的项目处于免费层,而免费层自 2025 年 12 月 7 日起 Gemini 图片模型的 IPM(每分钟图片数)已精确设为零。这意味着如果你没有在 Google Cloud 项目上启用计费,每一个图片生成请求都会以 429 失败——不管你之前发了零个请求还是一千个。修复方法很简单:在 Google Cloud Console 中启用计费,即使你设置 $0 的消费限额也行。仅仅激活计费就能将你升级到 Tier 1,从而解锁图片生成能力。你可以在我们的专题排错指南中了解 Gemini 图片 429 错误的完整解决方案。
第二种原因是突发速率限制——你在一分钟内超过了所在层级的请求上限。Tier 1 大多数模型允许每分钟 15 个请求,所以在 60 秒窗口内发送第 16 个请求就会触发此错误。修复方法是带抖动的指数退避——从 2 秒延迟开始,每次重试翻倍,最多 60 秒,加上 25% 的随机偏差以防止多客户端同步重试风暴。第三种原因是每日配额耗尽——你达到了 RPD(每日请求数)上限。Tier 1 的 Flash Image 模型允许每天 1,500 RPD,在太平洋时间午夜重置。如果你的应用全天生成图片而不追踪消耗量,可能比预期更快耗尽配额,特别是每次重试也计入每日限额。
第四种也是最令人头疼的原因是"幽灵 429"Bug——一个主要影响最近从免费层升级到 Tier 1 账户的服务端问题。启用计费后的最初 24 到 48 小时内,配额执行系统可能会错误计算你的用量,即使你远未达到限额也返回 429 错误。多个 Google 开发者论坛帖子记录了临时解决方案:切换到不同的模型变体——如果你在用 gemini-3.1-flash-image-preview,尝试 gemini-3-pro-image-preview,反之亦然,因为这通常能绕过受影响的配额执行路径。大多数情况下,等待 24 到 48 小时让配额传播完成即可解决。
IMAGE_SAFETY 和安全过滤器:第一层 vs 第二层
Gemini 图片生成中的安全相关错误采用两层系统运作,大多数开发者将其混为一谈。第一层由可配置的安全设置组成,你可以通过 API 请求中的 safety_settings 参数进行控制。当提示词触发第一层拦截时,响应中会返回 blockReason: SAFETY,你可以通过将特定危害类别(骚扰、仇恨言论、色情内容、危险内容)的阈值调整为 BLOCK_NONE 或 OFF 来解决。对于 Gemini 2.5 及更新的模型,默认安全阈值已设为 OFF,这意味着大多数第一层拦截只在你显式配置了安全设置时才会发生。理解 blockReason OTHER 和不可配置安全过滤器的细微差别对生产应用至关重要。
然而第二层完全是另一回事。当你看到 blockReason: OTHER 或 finishReason: IMAGE_SAFETY 时,说明触发了不可配置的策略执行过滤器,任何 API 参数都无法绕过。第二层强制执行版权保护(生成受版权保护的角色或标志)、名人限制(可识别真实人物的逼真图片)和强制性儿童安全保护。无论怎样调整 safety_settings 都不会改变第二层拦截——唯一的解决方案是从根本上重新措辞你的提示词以避免受保护内容。对于被错误拦截的合法用例,可以通过 Google AI Developer Forum 报告误判,但响应时间差异很大。
静默失败和纯文本响应
也许最令人困惑的"错误"根本不是错误。当 Gemini 返回 finishReason: STOP 且只有文本内容没有图片时,说明模型决定不生成图片,但没有抛出明确的错误。这通常发生在模型将其解读为纯文本请求的模糊提示词、太笼统而无法用于图片生成的提示词,或者模型判断无法创建满意图片的情况下。修复方法是在提示词中添加明确的图片生成指令——在开头加上"生成一张……的图片"或"创建一张展示……的真实感图片"来清楚表达你的意图。模型名称错误:出人意料的常见陷阱
在你遇到速率限制或安全过滤器之前,错误的模型标识符就会导致请求以 404 Not Found 或"Invalid model name"错误失败。Google 的图片生成模型命名规范在各文档中不一致,从过时教程中复制粘贴模型名称是新开发者最常见的错误来源之一。截至 2026 年 3 月的正确模型标识符为:Flash Image 模型使用 gemini-3.1-flash-image-preview(不是 gemini-flash-image 或 gemini-3.1-flash-preview-image),Pro Image 模型使用 gemini-3-pro-image-preview(不是 gemini-pro-image 或 gemini-3-pro-preview-image),Imagen 4 家族使用 imagen-4-fast、imagen-4-standard 或 imagen-4-ultra。旧的 gemini-2.5-flash-image 标识符仍然有效,但会路由到上一代模型,定价和功能都不同。在调试其他潜在的请求失败原因之前,务必对照 ai.google.dev/gemini-api/docs/models 官方模型页面验证你的模型标识符。
503 SERVICE_UNAVAILABLE 错误诊断更简单:Google 服务器容量已满。在高峰时段(大约太平洋时间上午 9 点到下午 5 点),根据 2025 年 12 月至 2026 年 2 月的社区报告,图片生成的失败率可达约 45%。解决方案是在非高峰时段(太平洋时间凌晨 2 点到 7 点)重试,或使用自带队列管理和重试机制的中转服务。
速率限制和配额:每个模型、每个层级

要理解速率限制系统,需要知道 Google 同时运行三个独立的配额维度:RPM(每分钟请求数)控制突发吞吐量,RPD(每日请求数)控制每日总量,IPM(每分钟图片数)专门限制图片生成输出。触碰任何一个限制都会触发 429 错误,而错误信息不会告诉你触碰的是哪个限制。想深入了解所有 Gemini API 层级,可以查看我们的完整速率限制指南。
免费层是大多数困惑的根源。虽然 Google 宣传 Gemini 模型提供慷慨的免费请求限额(某些模型高达 500 RPD),但 Gemini 模型在免费层的图片生成配额(IPM)被设为零。这意味着你可以免费发送文本提示词,但任何尝试生成图片的请求都会以 429 错误失败。例外是 Imagen 4,它确实通过 AI Studio 提供有限的免费层可用性,不过确切的每日限额会波动,Google 也未公布官方数字。社区测试表明免费层大约有 500 个 Imagen 4 每日请求可用,但这个数字因地区、账户年龄和时间而异。Gemini App(gemini.google.com 的消费者界面)提供单独的约 100 次免费图片生成额度,这与 API 和 AI Studio 配额完全独立。如果你想最大化 Gemini 免费图片生成配额,我们的专题指南涵盖了叠加这些独立配额池的所有技巧。
2025 年 12 月的配额削减是 Gemini 免费层历史上最剧烈的变化。在 2025 年 12 月 7 日之前,免费 API 层允许使用 Gemini 模型进行有限的图片生成。此后,Google 将所有 Gemini 图片模型在免费层的 IPM 精确设为零,同时将 Gemini 2.5 Flash 的每日请求限额从约 250 RPD 大幅削减至仅 20——降幅达 92%。这些削减似乎反映了 Google 的策略:将认真使用图片生成的用户推向付费层,同时保持对纯文本工作负载的慷慨免费访问。
Tier 1 在你于 Google Cloud 项目上启用计费后即可解锁。你不需要实际支付任何费用——仅激活绑定有效信用卡的计费账户即可。Tier 1 为 Flash Image 模型提供 15 RPM 和 1,500 RPD,为 Pro Image 模型提供 2 RPM 和 50 RPD。这两个模型之间的巨大差距反映了不同的目标用途:Flash 适合低成本的大批量生成,Pro 适合偶尔的高质量生成。Tier 2 需要至少 30 天累计消费 $250 以上,之后限额大幅提升至 Flash 的 2,000 RPM 和 50,000 RPD,以及 Pro 的 1,000 RPM 和 10,000 RPD。Batch API 值得特别提及,因为它在独立的配额池上运行,且 token 定价自动享受 50% 折扣,非常适合不要求实时性的批量生成。
这个分层系统的实际意义是:最经济的图片生成路径从 Imagen 4 Fast($0.02/张,有一定免费层可用性)开始,启用计费后升级到 Gemini 3.1 Flash Image($0.067/张),只有在你确实需要其卓越质量用于专业应用时才使用 Gemini 3 Pro Image($0.134/张)。
一个经常被忽视的最大化有效配额的策略是同时使用多种访问方式。Gemini App(消费者界面)、AI Studio 网页界面和开发者 API 各自运行在完全独立的配额池上。这意味着一个耗尽了 API 每日配额的开发者仍然可以使用同一 Google 账户通过 AI Studio 网页界面生成图片。虽然这不是一个可扩展的生产策略,但在开发和测试期间提供了一个有用的安全阀,可以节省 API 配额用于生产流量。此外,不同的 Gemini 图片模型拥有独立配额——gemini-3.1-flash-image-preview 达到速率限制不会影响你在 gemini-3-pro-image-preview 或 imagen-4-fast 上的配额,使模型轮换成为一个在单个模型限额不足时维持持续吞吐量的可行策略。
如何修复 Gemini 图片生成错误
生产应用需要能区分不同 429 原因并针对每种情况做出适当响应的错误处理。以下 Python 实现展示了一个涵盖最常见故障模式的错误处理器,包括针对速率限制的带抖动指数退避、免费层拦截的计费检测,以及持续失败时的模型降级。
pythonimport time import random import google.generativeai as genai def generate_image_with_retry(prompt, model_name="gemini-3.1-flash-image-preview", max_retries=5, base_delay=2.0): """Generate image with comprehensive error handling.""" fallback_models = [ "gemini-3.1-flash-image-preview", "gemini-3-pro-image-preview", "imagen-4-fast" ] for attempt in range(max_retries): try: model = genai.GenerativeModel(model_name) response = model.generate_content( f"Generate an image: {prompt}", generation_config={"response_mime_type": "image/png"} ) # Check for safety blocks if response.prompt_feedback and response.prompt_feedback.block_reason: reason = response.prompt_feedback.block_reason if str(reason) == "OTHER": raise Exception("Layer 2 policy block - rephrase prompt") else: raise Exception(f"Safety block: {reason} - adjust safety_settings") # Check for image in response for part in response.candidates[0].content.parts: if hasattr(part, 'inline_data') and part.inline_data: return part.inline_data.data # Image bytes raise Exception("No image in response - add explicit image instruction") except Exception as e: error_str = str(e) if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str: delay = base_delay * (2 ** attempt) * (1 + random.random() * 0.25) delay = min(delay, 60) print(f"Rate limited (attempt {attempt+1}). Waiting {delay:.1f}s...") time.sleep(delay) elif "503" in error_str: # Server overloaded - try fallback model current_idx = fallback_models.index(model_name) if model_name in fallback_models else -1 if current_idx < len(fallback_models) - 1: model_name = fallback_models[current_idx + 1] print(f"Server overloaded. Switching to {model_name}") else: time.sleep(base_delay * (2 ** attempt)) else: raise # Non-retryable error raise Exception(f"Failed after {max_retries} retries")
除了重试逻辑之外,一个让许多开发者踩坑的关键实现细节是响应解析结构。与文本生成中 response.text 直接给出完整输出的单个字符串不同,图片生成响应将生成的图片作为 inline_data 嵌入在 candidates[0].content.parts 中的 Part 对象里。访问图片数据需要遍历 parts 并检查 inline_data 属性,当模型返回文本而非图片时该属性完全不存在。尝试对图片响应访问 response.text 会抛出错误,而对纯文本响应访问图片数据会返回 None 而没有任何有用的错误信息。上面的代码显式处理了这两种情况,这对任何生产级实现都至关重要。
对于安全设置配置,关键认知是调整这些设置只影响第一层(可配置)安全过滤器,对第二层(策略执行)没有任何效果。以下配置将第一层过滤器放宽到最低,同时尊重不可更改的第二层边界。
pythonfrom google.generativeai.types import HarmCategory, HarmBlockThreshold safety_settings = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE, } model = genai.GenerativeModel(model_name, safety_settings=safety_settings)
Gemini 图片水印:可见标志、SynthID 与去除方案
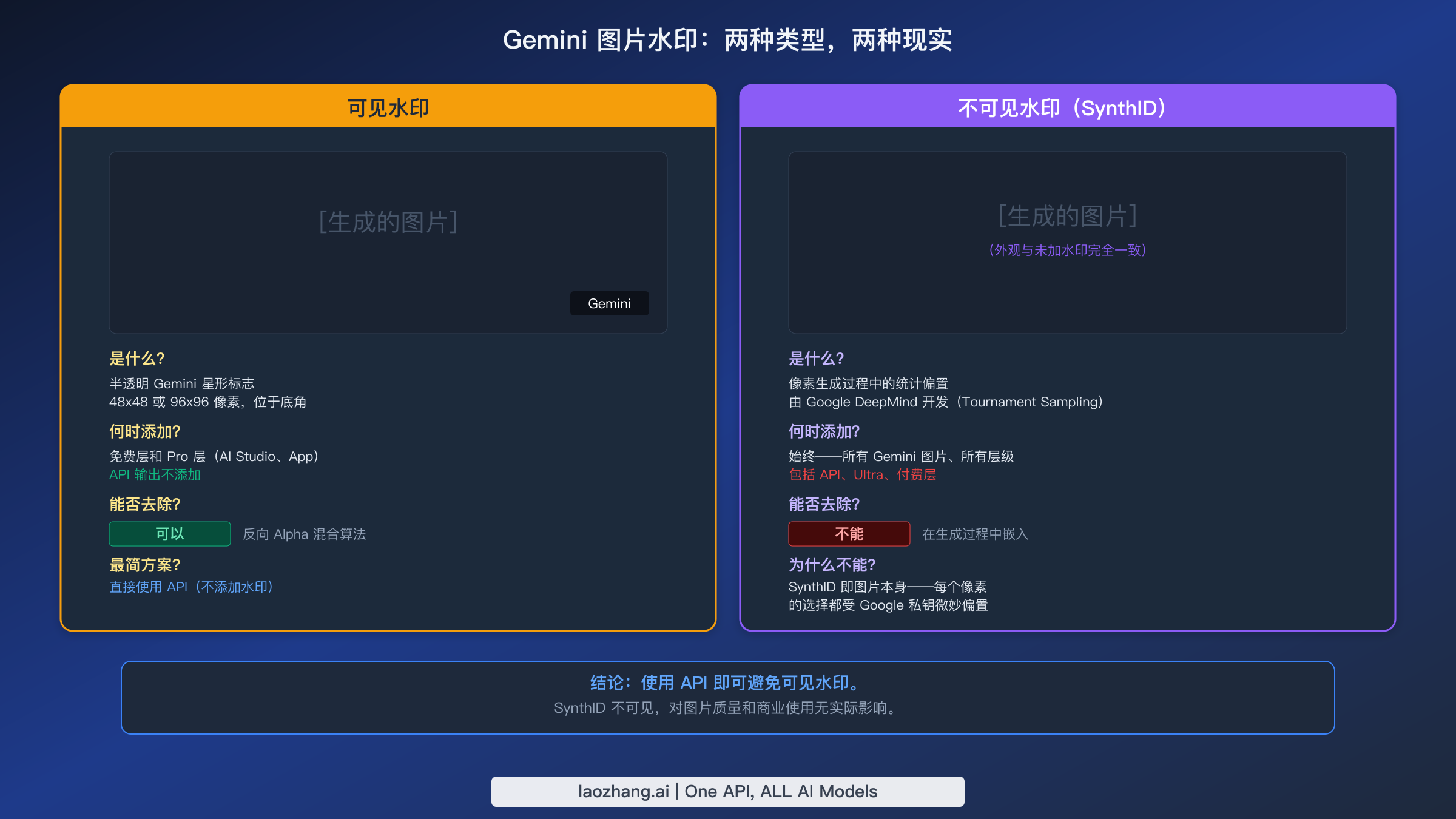
Google 的 Gemini 模型生成的每张图片都带有两种截然不同的水印,理解它们之间的根本区别对于任何商业使用 Gemini 图片的人来说都至关重要。第一种是可见水印——AI Studio 和 Gemini App 生成的图片角落出现的那个熟悉的 Gemini 星形标志。第二种是 SynthID,由 Google DeepMind 开发的不可见水印,嵌入在每一张 Gemini 生成的图片中,无论你通过什么方式创建或使用什么订阅层级。
可见水印:容易处理
可见的 Gemini 水印是一个半透明的标志叠加层,通常为 48x48 或 96x96 像素,位于生成图片的某个底角。它作为后处理步骤应用于通过 Gemini Web App 和 AI Studio 生成的图片,但关键的是,通过 API 生成的图片不会添加此水印。这意味着获得没有可见水印的干净图片最简单的方法就是直接使用 API,无论是通过你自己的集成还是通过中转服务。对于已经带有可见水印的图片,有几个开源工具实现了反向 Alpha 混合算法,可以精确去除叠加层而不影响底层图片内容。GitHub 上的 GeminiWatermarkTool 等工具能实现像素级精确去除,因为水印是以已知的 Alpha 透明度模式应用的,可以通过数学方法反向还原。
SynthID:水印即图片本身
SynthID 与传统水印有着本质区别。它不是在图片生成后添加的叠加层,而是在生成过程本身中运作。Google DeepMind 的 Tournament Sampling 算法使用私有加密密钥在图片创建期间微妙地偏置每个像素的选择。结果是一张看起来与未加水印版本完全相同的图片,但包含可被 Google 验证工具检测到的统计签名。这个区别很重要,因为它意味着 SynthID 在任何有意义的层面上都无法被"去除"——水印不是添加到图片上的独立层或图案,而是图片生成方式的固有属性。图片中的每个像素都携带着水印的痕迹。有些工具声称可以通过像素扰动来破坏 SynthID,但这通常会降低图片质量而无法可靠地消除水印,因为统计偏差分布在整个图片中,而非集中在任何可检测的区域。
从实际角度来看,SynthID 对生成图片的视觉质量没有影响,也不影响其商业可用性。它主要作为 AI 生成内容检测的来源验证工具存在,目前没有任何主要商业许可协议禁止使用包含 SynthID 水印的图片。对 SynthID 的担忧在很大程度上是理论性的而非实际性的,对于绑大多数用例,你可以像对待未加水印的图片一样使用 SynthID 标记的图片。
按访问方式区分的水印策略
水印行为根据你访问 Gemini 图片生成的方式有显著不同,理解这些差异可以为你节省时间和金钱。通过 Gemini 消费者应用(gemini.google.com)生成的图片始终带有可见的星形水印,无论你是免费用户、Pro 订阅($19.99/月)还是 Ultra 订阅($249.99/月)。通过 AI Studio 生成的图片也带有可见水印。然而,通过开发者 API(ai.google.dev)生成的图片则不带任何可见水印——API 输出是干净的。这意味着获取无水印图片最经济的方式不是花 $249.99/月购买 Ultra 订阅,而是以每张 $0.02 到 $0.134 不等的价格使用 API(取决于你选择的模型和分辨率)。对于构建应用的开发者来说这是标准做法,对于偶尔需要无水印图片的非开发者用户,中转服务提供了无需编写任何代码即可使用 API 的简单界面。
如何选择 Gemini 图片生成模型
Google 目前通过其 API 提供五种图片生成模型,选择合适的模型取决于你对质量、速度、成本和可靠性的具体需求。Gemini 3 Pro Image(gemini-3-pro-image-preview)以 1K 分辨率 $0.134/张的价格提供最高质量输出,4K 可达 $0.24。它支持最多 14 张输入图片用于编辑任务,产出最逼真的效果,但 Tier 1 的速率限制非常紧(仅 2 RPM 和 50 RPD),不适合没有 Tier 2 访问权限的高频应用。Gemini 3.1 Flash Image(gemini-3.1-flash-image-preview)是主力模型,成本仅为一半(1K 分辨率 $0.067/张),速率限制高得多(Tier 1 为 15 RPM、1,500 RPD)。它生成图片更快,能胜任大多数用例,但在精细摄影内容方面质量明显低于 Pro。
Imagen 4 是经济选项,提供三个子级别:Fast($0.02/张)、Standard($0.04/张)和 Ultra($0.06/张)。Imagen 4 在文本到图片的提示词理解能力上不及 Gemini 模型,但在背景去除、修复和风格迁移等特定任务上表现出色。至关重要的是,Imagen 4 是唯一在免费层 API 有可用性的模型家族,是无法立即启用计费的开发者的入门选择。对于大多数构建生产应用的开发者来说,推荐策略是将 Gemini 3.1 Flash Image 作为主力模型以平衡成本和质量,在速率限制或服务器过载期间降级到 Imagen 4 Fast,只有在质量值得 2 倍价格溢价的高端用例中才使用 Gemini 3 Pro Image。
在将可靠性与成本一并考虑时,值得注意的是 503 服务器过载错误并非均匀分布在各模型上。2025 年 12 月至 2026 年 2 月的社区报告显示,Pro Image 模型在高峰时段的失败率更高(约 45%),而 Flash Image 约为 30%,Imagen 4 约为 15%,这可能是因为 Pro Image 每个请求需要更多计算资源。对于时间敏感的应用,构建一个从首选模型开始、优雅降级到更便宜和可用性更高的替代方案的降级链,可以显著改善用户体验。上面错误处理部分的代码示例正是展示了这种模式——按 Flash、Pro、Imagen 4 的质量顺序循环,直到有一个成功。
分辨率维度为成本-质量计算增加了另一层考量。Gemini 3.1 Flash Image 支持四种分辨率——0.5K($0.045)、1K($0.067)、2K($0.101)和 4K($0.151)——而 Gemini 3 Pro Image 支持 1K($0.134)、2K($0.134,相同价格)和 4K($0.240)。一个有趣的优化是 Pro Image 的 1K 和 2K 收费相同,这使得 2K 对于不需要 4K 的 Pro Image 用户来说是显然更优的选择。对于 Flash Image,1K 到 2K 的跳升每张图片只增加 $0.034,对于图片质量重要的商业应用来说通常值得。
经济高效的替代方案与 API 中转服务
当 Gemini 原生的速率限制、服务器可靠性或错误率成为你应用的瓶颈时,中转服务提供了一条可以同时缓解多个问题的替代访问路径。laozhang.ai 等服务提供 OpenAI 兼容的 API,通过其自身基础设施路由到 Gemini 图片生成模型,提供内置的跨多个 Google Cloud 项目重试逻辑、通过请求分发实现更高的有效速率限制、宕机期间的自动模型降级,以及适用于 Gemini、GPT 和其他提供商的统一 API。对于 Gemini 图片生成,中转服务通常按每张图片收取固定费率(根据 laozhang.ai 的文档约为 $0.05),不受分辨率影响,这在 2K 和 4K 图片方面可能比原生的基于 token 的定价更经济。
Batch API 是另一条值得考虑的成本优化路径,适用于不要求实时性的工作负载。Google 的 Batch API 对所有 token 定价自动提供 50% 折扣,将 Flash Image 成本从 1K 分辨率的 $0.067 降至约 $0.034/张,Imagen 4 Fast 从 $0.02 降至仅 $0.01/张——使其成为所有主要提供商中最便宜的 AI 图片生成选项。代价是批量任务可能需要长达 24 小时才能完成,且限制为 100 个并发任务,因此这种方法最适合后台处理、内容管线和批量生成工作流,而非交互式应用。
对于每天需要跨多个项目生成数千张图片的团队,最具弹性的架构是将中转服务用于实时交互请求(延迟敏感)与 Batch API 用于后台处理(成本敏感)相结合。这种混合方案确保面向用户的功能始终通过中转服务的重试基础设施在数秒内获得图片,而批量处理任务如目录生成、社交媒体内容创建或数据集准备则以最低成本通过 Batch API 运行。混合架构中每张图片的总成本通常在 $0.025 到 $0.05 之间,取决于实时与批量的比例,与 Flash Image 默认分辨率的 $0.067 标准 API 价格或 Pro Image 的 $0.134 标准价格相比具有明显优势。
FAQ
为什么 Gemini 图片生成只返回文本没有图片?
这是一种静默失败,模型决定不生成图片但没有抛出明确的错误。最常见的原因是模型将模糊的提示词解读为纯文本请求。要解决此问题,请始终在提示词开头包含明确的图片生成指令,如"生成一张……的真实感图片"。同时确认你使用的是支持图片生成的模型(gemini-3.1-flash-image-preview 或 gemini-3-pro-image-preview),并且请求中包含正确的 response_mime_type 参数。如果模型持续拒绝为某个提示词生成图片,可能是触发了第二层安全过滤器但没有返回明确的错误码。
可以在不去除 SynthID 水印的情况下商业使用 Gemini 生成的图片吗?
可以。SynthID 是一种不可见水印,对图片质量和视觉外观没有任何影响。目前没有法律要求在商业使用的图片中披露 SynthID 的存在,Google 的 Gemini API 服务条款授予你将生成的图片用于商业目的的许可。但是,可见的 Gemini 星形水印在专业和商业应用中应当去除或避免(通过使用 API)。请务必查阅 Google 最新的生成式 AI 服务条款以获取最新的使用权限。
2026 年用 Gemini 生成图片最便宜的方式是什么?
绝对最便宜的选项是通过 Batch API 使用 Imagen 4 Fast,享受 50% 批量折扣后约 $0.01/张。实时生成中,Imagen 4 Fast 以 $0.02/张最便宜,其次是 Gemini 3.1 Flash Image 的 $0.067/张。如果需要免费生成,AI Studio 为 Imagen 4 提供有限的免费每日配额,Gemini App 通过消费者界面每天允许约 100 次免费图片生成,但这些带有可见水印且分辨率限制较低。
如何检查我的 Google Cloud 项目处于哪个速率限制层级?
访问 Google AI Studio 控制台 aistudio.google.com,进入项目设置,查看计费状态。免费层项目显示未关联计费账户。Tier 1 项目已启用计费但累计消费不足 $250。Tier 2 及以上在 console.cloud.google.com 的配额设置页面显示,路径为 IAM and Admin 然后 Quotas。你也可以通过发送测试请求并检查响应中的速率限制头来程序化检查。
为什么启用计费后立刻就收到 429 错误?
这很可能是影响最近从免费层升级到 Tier 1 账户的"幽灵 429"Bug。Google 的配额追踪系统可能需要 24 到 48 小时才能将计费状态变更完全传播到所有服务器。临时解决方案是暂时切换到不同的模型变体,或等待传播完成。如果问题持续超过 48 小时,请验证你的计费账户是否处于活跃状态,以及绑定的信用卡是否未被拒绝。
blockReason SAFETY 和 blockReason OTHER 有什么区别?
这代表两种完全不同的过滤系统。blockReason SAFETY 是第一层过滤器,你可以通过 API 请求中的 safety_settings 参数进行配置。你可以通过将阈值设为 BLOCK_NONE 或 OFF 来放宽或禁用这些过滤器。blockReason OTHER 是第二层策略执行过滤器,不可配置、不可放宽、不可通过任何方式绕过。第二层执行版权保护、名人限制和儿童安全规则。当你遇到 blockReason OTHER 时,唯一的解决方案是从根本上修改你的提示词以避免受保护的内容类别。尝试用改写版本"欺骗"系统通常仍会触发第二层过滤器,因为它基于语义理解而非关键词匹配。
如何在生产应用中处理 Gemini 图片错误?
生产环境错误处理最重要的原则是永远不要把所有 429 错误都同等对待。首先检查计费状态(持续出现 429 最常见的原因就是没有启用计费)。对突发速率限制实施带抖动的指数退避,从 2 秒开始翻倍到最多 60 秒。追踪每日消耗量以预测何时会达到 RPD 限制。构建模型降级链(Flash 到 Imagen 4 到 Pro),使单个模型宕机不会导致应用崩溃。始终记录包括 finishReason 和 blockReason 字段在内的完整错误响应,因为这些包含了判断错误是暂时性(重试)还是永久性(重写提示词或更换方案)所需的诊断信息。