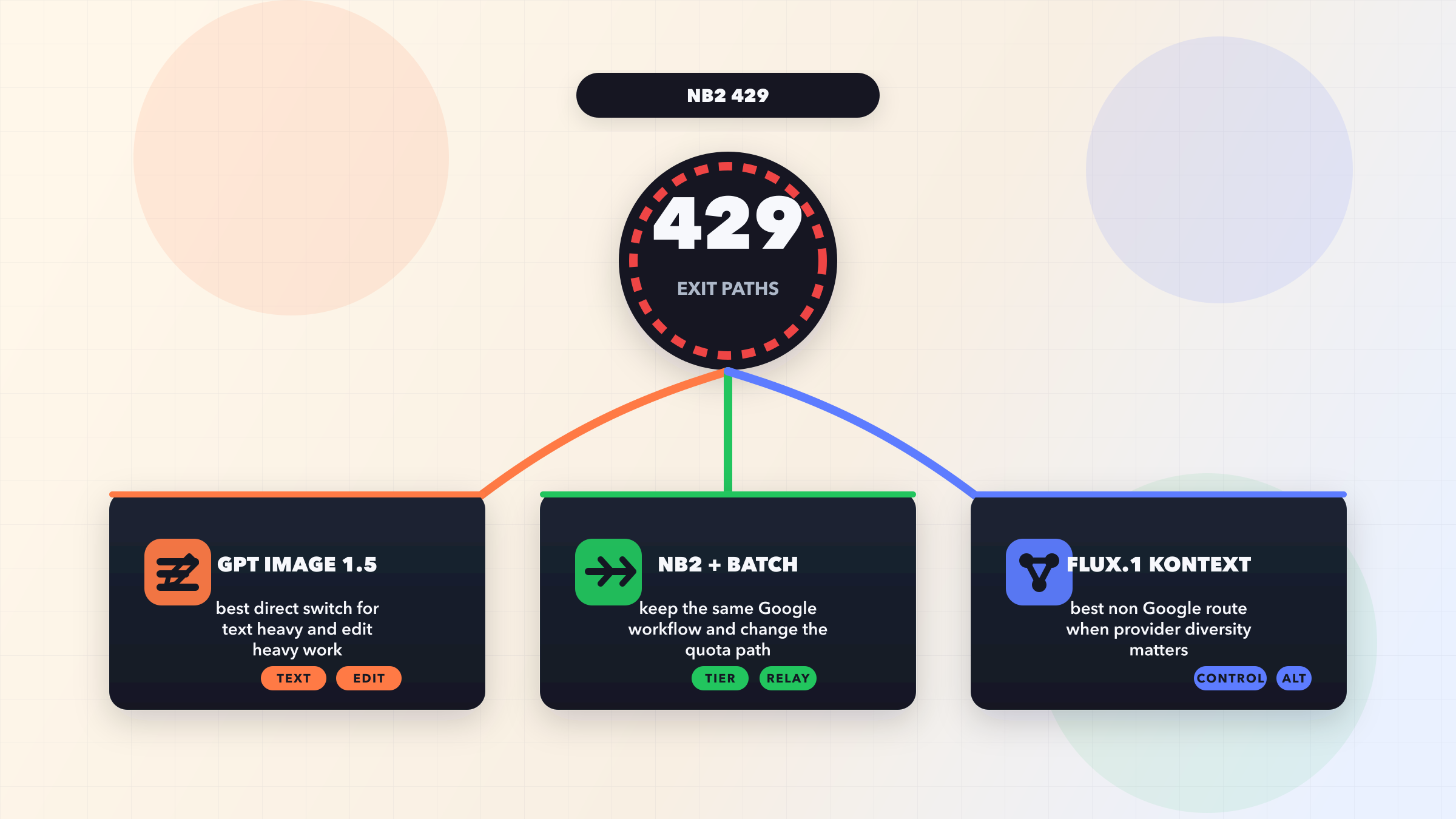
Gemini 图片生成 429 错误发生在你的应用超过 Google 四种速率限制维度之一时:每分钟请求数(RPM)、每日请求数(RPD)、每分钟令牌数(TPM)或常被忽视的每分钟图片数(IPM)。最快的修复方法是实现带抖动的指数退避,它能将 80% 的失败率转变为 99% 以上的成功率(针对突发流量)。但如果你使用的是免费版,必须先启用计费,因为免费版 IPM 在 2025 年 12 月已降至 0,这意味着没有付费账户就无法进行图片生成。升级到 Tier 1 后可立即获得 10 IPM,无最低消费要求。
为什么 Gemini 图片生成会返回 429 错误
每个 API 提供商都会实施速率限制,以保护基础设施免受滥用,并确保所有用户之间的公平资源分配。当你的 Gemini API 请求超过所在计费层级分配的配额时,Google 的服务器会返回 HTTP 状态码 429 和 RESOURCE_EXHAUSTED 错误消息。这不是你代码中的 bug,也不是 Gemini 模型本身的问题——这是 API 网关在执行 Google 为你的项目设定的配额边界。理解这个错误背后的机制,是构建弹性图片生成管线的第一步,让你的管线能够在生产规模的工作负载下不间断运行。
Gemini API 的 429 响应携带了一个许多开发者忽略的特定结构。响应体包含一个 JSON 对象,其中有一个 error 字段,包括状态码 RESOURCE_EXHAUSTED、描述超出了哪个配额的人类可读消息,以及关键的元数据头信息,如 x-ratelimit-limit、x-ratelimit-remaining 和 x-ratelimit-reset,它们会告诉你确切触发了哪个维度的限制以及何时会重置。很多开发者只是简单地捕获 429 然后盲目重试,但解析这些头信息可以让你获得实施针对性修复的情报,而非暴力重试。如果 x-ratelimit-remaining 的 IPM 显示为 0 而 RPM 仍有容量,你就知道瓶颈具体是图片生成吞吐量,而不是一般的请求量。
四种速率限制维度
Google 在四个独立维度上执行速率限制,触发其中任何一个就会产生 429 错误。大多数开发者熟悉 RPM 和 RPD,但 IPM 在 2025 年底随 Gemini 原生图片生成能力一起引入时,让很多团队措手不及。每个维度独立运作——你可能远在 RPM 限制之内,但仍因 IPM 配额耗尽而被限制。下表详细说明了每个维度及其对图片生成工作负载的影响:
| 维度 | 全称 | 度量内容 | 对图片生成的影响 |
|---|---|---|---|
| RPM | Requests Per Minute | 60 秒窗口内的总 API 调用次数 | 影响所有 Gemini 调用,包括文本 |
| RPD | Requests Per Day | 24 小时窗口内的总 API 调用次数(太平洋时间午夜重置) | 限制所有操作的每日总量 |
| TPM | Tokens Per Minute | 每分钟处理的总输入+输出令牌数 | 主要影响文本;图片按固定令牌块计数 |
| IPM | Images Per Minute | 每分钟生成的图片数量 | 隐藏杀手——直接限制图片输出 |
IPM:大多数开发者忽视的隐藏杀手
每分钟图片数是在集成 Gemini 图片生成功能的开发者中引起最多困惑的速率限制维度。与管控所有 API 请求(包括文本补全)的 RPM 不同,IPM 专门计算你的应用在 60 秒滑动窗口内生成的图片数量。一个生成四张图片的 API 调用消耗的是 4 IPM,而不是 1 RPM。这意味着你可能远在 RPM 配额之内,但如果你的请求频繁产生多张图片,就仍然会触及 IPM 上限。问题因免费版在 2025 年 12 月降至 0 IPM 而加剧,这意味着未付费账户上的任何图片生成尝试都会立即返回 429,甚至不会处理请求。许多开发者在调试第一个 429 错误时花费数小时检查代码逻辑,而真正的问题只是他们的计费层级根本不允许任何图片生成。
2026 年 2 月的幽灵 429 Bug
从 2026 年 2 月初开始,多名使用付费 Tier 1 账户的开发者报告收到 429 RESOURCE_EXHAUSTED 错误,尽管他们的用量仪表板显示配额的使用量为零或接近零。这个"幽灵 429" bug 似乎是 Google 配额追踪系统的服务端问题,速率限制器对某些项目配置的用量计算不正确。该 bug 主要影响最近从免费版升级到 Tier 1 的账户,最常在启用计费后的前 24-48 小时内出现。Google 在其开发者论坛中承认了这个问题,并建议切换到不同的模型变体(例如,从 gemini-3.1-flash 切换到 gemini-3-pro)作为临时解决方案,同时其工程团队正在调查。如果你在 Google Cloud Console 配额仪表板中确实显示零用量的情况下遇到 429 错误,这个 bug 是最可能的原因,而非你端的任何配置错误。要更全面地了解 Gemini API 错误码及其解决方案,请参阅我们的 Gemini API 错误排查完整指南。如果你想详细了解完整的速率限制系统,我们的 Gemini API 速率限制完整指南 涵盖了每个层级和维度。
快速诊断——你触发了哪个速率限制?
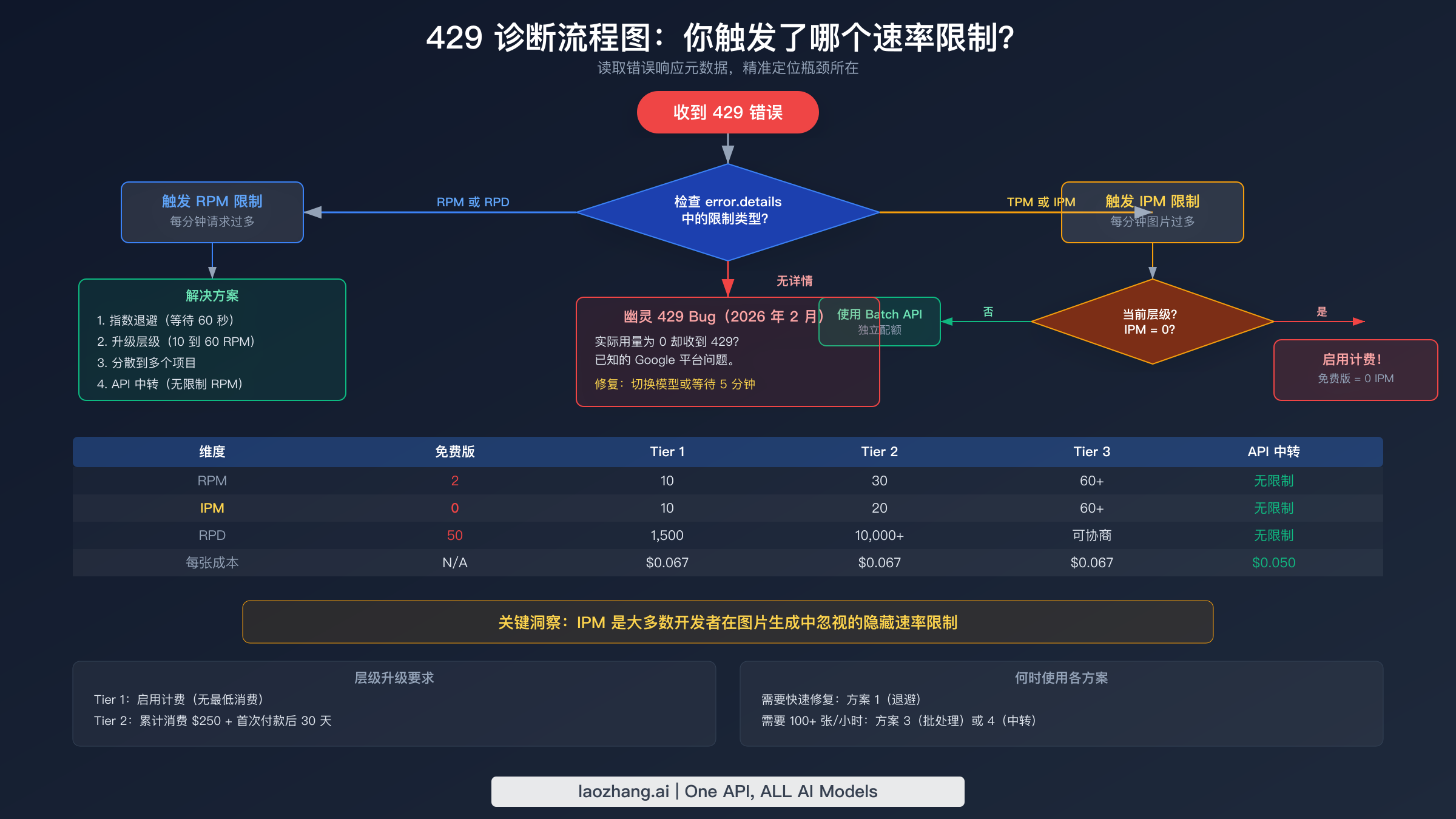
在跳到解决方案之前,你需要确定哪个具体的速率限制维度在阻止你的请求。应用错误的修复方案是在浪费时间——指数退避可以解决 RPM 问题,但对需要层级升级的 IPM 瓶颈毫无作用。诊断过程需要同时检查 API 的错误响应和你一段时间内的使用模式。Google 并不总是在 429 错误体中包含明确的维度信息,所以你通常需要将错误时间与已知的请求模式进行关联来缩小原因范围。好消息是,每种速率限制维度都会产生独特的故障模式,你可以通过系统方法来识别。
读取错误响应元数据
识别你触发了哪个速率限制的最直接方法是解析 429 响应中的响应头和错误体。Google 在响应头中包含了速率限制元数据,尽管具体存在哪些头信息可能因超出的配额不同而有所变化。以下 Python 代码片段演示了如何从失败请求中提取和记录这些诊断信息。这段代码捕获 429 异常,提取所有与速率限制相关的头信息,并打印一个结构化的诊断报告,立即告诉你哪个维度是瓶颈。
pythonimport google.generativeai as genai from google.api_core.exceptions import ResourceExhausted def diagnose_rate_limit(api_key: str, prompt: str): genai.configure(api_key=api_key) model = genai.GenerativeModel("gemini-3.1-flash") try: response = model.generate_content(prompt) return response except ResourceExhausted as e: print(f"429 RESOURCE_EXHAUSTED: {e.message}") # Parse error details for quota dimension if hasattr(e, 'errors') and e.errors: for error in e.errors: metadata = error.get('metadata', {}) print(f" Quota dimension: {metadata.get('quota_dimension', 'unknown')}") print(f" Quota limit: {metadata.get('quota_limit', 'unknown')}") print(f" Quota usage: {metadata.get('quota_usage', 'unknown')}") # Check for ghost 429 pattern if "usage: 0" in str(e) or "quota_usage: 0" in str(e.errors): print(" WARNING: Ghost 429 detected (usage=0).") print(" This matches the known Feb 2026 bug.") print(" Try switching model: gemini-3-pro or imagen-4") raise
三种故障模式
除了解析错误元数据之外,你还可以通过观察故障的时间模式来识别速率限制维度。每个维度都会产生独特的特征,因为 RPM、RPD 和 IPM 在不同的时间窗口上运作。当错误元数据不完整或你在生产环境中只有日志可用时,理解这些模式至关重要。以下是需要关注的三种模式:
第一种模式是"突发后成功"——你的应用发送一连串快速请求,得到若干 429 错误,然后在等待 30-60 秒后成功。这种模式强烈表明违反了 RPM 限制。60 秒滑动窗口持续重置,因此短暂的暂停就能恢复你的配额。第二种模式是"早上正常,晚上失败"——你的应用在一天早期运行正常,但到后来开始持续失败。这表明 RPD 耗尽,因为每日配额已被消耗完毕,要到太平洋时间午夜才会重置。第三种也是最隐蔽的模式是"只有图片失败"——你的文本生成请求完美成功,但每个图片生成请求都返回 429。这是 IPM 耗尽的标志,也是对处于 RPM 限制之内但已耗尽图片专用配额的开发者最常见的陷阱。
如果你在付费账户上看到 429 错误,但 Google Cloud Console 显示你的配额用量为零,你很可能遇到了上文记录的幽灵 429 bug。这与合法的配额耗尽是不同的问题。最近从免费版升级到 Tier 1 的开发者应特别警惕这种模式。要了解更多关于区分合法速率限制和计费层级不匹配的详情,请查看我们关于付费层级账户获得免费版请求限制的指南。
方案 1——带智能重试的指数退避
指数退避是你可以针对 429 错误实施的最具影响力的修复方案,而且不需要任何基础设施变更或计费修改。原理很简单:当你的请求因 429 失败时,在重试前等待指数增长的时间——1 秒、然后 2 秒、然后 4 秒、然后 8 秒,依此类推。这给速率限制器时间来释放容量,并防止你的应用在配额恢复窗口期间疯狂轰炸 API。在实践中,良好实施的指数退避能将峰值负载期间 80% 失败率的应用转变为最终 99% 以上请求都成功的应用,尽管代价是需要多次重试的请求会增加延迟。
为什么抖动很重要:惊群问题
简单的指数退避在你的应用的多个实例部署时有一个严重缺陷。如果十个应用服务器在完全相同的时刻都触发了 429,并且实现了相同的指数退避,它们将在完全相同的时间重试——1 秒后、然后 2 秒后、然后 4 秒后。这种同步的重试行为会产生"惊群效应",在精确的间隔内反复压倒速率限制器,使拥塞变得更糟而不是更好。添加随机抖动——在每个等待时间上添加小的随机变化——可以使你所有实例的重试尝试去同步化。十个服务器不再都在 t+1s 时重试,而是在 t+0.7s、t+1.2s、t+0.9s 等时间重试,将负载平滑地分散在恢复窗口中。这个简单的添加在分布式系统中大幅提高了成功率,被包括 Google、AWS 和 Azure 在内的每个主要云提供商视为最佳实践。
Python 使用 Tenacity 的实现
tenacity 库提供了在 Python 中实现指数退避的最优雅方式。它以简洁的装饰器语法处理了重试逻辑、抖动、最大尝试次数限制和异常过滤的所有复杂性。以下实现是生产就绪的,包含了日志记录、可配置的超时以及对 429 错误与其他不应重试的 API 异常的特定处理。
pythonimport tenacity import google.generativeai as genai from google.api_core.exceptions import ResourceExhausted import logging logger = logging.getLogger(__name__) @tenacity.retry( retry=tenacity.retry_if_exception_type(ResourceExhausted), wait=tenacity.wait_exponential(multiplier=1, min=2, max=60) + tenacity.wait_random(0, 2), # jitter stop=tenacity.stop_after_attempt(8), before_sleep=tenacity.before_sleep_log(logger, logging.WARNING), reraise=True, ) def generate_image_with_retry(model, prompt: str): """Generate image with automatic exponential backoff on 429 errors.""" response = model.generate_content( prompt, generation_config=genai.GenerationConfig( response_modalities=["image", "text"], ), ) return response genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash") try: result = generate_image_with_retry(model, "A futuristic cityscape at sunset") # Process result.candidates[0].content.parts for image data except ResourceExhausted: logger.error("All retries exhausted. Consider upgrading tier.")
Node.js 使用 p-retry 的实现
对于 Node.js 应用,p-retry 包提供了等效的功能,其基于 Promise 的 API 与 async/await 模式完美集成。以下实现与 Python 版本的行为一致,包含相同的生产级安全措施——抖动、最大尝试次数、日志记录以及适当的错误分类,以避免重试认证失败或无效提示等不可重试的错误。
javascriptconst pRetry = require('p-retry'); const { GoogleGenerativeAI } = require('@google/generative-ai'); const genAI = new GoogleGenerativeAI('YOUR_API_KEY'); async function generateImageWithRetry(prompt) { const model = genAI.getGenerativeModel({ model: 'gemini-3.1-flash' }); return pRetry( async (attemptNumber) => { console.log(`Attempt ${attemptNumber} for image generation...`); const result = await model.generateContent({ contents: [{ role: 'user', parts: [{ text: prompt }] }], generationConfig: { responseModalities: ['image', 'text'] }, }); return result.response; }, { retries: 7, minTimeout: 2000, // 2 seconds initial wait maxTimeout: 60000, // 60 seconds maximum wait factor: 2, // exponential factor randomize: true, // adds jitter automatically onFailedAttempt: (error) => { if (error.status !== 429) { throw error; // don't retry non-429 errors } console.warn( `Rate limited. Attempt ${error.attemptNumber} failed. ` + `${error.retriesLeft} retries remaining.` ); }, } ); }
指数退避的生产建议:将最大重试次数设置在 6 到 10 次之间。以 2 秒为基数、2 倍因子计算,8 次尝试覆盖约 8.5 分钟的总等待窗口,对于 RPM 限制重置来说绰绰有余。始终在整个操作上设置绝对超时(不仅仅是单次重试),以防止请求无限挂起。记录每次重试的尝试次数和等待时间,这样你就可以在生产仪表板中监控 429 频率,并知道何时应该升级层级而不是仅依赖重试。
方案 2——升级计费层级
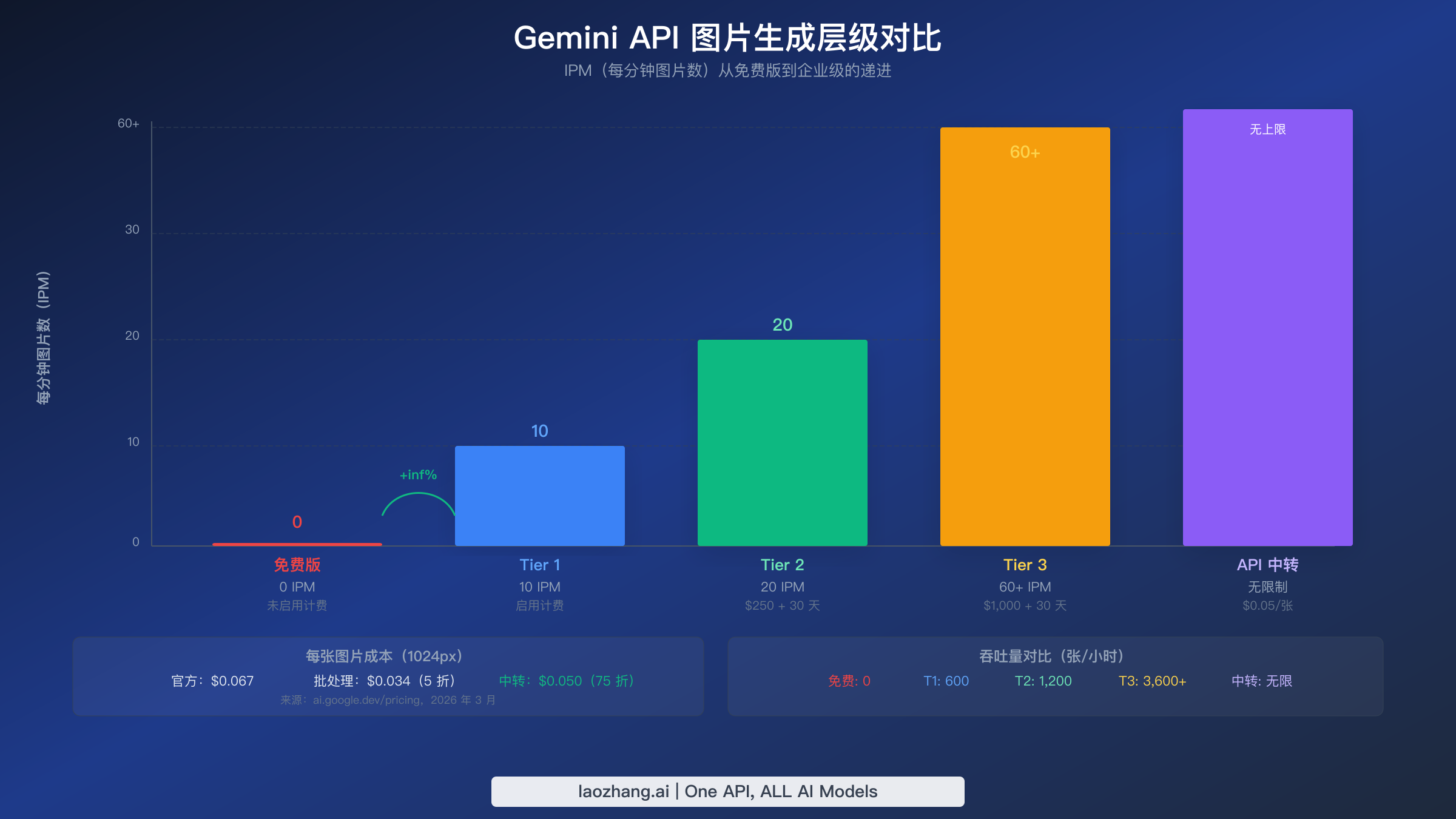
虽然指数退避可以处理瞬时的速率限制尖峰,但对于持续的 429 错误,最可靠的长期解决方案是升级你的 Google Cloud 计费层级。每次层级提升都会在所有四个速率限制维度上成倍增加你的配额,对于图片生成来说,IPM 的增加是最具影响力的变化。很多开发者没有意识到免费版实际上完全禁用了图片生成——IPM 配额在 2025 年 12 月降至 0。只需在你的 Google Cloud 项目上启用计费,就会立即升级到 Tier 1,解锁 10 IPM,无最低消费要求。这一步操作就能解决开发者在初始集成和测试期间遇到的大多数 429 错误。
图片生成的层级对比
了解每个层级的具体配额对于为你的工作负载选择合适的级别至关重要。下表展示了直接影响所有可用层级图片生成的速率限制。请注意,Tier 3 的限制可以通过 Google Cloud 销售团队协商,因此显示的数字代表的是标准基线而非硬性上限。
| 层级 | 月度消费要求 | 时间要求 | RPM | RPD | IPM | Batch TPD | 每张图片成本(1K) |
|---|---|---|---|---|---|---|---|
| 免费版 | 无 | 无 | 2 | 50 | 0 | N/A | N/A(被阻止) |
| Tier 1 | 启用计费(无最低消费) | 即时 | 10 | 1,500 | 10 | 1M tokens | $0.067 |
| Tier 2 | 累计消费 $250 | 在 Tier 1 上 30 天 | 30 | 10,000+ | 20 | 250M tokens | $0.067 |
| Tier 3 | 累计消费 $1,000 | 在 Tier 2 上 30 天 | 60+ | 可协商 | 60+ | 750M tokens | $0.067 |
从免费版到 Tier 1 的跳跃是最具影响力的升级,因为它从 0 IPM(完全无法生成图片)过渡到 10 IPM,足以满足开发、测试和低流量生产应用的需求。每分钟 10 张图片意味着每小时 600 张,如果持续运行则每天约 14,400 张,对于大多数中小型应用来说已经绰绰有余。从 Tier 1 到 Tier 2 的升级将你的 IPM 翻倍至 20,并大幅增加你的 RPD 从 1,500 到超过 10,000,这对于全天生成图片而非突发式的应用很重要。
如何检查和升级你的当前层级
检查当前计费层级需要导航到 Google Cloud Console 并查看项目的计费状态。进入 Google Cloud Console,选择你的项目,导航到"结算",然后查看 Generative Language API 部分下的"配额与系统限制"页面。你的当前层级会显示在每个配额指标旁边。如果你看到 IPM 列为 0,则无论计费页面显示什么,你都在免费版上——这是一个常见的混淆来源,因为在项目上关联了计费账户并不意味着 Generative AI API 已自动启用计费。你需要验证计费账户已关联到项目,且 Generative Language API 在 API 仪表板中已启用计费。对于遇到付费账户持续显示免费版限制的开发者,请参阅我们的 Gemini 图片生成免费版限制专题指南,其中详细介绍了每个验证步骤。
层级升级时间线:启用计费后 Tier 1 立即激活。Tier 2 需要累计消费 $250 和 30 天的 Tier 1 活跃使用——你不能通过一天内花费 $250 来加速。Tier 3 同样需要累计消费 $1,000 和在 Tier 2 上 30 天。请提前规划你的层级升级路径,因为这些时间门槛无法通过 Google Cloud 支持工单绕过。
方案 3——使用 Batch API 进行大批量生成
Gemini Batch API 是需要生成大量图片但不要求实时响应的开发者未充分利用的解决方案。Batch API 的关键优势在于它在一个完全独立的配额池中运作,与实时 API 分开,这意味着批量图片生成请求不会计入你的 RPM、RPD 或 IPM 限制。这种分离使 Batch API 成为你实时管线的有力补充——你可以将非紧急的图片生成卸载到批处理,同时保留你的实时配额给面向用户的交互式请求。此外,Google 对所有批处理 API 请求提供 50% 的费用折扣,使其在高容量工作负载中比实时生成便宜得多。
批处理的工作原理
Batch API 遵循异步的基于作业的模型。你将一批提示作为单个作业提交,Google 将它们排队处理,你轮询结果直到作业完成。服务级别协议保证在 24 小时内完成,尽管实际上大多数批处理作业在 2-6 小时内完成,具体取决于数量和当前系统负载。每个批处理作业最多可包含 100 个请求,你可以并发提交多个批处理作业。独立的配额池意味着一个只有 10 IPM 实时请求配额的 Tier 1 账户可以通过 Batch API 处理数千张图片,仅受批处理专用令牌分配的限制:Tier 1 每天 100 万令牌,Tier 2 为 2.5 亿,Tier 3 为 7.5 亿。由于典型的图片生成请求消耗约 1,000-2,000 个令牌,即使 Tier 1 的批处理分配也支持每天通过批处理管线生成 500-1,000 张图片。
Python 实现:批量图片生成
以下代码演示了如何创建批量图片生成作业,将其提交到 Gemini Batch API,并轮询结果。这种模式适合电商产品图片批量生成、社交媒体素材批量创建或 A/B 测试图片变体预处理等工作流。批处理作业在内部处理重试,因此你不需要为批量提交实现指数退避。
pythonimport google.generativeai as genai import time import json genai.configure(api_key="YOUR_API_KEY") def batch_generate_images(prompts: list[str], model_name="gemini-3.1-flash"): """Submit a batch of image generation prompts and wait for results.""" # Prepare batch request batch_requests = [] for i, prompt in enumerate(prompts): batch_requests.append({ "custom_id": f"image-{i}", "request": { "model": model_name, "contents": [{"role": "user", "parts": [{"text": prompt}]}], "generation_config": { "response_modalities": ["image", "text"], }, }, }) # Submit batch job batch_job = genai.create_batch( requests=batch_requests, display_name=f"image-batch-{int(time.time())}", ) print(f"Batch job created: {batch_job.name}") print(f"Status: {batch_job.state}") # Poll for completion (24h SLA, typically 2-6h) while batch_job.state in ("QUEUED", "PROCESSING"): time.sleep(30) # Check every 30 seconds batch_job = genai.get_batch(batch_job.name) completed = sum(1 for r in batch_job.results if r.state == "COMPLETED") print(f" Progress: {completed}/{len(prompts)} completed") # Collect results results = {} for result in batch_job.results: if result.state == "COMPLETED": results[result.custom_id] = result.response else: print(f" Failed: {result.custom_id} - {result.error}") return results # Example usage prompts = [ "A modern office workspace with natural lighting", "A coffee shop interior with warm ambiance", "A serene garden with Japanese maples", # ... up to 100 prompts per batch ] results = batch_generate_images(prompts) print(f"Successfully generated {len(results)} images")
成本节省和层级分配
50% 的批处理折扣适用于所有图片尺寸,使每张图片的成本显著低于实时生成。在 1K 分辨率下,每张图片的成本从 $0.067 降至约 $0.034。对于每天生成数百或数千张图片的团队,仅这个折扣就可以证明投入批处理基础设施的合理性。各层级的批处理专用令牌分配也值得关注,因为它们独立于你的实时配额,决定了最大批处理吞吐量。
| 层级 | 批处理令牌分配(每日) | 大约图片容量 | 每张图片成本(1K,含 50% 折扣) |
|---|---|---|---|
| Tier 1 | 1M tokens | ~500-1,000 张 | $0.034 |
| Tier 2 | 250M tokens | ~125,000-250,000 张 | $0.034 |
| Tier 3 | 750M tokens | ~375,000-750,000 张 | $0.034 |
从 Tier 1 到 Tier 2 的批处理分配跳跃幅度巨大(从 1M 到 250M 令牌),使得 Tier 2 升级对批处理密集型工作负载特别有价值。如果你的应用可以容忍批处理的异步特性来处理相当比例的图片生成需求,将实时 API 调用用于交互式请求与批处理用于后台任务相结合,就能两全其美。更多关于批处理成本优化策略,请参阅我们的批处理 API 成本优化指南。
方案 4——使用 API 中转实现无限吞吐量
当你的应用需要超过 Tier 3 限制的吞吐量,或者你想避免管理 Google Cloud 计费层级和配额监控的复杂性时,API 中转服务提供了一种从根本上不同的方法来解决速率限制问题。API 中转在单个统一端点后面聚合了多个 API 密钥和 Google Cloud 项目,将你的请求分散到这个池中,从而有效消除了单个项目的速率限制。从你的应用角度来看,你用单个端点和单个密钥进行 API 调用,中转在幕后处理负载均衡、配额追踪和自动故障转移。这种方法对于需要生产级吞吐量但又不想承担管理多个 Google Cloud 项目和计费账户运维开销的初创公司和中型企业尤其有价值。
API 中转如何解决速率限制
API 中转背后的核心洞察是 Google 的速率限制是按项目执行的,而不是按用户或按组织。中转服务维护一个包含 N 个项目的池,每个项目都有自己独立的配额分配。当你的请求到达时,中转将其路由到有可用配额的项目,有效地将你的总吞吐量乘以池中项目的数量。如果每个项目有 10 IPM,池中有 20 个项目,你的有效限制就变成了 200 IPM——远超任何单个 Tier 3 账户所能提供的。中转还实时监控所有项目的配额使用情况,实施智能路由以避免将请求发送到接近限制的项目。这种分布式架构使得 429 错误在正常操作条件下几乎不可能发生,因为中转始终有备用容量可用。
所需的代码改动最小
从直接 Gemini API 访问切换到中转端点在大多数实现中只需要更改三行代码。支持 OpenAI 兼容接口的 API 中转允许你使用标准的 OpenAI SDK,这是很多开发者已经熟悉的。以下示例展示了 Python 和 Node.js 的前后对比:
python# Before: Direct Gemini API import google.generativeai as genai genai.configure(api_key="YOUR_GOOGLE_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash") # After: Through API proxy (OpenAI-compatible) from openai import OpenAI client = OpenAI( api_key="YOUR_PROXY_KEY", base_url="https://api.laozhang.ai/v1" # proxy endpoint ) response = client.chat.completions.create( model="gemini-3.1-flash", messages=[{"role": "user", "content": "Generate an image of a sunset"}], )
中转方式除了原始吞吐量之外还提供了几个优势。首先,你可以获得统一定价模式——laozhang.ai 无论分辨率如何都收取每张图片 $0.05,相比 Google 的分层定价 $0.045(512px)、$0.067(1K)、$0.101(2K)或 $0.151(4K)。对于以 2K 或 4K 分辨率生成图片的应用,中转实际上比直接 API 访问更便宜。其次,中转在内部处理所有重试逻辑、配额管理和错误处理,降低了你应用代码的复杂性。第三,你可以避免层级升级所需的 30 天时间门槛——中转从第一天起就提供高吞吐量。
何时使用 API 中转:需要超过 60 IPM 的实时应用、想要避免管理 Google Cloud 计费复杂性的团队、生成高分辨率图片时统一定价更便宜的应用,以及需要快速扩展而不等待层级升级资格期的项目。
方案 5——多模型降级策略
Gemini API 提供多个能够生成图片的模型,每个模型变体维护自己独立的速率限制。这个架构细节创造了一个强大的降级策略机会:当一个模型触发速率限制时,你的应用自动切换到仍有可用配额的替代模型。这种方法无需层级升级、额外的计费账户或外部中转服务就能倍增你的有效吞吐量。代价是不同模型可能产生略有不同的图片质量和风格,因此这种策略最适合不需要所有生成图片保持一致性的应用。
构建降级链
2026 年初最有效的图片生成降级链按优先级使用三个模型:gemini-3.1-flash-image 作为主要模型(最快、最便宜),gemini-3-pro-image 作为次要模型(质量更高、略慢),imagen-4 作为第三备选(专用图片模型、不同风格)。每个模型都有自己的 RPM、IPM 和 RPD 配额,由 Google 的速率限制器独立追踪。如果你主要模型的 IPM 耗尽,次要模型的 IPM 池很可能未被使用,因为它还没有收到任何请求。这使你在 Tier 1 上的有效 IPM 达到 30(每个模型 10,3 个模型),而不是使用单个模型时的 10 IPM。
以下 Python 实现创建了一个 ModelFallbackClient 类,当遇到 429 错误时自动在模型之间轮换。它将方案 1 的指数退避与模型轮换相结合,提供两层弹性。客户端追踪哪些模型当前受限及其预估恢复时间,避免向已知被限制的模型发送无用请求。
pythonimport google.generativeai as genai from google.api_core.exceptions import ResourceExhausted import time import logging logger = logging.getLogger(__name__) class ModelFallbackClient: """Image generation client with automatic model fallback on 429 errors.""" FALLBACK_CHAIN = [ "gemini-3.1-flash", # Primary: fast, cheap "gemini-3-pro", # Secondary: higher quality "imagen-4", # Tertiary: specialized image model ] def __init__(self, api_key: str): genai.configure(api_key=api_key) self.models = { name: genai.GenerativeModel(name) for name in self.FALLBACK_CHAIN } self.cooldowns = {} # model_name -> earliest_retry_time def generate_image(self, prompt: str, max_retries: int = 3): """Generate image, falling back through model chain on 429 errors.""" for model_name in self.FALLBACK_CHAIN: # Skip models in cooldown if model_name in self.cooldowns: if time.time() < self.cooldowns[model_name]: logger.info(f"Skipping {model_name} (cooldown)") continue else: del self.cooldowns[model_name] for attempt in range(max_retries): try: logger.info(f"Trying {model_name} (attempt {attempt + 1})") response = self.models[model_name].generate_content( prompt, generation_config=genai.GenerationConfig( response_modalities=["image", "text"], ), ) return {"model": model_name, "response": response} except ResourceExhausted: wait = (2 ** attempt) + (time.time() % 1) # backoff + jitter logger.warning( f"{model_name} rate limited. " f"Waiting {wait:.1f}s before retry." ) time.sleep(wait) # All retries exhausted for this model — add cooldown and try next self.cooldowns[model_name] = time.time() + 60 logger.warning(f"{model_name} exhausted. Moving to next model.") raise ResourceExhausted("All models in fallback chain exhausted.") # Usage client = ModelFallbackClient("YOUR_API_KEY") result = client.generate_image("A photorealistic mountain landscape at dawn") print(f"Generated by: {result['model']}")
权衡与注意事项
多模型降级策略并非没有局限性,理解这些权衡对于决定它是否适合你的使用场景至关重要。最显著的权衡是视觉一致性——gemini-3.1-flash 和 gemini-3-pro 使用不同的底层架构和训练数据,这意味着相同的提示在不同模型间可能产生明显不同的结果。对于社交媒体内容生成等每张图片独立存在的应用,这种不一致性无关紧要。对于产品目录生成等所有图片需要保持视觉一致性的应用,降级到不同模型可能产生与已建立的视觉风格冲突的结果。另一个考量是 imagen-4 使用与 Gemini 模型不同的 API 契约——它是专用的图片生成模型而非多模态 LLM,因此提示可能需要轻微调整才能产生最佳结果。上面的降级客户端透明地处理了这一点,但你应该在部署到生产之前在所有三个模型上测试你的具体提示,以了解质量差异。
应该选择哪种方案?
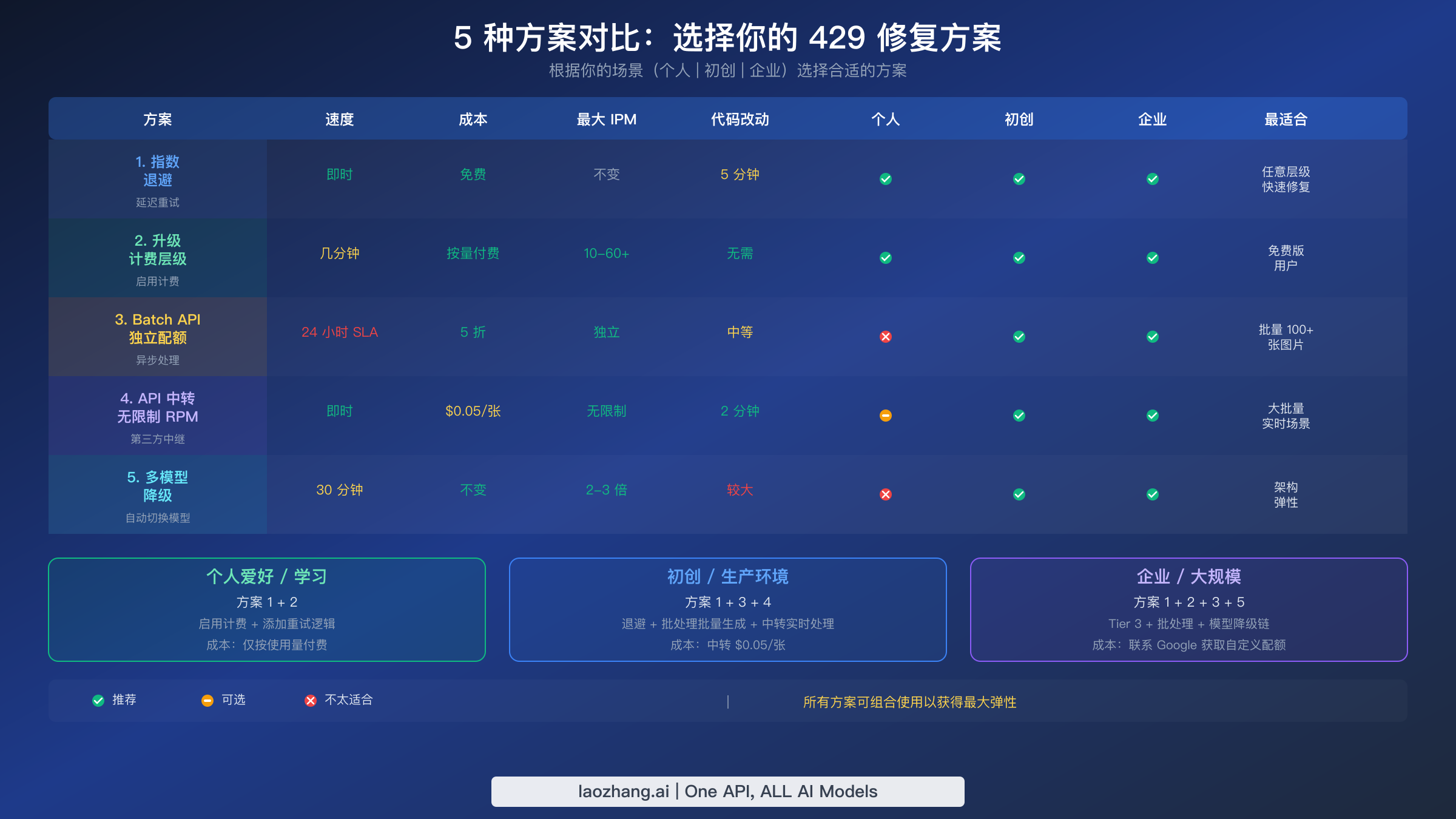
选择正确的方案组合取决于你的应用对吞吐量、延迟、成本和运维复杂性的具体要求。没有一种方案是普遍最优的——偶尔生成图片的个人项目与服务数百万用户的企业平台需要根本不同的方法。下表将三种常见的开发者画像映射到推荐的方案组合,以及每个推荐的理由。在实践中,大多数生产应用最终会组合两到三种方案以获得最大弹性,指数退避作为通用基础,无论规模大小每种实现都应该包含。
| 画像 | 推荐方案 | 月度图片量 | 预估成本 | 理由 |
|---|---|---|---|---|
| 个人爱好/副项目 | 方案 1(退避)+ 方案 2(Tier 1) | < 10,000 | < $10 | Tier 1 解锁 10 IPM,退避处理突发 |
| 初创/成长型应用 | 方案 1 + 方案 3(批处理)+ 方案 4(中转) | 10,000 - 500,000 | $50 - $500 | 批处理用于大量生成,中转用于实时溢出 |
| 企业/大规模 | 方案 1 + 方案 2(Tier 3)+ 方案 3 + 方案 5(降级) | 500,000+ | $500+ | 多层弹性,专用配额 |
对于大多数首次遇到 429 错误的开发者,行动计划很清晰:立即实现指数退避(方案 1,需要 15 分钟),然后启用计费升级到 Tier 1(方案 2,在 GCP Console 中需要 5 分钟)。仅这两个改变就能解决每分钟生成少于 10 张图片的应用 95% 的 429 错误。如果你的需求超出此范围,可以为非紧急生成添加 Batch API,并考虑为超出层级限制的实时工作负载使用 API 中转。
429 速率限制会持续多久? 持续时间取决于你触发的维度。RPM 限制在 60 秒滑动窗口上重置,所以只需等待一分钟就能恢复你的完整每分钟配额。RPD 限制在太平洋时间午夜重置,这意味着下午触发每日限制需要等待数小时。IPM 限制遵循与 RPM 相同的 60 秒窗口。幽灵 429 bug 没有可预测的持续时间——一些开发者报告在几小时内解决,而其他人需要切换模型或重新创建 API 密钥来绕过它。
我能获得超过 60 IPM 吗? 可以。Tier 3 限制列为"60+"是因为它们可以协商。如果你通过 GCP Console 联系 Google Cloud 销售团队并能证明合理的业务需求,Google 将提供可达数百或数千 IPM 的自定义配额分配。使用承诺使用合同的企业账户通常会在其整体 Google Cloud 协议中协商自定义限制,并获得随承诺量增长的价格折扣。
使用 API 中转安全吗? 信誉良好的 API 中转作为透明的转发层运作——它们接收你的请求,通过其管理的凭据之一将其路由到 Google 的 API,然后将响应返回给你。中转不会在完成请求所需的时间之外存储你的提示、生成的图片或 API 响应。也就是说,你需要信任中转运营商处理你的请求内容,因此请选择有明确隐私政策和开发者社区口碑的成熟服务。安全模型与使用任何第三方 SaaS API 类似——你应该在发送敏感提示之前评估提供商的声誉和数据处理实践。
为什么我在 0 用量时也收到 429? 这几乎可以确定是 2026 年 2 月的幽灵 429 bug,它影响最近升级的 Tier 1 账户。即时的解决方法是切换你的模型变体——如果你使用的是 gemini-3.1-flash,试试 gemini-3-pro,反之亦然。一些开发者也通过在同一项目中创建新的 API 密钥来解决了这个问题,尽管这并不一致有效。Google 已承认该问题并正在开发永久修复。如果问题在层级升级后 48 小时以上仍然持续,请通过 Google Cloud Console 开立支持工单,提供你的项目 ID 和具体的错误响应体,包括头信息中的任何配额元数据。