Gemini 图像 API 错误分为三类:429 速率限制(由计费限额为零、超出 IPM、Ghost Bug 或动态共享配额引起)、静默生成失败(错误的端点、responseModalities 配置错误或未启用计费),以及参数问题(imageConfig 被忽略、image_size 大小写敏感、responseModalities 中缺少 TEXT)。首先检查 GCP Console 配额面板,然后验证是否已启用计费——自 2025 年 12 月 7 日起,免费套餐的 IPM 已降为 0。请使用正确的 /v1beta/ 端点,并将 responseModalities 设为 ["TEXT", "IMAGE"]。
要点速览
三类错误,三条诊断路径。429 错误有四个不同的根本原因,每种原因都需要不同的修复方法——不要在未确定类型的情况下盲目"等待并重试"。静默失败(HTTP 200 但响应中无图像)几乎总是 responseModalities 配置错误导致的。参数失败(设置被接受但被忽略)通常涉及 image_size 的大小写问题,或 imageConfig 被中间件层剥离。按以下顺序检查:先查计费,再查端点,最后查参数。
理解 Gemini 图像 API 错误:诊断地图
当 Gemini 图像生成出现问题时,开发者通常会遇到三种截然不同的故障模式,每种模式需要完全不同的诊断方法。第一种是硬错误——API 调用返回 HTTP 429 或 HTTP 400,请求在任何生成开始之前就被拒绝了。第二种是静默失败,调用以 HTTP 200 成功完成,但响应中不包含任何图像数据。第三种是配置失败,图像成功生成,但输出与你的配置不符——分辨率错误、宽高比错误,或与指定设置完全不同的参数。
判断自己处于哪种故障模式是关键的第一步。错误识别会导致开发者走上错误的诊断路径,浪费数小时时间。下表将每种错误类型映射到其 HTTP 状态码、gRPC 状态码,以及本指南中对应的章节。
| 错误类型 | HTTP 状态 | gRPC 状态 | 典型症状 | 修复章节 |
|---|---|---|---|---|
| 计费限额 = 0 | 429 | RESOURCE_EXHAUSTED | 免费套餐,无法生成图像 | 第2章 |
| 超出 IPM 速率限制 | 429 | RESOURCE_EXHAUSTED | 生成一段时间后失败 | 第2章 |
| Ghost 429 Bug | 429 | RESOURCE_EXHAUSTED | 升级计费后仍出现 | 第2章 |
| 动态共享配额 | 429 | RESOURCE_EXHAUSTED | 预览模型流量拥塞 | 第2章 |
| responseModalities 错误 | 200 | — | parts[] 数组为空 | 第3章 |
| 错误的 API 端点 | 404/400 | NOT_FOUND | 不支持的操作 | 第3章 |
| 错误的模型名称 | 400 | INVALID_ARGUMENT | 找不到模型 | 第3章 |
| 未启用计费 | 400 | FAILED_PRECONDITION | 明确的错误信息 | 第3章 |
| image_size 大小写错误 | 200 | — | 输出分辨率错误 | 第4章 |
| imageConfig 被剥离 | 200 | — | 配置被静默忽略 | 第4章 |
| 缺少 TEXT 模态 | 200 | — | 响应为空 | 第4章 |
对于非图像特定的一般 Gemini API 错误,我们的Gemini API 错误排查通用指南涵盖了全范围的非图像错误。本文专注于图像生成特有的三类错误——通用 Gemini API 指南未涉及的问题。图像 API 有其独立的配额维度(IPM——每分钟图像数)、独立的必需参数,以及不适用于文本生成的独立模型端点。
最重要的诊断原则是:永远不要假设 429 错误只是需要等待的"速率限制"。四种完全不同的根本原因会产生相同的 429 响应,而等待只对其中一种情况是正确的应对措施。同样,永远不要假设 HTTP 200 响应意味着图像已成功生成——200 可能掩盖了一个产生空响应的配置错误。
429 错误:四个根本原因,四种不同修复方法
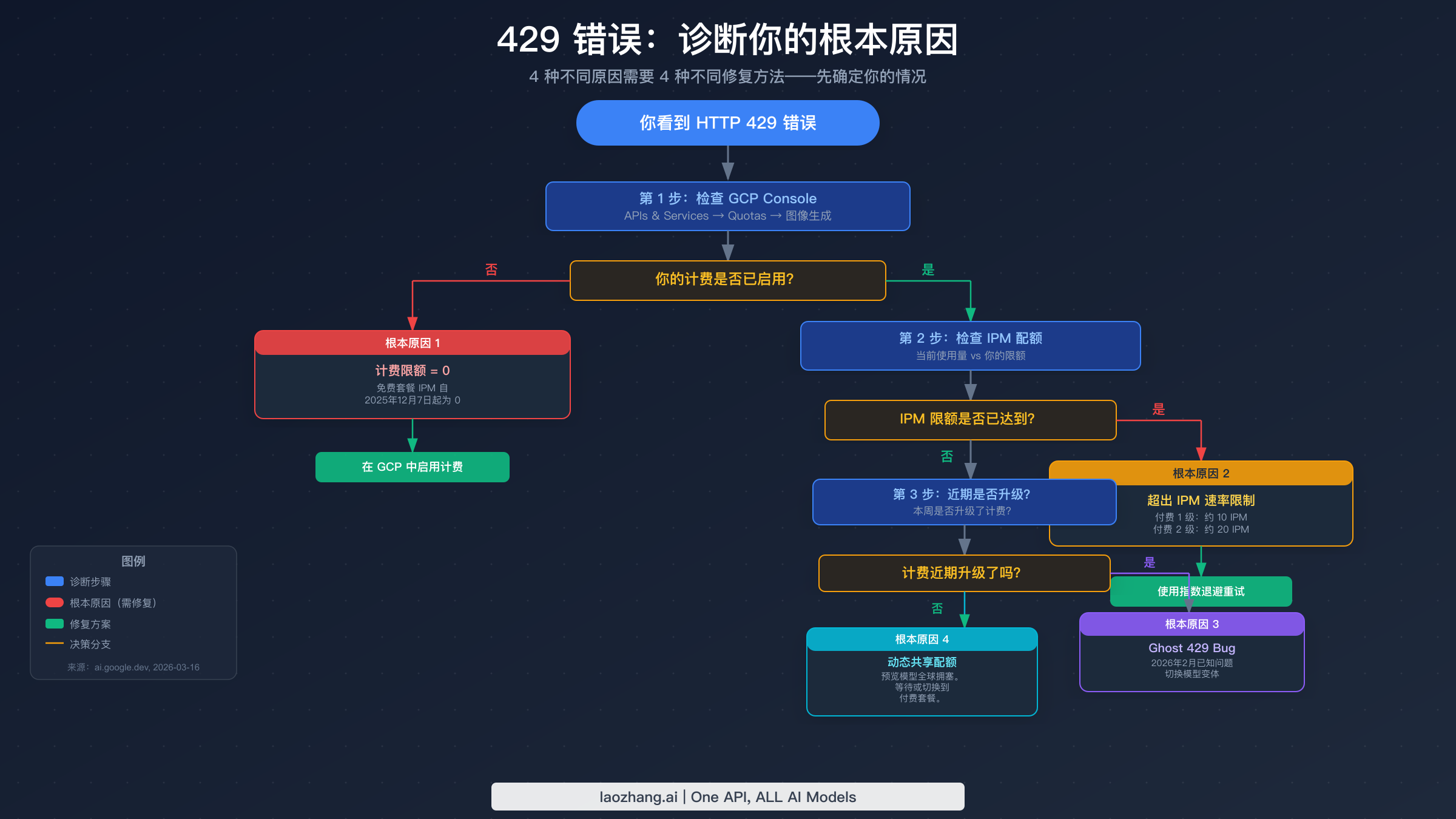
429 RESOURCE_EXHAUSTED 错误是最常见的 Gemini 图像 API 错误,但它具有误导性,因为无论是哪种完全不同的问题触发了它,错误信息看起来都完全相同。每个 Gemini 图像开发者都会遇到它,而几乎所有网上的资料都将其视为单一问题——"你超出了速率限制"。这种定性会浪费时间,因为四个根本原因有四种完全不同的修复方法,使用错误的修复方法毫无帮助。
根本原因 1:计费限额 = 0(免费套餐)
对新开发者来说,429 最常见的原因也是最简单的:自 2025 年 12 月 7 日起,免费套餐的每张图像配额(IPM)精确为零(已对照 Firebase AI Logic 文档验证,2026-03-16)。这意味着免费套餐账户无法通过 API 生成任何图像——不是限制很低,而是完全为零。当你遇到这个问题时,429 不会告诉你"你超出了限制",而是表示你的限制本身就已经是零了。
要验证是否属于这种情况,请导航至 GCP Console → APIs & Services → Generative Language API → Quotas and Limits。过滤"image"并查看 IPM(每分钟图像数)配额。如果显示为 0,则属于根本原因 1。修复方法是在 Google Cloud 项目中启用计费并升级到至少付费套餐 1 级。请注意,仅启用计费并不总是能立即恢复配额——可能存在 15-30 分钟的传播延迟。
根本原因 2:超出 IPM 速率限制(付费套餐)
一旦启用计费,你就有了每分钟图像生成配额。根据我们Gemini 图像 429 速率限制详细指南中的验证数据,付费套餐 1 级支持约 10 IPM(每分钟图像数),付费套餐 2 级约 20 IPM。这与 RPM(每分钟请求数)是独立的——图像模型有其专属的 IPM 配额,专门适用于图像生成调用。
根本原因 2 的诊断特征是模式:你的应用最初运行正常,然后在快速连续生成多张图像后开始出现 429 错误。GCP Console 配额面板将显示当前使用量接近或达到 IPM 限制。修复方法是指数退避——第一次 429 后等待 2 秒,每次重试后翻倍(2 秒、4 秒、8 秒、16 秒)。批量处理作业应提前计算保持在 IPM 限制内所需的延迟,而不是被动地在达到限制后才退避。
根本原因 3:Ghost 429 Bug(2026 年 2 月)
这个 Bug 影响最近升级了计费套餐的账户。症状是即使在成功升级计费后,429 错误仍持续出现——GCP Console 显示非零的 IPM 配额,计费已启用,但图像生成仍返回 429。Google 在 2026 年 2 月的 AI Developers Forum 中确认这是一个已知问题。该 Bug 影响账户级配额执行层,新的配额分配未能正确传播。
临时解决方法是切换到不同的模型变体。如果你正在使用 gemini-3.1-flash-image-preview,请尝试切换到 gemini-2.5-flash-image,反之亦然。在许多情况下,这可以绕过受影响的配额执行路径。此外,等待 24-48 小时通常也能解决问题,因为配额传播会自动完成。如果 Bug 持续存在,向 Google Cloud 提交支持工单并明确引用 2026 年 2 月的 Ghost 429 问题,可以加快解决速度。
对于看起来类似的 503 过载错误,请参阅我们关于修复 503 过载错误的指南。
根本原因 4:动态共享配额(预览模型)
预览模型——gemini-3.1-flash-image-preview 和 gemini-3-pro-image-preview——不像生产模型那样使用按项目分配的配额。相反,它们使用 Google 所称的"动态共享配额",即可用容量在全球所有预览模型用户之间共享,当全球系统拥塞程度较高时,无论你个人的使用量如何,都会出现 429 错误。Google 在 2026 年 1 月 29 日的 support.google.com 支持线程中确认了这一行为。
这是唯一一个等待确实是正确响应的根本原因。429 不是因为你做错了什么——而是因为全球预览模型容量暂时受限。使用更长延迟的指数退避(从 5 秒而非 2 秒开始)在这里是有效的。对于有可靠性要求的生产应用,正确的架构响应是使用像 gemini-2.5-flash-image 这样的生产模型,或使用具有预置吞吐量的 Vertex AI,后者提供专用容量而非共享容量。
以下是一个完整的指数退避实现,可以帮助识别你遇到的 429 类型:
pythonimport time import google.generativeai as genai def generate_image_with_backoff(prompt: str, max_retries: int = 5) -> dict: """Generate image with exponential backoff for 429 errors.""" client = genai.GenerativeModel("gemini-3.1-flash-image-preview") for attempt in range(max_retries): try: response = client.generate_content( contents=prompt, generation_config={ "responseModalities": ["TEXT", "IMAGE"], } ) return response except Exception as e: error_str = str(e) if "429" not in error_str and "RESOURCE_EXHAUSTED" not in error_str: raise # Not a rate limit error if attempt == max_retries - 1: raise # Exhausted retries # Exponential backoff: 2s, 4s, 8s, 16s, 32s delay = 2 ** (attempt + 1) print(f"429 on attempt {attempt + 1}, waiting {delay}s...") time.sleep(delay) raise Exception("Max retries exceeded")
图像生成返回空结果:修复静默失败
静默失败是最令人沮丧的 Gemini 图像错误类型,因为它不给你任何可操作的反馈。你的 API 调用返回 HTTP 200(成功),响应是有效的 JSON,但当你查找图像数据时,parts 数组为空或只包含文本。不会抛出异常,没有错误信息解释出了什么问题。这类失败有四个不同的原因,每种原因都需要不同的排查方式。
最常见原因:responseModalities 配置错误
最频繁出现的静默失败来自配置中缺少一个词。Gemini Image API 要求 responseModalities 同时包含 "TEXT" 和 "IMAGE"——仅包含 ["IMAGE"] 会导致 HTTP 200 成功响应,但 parts 数组为空。不会抛出错误。API 接受请求,处理它,然后什么也不返回,并且不告诉你原因。
这一要求在 Gemini 官方图像生成文档(ai.google.dev/gemini-api/docs/image-generation,已于 2026-03-16 验证)中有说明,但许多开发者因为非官方来源的示例只显示 ["IMAGE"],或者认为指定 "IMAGE" 模态就足够了(因为那是他们想要的),而遇到了这个问题。正确的配置如下:
pythongeneration_config = { "responseModalities": ["TEXT", "IMAGE"], # 两者都必须 "imageConfig": { "image_size": "1K" # 注意:大写 K } }
为什么 TEXT 是必需的?Gemini 图像模型在设计上是多模态的——它们会在图像旁边生成文本响应(通常是描述或说明文字)。API 围绕这种双输出模型构建,试图通过从 responseModalities 中省略 TEXT 来抑制文本输出,会导致整个响应失败,而不是返回仅有图像的输出。目前无法在不将 TEXT 包含在模态列表中的情况下获得纯图像输出。
错误的 API 端点
一些开发者通过 OpenAI 兼容客户端集成 Gemini 图像生成,或使用 /v1/ 端点而非 /v1beta/。Gemini 图像生成 API 需要 /v1beta/ 端点路径。向 OpenAI 兼容端点(/v1/images/generations)或稳定版 /v1/ 路径发送的请求会返回 404 错误或明确的"不支持的操作"消息。
正确的端点结构如下:
POST https://generativelanguage.googleapis.com/v1beta/models/{model-name}:generateContent
如果你在使用 OpenAI 兼容库与 Gemini 配合,请确保正确配置了 base URL。许多使用 openai Python 库接入 Gemini 的开发者会将 base_url 指向 Gemini 服务器,但如果指向了 /v1/ 路径,图像模型将无法访问。
错误的模型名称
三个当前的 Gemini 图像模型有特定的名称,必须与文档完全一致。截至撰写本文时(已对照 ai.google.dev 验证,2026-03-16),当前模型名称为:
gemini-3.1-flash-image-preview— 快速生成,预览模型gemini-3-pro-image-preview— 高质量,预览模型gemini-2.5-flash-image— 高效,稳定模型
常见错误包括使用 gemini-2.5-flash-preview-image(后缀顺序错误)、gemini-flash-image(缺少版本号),或已被弃用的旧模型名称。模型名称错误通常返回 400 INVALID_ARGUMENT 或 404 NOT_FOUND——它们通常不会产生静默的 200 响应,但会导致生成失败,错误特征与速率限制不同。
未启用计费:你可能误认为是配置错误的 400
当计费未启用且超出免费套餐的零配额限制时,你可能期望看到一个清晰的错误。Gemini Image API 实际上返回 HTTP 400,gRPC 状态为 FAILED_PRECONDITION,消息中包含"billing"。这与计费已启用但配额耗尽时的 429 不同。FAILED_PRECONDITION 状态意味着操作的前置条件未满足——在这种情况下,前置条件是必须启用计费才能使用图像生成 API。
如果你在错误响应中看到 FAILED_PRECONDITION,修复方法始终是在 GCP Console 中启用计费,而不是调整 API 参数。更改 responseModalities 或 imageConfig 不会解决这个错误。
静默失败的参数:imageConfig 与 responseModalities

参数失败是 Gemini 图像 API 中一种特殊的令人沮丧的情况,因为 API 毫无怨言地接受你的请求,生成图像并返回——但图像与你的规格不符。你请求了 2K 分辨率,却得到了 512px。你设置了宽高比,却得到了 1:1。你配置了 imageConfig,但它毫无效果。API 没有拒绝你的参数,只是忽略了它们。
image_size 大小写陷阱
imageConfig 中的 image_size 参数以一种不直观的方式区分大小写。有效值使用大写"K"——"512"、"1K"、"2K"、"4K"。使用小写 "1k" 不会产生错误;它会静默地回退到默认分辨率(512px)。这意味着你可以写出看似正确的代码,测试它,却永远不知道你的分辨率设置被忽略了。
这一具体问题已对照官方 Gemini API 文档(ai.google.dev,2026-03-16)进行了验证。对于来自不区分大小写字符串值的小写惯例语言或 API 的开发者来说,这个陷阱特别隐蔽。响应中没有任何警告说明你的 "1k" 是无效的——图像只是比预期更小。
image_size 的完整有效值列表为:"512"、"1K"、"2K"、"4K"。宽高比参数(aspect_ratio)接受 "1:1"、"3:4"、"4:3"、"9:16"、"16:9"——这些值不区分大小写,并使用冒号表示法。
为什么 responseModalities 必须包含 TEXT
如静默失败章节所述,responseModalities 必须同时包含 "TEXT" 和 "IMAGE"。但参数顺序也有一个额外的细节需要注意。responseModalities 数组应先列出 "TEXT",再列出 "IMAGE"——虽然 API 目前接受任意顺序,但文档中规定的顺序是 ["TEXT", "IMAGE"],偏离此顺序可能会在未来的 API 版本中引起问题。这是个小细节,但生产代码应遵循文档中的惯例。
python"responseModalities": ["TEXT", "IMAGE"] # 被接受但不推荐 "responseModalities": ["IMAGE", "TEXT"] # 错误 - 静默返回空响应 "responseModalities": ["IMAGE"] # 错误 - 根本没有请求图像 "responseModalities": ["TEXT"]
imageConfig 被中间件剥离
这是最微妙的参数失败模式。当使用 LiteLLM 等中间件层代理 Gemini API 调用时,imageConfig 参数通常在到达 Gemini API 之前就被从请求中剥离。LiteLLM GitHub Issue #18656 记录了这一行为——LiteLLM 将参数规范化为其内部格式,而 imageConfig 在此规范化过程中无法存活。
症状是:你的图像可以生成,但分辨率和宽高比设置无效。修复方法是绕过中间件直接进行图像生成,使用原生 HTTP API。如果你必须在基础设施中使用 LiteLLM 或类似工具,你需要将图像生成请求直接路由,同时将文本生成通过中间件路由。
以下是直接调用 API、绕过任何中间件的方法:
pythonimport requests import base64 def generate_image_direct(prompt: str, api_key: str, size: str = "1K") -> bytes: """Direct HTTP call to Gemini Image API — bypasses middleware.""" url = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" headers = {"Content-Type": "application/json"} params = {"key": api_key} payload = { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], "imageConfig": { "image_size": size, # Must be "512", "1K", "2K", or "4K" "aspect_ratio": "16:9" # Optional } } } response = requests.post(url, json=payload, headers=headers, params=params) response.raise_for_status() data = response.json() for part in data["candidates"][0]["content"]["parts"]: if "inlineData" in part: return base64.b64decode(part["inlineData"]["data"]) raise ValueError("No image data in response — check responseModalities config")
请注意,在直接 HTTP 请求体中,generationConfig 包裹着 imageConfig。某些 SDK 版本使用平面的 generation_config 字典,但原生 REST API 使用上面所示的嵌套结构。这是参数混淆的另一个来源——SDK 接口并不总是与底层 HTTP 请求结构一致。
检查你的配额:GCP Console 诊断指南
了解配额状况对诊断 429 错误至关重要,但许多开发者不知道在哪里找到准确的配额信息,也不知道这些数字代表什么含义。GCP Console 有权威数据,但导航到那里并不直观。
找到你的图像生成配额
GCP Console 中的精确导航路径(已于 2026-03-16 验证):
- 前往 console.cloud.google.com
- 从顶部下拉菜单选择你的项目
- 导航至 APIs & Services → Generative Language API
- 点击左侧边栏中的 Quotas and System Limits
- 在过滤栏中输入"image"以过滤图像专属配额
配额视图显示多个维度。对于图像生成,关键维度是 IPM(每分钟图像数)——这是 Gemini 图像生成被限速的维度。不要将其与 RPM(每分钟请求数)混淆,后者用于管理文本生成调用,对图像 API 调用而言不是约束性限制。
理解配额维度
Gemini 图像模型有三个配额维度:
| 维度 | 限制内容 | 典型范围 |
|---|---|---|
| RPM(每分钟请求数) | 每分钟 API 调用次数 | 与文本模型共享 |
| RPD(每天请求数) | 每天 API 调用次数 | 预览模型:1,500/天 |
| IPM(每分钟图像数) | 每分钟生成的图像数 | 图像专属;最关键 |
自 2025 年 12 月 7 日起,免费套餐的 IPM 为 0——这意味着免费账户无法通过 API 生成任何图像。这是对之前允许有限图像生成的免费套餐的改变。如果你在此日期之前升级并享有祖父级配额,GCP Console 将显示你当前的配额额度。如果你在 2025 年 12 月 7 日之后创建账户或首次启用了该 API,在启用计费之前你的 IPM 将为 0。
对于付费套餐 1 级账户(已启用计费,低于 2 级阈值),我们 SERP 分析的验证数据(wentuo.ai,Firebase 文档,2026-03-16)显示约为 10 IPM。付费套餐 2 级(更高使用量)提供约 20 IPM。具有预置吞吐量的 Vertex AI 提供与 Google 协商的专用配额,消除了共享池约束。
解读配额面板
配额面板以限额的百分比显示当前使用量。读数为"100%"意味着你已在该时间窗口内达到限制。重要提示:配额重置是滚动窗口,而不是固定的时钟分钟。你的 IPM 配额是在滚动 60 秒窗口内计算的,所以如果你在 12:00:00 生成了 10 张图像并处于付费套餐 1 级(10 IPM 限制),你直到 12:01:00 才能再次生成。
如果你看到配额为 0%,但仍然收到 429 错误,这是 Ghost 429 Bug(第2章根本原因3)或近期计费变更后配额传播问题的强烈诊断信号。在这种情况下,等待 15-30 分钟让配额变更传播,如果问题在几小时后仍然存在,请查阅第2章中的 Ghost 429 指导。
选择适合 Gemini 图像生成的套餐层级
你使用的套餐层级对成本和可靠性都有重大影响,特别是对生产应用而言。了解权衡取舍有助于你做出正确的基础设施决策,而不是在生产负载下才发现限制。
| 套餐层级 | IPM | RPM | RPD | 最适合场景 |
|---|---|---|---|---|
| 免费 | 0 | 10 | 1,500 | 仅供学习(无法生成图像) |
| 付费 1 级 | ~10 | 10 | 1,500 | 轻量级生产使用 |
| 付费 2 级 | ~20 | 20+ | 3,000+ | 中等规模生产 |
| Vertex AI | 协商确定 | 协商确定 | 协商确定 | 高吞吐量生产 |
预览模型 vs. 生产模型
gemini-3.1-flash-image-preview 和 gemini-3-pro-image-preview 是预览模型——它们在动态共享配额上运行,不提供与生产模型相同的可靠性保证。对于 Gemini 图像生成功能,截至本文撰写时,只有 gemini-2.5-flash-image 是稳定(非预览)模型。
对于生产用例,这有两方面的影响。首先,即使你在个人配额内,预览模型的 429 也可能出现——它们反映的是全球拥塞,而非你的使用情况。其次,预览模型可能被弃用或在行为上发生变化,而不会像生产模型那样收到完整的弃用通知。如果你在构建需要可靠运行数月的应用,稳定模型是更好的基础,即使它的某些能力略有不同。关于预览模型提供的完整功能细节,请参阅我们关于 Gemini 3.1 Flash Image 预览模型能力的指南。
何时考虑替代 API 提供商
如果你需要比 AI Studio 套餐提供更高的吞吐量,但又没有准备好建立完整的 Vertex AI 集成,第三方 API 聚合服务如 laozhang.ai 提供具有不同速率限制结构的 Gemini 图像模型。这些服务对开发、测试或在主要 API 访问高峰期间作为补充非常有用。聚合器方案会增加一个网络跳转,不应作为关键应用的主要生产基础设施,但在主要配额耗尽时可以作为有用的备用方案。
对于生产规模的图像生成,具有预置吞吐量的 Vertex AI 是正确的长期解决方案——你可以协商专用容量,而不必与其他用户竞争共享池配额。
生产可用的错误处理代码
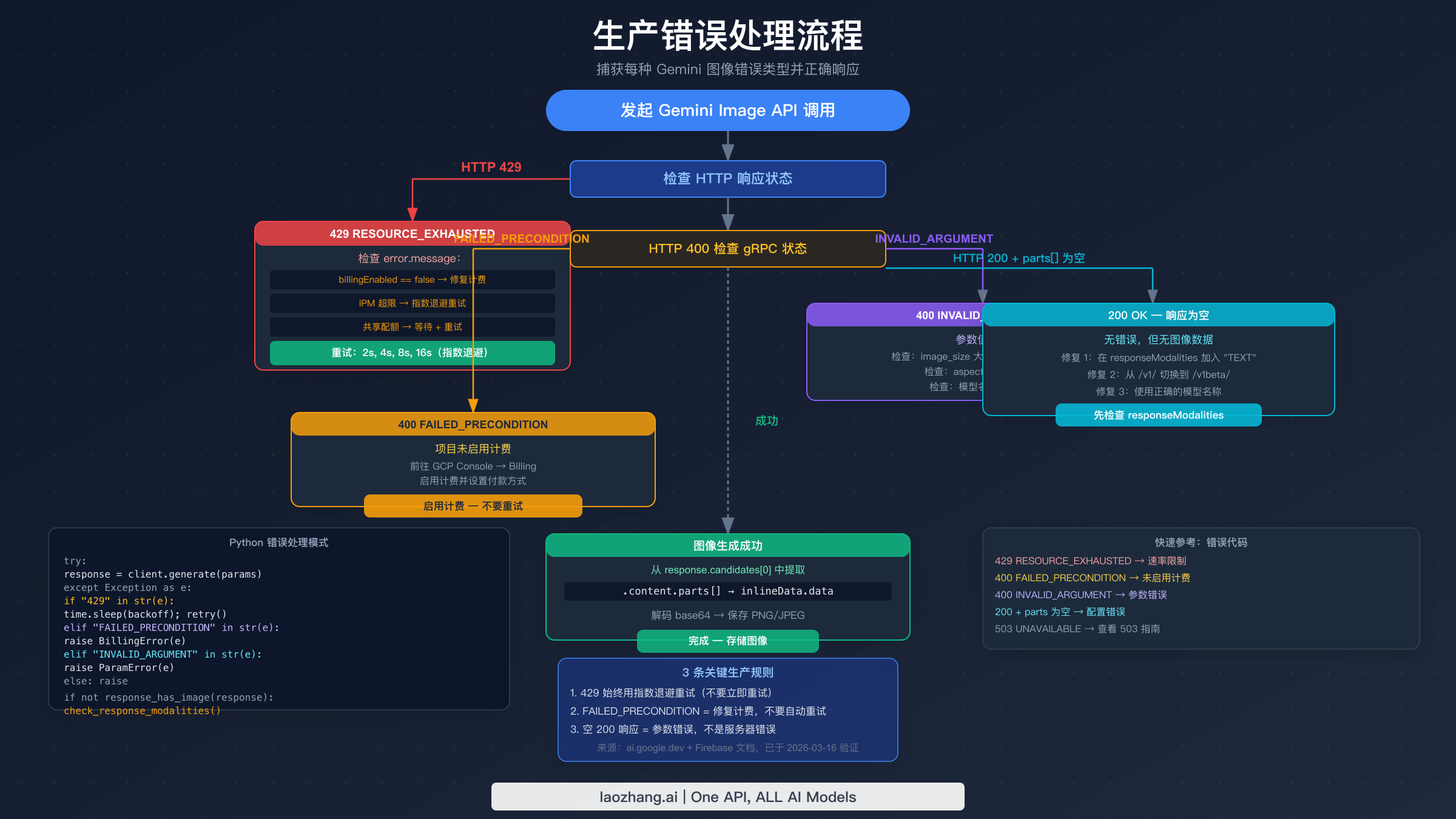
生产环境中的 Gemini 图像生成需要系统性地处理所有三类错误。以下代码提供了一个完整的 Python 实现,包含适当的错误分类、指数退避、参数验证和空响应检测。
pythonimport time import base64 import requests from typing import Optional from dataclasses import dataclass # Valid parameter constants (from official docs, verified 2026-03-16) VALID_IMAGE_SIZES = {"512", "1K", "2K", "4K"} VALID_ASPECT_RATIOS = {"1:1", "3:4", "4:3", "9:16", "16:9"} GEMINI_IMAGE_ENDPOINT = ( "https://generativelanguage.googleapis.com/v1beta/models/" "{model}:generateContent" ) @dataclass class ImageGenerationError(Exception): """Base class for Gemini image generation errors.""" message: str error_type: str # "rate_limit", "billing", "parameter", "empty_response" retryable: bool def validate_image_config(image_size: str, aspect_ratio: Optional[str] = None): """Validate imageConfig parameters before API call.""" if image_size not in VALID_IMAGE_SIZES: raise ImageGenerationError( message=f"Invalid image_size '{image_size}'. Valid values: {VALID_IMAGE_SIZES}. " f"Note: case-sensitive — use '1K' not '1k'.", error_type="parameter", retryable=False ) if aspect_ratio and aspect_ratio not in VALID_ASPECT_RATIOS: raise ImageGenerationError( message=f"Invalid aspect_ratio '{aspect_ratio}'. Valid: {VALID_ASPECT_RATIOS}", error_type="parameter", retryable=False ) def classify_error(response_or_exception) -> ImageGenerationError: """Classify API error into actionable categories.""" if isinstance(response_or_exception, requests.Response): status = response_or_exception.status_code try: body = response_or_exception.json() error_msg = str(body.get("error", {}).get("message", "")) grpc_status = body.get("error", {}).get("status", "") except Exception: error_msg = response_or_exception.text grpc_status = "" else: error_msg = str(response_or_exception) status = 500 grpc_status = "" if status == 429 or "RESOURCE_EXHAUSTED" in grpc_status: return ImageGenerationError( message=f"Rate limit exceeded: {error_msg}", error_type="rate_limit", retryable=True ) elif "FAILED_PRECONDITION" in grpc_status or "billing" in error_msg.lower(): return ImageGenerationError( message="Billing not enabled. Enable billing in GCP Console.", error_type="billing", retryable=False # Retrying won't help — fix billing first ) elif "INVALID_ARGUMENT" in grpc_status or status == 400: return ImageGenerationError( message=f"Invalid parameter: {error_msg}", error_type="parameter", retryable=False ) else: return ImageGenerationError( message=f"Unexpected error ({status}): {error_msg}", error_type="unknown", retryable=False ) def generate_image( prompt: str, api_key: str, model: str = "gemini-3.1-flash-image-preview", image_size: str = "1K", aspect_ratio: Optional[str] = None, max_retries: int = 5, initial_backoff: float = 2.0 ) -> bytes: """ Generate image with full error handling. Returns raw image bytes (PNG format). Raises ImageGenerationError with retryable flag for caller to handle. """ # Validate parameters before making API call validate_image_config(image_size, aspect_ratio) url = GEMINI_IMAGE_ENDPOINT.format(model=model) headers = {"Content-Type": "application/json"} params = {"key": api_key} image_config = {"image_size": image_size} if aspect_ratio: image_config["aspect_ratio"] = aspect_ratio payload = { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], # Both required "imageConfig": image_config } } last_error = None for attempt in range(max_retries): try: response = requests.post( url, json=payload, headers=headers, params=params, timeout=60 ) if not response.ok: error = classify_error(response) if not error.retryable: raise error last_error = error backoff = initial_backoff * (2 ** attempt) print(f"Attempt {attempt + 1}: {error.error_type}, retrying in {backoff}s") time.sleep(backoff) continue # HTTP 200 — check for actual image data data = response.json() candidates = data.get("candidates", []) if not candidates: raise ImageGenerationError( message="No candidates in response. Check model name and quota.", error_type="empty_response", retryable=False ) parts = candidates[0].get("content", {}).get("parts", []) for part in parts: if "inlineData" in part: return base64.b64decode(part["inlineData"]["data"]) # 200 OK but no image data — common config error raise ImageGenerationError( message=( "HTTP 200 but no image in response. " "Verify responseModalities includes both 'TEXT' and 'IMAGE'. " "Check you're using /v1beta/ endpoint." ), error_type="empty_response", retryable=False ) except ImageGenerationError: raise # Don't retry non-retryable errors except requests.RequestException as e: last_error = classify_error(e) if attempt < max_retries - 1: backoff = initial_backoff * (2 ** attempt) time.sleep(backoff) raise last_error or ImageGenerationError( message="Max retries exceeded", error_type="rate_limit", retryable=True ) # Usage example if __name__ == "__main__": try: image_bytes = generate_image( prompt="A serene mountain lake at sunset", api_key="YOUR_API_KEY", model="gemini-3.1-flash-image-preview", image_size="1K", aspect_ratio="16:9" ) with open("output.png", "wb") as f: f.write(image_bytes) print("Image saved to output.png") except ImageGenerationError as e: print(f"Error type: {e.error_type}") print(f"Message: {e.message}") print(f"Retryable: {e.retryable}") if e.error_type == "billing": print("Action: Enable billing at console.cloud.google.com/billing") elif e.error_type == "parameter": print("Action: Fix parameters — check image_size casing and aspect_ratio format") elif e.error_type == "empty_response": print("Action: Add 'TEXT' to responseModalities and verify /v1beta/ endpoint")
JavaScript/Node.js 版本
javascriptconst fetch = require('node-fetch'); const VALID_IMAGE_SIZES = new Set(['512', '1K', '2K', '4K']); async function generateImage(prompt, apiKey, options = {}) { const { model = 'gemini-3.1-flash-image-preview', imageSize = '1K', aspectRatio = null, maxRetries = 5, } = options; if (!VALID_IMAGE_SIZES.has(imageSize)) { throw new Error(`Invalid imageSize '${imageSize}'. Use: ${[...VALID_IMAGE_SIZES].join(', ')}`); } const url = `https://generativelanguage.googleapis.com/v1beta/models/${model}:generateContent?key=${apiKey}`; const imageConfig = { image_size: imageSize }; if (aspectRatio) imageConfig.aspect_ratio = aspectRatio; const payload = { contents: [{ parts: [{ text: prompt }] }], generationConfig: { responseModalities: ['TEXT', 'IMAGE'], imageConfig, }, }; for (let attempt = 0; attempt < maxRetries; attempt++) { const response = await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload), }); if (response.status === 429) { if (attempt === maxRetries - 1) throw new Error('Max retries exceeded (429)'); const delay = Math.pow(2, attempt + 1) * 1000; await new Promise(r => setTimeout(r, delay)); continue; } if (!response.ok) { const body = await response.json(); const status = body?.error?.status || ''; if (status === 'FAILED_PRECONDITION') { throw new Error('Billing not enabled. Enable billing in GCP Console.'); } throw new Error(`API error ${response.status}: ${JSON.stringify(body?.error)}`); } const data = await response.json(); const parts = data?.candidates?.[0]?.content?.parts || []; const imagePart = parts.find(p => p.inlineData); if (!imagePart) { throw new Error( 'HTTP 200 but no image data. Check responseModalities includes TEXT and IMAGE.' ); } return Buffer.from(imagePart.inlineData.data, 'base64'); } }
在需要处理多个模型和降级策略的高并发生产场景中,当主要 API 配额耗尽时,laozhang.ai 的图像端点等 API 聚合服务可以作为备用方案。聚合器内部处理速率限制,这在主 API 被限速时可以简化你的错误处理代码。
常见问题解答
为什么我的 Gemini 图像 API 调用返回 HTTP 200 但没有图像?
最常见的原因是 responseModalities 设置为 ["IMAGE"] 而非 ["TEXT", "IMAGE"]。Gemini 图像 API 需要同时指定 TEXT 和 IMAGE 两种模态——省略 TEXT 会导致 API 返回空响应且不报错。检查你的 generationConfig,确保包含这两个值。如果这没问题,请验证你使用的是 /v1beta/ 端点,而非 /v1/ 或 OpenAI 兼容端点。
升级到付费计划后,如何修复 Gemini 图像 API 429 错误?
首先检查你升级的时间。如果是在过去 24-48 小时内,你可能受到了 Ghost 429 Bug 的影响(2026 年 2 月确认的已知问题,新计费激活不会立即传播配额)。尝试暂时切换到不同的模型变体。如果在 GCP Console 显示非零配额的情况下,429 在 48 小时后仍持续存在,请提交支持工单并引用配额传播问题。同时验证 GCP Console 中的 IPM(每分钟图像数)配额实际上是非零的——启用计费并不自动意味着你的图像配额被设置为非零值。
为什么我的 imageConfig 设置被忽略了?
两个常见原因:大小写敏感性或中间件剥离。对于大小写敏感性,检查你的 image_size 值是否使用了大写 K——"1K" 而非 "1k"。对于中间件剥离,如果你通过 LiteLLM 或类似代理层路由请求,imageConfig 可能在到达 Gemini API 之前就被剥离了。修复方法是直接对 Gemini API 发起 HTTP 调用进行图像生成,而不是通过代理。
Gemini 图像模型的 IPM 和 RPM 配额有什么区别?
RPM(每分钟请求数)限制每分钟 API 调用次数,适用于所有 Gemini 模型。IPM(每分钟图像数)是图像专属的,限制每分钟可以生成的单独图像数量。如果 numberOfImages 设置大于 1,一次 API 调用可以生成多张图像,每张图像都会单独计入你的 IPM 配额。在大多数使用模式中,IPM 配额通常是图像生成的约束性限制——你会在达到 RPM 之前先达到 IPM。
在生产环境中使用 Gemini 预览图像模型安全吗?
预览模型(gemini-3.1-flash-image-preview、gemini-3-pro-image-preview)使用动态共享配额,这意味着即使你在个人配额限制内,它们也可能因全球拥塞而返回 429 错误。它们适合开发和轻量级生产使用,但对于有 SLA 要求的应用,请使用稳定的 gemini-2.5-flash-image 模型或具有预置吞吐量的 Vertex AI。预览模型也可能被更改或弃用,通知期比生产模型短。
总结与下一步
Gemini 图像 API 错误确实令人困惑,因为不同的问题会产生看起来完全相同的症状。429 可能意味着你的免费套餐配额为零、你的付费配额已耗尽、你遇到了已知 Bug,或者你正在经历全球拥塞——每种情况都需要完全不同的应对措施。空的 HTTP 200 可能意味着参数配置错误、端点错误或中间件干扰。
适用于所有错误类型的诊断顺序:先检查计费(GCP Console → APIs & Services → Generative Language API → Quotas),然后验证你的参数(responseModalities: ["TEXT", "IMAGE"],image_size: "1K" 大写),最后确认你的端点(/v1beta/ 而非 /v1/)。大多数问题在这三个检查点之一处得以解决。
对于生产应用,从一开始就在代码中构建错误分类机制——区分可重试的 429 和不可重试的计费错误及参数错误,可以避免后期的运维痛苦。第7章中的完整代码示例开箱即提供了这种分类功能。
如果你持续达到配额限制并需要更高的吞吐量,但又不想面对 Vertex AI 预置的复杂性,可以考虑调整你的批量生成策略以保持在 IPM 限制内,或者探索 2 级配额阈值是否满足你的需求。配额结构设计为随使用量扩展——一旦你理解了哪个维度是你工作负载的约束性限制,起初看起来的限制就会变得可控。