
如果 Nano Banana Pro 返回的是 HTTP 503 UNAVAILABLE,最安全的第一步是先信 code 和 status,再看后面的 message。原因很简单:gemini-3-pro-image-preview 这个图片端点,确实出现过「明明是 503,却写着 Deadline expired before operation could complete」的情况。文案看起来像超时,但这并不自动把你送进 504 分支。
这正是很多故障排查文章不够有用的地方。它们要么只说「503 是服务端容量问题」,要么只看到 deadline 就让你调 timeout,却没有帮你足够快地拆清楚矛盾。对这个具体症状来说,第一页真正该完成的任务只有一个:先告诉你现在该重试、该调 timeout,还是该离开 503 页面。
我在 2026 年 4 月 15 日重新核对了 Gemini API troubleshooting、Gemini image generation docs,以及这条精确匹配的官方论坛线程。当前最稳妥的读法仍然是:
- 如果响应真的还是
503 UNAVAILABLE,先按临时容量不足处理,在同一路径上做有界重试。 - 如果响应真的是
504 DEADLINE_EXCEEDED,或者是你自己的 client 先超时,那才是该调 timeout 或减轻负载的分支。 - 如果错误其实是
429、400、403,就不要继续留在这篇 503 页面里叠随机修复动作。
还有一个同样重要的动作:验证时尽量保持 same path。也就是先别同时改模型、改 prompt、改 SDK、改鉴权、改 payload 形状。否则你就无法判断,到底是服务自己恢复了,还是你换了题目。
30 秒先分 503 还是 504
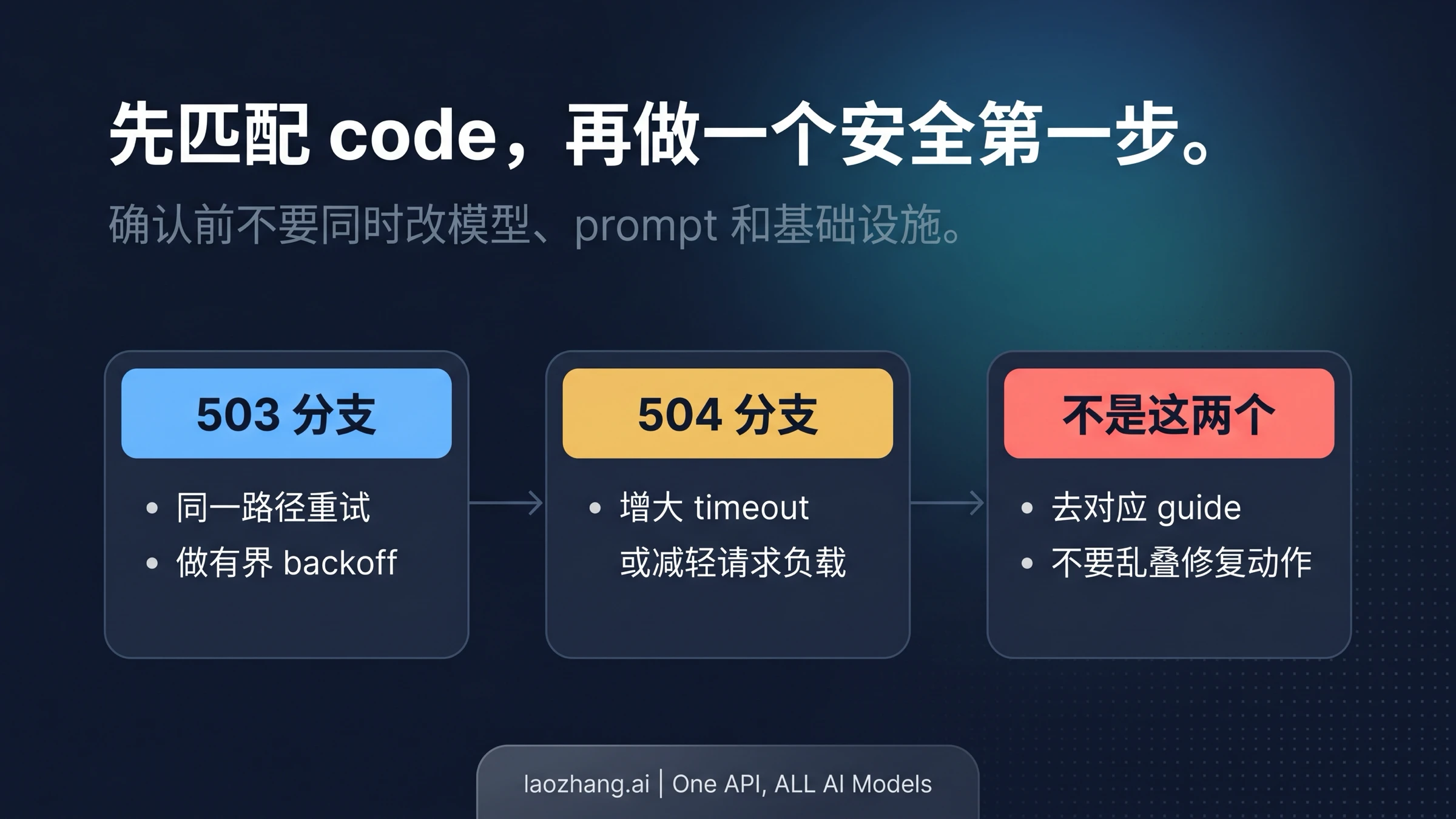
最简单、也最稳定的判断方式就是三步分流:
503 UNAVAILABLE:先按临时容量不足处理,第一反应是重试。504 DEADLINE_EXCEEDED:这是 timeout 预算或请求负载不匹配的分支。429、400、403:这就已经不是这篇页面该负责的错误类了。
这不是拍脑袋的经验法则。Google 当前的 troubleshooting 文档仍然明确区分 503 UNAVAILABLE 和 504 DEADLINE_EXCEEDED,而这篇页的价值就在于把这个官方区分,跟 Nano Banana Pro 的精确报错场景接起来。message 可以帮你认出「你可能遇到的是同一类问题」,但它不该推翻 response class 本身。
如果你现在只想先做一个最快的判断,就做这件事:看 HTTP code,确认 status,然后在同一路径上重试一次,观察它是继续停留在 503,还是已经变成 504,或者干脆翻成了 429 / 400 / 403。这个动作提供的信息量,比先读一大段原理解释更高。
为什么 503 也会写 Deadline expired
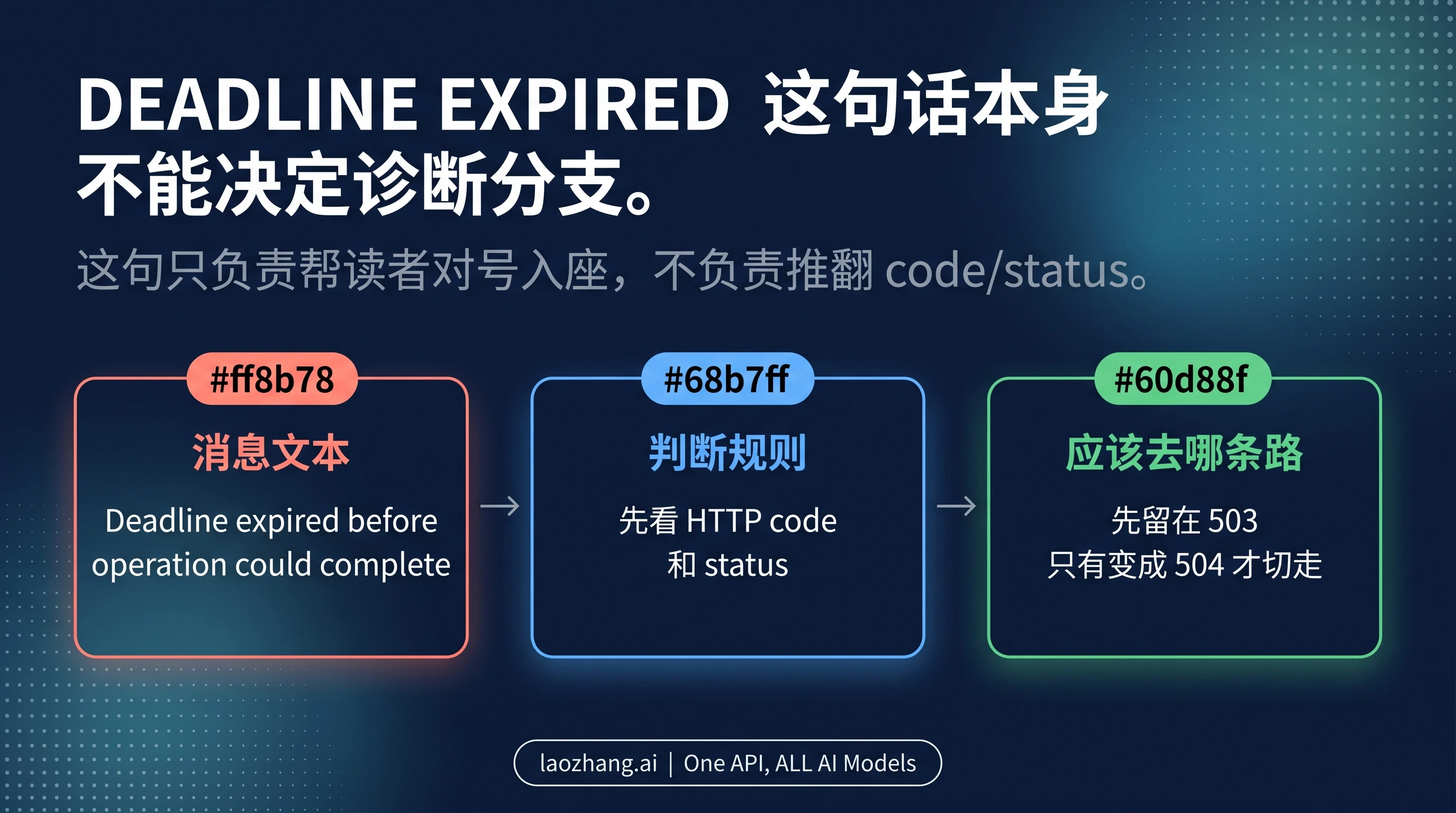
这个症状最容易误导人的地方,就是 message 文案看起来像一个完整的超时诊断。很多人也是先搜这串字面文本,再去找答案。但对这个问题来说,论坛里的精确案例已经足够说明关键事实:Nano Banana Pro 图片端点确实出现过 503 UNAVAILABLE 和 Deadline expired before operation could complete 同时出现的情况。这说明「deadline wording 存在」和「它一定是 504」不是一回事。
真正实用的结论只有一个:把这句 message 当作定位线索,而不是最终诊断。它的作用,是告诉读者这篇文章确实在处理你看到的那种错误;它的作用不是越过 code/status,直接把你送去调 timeout。
这也是为什么第一页必须先做 503 vs 504 分流。如果你一看到 deadline 就先去调 timeout,很可能会在错误的变量上浪费十分钟;而如果你一看到 overloaded 就默认所有失败都是容量问题,也可能错过真实的 timeout 分支。这个页面存在的意义,就是把这两个常见误判都砍掉。
如果它是一个真实的 503 容量故障
当响应还停留在 503 UNAVAILABLE 时,最好的策略不是「立刻大修系统」,而是先做最小的、能验证恢复的动作。
第一步就是在同一路径上做有界 backoff。所谓「同一路径」,指的是尽量保持同一个 model、同一条 API route、同一套鉴权归属,以及大体相同的请求形状。先不要同时改 prompt、改 SDK、改 timeout、换模型。你现在首先要确认的是:这是不是一个会自行恢复的临时容量问题。
一个足够实用的节奏通常就够了:
- 短暂停顿后重试一次。
- 如果还是 503,再把等待时间往上加一点。
- 达到一个有边界的重试次数后,决定是继续等待、排队,还是临时走备用路线。
这里「有界」两个字非常关键。无边界的重试循环会把真正需要换策略的时刻也一起吞掉。有界重试的价值,在于它能帮你分清:这是短暂波动,还是已经该进入排队、延迟执行、或者备用模型方案的情况。
对实时产品来说,下一步要看你的用户到底更在意什么。有些场景可以接受等几十秒再试,有些场景则更适合直接返回一个排队状态,或者临时切到别的图片路线。这个页面不需要给出一个万能 fallback model 才算有用;它真正该做的,是先防止你在错误的故障类型上浪费时间。
还要避免一个常见误判:把 503 当成配额问题。只要它还是 503 UNAVAILABLE,升级 billing、改个人限流策略,都不是你的第一步。只有当错误真的变成 429 RESOURCE_EXHAUSTED,你才该切到速率限制分支。对应内容可以看我们的 Gemini API 速率限制指南 或更广的 Nano Banana Pro 错误码总表。
如果它其实是一个真实的 504 或客户端超时
真正的 timeout 分支,是在响应已经明确变成 504 DEADLINE_EXCEEDED,或者是你自己的 client 先放弃等待的时候才成立。也只有到了这里,timeout tuning 才是合理的第一反应。
这时你解决的已经不是同一个问题了。你不再是在处理「服务端暂时没容量」,而是在处理「当前 timeout 预算和请求负载不匹配」。这两个问题的最优动作完全不同。
在这个分支里,最稳的起手式通常是:
- 把 client timeout 适度调高,
- 在合理范围内减轻请求负载,
- 然后仍然在 same path 上重测。
这里说的「减轻负载」,不一定意味着大改架构。很多时候,它只意味着先用一个稍轻一点的请求形状去证明:问题确实是时间预算,而不是别的东西。你不是要永久牺牲质量,而是先把 timeout 分支坐实。
需要强调的是:不要把 timeout 建议反向套回所有带 deadline 的报错文案。这个页面之所以值得存在,就是因为它先把「词面像 timeout」和「真实属于 timeout 分支」拆开了。
如果你跨多个表层工作,还不能确定自己面对的是纯 API 分支,还是更广的接入/流程问题,那么下一站就应该是更宽的 Nano Banana Pro 故障排查总指南。
一定要在 same path 上验证,再决定要不要换路
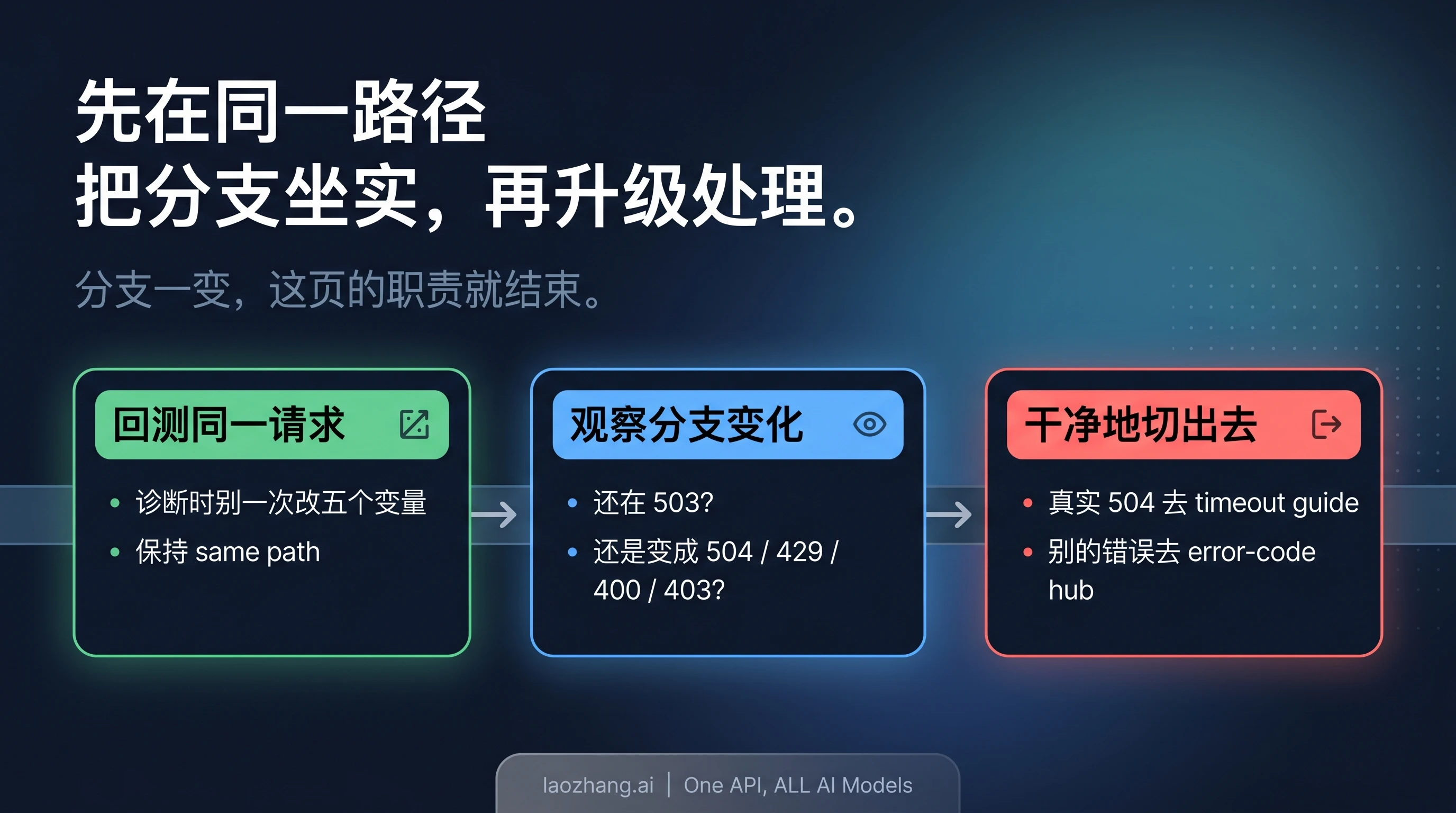
这一步,决定了这篇文章是不是一篇真正有操作价值的 exact-error page。
先在 same path 上回测。也就是先尽量保持同一个 model、同一条 route、同一个 auth owner、同一套 SDK 表层,以及大体相同的 payload 形状。因为只要你同时改了太多变量,哪怕请求成功了,你也不知道到底是哪个变量起了作用。
回测后,真正重要的结果只有三种:
-
它还是
503 UNAVAILABLE。
继续留在 503 容量分支,做有界重试、排队或者明确的 fallback 方案。 -
它变成了
504 DEADLINE_EXCEEDED,或者还是由 client 自己超时。
切到 timeout 分支,不要再留在这篇 exact 503 页面里。 -
它翻成了
429、400、403。
这说明当前诊断边界已经变化,应该离开这篇页,进入对应的 sibling guide。
这条「换路边界」特别重要,因为很多人会在一篇已经不匹配当前错误的页面里继续加修复动作。exact-error page 的价值,恰恰在于它足够窄,知道自己什么时候该结束。
如果错误已经换类,请直接去 Nano Banana Pro 错误码总表。如果你发现自己真正困惑的不是 exact 503,而是当前接入方式、表层差异、或者整体使用路径,可以转去看 Nano Banana Pro 使用指南。
FAQ
只要看到 Deadline expired,就应该先调 timeout 吗?
不是。只有当响应真的是 504 DEADLINE_EXCEEDED,或者确认是 client 自己先超时,timeout 才是正确第一步。只要响应还是 503 UNAVAILABLE,你就应该先按临时容量故障处理。
为什么 503 里会出现 Deadline expired before operation could complete?
因为 message 文案不是完整诊断。官方论坛里已经出现过这个精确组合,所以这句文案可以拿来帮助读者对号入座,但不能拿来推翻 code/status。
这和配额或 rate limit 是一回事吗?
默认不是。配额或 rate limit 属于 429 RESOURCE_EXHAUSTED,不是 503 UNAVAILABLE。如果你的错误已经变成 429,就该切到速率限制分支。
应不应该同时改 prompt、换模型、调 timeout?
不应该。先把分支在 same path 上坐实,再决定要改哪个变量。一次改太多,只会让诊断信号消失。
什么时候该离开这篇页面?
只要错误已经变成真实的 504、client timeout,或者换成了 429 / 400 / 403,这篇页面就完成使命了。exact-error page 的价值就在于不乱扩边界。
这篇文章真正想让你记住的一条规则
当 Nano Banana Pro 返回 503 UNAVAILABLE 时,先信 response code 和 status,再看 message string。即使 message 里出现了 Deadline expired before operation could complete,也不要跳过 503 分支,除非响应本身已经变成 504,或者是你的 client 先超时。
这条规则,能直接帮你避开最常见、也最浪费时间的误修路径。