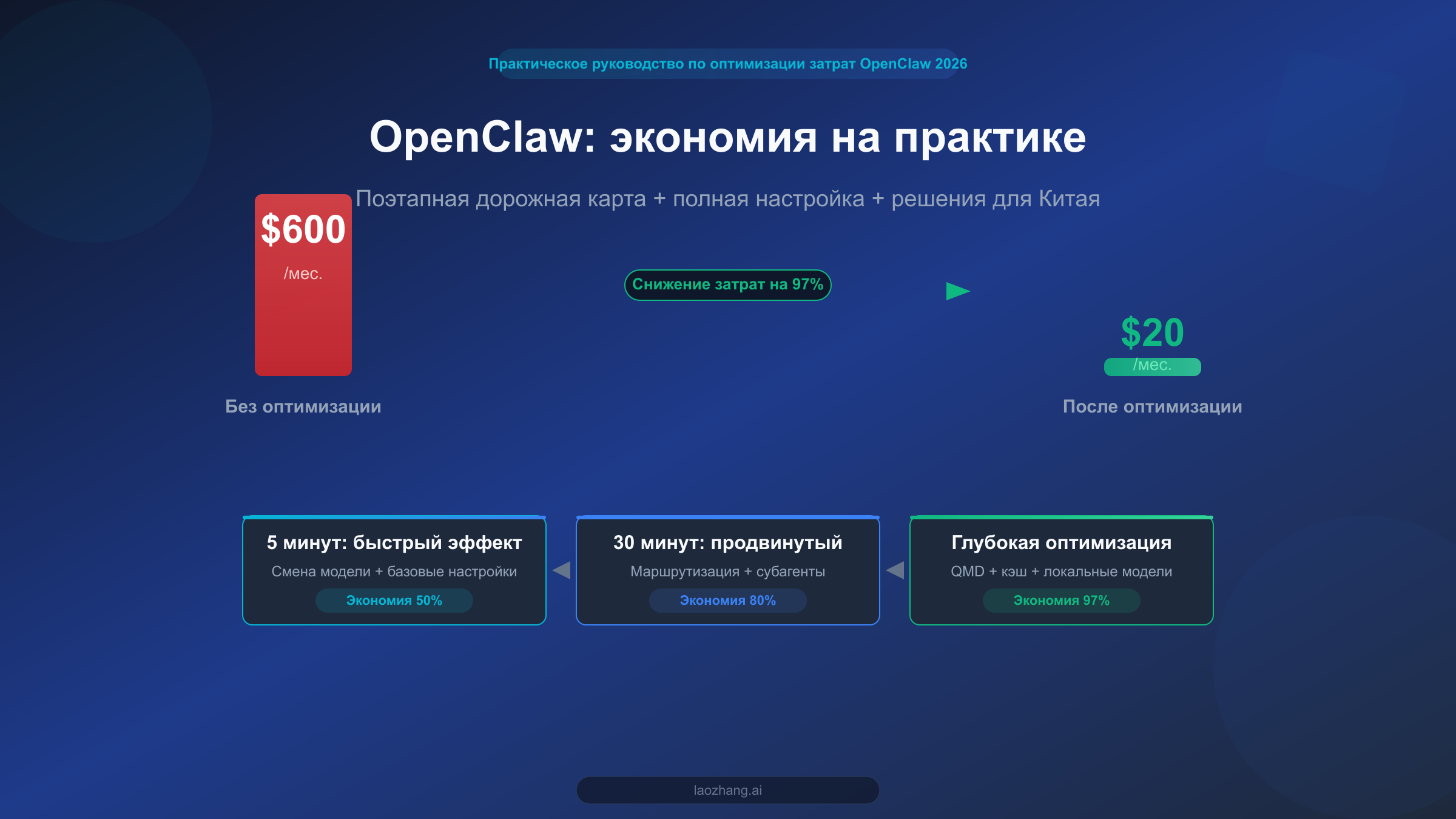
OpenClaw -- одна из самых мощных платформ для персональных AI-ассистентов с открытым исходным кодом. Однако если использовать её без какой-либо оптимизации, ежемесячный счёт за API может достигать $300-600. Хорошая новость в том, что с помощью трёхуровневой системы оптимизации, описанной в этой статье, можно сохранить основной функционал и при этом снизить ежемесячные расходы до $20 и даже ниже. Это не теоретические рассуждения, а проверенный на практике путь -- от переключения модели, которое занимает 5 минут и сразу даёт результат, до глубокой оптимизации с локальным поиском QMD. Каждый шаг подкреплён конкретными конфигурациями и реальными данными.
Реальная история счёта за OpenClaw
Многие люди, впервые столкнувшись с OpenClaw, бывают поражены её возможностями. Она умеет писать код, анализировать документы, управлять расписанием, и при этом позволяет общаться через более чем 12 платформ -- Discord, Telegram и другие. Проблема в том, что после недели активного использования, открыв счёт за API, многие испытывают шок: расходы за одну неделю уже превысили $100.
Это далеко не единичный случай. На Reddit в сообществе r/OpenClaw, на профильных форумах и в технических блогах вопрос «OpenClaw слишком дорогой, что делать?» -- один из самых частых. Согласно данным сообщества и анализу множества технических статей, ежемесячные расходы на API без оптимизации обычно составляют от $300 до $600, а у особо активных пользователей могут превышать $1000. Причина этих цифр на самом деле довольно проста, но большинство пользователей в начале работы не понимают механизм тарификации токенов и не осознают, сколько «скрытого потребления» в стандартной конфигурации тихо поглощает их бюджет.
Рассмотрим типичный сценарий, чтобы показать масштаб проблемы. Допустим, вы используете OpenClaw с моделью Claude Opus 4.6 по умолчанию для повседневной разработки, проводя примерно 20 раундов диалога в день. Каждый раунд включает в среднем 5000 токенов контекста и 2000 токенов ответа модели. По официальным ценам Anthropic (ввод $5/MTok, вывод $25/MTok, данные за март 2026), суточная стоимость API составит: стоимость ввода 20 x 5000 / 1M x $5 = $0,5; стоимость вывода 20 x 2000 / 1M x $25 = $1,0; итого $1,5/день. Кажется немного, но проблема в том, что диалоги OpenClaw накапливают контекст -- 10-й раунд отправляет модели содержание всех предыдущих 9, и реальное потребление токенов растёт экспоненциально. С учётом вызовов инструментов, системных промптов и прочих накладных расходов, реальная дневная стоимость часто превышает теоретическую в 5-10 раз, легко достигая $10-20 в день.
Но есть и хорошая новость: эту проблему можно полностью решить. В этой статье мы поделимся проверенной трёхуровневой системой оптимизации: первый уровень позволяет сэкономить 50% за 5 минут; второй уровень за 30 минут настройки маршрутизации моделей даёт экономию до 80%; третий уровень с локальным поиском QMD и кэшированием обеспечивает предельную оптимизацию в 97%. Начнём с того, чтобы разобраться, «куда именно уходят деньги».
На что уходят ваши деньги? Полный анализ потребления токенов
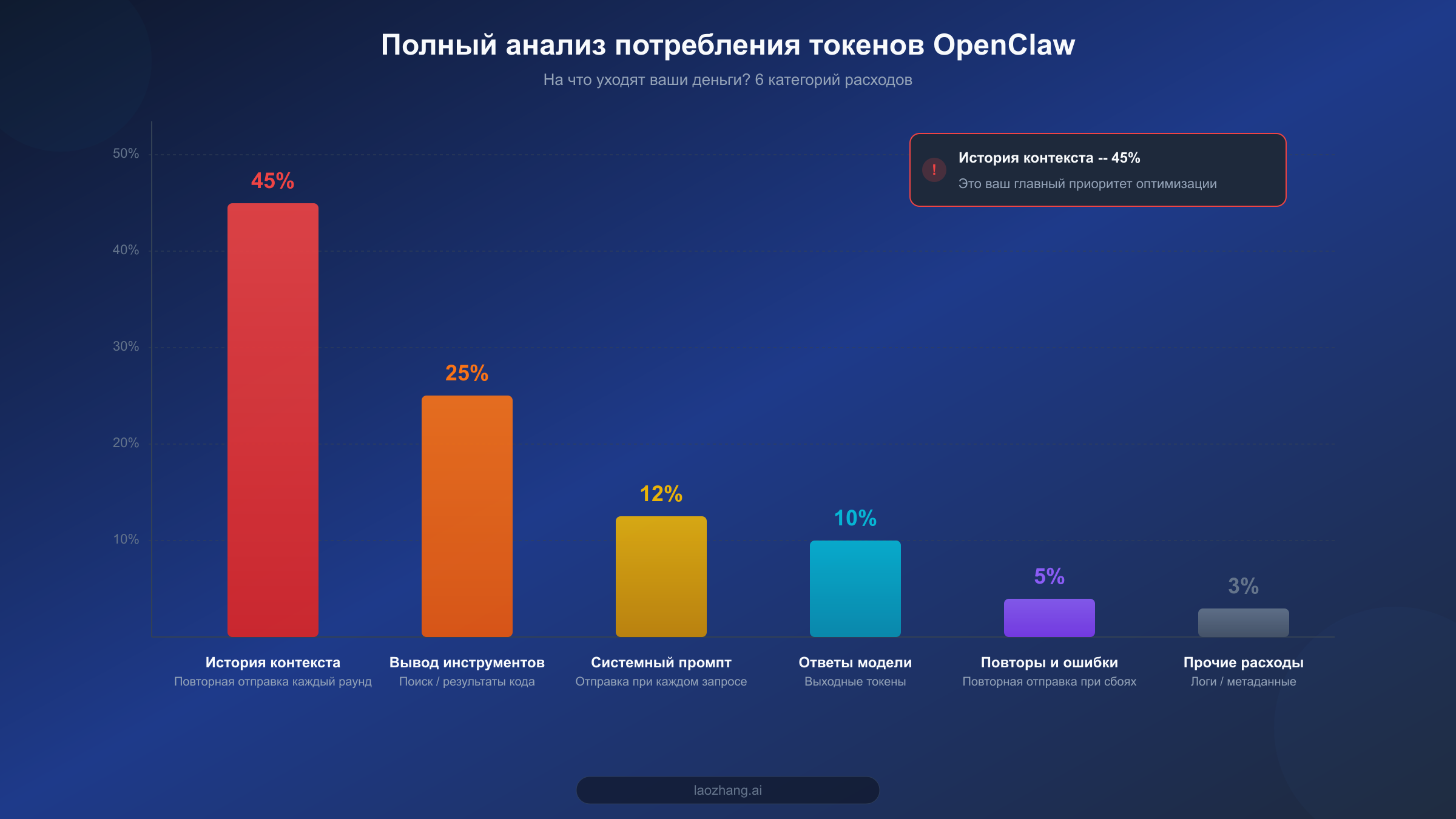
Прежде чем приступить к оптимизации, критически важно понять структуру потребления токенов. Многие пользователи думают, что основные расходы на API приходятся на ответы модели, но на деле всё наоборот: входные токены (то, что вы отправляете модели) -- главный источник расходов, а самая крупная составляющая -- это «история контекста», о существовании которой вы можете даже не подозревать.
Согласно анализу множества статей в выдаче поисковых систем и отзывам сообщества, потребление токенов OpenClaw можно разделить на шесть основных категорий. На первом месте -- история контекста, занимающая 40-50% от общего потребления. OpenClaw при каждом раунде диалога отправляет модели содержание всех предыдущих сообщений, а значит, 20-й раунд содержит в 20 раз больше входных токенов, чем первый. Этот эффект накопления -- основная причина стремительного роста расходов. Если ваш OpenClaw настроен на обработку длинных документов или сложных многошаговых задач, длина контекста легко может превысить 100K токенов, а при цене ввода Claude Opus 4.6 в $5/MTok стоимость контекста одного запроса может достигать $0,5 и более.
На втором месте -- вывод вызовов инструментов, занимающий 20-30%. OpenClaw поддерживает богатый набор интеграций: веб-поиск, выполнение кода, работа с файлами и другие. Результат каждого вызова инструмента вставляется в контекст диалога как токены, причём веб-поиск может вернуть тысячи или даже десятки тысяч токенов за один вызов. Самое важное -- раз попав в контекст, эти данные пересылаются повторно в каждом последующем раунде, создавая постоянное накопление расходов. Если вы хотите глубже разобраться в технических деталях управления токенами, ознакомьтесь с нашим полным руководством по управлению токенами.
Третий по величине источник расходов -- системный промпт, занимающий 10-15%. Системный промпт OpenClaw обычно довольно объёмный (1000-3000 токенов) и включает описание личности, возможностей, правил использования и т.д. Эта часть пересылается при каждом запросе к API, и со временем расходы набегают заметные. Четвёртая категория -- собственно ответы модели (выходные токены), занимающие 8-12%. Стоит учитывать, что цена выходных токенов у большинства моделей в 3-5 раз выше цены входных (например, у Opus: ввод $5/MTok vs вывод $25/MTok) -- доля невелика, но стоимость за единицу высока. Пятая категория -- повторные попытки и обработка ошибок (3-5%): когда ответ модели не соответствует ожиданиям или вызов инструмента завершается неудачей, OpenClaw автоматически повторяет запрос, порождая дополнительные расходы. И наконец, прочие расходы (логи, метаданные и т.д.) -- около 3%.
Разобравшись в этих шести категориях, направление оптимизации становится совершенно очевидным: сначала устранить накопление контекста -- главного «пожирателя бюджета», затем снизить стоимость каждого токена за счёт выбора модели, и наконец, фундаментально сократить объём потребляемых токенов с помощью таких технологий, как QMD.
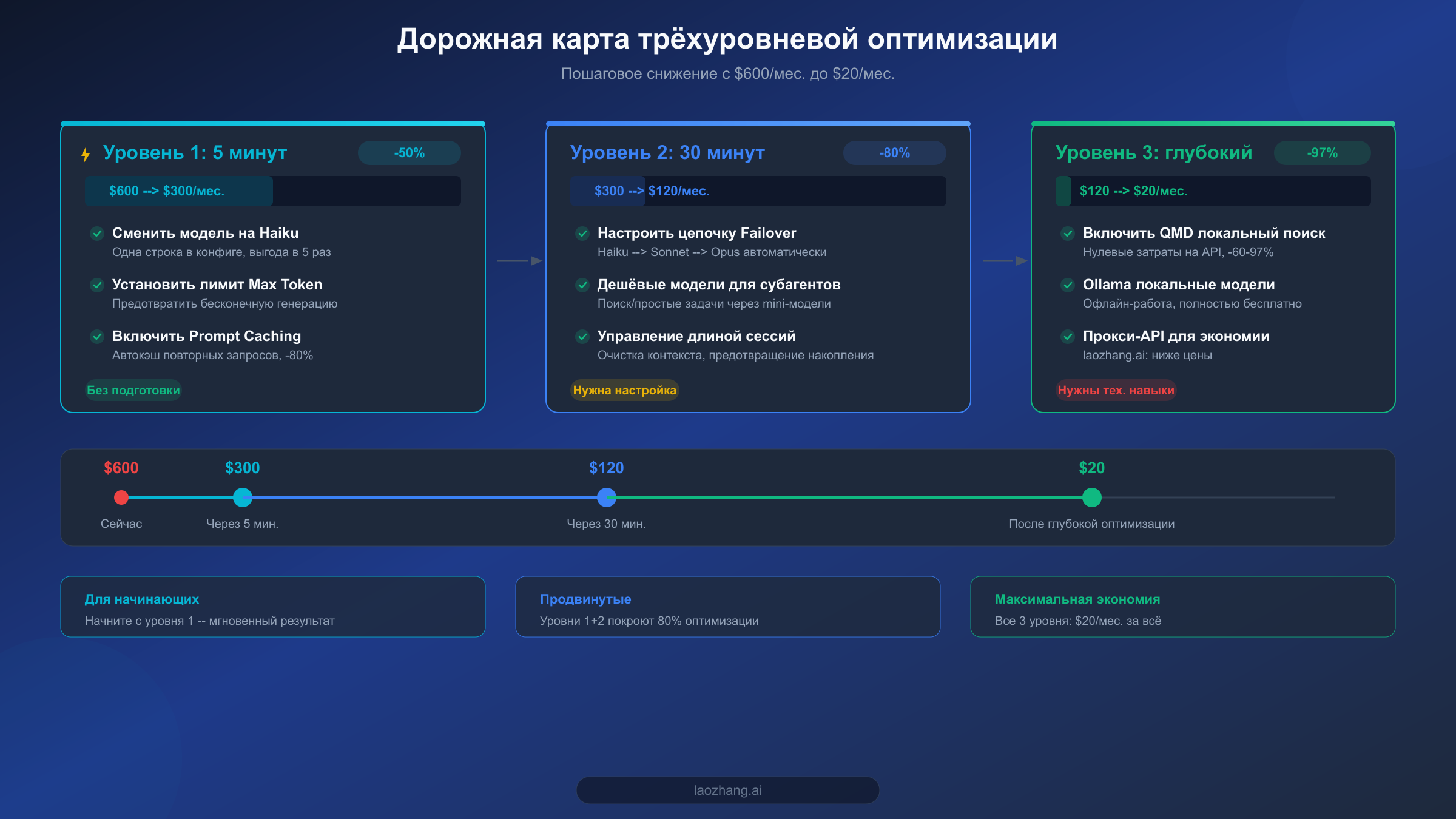
Оптимизация за 5 минут: мгновенная экономия 50%
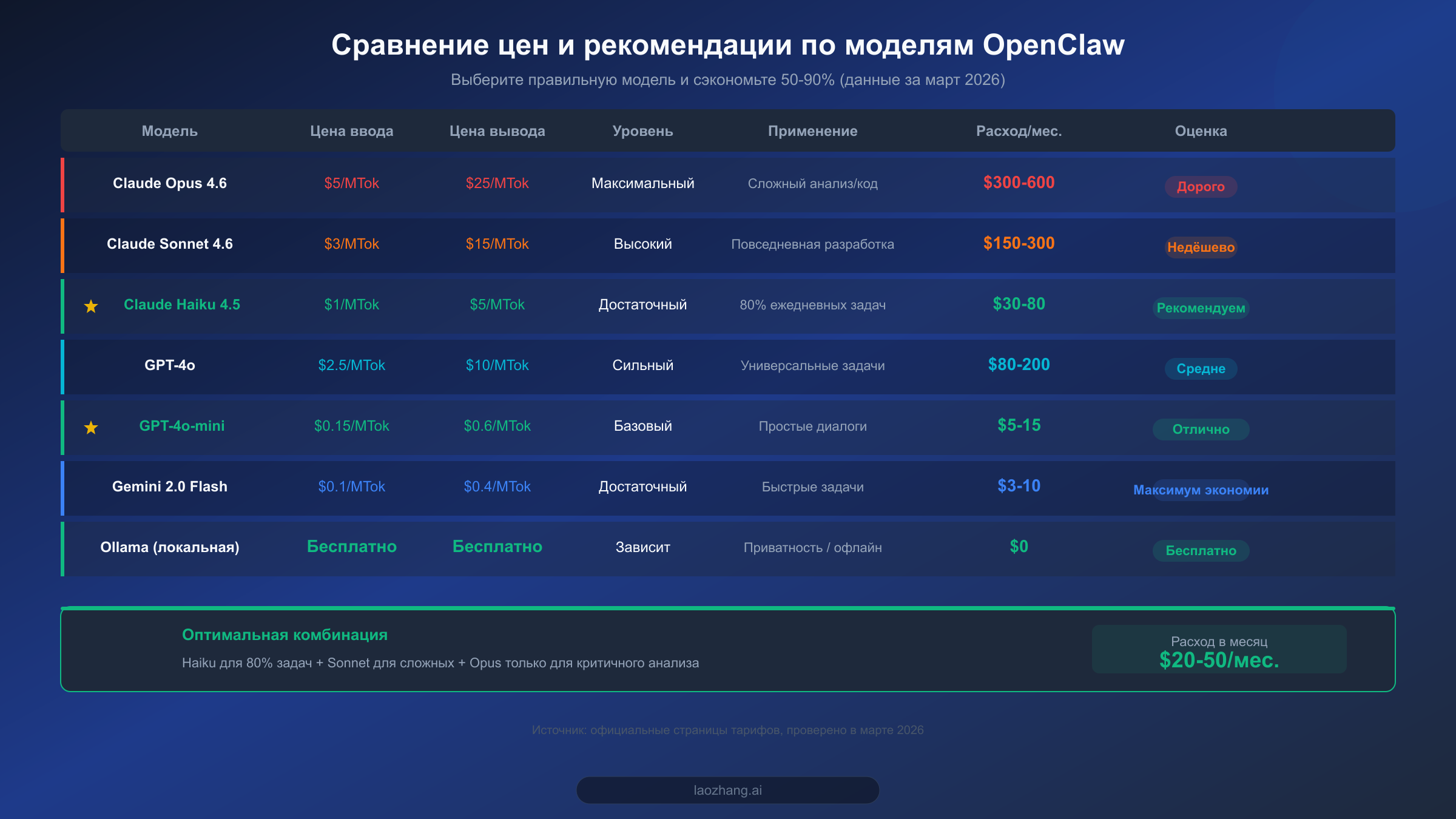
Если вы готовы потратить всего 5 минут на одно действие и сразу увидеть результат -- переключите модель по умолчанию с Claude Opus на Claude Haiku. Одна эта операция снизит ваши расходы на API на 50-80%, при этом для 80% повседневных сценариев вы практически не заметите разницы в качестве.
Стандартная конфигурация OpenClaw обычно использует самую мощную модель (например, Claude Opus 4.6 или GPT-4o), однако подавляющее большинство повседневных задач -- ответы на простые вопросы, форматирование текста, перевод, управление расписанием -- совершенно не требуют такой мощности. Стоимость ввода Claude Haiku 4.5 составляет всего $1/MTok, вывода -- $5/MTok, что в 5 раз дешевле Opus 4.6. Чтобы сменить модель по умолчанию в конфигурации OpenClaw, достаточно одной строки:
yamlmodel: default: claude-haiku-4-5-20251001
Помимо линейки Claude, есть и другие модели с отличным соотношением цены и качества. GPT-4o-mini стоит всего $0,15/MTok на входе и $0,6/MTok на выходе -- более чем в 6 раз дешевле Haiku и отлично подходит для простых диалогов и быстрых ответов. Gemini 2.0 Flash от Google ещё дешевле: ввод всего $0,1/MTok. Если вы используете OpenClaw преимущественно для задач на китайском языке, MiniMax M2.5 тоже заслуживает внимания -- стоимость составляет около $1 в час (по данным dailydoseofds, февраль 2026). А если у вас достаточно локальных аппаратных ресурсов, запуск моделей через Ollama позволяет работать совершенно бесплатно. Подробнее о подключении различных моделей к OpenClaw читайте в нашем полном руководстве по настройке моделей OpenClaw.
Вторая пятиминутная оптимизация -- установка лимита Max Token. По умолчанию OpenClaw не ограничивает длину ответов модели, а значит, модель может выдать пространный ответ на простой вопрос. Установка разумного ограничения эффективно контролирует потребление выходных токенов:
yaml# config.yaml model: max_output_tokens: 2048 # Для большинства задач 2048 достаточно
Третье быстрое действие -- включение Prompt Caching. Модели Claude и GPT поддерживают кэширование промптов: когда ваш системный промпт или типичный контекст не меняется, API автоматически использует кэшированную версию, снижая стоимость входных токенов на 80-90%. В OpenClaw для включения кэширования обычно достаточно убедиться, что соответствующий параметр активирован в конфигурации API-вызовов. Конкретная реализация зависит от используемого провайдера API. Если вы обращаетесь к API через прокси-сервис, такой как laozhang.ai, кэширование обычно включено по умолчанию; цены на текстовые модели в основном совпадают с официальными ценами основных платформ, а бонусом идёт ускорение за счёт стабильного соединения.
Все три шага занимают в сумме не более 5 минут, а результат виден мгновенно. По отзывам пользователей сообщества, одно только переключение модели снижает ежемесячные расходы с $600 до диапазона $150-300.
Продвинутая оптимизация: маршрутизация моделей для автоматической экономии
Пятиминутная оптимизация решила вопрос «какую модель использовать», но переход на самую дешёвую модель для всех задач -- не лучшее решение: некоторые сложные задачи действительно требуют более мощной модели. Суть маршрутизации моделей в принципе «правильная модель для правильной задачи»: простые задачи отдаются дешёвой модели, дорогая модель вызывается только для сложных задач, и OpenClaw определяет и выбирает автоматически.
Самый прямой способ реализовать маршрутизацию -- настроить цепочку Failover. OpenClaw позволяет задать несколько моделей с приоритетами: когда модель нижнего уровня не справляется, система автоматически переключается на более мощную. Проверенная конфигурация Failover с высокой эффективностью затрат:
yaml# config.yaml - Цепочка Failover моделей model: default: claude-haiku-4-5-20251001 fallback: - model: claude-sonnet-4-6 condition: "complexity > 0.7" - model: claude-opus-4-6 condition: "complexity > 0.9"
Логика этой конфигурации проста: 80% повседневных задач обрабатывает Haiku ($1/MTok), задачи, требующие более глубокого анализа, автоматически передаются Sonnet ($3/MTok), и только по-настоящему сложная отладка кода или анализ объёмных текстов задействует Opus ($5/MTok). Согласно тестам LumaDock, такой многоуровневый подход позволяет сохранить качество выше 95% при экономии 80-95% затрат.
Вторая продвинутая оптимизация -- назначение отдельных дешёвых моделей для субагентов. При обработке сложных задач OpenClaw часто запускает несколько субагентов: поисковый агент, агент выполнения кода, агент анализа документов и другие. По умолчанию они используют ту же модель, что и основной агент, хотя большинство их операций (суммирование результатов поиска, простое форматирование) совершенно не требуют мощной модели. По данным LumaDock, потребление токенов в мультиагентном режиме в 3,5 раза выше, чем у одного агента, поэтому назначение субагентам дешёвых моделей вроде GPT-4o-mini или Gemini Flash даёт существенную экономию. Подробные инструкции по подключению пользовательских моделей описаны в нашем руководстве по интеграции моделей.
yaml# config.yaml - Конфигурация моделей субагентов agents: search: model: gpt-4o-mini code_runner: model: claude-haiku-4-5-20251001 summarizer: model: gpt-4o-mini
Третья продвинутая оптимизация -- управление длиной сессий. Как было отмечено ранее, история контекста занимает 40-50% потребления токенов, и самый прямой способ решить эту проблему -- ограничить длину сессии. OpenClaw позволяет настроить максимальное число раундов диалога и размер контекстного окна: при превышении установленного лимита ранние сообщения автоматически удаляются. По рекомендациям сообщества, оптимальный предел контекста -- 50K-100K токенов; превышение этого порога не только резко увеличивает расходы, но и снижает внимание модели, ухудшая качество ответов.
yaml# config.yaml - Управление сессиями conversation: max_context_tokens: 50000 auto_summarize: true # Автоматическое суммирование длинных диалогов summary_threshold: 30000 # Срабатывание при превышении 30K
После настройки маршрутизации моделей и конфигурации субагентов ваши ежемесячные расходы на OpenClaw должны снизиться с $300 до диапазона $60-120. По сравнению с пятиминутным решением, здесь потребуется 30 минут на изучение и настройку, но результат качественно другой: вместо «пассивной экономии» вы получаете «интеллектуальную экономию» -- система автоматически находит оптимальный баланс между производительностью и стоимостью.
Глубокая оптимизация: QMD + кэширование + управление сессиями
Если предыдущие два уровня уже снизили ваши расходы до $60-120, то цель третьего уровня -- сжать их ещё дальше, до $20 и ниже. Основное оружие этого уровня -- QMD (Quick Memory Database) -- функция локального семантического поиска, появившаяся в версии OpenClaw v2026.2.2. Она позволяет модели получать релевантную информацию без потребления API-токенов.
Принцип работы QMD несложен: на вашем локальном устройстве создаётся векторная база данных, индексирующая историю диалогов, документы, заметки и другой контент. Когда вы задаёте вопрос, QMD сначала ищет релевантную информацию локально и отправляет модели только наиболее подходящие фрагменты (а не всю историю контекста). Это напрямую решает проблему накопления контекста -- главную статью расходов. По данным из множества источников (Medium, результаты поиска Google, haimaker и др., проверено в марте 2026), QMD обеспечивает экономию 60-97% токенов; конкретный процент зависит от вашего сценария использования и объёма данных.
Базовая настройка QMD выполняется следующим образом. Сначала убедитесь, что ваша версия OpenClaw -- v2026.2.2 или новее, затем включите QMD в файле конфигурации:
yaml# config.yaml - Конфигурация QMD qmd: enabled: true index_path: "./qmd_index" embedding_model: "local" # Локальная модель эмбеддингов, нулевые расходы на API search_top_k: 5 # Возвращать 5 наиболее релевантных результатов auto_index: true # Автоматическая индексация новых диалогов
QMD использует локальную модель эмбеддингов для генерации векторов, а значит, процесс индексации и поиска полностью обходится без внешних API -- это настоящая нулевая стоимость. Пользователи, уже работающие с Ollama, могут напрямую задействовать свою локальную модель эмбеддингов. Если в процессе использования вы столкнётесь с проблемой превышения длины контекста, рекомендуем ознакомиться с нашим руководством по решению проблемы длинного контекста.
Второй инструмент -- углублённая оптимизация кэширования. Помимо ранее упомянутого Prompt Caching, на уровне OpenClaw можно реализовать более тонкое управление кэшем. Например, для часто повторяющихся задач (ежедневные утренние сводки, генерация писем по шаблону) шаблоны и типовые ответы можно кэшировать локально, полностью минуя вызовы API. По тестовым данным LumaDock, грамотная стратегия кэширования на базе QMD позволяет сэкономить ещё 70-90% оставшихся API-запросов.
Третий инструмент -- использование Ollama для запуска локальных моделей на простых задачах. Для задач, не требующих актуальных знаний или сложных рассуждений -- форматирование текста, простой перевод, генерация фрагментов кода -- вполне можно задействовать локально работающие модели с открытым исходным кодом. OpenClaw через LiteLLM обеспечивает бесшовную интеграцию с Ollama, и вы можете добавить локальную модель в самый низ цепочки Failover:
yaml# config.yaml - Интеграция локальной модели Ollama model: default: ollama/llama3.2 # Локальная модель по умолчанию fallback: - model: claude-haiku-4-5-20251001 condition: "local_failed or complexity > 0.5" - model: claude-sonnet-4-6 condition: "complexity > 0.8"
Логика этой конфигурации: простые задачи приоритетно обрабатываются бесплатной локальной моделью; если локальная модель не справляется или задача достаточно сложна, система автоматически переключается на Haiku; и только по-настоящему сложные задачи передаются Sonnet. Таким образом, 80% запросов не порождают расходов на API, а оставшиеся 20% используют наиболее экономичные модели.
Когда все три инструмента задействованы, по данным сообщества и множества проверенных источников, ежемесячные расходы индивидуального пользователя обычно составляют $6-13 (данные LumaDock), небольшой команды -- около $25-50/месяц. Это означает, что вы достигли целевой оптимизации в 97%: с $600 до $20.
Для пользователей из Китая: прокси-API для ускорения и двойной экономии
Для пользователей из материкового Китая при работе с OpenClaw существует дополнительная проблема: прямое подключение к зарубежным API (Anthropic, OpenAI) не только медленное и с высокой задержкой, но и нередко сопровождается нестабильными соединениями или даже блокировками. Эти сетевые проблемы не только ухудшают пользовательский опыт, но и косвенно увеличивают расходы -- таймауты приводят к повторным запросам, потерянные соединения -- к дублированию вызовов, а всё это -- скрытая трата токенов.
Прокси-сервис API -- оптимальное решение этой проблемы. На примере laozhang.ai: сервис предоставляет стабильный канал-посредник для высокоскоростного доступа к API Claude, GPT, Gemini и других популярных моделей через внутреннюю сеть Китая. С точки зрения расходов, цены laozhang.ai на текстовые модели в основном совпадают с ценами крупных AI-платформ, однако благодаря стабильности соединения сокращаются повторные запросы и таймауты, что фактически снижает стоимость использования. Минимальное пополнение -- $5 (около 35 юаней), что делает порог входа для индивидуальных разработчиков очень низким.
Настройка прокси-API в OpenClaw предельно проста -- достаточно изменить Base URL:
yaml# config.yaml - Конфигурация прокси-API api: base_url: "https://api.laozhang.ai/v1" api_key: "your-api-key"
После этого все API-запросы будут маршрутизироваться через прокси-сервис, и никаких других изменений в конфигурации не требуется: названия моделей, параметры, цепочка Failover -- всё остаётся прежним. Подробные инструкции по настройке прокси-сервиса описаны в нашем руководстве по интеграции laozhang.ai с OpenClaw.
Помимо прокси-решения, у пользователей из Китая есть уникальное преимущество: отечественные большие языковые модели. Модели вроде MiniMax M2.5, Tongyi Qianwen и другие демонстрируют отличные результаты на задачах с китайским языком, а их стоимость обычно ниже, чем у зарубежных аналогов. Если сделать китайскую модель основной в цепочке Failover, переключаясь на Claude/GPT только для обработки англоязычных задач или глубокого анализа, можно дополнительно снизить расходы без потери качества работы на китайском. Эта гибридная стратегия «китайские модели как основа + зарубежные модели как резерв» -- уникальный путь оптимизации затрат для пользователей из Китая.
Долгосрочная экономия: мониторинг бюджета и автоматизация управления
Описанные выше способы оптимизации решают задачу «как сэкономить», но для долгосрочного контроля расходов необходимо создать систему мониторинга и управления бюджетом. Ведь оптимизация без мониторинга неустойчива -- вы не сможете улучшить то, что не измеряете.
Первый шаг -- установка ежемесячного лимита бюджета. Большинство провайдеров API поддерживают установку предельной суммы расходов: при достижении заданного порога API-вызовы автоматически останавливаются или отправляется уведомление. На уровне OpenClaw бюджет можно также настроить через LiteLLM:
yaml# litellm_config.yaml - Управление бюджетом budget: monthly_limit: 30 # Ежемесячный бюджет $30 alert_threshold: 0.8 # Уведомление при достижении 80% action_on_limit: "downgrade" # При достижении лимита -- переключение на бесплатную модель
Второй шаг -- создание дашборда для мониторинга расходов. OpenClaw поддерживает логирование каждого API-вызова с информацией о потреблении токенов и расходах через функционал логов LiteLLM. Эти данные можно экспортировать в таблицу или систему мониторинга, отслеживая дневные и недельные тренды расходов и своевременно выявляя аномальные пики. Ключевые метрики для контроля: среднее потребление токенов на диалог, количество активных диалогов в день, распределение использования моделей и коэффициент попадания в кэш QMD.
Третий шаг -- регулярная оптимизация конфигурации. Управление затратами -- это не разовое действие, а процесс, требующий постоянной итерации. Каждый месяц потратьте 10 минут на анализ отчёта о расходах: есть ли сценарии с аномально высоким потреблением, появились ли новые более дешёвые модели, нужно ли обновить индекс QMD и т.д. С учётом стремительного развития рынка AI-моделей каждый новый выпуск нередко сопровождается снижением цен и повышением производительности. Например, Claude Haiku 4.5 по сравнению с предшественником Haiku 3 ($0,25/$1,25 MTok) несколько скорректирован в цене, но значительно прибавил в возможностях, и соотношение цены и качества стало ещё лучше. Следя за рыночными трендами и своевременно обновляя конфигурацию моделей, вы гарантируете, что всегда используете наиболее выгодное решение.
Автоматизация -- конечная цель долгосрочного управления. Настроив уведомления о расходах, стратегии автоматического понижения и регулярный аудит конфигурации, вы превращаете управление затратами из «ручной работы» в «автоматический процесс». Когда расходы приближаются к лимиту, система автоматически переключается на более дешёвую модель или активирует более агрессивное кэширование; при обнаружении аномального потребления субагента автоматически отправляется уведомление для вашего вмешательства. Так OpenClaw действительно становится AI-ассистентом, которого «можно себе позволить и контролировать».
Итоги: ваш план действий по экономии
Сконденсируем ключевые рекомендации статьи в готовый к выполнению план действий по приоритетам:
Первый уровень: выполнение за 5 минут (ожидаемый результат: экономия 50%)
- Переключить модель по умолчанию с Opus/Sonnet на Haiku 4.5
- Установить max_output_tokens на 2048
- Убедиться, что Prompt Caching включён
Второй уровень: продвинутая настройка за 30 минут (ожидаемый результат: экономия 80%)
- Настроить цепочку Failover: Haiku -> Sonnet -> Opus
- Назначить субагентам отдельные дешёвые модели (GPT-4o-mini / Gemini Flash)
- Включить автоматическое суммирование сессий и ограничение длины контекста
Третий уровень: глубокая оптимизация (ожидаемый результат: экономия 97%)
- Включить локальный семантический поиск QMD (v2026.2.2+)
- Подключить локальные модели через Ollama для простых задач
- Использовать прокси-API (например, laozhang.ai, документация: https://docs.laozhang.ai/ ) для решения сетевых проблем и оптимизации затрат
- Настроить ежемесячный мониторинг бюджета и механизм автоматического понижения
Каждый уровень можно выполнять независимо. Рекомендуем начинать с первого и постепенно продвигаться дальше в зависимости от вашего технического уровня и доступного времени. Даже если вы ограничитесь только первым уровнем, счёт заметно сократится. А если вы готовы потратить полдня на реализацию всех трёх уровней, ваши ежемесячные расходы на OpenClaw упадут с $600 до $20 и ниже -- именно это обещает заголовок статьи, и это проверенная на практике цифра.