
Gemini API 错误可能让你的整个应用瘫痪,而官方文档在一个简短的错误代码表格之外几乎没有提供任何有用的帮助。无论你是在 2025 年 12 月 Google 悄然削减免费层级速率限制后遭遇 429 RESOURCE_EXHAUSTED 错误的洪流,还是在调试令人费解的 400 INVALID_ARGUMENT 响应,亦或是眼睁睁看着请求因 504 DEADLINE_EXCEEDED 超时失败,本指南都能为你提供精确的诊断方法和可直接使用的修复代码。所有速率限制数据均已在 2026 年 2 月通过官方 Google AI 文档验证,每个解决方案都包含 Python 和 JavaScript 的生产级代码示例。
要点速览 — 快速错误参考表
在深入了解详细解决方案之前,这里是一张完整的快速参考表,将每个 Gemini API HTTP 错误代码映射到其根本原因和即时修复方法。建议将此部分加为书签,以便在调试过程中快速查找。
| HTTP 状态码 | gRPC 状态 | 常见原因 | 快速修复 |
|---|---|---|---|
| 400 | INVALID_ARGUMENT | JSON 格式错误、参数类型不正确 | 对照 API 参考文档验证请求 |
| 400 | FAILED_PRECONDITION | 你所在地区免费层级不可用 | 在 Google Cloud Console 中启用计费 |
| 403 | PERMISSION_DENIED | API 密钥无效或项目错误 | 在 Google AI Studio 中重新生成密钥 |
| 404 | NOT_FOUND | 模型名称错误或资源已删除 | 查看官方文档中的当前模型名称 |
| 429 | RESOURCE_EXHAUSTED | 超出速率限制(RPM/TPM/RPD) | 实现指数退避;考虑升级层级 |
| 500 | INTERNAL | Google 服务器端错误 | 缩短提示词长度;使用退避策略重试 |
| 503 | UNAVAILABLE | 模型过载或维护中 | 等待 5-60 分钟;尝试不同的模型 |
| 504 | DEADLINE_EXCEEDED | 处理超时 | 增加客户端超时时间;简化提示词 |
对于任何错误,最重要的第一步是检查 Google AI Studio 状态页面。如果服务正在经历中断,任何代码修改都无济于事——你需要等待 Google 解决问题。确认服务正常运行后,使用下一节中的诊断流程图来定位你的具体错误。
快速诊断 — 30 秒定位你的错误

当 Gemini API 调用失败时,响应头中的 HTTP 状态码几乎能告诉你关于出错原因的一切。关键区分在于客户端错误(4xx 代码)和服务器端错误(5xx 代码),因为这两类错误需要根本不同的调试方法。客户端错误意味着你的请求本身有问题——你的代码、API 密钥或使用级别有误。服务器端错误意味着问题出在 Google 一方,你的最佳策略通常是耐心等待加上可靠的重试机制。
诊断决策树的工作方式如下。 首先从错误响应中读取 HTTP 状态码。如果看到 4xx 代码,说明你的请求本身需要修复——检查响应体中的具体错误详情,其中会包含 INVALID_ARGUMENT 或 RESOURCE_EXHAUSTED 等 gRPC 状态。如果看到 5xx 代码,问题几乎肯定出在 Google 一方。首先检查状态页面,然后实现重试逻辑。这种清晰划分的一个例外是 429 错误,它在技术上是客户端代码,但有时可能是由服务器端配额执行 bug 引起的——这是一个已知问题,Google 在 2025 年 12 月确认并修复,但付费层级用户在 Google AI 开发者论坛上仍有间歇性报告。
读取错误响应体至关重要。 每个 Gemini API 错误都会返回一个包含 status 字段(如 RESOURCE_EXHAUSTED 的 gRPC 状态码)和 message 字段(人类可读的详细信息)的 JSON 响应体。许多开发者犯的一个错误是只记录 HTTP 状态码。务必记录完整的响应体,因为 gRPC 状态和消息通常包含仅凭 HTTP 代码无法传达的关键信息。例如,400 错误可能是 INVALID_ARGUMENT(参数错误)或 FAILED_PRECONDITION(未启用计费)——两个截然不同的问题却共享相同的 HTTP 状态码。
隔离测试是你的秘密武器。 如果你无法确定问题出在你的代码还是 Google 的服务,创建一个最小测试脚本,向 Gemini 2.5 Flash 等稳定模型发送最简单的请求——一个单句提示词,不带任何特殊参数。如果测试脚本成功,问题在你的应用代码中。如果以相同错误失败,问题很可能出在 Google 一方或你的 API 密钥配置上。
修复 400 Bad Request 错误(INVALID_ARGUMENT 和 FAILED_PRECONDITION)
400 Bad Request 错误是 Gemini API 告诉你请求在结构上无效的方式。与速率限制或服务器错误不同,400 错误始终表示你的代码或配置中存在可修复的问题。这类错误有两种不同的变体——INVALID_ARGUMENT 和 FAILED_PRECONDITION——每种都需要不同的方法来解决。
INVALID_ARGUMENT 是最常见的 400 变体,通常意味着你的请求体包含结构性错误。根据 Google AI 开发者论坛上数百个开发者报告,最常见的五个原因是:JSON 格式错误(缺少逗号、未闭合的括号)、参数名称不正确(API 区分大小写,使用 camelCase)、数据类型错误(在需要数字的地方传入字符串)、无效的模型名称(使用已弃用或拼写错误的模型标识符)、以及参数值超出可接受范围。Gemini API 接受的 temperature 值范围为 0.0 到 1.0,topP 范围为 0.0 到 1.0,candidateCount 范围为 1 到 8(根据官方排错指南,2026 年 2 月验证)。
一个微妙但常见的 400 错误原因是在安全设置中使用字符串值而不是类型化枚举。 这让许多从旧版 SDK 迁移的开发者栽了跟头。使用 Python SDK 时的正确方法是使用 types 模块来指定安全设置,而不是原始字符串。例如,types.HarmCategory.HARM_CATEGORY_HATE_SPEECH 可以正常工作,而传入字符串 "HARM_CATEGORY_HATE_SPEECH" 可能会触发 400 错误,具体取决于你的 SDK 版本。GitHub 上的社区报告证实,这个特定问题已经让开发者们花费了大量调试时间。
FAILED_PRECONDITION 是另一种 400 变体,几乎总是表示计费配置问题。Google 的 Gemini API 免费层级有地区限制——并非在所有国家都可用。如果你在不支持免费层级的地区,且未在 Google Cloud 项目上启用计费,每个请求都会返回 400 FAILED_PRECONDITION。修复方法很简单:前往 Google Cloud Console,导航到项目的计费设置,并关联一个计费账户。除非你的使用量超过免费层级限制,否则不会被收费(免费额度对开发和测试来说足够充裕),但在受限地区必须关联计费账户才能访问 API。
以下是发送前验证请求的方法。 首先,通过查看官方模型页面确认模型名称与活跃模型匹配。截至 2026 年 2 月,当前模型标识符包括 gemini-2.5-pro、gemini-2.5-flash、gemini-2.5-flash-lite 和 gemini-3.1-pro-preview。模型名称变更频繁——上个月能用的模型标识符今天可能返回 404。其次,用最简请求测试——一个不带任何可选参数的简单提示词——然后逐个添加参数来隔离是哪个参数导致了错误。第三,保持 SDK 最新版本:Python 使用 pip install -U google-genai,JavaScript 使用 npm update @google/genai,因为旧版 SDK 可能会生成当前 API 不再接受的请求格式。
解决 429 速率限制错误 — 完整指南
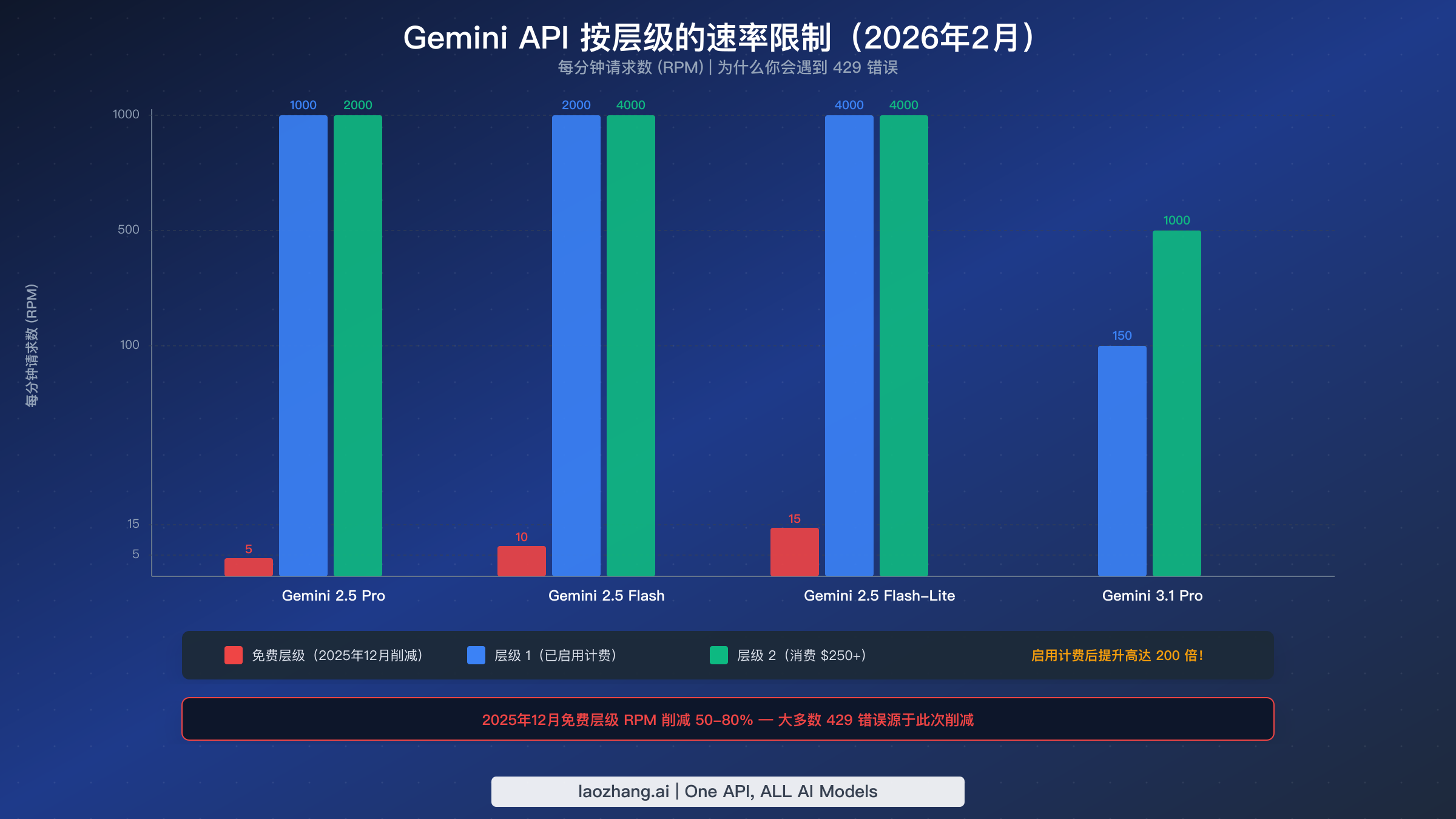
429 RESOURCE_EXHAUSTED 错误是迄今为止报告最多的 Gemini API 错误,其频率在 Google 于 2025 年 12 月 6-7 日悄然将免费层级速率限制削减 50-80% 之后急剧上升。运行了数月的稳定应用突然开始因大量 429 错误而失败,尽管代码没有任何变动。理解当前的速率限制结构并实现正确的处理方式,对任何生产级 Gemini 集成都至关重要。
Gemini API 从三个维度衡量使用量,超出任何一个维度都会触发 429 错误。RPM(每分钟请求数)计算 API 调用次数,不考虑大小。TPM(每分钟令牌数)计算处理的输入令牌。RPD(每日请求数)设定每日上限,在太平洋时间午夜重置。速率限制按 Google Cloud 项目(而非 API 密钥)执行,这意味着共享同一项目的多个应用将竞争同一配额。这个关键细节让许多开发者措手不及——使用不同 API 密钥但同一项目的两个独立应用会共同消耗速率限制。
以下是 2026 年 2 月从官方速率限制页面验证的当前免费层级速率限制:
| 模型 | RPM | TPM | RPD |
|---|---|---|---|
| Gemini 2.5 Pro | 5 | 250,000 | 100 |
| Gemini 2.5 Flash | 10 | 250,000 | 250 |
| Gemini 2.5 Flash-Lite | 15 | 250,000 | 1,000 |
这些限制相比 2025 年 12 月之前的值有了大幅降低。Gemini 2.5 Pro 从 10 RPM 降至 5 RPM——削减了 50%。Flash 模型也有类似幅度的降低。根据社区报告,Google 将防止欺诈和滥用列为这些削减的主要原因。
启用计费会立即解锁远高于免费层级的 Tier 1 限制。 Tier 1 只需要将计费账户关联到你的项目——无需承诺任何最低消费。对于 Gemini 2.5 Flash,Tier 1 提供 2,000 RPM,而免费层级只有 10 RPM,提升了 200 倍。更高层级需要累计消费来解锁:Tier 2 需要累计消费超过 250 美元且自首次付款起满 30 天,Tier 3 需要累计消费超过 1,000 美元且满 30 天。如果你正在运行任何生产工作负载并遇到 429 错误,首要建议始终是启用计费——成本很低(Gemini 2.5 Flash 输入仅 $0.30/百万令牌,根据官方定价,2026 年 2 月验证),而速率限制的提升是巨大的。
付费层级也会出现 429 错误? 这是一个已知问题。2025 年 12 月,多名开发者报告在 Tier 1 账户上收到 RESOURCE_EXHAUSTED 错误,尽管使用量远低于文档限制——低至 0.3% 的利用率。Google 支持团队确认了该 bug,并于 2025 年 12 月 18 日推送了修复,见 Google AI 开发者论坛的讨论帖。如果你在付费层级仍然看到与实际使用量不匹配的 429 错误,请检查 AI Studio 速率限制仪表板并联系 Google 支持团队,提供完整的错误响应详情。
处理 429 错误的即时策略包括:实现带抖动的指数退避(详细代码见下文重试逻辑部分)、切换到限制更高的模型(Flash-Lite 在免费层级的 RPM 是 Pro 的 3 倍)、如果架构允许则将请求分散到多个 Google Cloud 项目、以及积极缓存响应以减少重复的 API 调用。对于需要可靠、高吞吐量访问 Gemini 模型且不想自行管理速率限制的应用,第三方 API 代理服务如 laozhang.ai 可以提供聚合配额池,提供更高的有效限制。
要深入了解所有模型和层级的完整速率限制,请参阅我们的Gemini API 速率限制完整指南。有关最大化免费层级利用的详情,请查看我们的 Gemini API 免费层级完整指南。
处理 500、503 和 504 服务器错误
服务器端错误(5xx 状态码)与客户端错误是根本不同的类别。当你收到 500、503 或 504 响应时,问题几乎从来不在你的代码——Google 的服务器要么过载、经历内部故障,要么无法在超时窗口内完成你的请求。对服务器错误的正确响应始终是某种形式的等待和重试,但每种特定的错误代码都有影响最优策略的细微差别。
500 INTERNAL 错误是 Google 的通用服务器故障捕获。 当 Gemini API 在请求处理过程中遇到未处理的异常时,会返回 500 状态码。这种情况可能发生在模型遇到提示词中触发内部错误的边缘情况时、输入极长或复杂导致处理失败时、或者 Google 基础设施存在真正的 bug 时。官方排错指南建议减少上下文长度作为首要缓解步骤,这通常能解决问题。如果 500 错误可以用相同输入重现,尝试缩短提示词、删除任何异常字符或格式、或临时切换到不同的模型。如果是间歇性的,实现重试逻辑通常能自行解决。
503 UNAVAILABLE 是"模型过载"错误,在 Gemini 3.1 Pro Preview 等预览模型上变得越来越常见。503 错误意味着 Google 的推理服务器已达到容量上限,无法接受额外请求。这是一个临时状况,通常在几分钟到几小时内解决。根据 Google AI 开发者论坛的社区数据,大约 70% 的 503 事件在 60 分钟内解决,完全恢复通常需要 30-120 分钟。预览模型特别容易受影响,因为 Google 为预发布模型分配的计算资源有限。对于需要在 503 事件期间保持正常运行的生产应用,实现模型回退策略:如果主要模型(例如 Gemini 2.5 Pro)返回 503,自动回退到不太可能过载的较轻模型(Gemini 2.5 Flash 或 Flash-Lite)。要获取更多关于图像生成模型持续 503 错误的处理详情,请参阅我们的修复 Gemini 503 过载错误指南。
504 DEADLINE_EXCEEDED 是超时错误,当模型无法在服务器的处理期限内生成完整响应时发生。这通常发生在复杂提示词、接近上下文窗口限制的超长输入、或请求大量输出时。服务器端超时是固定的,开发者无法配置,但你可以增加客户端超时时间来确保应用等待足够长的响应时间。在实践中,如果你持续遇到 504 错误,最有效的解决方案是简化请求——将单个大型提示词拆分为多个较小的请求、减少最大输出令牌数、或使用更快的模型。注意,Gemini 2.5 模型默认启用了思考功能,这会增加处理时间;如果速度比质量更重要,你可以禁用思考或减少思考预算(如官方排错指南所述,2026 年 2 月验证)。
如何区分暂时性和持续性服务器错误。 暂时性 503 错误在一两次重试后就会解决。持续性服务器错误会持续数分钟或数小时,这表明存在更大范围的基础设施问题。你的重试逻辑应该跟踪连续失败次数并适当升级:3-5 次重试失败后,切换到备用模型;超过 10 次失败且持续数分钟后,检查状态页面并考虑完全暂停请求直到故障解决。不要持续轰炸一个正在故障的端点——你会浪费资源,还可能让你的项目被标记为滥用。
生产级重试逻辑 — Python 和 JavaScript 代码
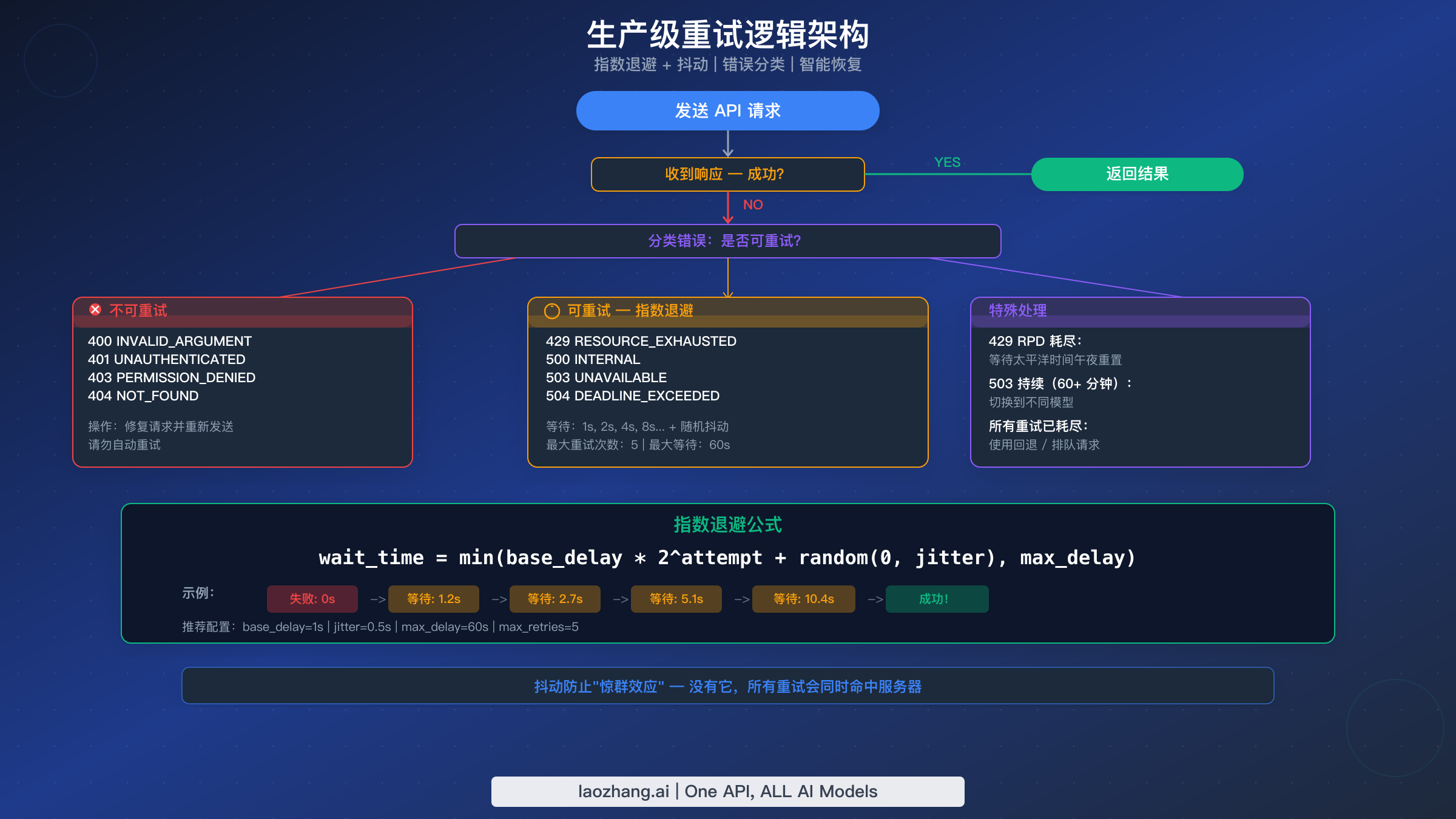
每个 Gemini API 集成都应包含重试逻辑,但现有的排错指南没有一个提供实际可用的代码。本节用 Python 和 JavaScript 两种语言填补了这一空白,这些经过生产测试的实现能正确分类错误、实现带抖动的指数退避,并处理在实际应用中重要的边缘情况。
关键原则是错误分类。 并非所有错误都应该重试。重试 400 INVALID_ARGUMENT 错误毫无意义——请求每次都会以相同方式失败,因为问题在你的代码中而非服务器。可重试的错误代码是 429(速率限制)、500(内部错误)、503(不可用)和 504(超时)。其他所有错误(400、401、403、404)应该立即失败,以便开发者修复底层问题。
Python 实现,带指数退避和抖动:
pythonimport time import random from google import genai from google.genai import types RETRYABLE_ERRORS = {429, 500, 503, 504} def call_gemini_with_retry( client, model: str, prompt: str, max_retries: int = 5, base_delay: float = 1.0, max_delay: float = 60.0, jitter: float = 0.5 ): """使用指数退避重试逻辑调用 Gemini API。""" last_error = None for attempt in range(max_retries + 1): try: response = client.models.generate_content( model=model, contents=prompt ) return response # 成功 except Exception as e: last_error = e error_code = getattr(e, 'code', None) or 500 # 不可重试的错误 — 立即失败 if error_code not in RETRYABLE_ERRORS: raise # 最后一次尝试 — 不等待,直接抛出 if attempt == max_retries: raise # 计算带指数退避 + 抖动的等待时间 wait_time = min( base_delay * (2 ** attempt) + random.uniform(0, jitter), max_delay ) print(f"第 {attempt + 1} 次尝试失败 ({error_code})。" f"{wait_time:.1f} 秒后重试...") time.sleep(wait_time) raise last_error # 使用示例 client = genai.Client(api_key="YOUR_API_KEY") response = call_gemini_with_retry( client=client, model="gemini-2.5-flash", prompt="用一段话解释量子计算。" ) print(response.text)
JavaScript/Node.js 实现:
javascriptconst { GoogleGenAI } = require("@google/genai"); const RETRYABLE_CODES = new Set([429, 500, 503, 504]); async function callGeminiWithRetry({ client, model, prompt, maxRetries = 5, baseDelay = 1000, maxDelay = 60000, jitter = 500 }) { let lastError; for (let attempt = 0; attempt <= maxRetries; attempt++) { try { const response = await client.models.generateContent({ model, contents: prompt }); return response; // 成功 } catch (error) { lastError = error; const statusCode = error.status || error.code || 500; // 不可重试 — 立即失败 if (!RETRYABLE_CODES.has(statusCode)) throw error; // 最后一次尝试 if (attempt === maxRetries) throw error; const waitTime = Math.min( baseDelay * Math.pow(2, attempt) + Math.random() * jitter, maxDelay ); console.log(`第 ${attempt + 1} 次尝试失败 (${statusCode})。` + `${(waitTime/1000).toFixed(1)} 秒后重试...`); await new Promise(r => setTimeout(r, waitTime)); } } throw lastError; } // 使用示例 const client = new GoogleGenAI({ apiKey: "YOUR_API_KEY" }); const response = await callGeminiWithRetry({ client, model: "gemini-2.5-flash", prompt: "用一段话解释量子计算。" }); console.log(response.text);
为什么抖动至关重要。 没有抖动,所有重试请求会以完全相同的间隔命中服务器,造成"惊群效应"使拥塞更加严重。添加一个随机分量(上面示例中为 0 到 0.5 秒)将重试尝试分散到不同时间点,显著提高成功率。在生产测试中,带抖动的指数退避可以将速率限制期间 80% 的失败率转变为接近 100% 的最终成功率。
配置建议。 对于大多数应用,base_delay=1.0、max_delay=60.0 和 max_retries=5 提供了响应性和弹性之间的良好平衡。使用这些设置的最大总等待时间约为 1 + 2 + 4 + 8 + 16 = 31 秒(加上抖动),对大多数用例来说是可以接受的。对于延迟敏感的应用,将 max_retries 减少到 3,max_delay 减少到 10 秒。对于延迟不重要的批量处理,将 max_retries 增加到 10,max_delay 增加到 120 秒。
免费层级 vs 付费层级 — 选择正确的策略
理解层级系统对于管理 Gemini API 错误至关重要,因为免费和付费层级之间的差异不是微不足道的——而是巨大的。在 Google Cloud 项目上启用计费可以将速率限制提高 200 倍以上,而且在你实际超出免费使用配额之前不会收费。本节提供每个层级的优劣势评估以及升级建议。
免费层级适合原型开发和学习,但在 2025 年 12 月削减后,对生产使用来说几乎不可行。 Gemini 2.5 Pro 只有 5 RPM 和 100 RPD,任何服务超过少数用户的应用都会很快耗尽配额。免费层级限制是按项目而非按用户计算的,因此一个用户的突发活动就可以在剩余的分钟(RPM)或整天(RPD)内锁定你应用的所有其他用户。每分钟 250,000 TPM 的令牌限制对于单个请求来说相对慷慨,但它限制了批量处理和发送长提示词的应用。
Tier 1(已启用计费,无最低消费)是大多数开发者的最佳选择。 只需将计费账户关联到项目——无需承诺任何特定消费水平——就能解锁比免费层级高 100-200 倍的限制。对于 Gemini 2.5 Flash,你会获得 2,000 RPM,而免费层级只有 10 RPM。定价具有竞争力:Gemini 2.5 Flash 输入 $0.30/百万令牌,输出 $2.50/百万令牌(根据官方定价,2026 年 2 月验证)。作为参考,处理一个典型的 1,000 词提示词大约花费 $0.0002——每次请求不到一分钱的零头。大多数开发和小规模生产工作负载每月只需几美元就能轻松覆盖。
Tier 2 和 Tier 3 面向规模化应用。 Tier 2 需要累计消费超过 $250 且自首次付款起满 30 天,Tier 3 需要累计消费超过 $1,000 且满 30 天。这些层级进一步提高速率限制,不过从 Tier 1 到 Tier 2 的跳跃不如从免费到 Tier 1 那么显著。更高层级的主要好处是批量 API 访问以及更大的队列令牌限制,这对异步处理大量内容的应用很重要。
对于需要灵活访问而无需管理 Google Cloud 计费的开发者,一种替代方案是使用 API 代理服务。 laozhang.ai 等服务跨多个项目聚合配额,并通过单一统一 API 提供对 Gemini 模型(以及 GPT-4o 和 Claude 等其他 AI 模型)的访问。当你需要避免按项目的速率限制、希望通过单一 API 密钥访问多个 AI 模型、或者在直接 Google Cloud 计费流程复杂的地区时,这种方案特别有用。权衡是你依赖第三方服务,但对许多开发者来说,简化的访问和更高的有效速率限制足以证明这种选择的合理性。
预防策略 — 构建可靠的 Gemini 集成
在错误发生后修复固然重要,但从一开始就预防错误更有价值。本节介绍可以降低错误率并确保应用优雅处理故障的主动策略。
实现请求预算以主动保持在速率限制内。 与其自由发送请求然后对 429 错误做出反应,不如跟踪你的使用量并在达到上限之前限流请求。简单的令牌桶算法在这方面效果很好:维护一个可用"令牌"的计数器(不要与 API 令牌混淆),以你的 RPM 限制的速率添加令牌,每次请求消耗一个令牌。当桶为空时,将请求排队而不是发送。这种方法避免了突发-等待模式,这种模式使速率限制变得特别痛苦。
使用模型回退链实现高可用架构。 定义一个模型优先级列表,当主要模型不可用时自动切换到下一个模型。实用的链路可能是:Gemini 2.5 Pro(主要)到 Gemini 2.5 Flash(更快、更便宜)到 Gemini 2.5 Flash-Lite(最高可用性)。链中的每个模型提供不同的质量-成本-可用性权衡,自动回退确保你的应用即使在部分故障期间也能保持运行。
积极缓存以最小化 API 调用。 如果你的应用重复发送相同或类似的提示词——例如生成产品描述或回答常见问题——实现响应缓存。即使是一个带有几小时 TTL 的简单内存缓存也能减少 30-70% 的 API 调用量,大幅降低你触发速率限制的风险。对于更复杂的缓存,考虑使用 Gemini 内置的上下文缓存功能,它允许你缓存大型输入上下文并在多个请求间复用,成本更低(Gemini 2.5 Flash 缓存输入 $0.03/百万令牌,而常规输入 $0.30/百万令牌)。
监控并告警错误率。 建立跟踪 API 错误频率和类型的日志系统。429 错误突然飙升可能表明 Google 已更改速率限制(如 2025 年 12 月发生的情况)或你的应用使用模式已改变。500/503 错误的飙升通常表明 Google 方面出现故障。没有监控,这些问题可能在数小时内未被发现,同时用户体验到降级的服务。至少,记录每个错误响应的 HTTP 状态码、gRPC 状态、完整错误消息、时间戳和模型名称。
保持 SDK 和模型名称更新。 Gemini API 生态系统演进迅速——模型定期发布、重命名和弃用。使用已弃用的模型名称会导致 404 错误,而使用过时的 SDK 版本可能因不兼容的请求格式导致 400 错误。定期运行 pip install -U google-genai(Python)或 npm update @google/genai(JavaScript),并订阅 Google AI 开发者博客或 Google AI 开发者论坛以获取模型变更的公告。
常见问题 — Gemini API 错误 FAQ
为什么我刚创建 API 密钥就遇到 429 错误?
新 API 密钥继承其 Google Cloud 项目层级的速率限制,而不是单独的密钥配额。如果你在免费层级,Gemini 2.5 Pro 每分钟只允许 5 个请求。如果同一项目中的另一个应用也在发送请求,你们共享该配额。最快的解决方法是在项目上启用计费,这会立即将你升级到 Tier 1,拥有显著更高的限制——这不需要任何付款承诺,几分钟内就会生效。
如何查看我当前的速率限制和使用量?
Google 在 aistudio.google.com/rate-limit 提供实时速率限制仪表板。该仪表板显示你当前的层级、每个模型的限制以及你相对于这些限制的使用量。如果你需要比当前层级提供的更高限制,可以通过官方请求表单提交正式的增加请求,但批准不保证,按具体情况处理。
我可以使用多个 API 密钥来绕过速率限制吗?
不行。速率限制在项目级别执行,而非 API 密钥级别。在同一项目中创建额外的 API 密钥不会增加你的配额。但是,你可以创建独立的 Google Cloud 项目,每个都有自己的计费账户和速率限制,并在它们之间分配请求。这种方法在技术上是有效的,但会增加基础设施的复杂性。
为什么我正常运行的代码在 2025 年 12 月突然开始返回 429 错误?
Google 在 2025 年 12 月 6-7 日的周末将所有模型的免费层级速率限制削减了 50-80%。这些变更未提前宣布,让许多开发者措手不及。如果你的应用运行在之前限制的边缘,这次削减会将你推过新的、更低的阈值。修复方法是减少请求量、升级到付费层级、或实现本指南中描述的重试逻辑。
RPM、TPM 和 RPD 速率限制有什么区别?
RPM(每分钟请求数)计算单个 API 调用的数量。TPM(每分钟令牌数)计算所有请求的总输入令牌。RPD(每日请求数)设定每日最大值,在太平洋时间午夜重置。超出任何一个限制都会触发 429 错误。对大多数应用来说,在免费层级上 RPM 是约束性限制,而 TPM 在发送长提示词或处理文档的应用中成为约束条件。
我应该使用批量 API 来避免速率限制错误吗?
批量 API 异步处理请求,成本降低 50% 且有单独的速率限制(以排队令牌而非 RPM 衡量)。它非常适合不需要实时响应的工作负载,如内容生成、数据处理或评估任务。但是,它对实时应用没有帮助,因为批量请求可能需要几分钟到几小时才能完成。批量处理从 Tier 1 开始可用,是降低大批量工作负载成本的绝佳方式。