Настройка моделей OpenClaw больше не является фиксированным списком "12 providers". По состоянию на 8 мая 2026 года текущий контракт такой: выберите provider surface, пройдите auth для этого provider, задайте модель как provider/model, проверьте её командами OpenClaw models и используйте models.providers только когда нужно переопределить встроенный provider, добавить custom base URL или описать proxy/local model, которую OpenClaw не может обнаружить сам.
Практический вопрос не "какая модель лучше", а "какой route владеет auth, rate limits, context behavior, cache behavior и fallback". Anthropic API keys, Claude CLI/OAuth-style routes, OpenAI/Codex, Google Gemini, Bedrock, Ollama, LM Studio, OpenRouter, Vercel AI Gateway и custom proxies выглядят похоже после настройки, но ломаются в разных местах. Это руководство начинает с этого разделения маршрутов.
Что такое OpenClaw и почему выбор LLM имеет значение
OpenClaw — это self-hosted agent Gateway, который соединяет chat surfaces, Control UI, tools, skills, local execution и model providers. В отличие от простой чат-обёртки, OpenClaw позволяет выбранной модели работать через tools, files, shell commands, browser flows, memory, channels и plugins. Поэтому выбор provider — это системное решение, а не вопрос вкуса.
Настроенный provider определяет пять вещей: model catalog, credential storage, request transport, rate-limit owner и какие provider-specific request features OpenClaw может безопасно отправлять. Direct Anthropic route может использовать Anthropic-specific params вроде prompt caching и explicit 1M-context beta, если credential подходит. Bedrock route использует AWS SDK credential chain и Bedrock Converse streaming, а не Anthropic API key. Custom OpenAI-compatible proxy нельзя считать native OpenAI, потому что OpenClaw намеренно пропускает native-only request shaping на non-native endpoints.
Начните с текущей карты:
| Route | Best use | Setup owner | Model ref pattern | Что проверить |
|---|---|---|---|---|
| Direct Anthropic | Claude-first coding, long context when eligible | openclaw onboard или Anthropic provider auth | anthropic/claude-opus-4-6 | API key/profile, cacheRetention, optional params.context1m |
| OpenAI / Codex | GPT или Codex workflows | API key или OAuth route | openai/... или openai-codex/... | Native vs proxy endpoint, entitlement, model catalog |
| Google Gemini | Gemini API key или Gemini CLI route | Google provider auth | google/... или google-gemini-cli/... | API key/OAuth account, project env, model normalization |
| Amazon Bedrock | Enterprise AWS controls and IAM | AWS SDK credential chain | amazon-bedrock/<model-id> | Region, model access, ListFoundationModels, ListInferenceProfiles |
| Local runtime | Privacy, offline tests, cheap fallback | Ollama/LM Studio/vLLM provider | ollama/..., lmstudio/... или custom | Local server, context cap, timeout, model memory fit |
| Custom proxy | Regional access, gateway pricing, private relay | models.providers.<id> | <custom-id>/<model-id> | Base URL, API shape, explicit model metadata, unsupported native params |
Дальше руководство сохраняет практические walkthroughs, но первое правило стало строже: не копируйте февральский provider list или price table в production planning. Сначала пройдите onboarding или проверьте актуальные provider docs, затем подтвердите resolved model с хоста, где работает Gateway.
Как выбрать подходящего провайдера LLM
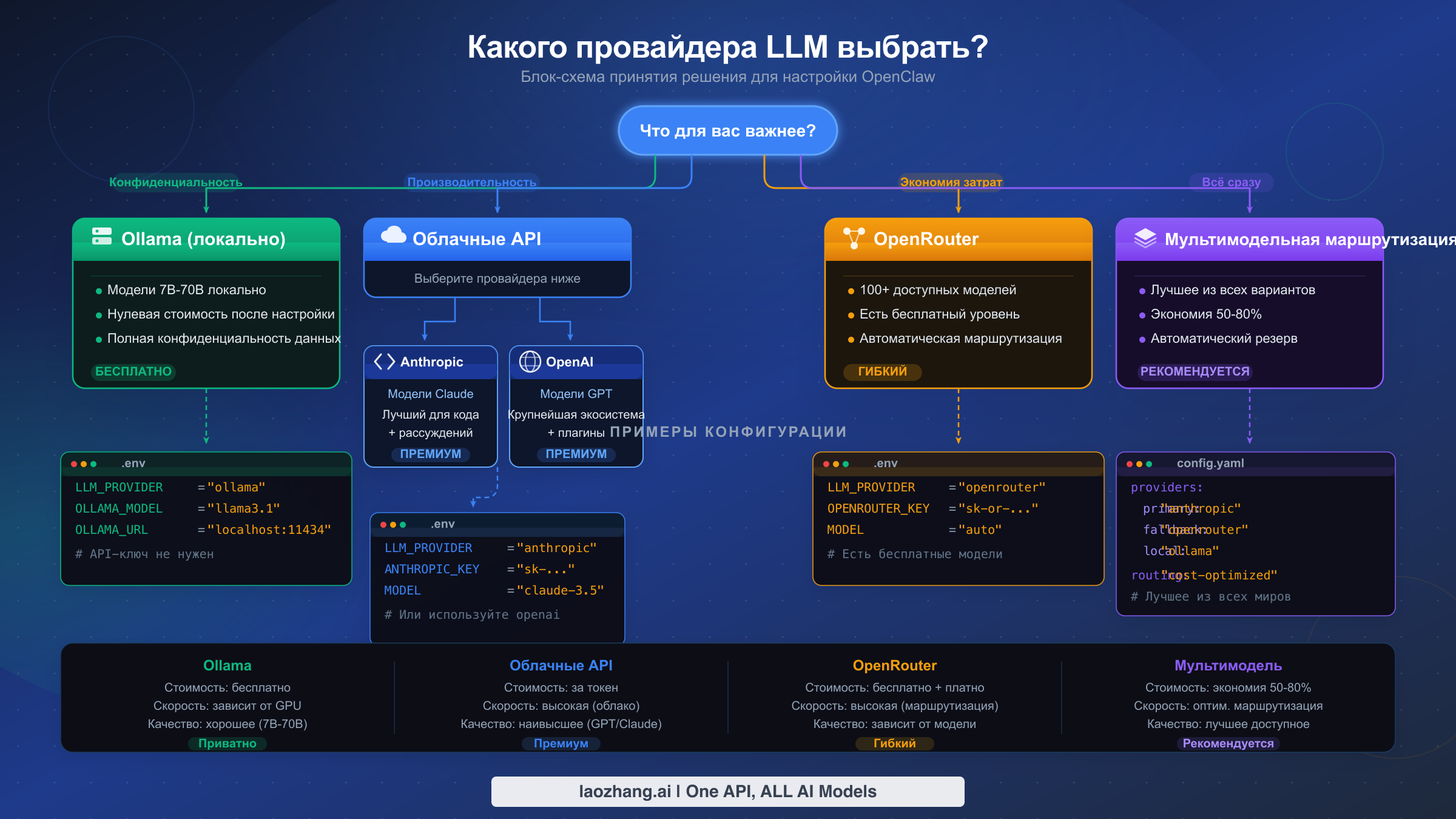
Выбор правильного провайдера LLM для OpenClaw зависит от четырёх факторов: вашего бюджета, оборудования, требований к конфиденциальности и сложности задач, которые вы планируете выполнять. Вместо того чтобы перечислять каждого провайдера и оставлять вас разбираться самостоятельно, этот раздел предлагает конкретный путь принятия решения, основанный на том, что для вас важнее всего. Блок-схема выше обобщает четыре основных пути, а таблица решений ниже сопоставляет типичные сценарии с конкретными рекомендациями.
| Priority | Recommended route | First model test | Setup difficulty | Main risk |
|---|---|---|---|---|
| Privacy + local control | Ollama или LM Studio | Small coding model that fits RAM | Средняя | Weak model or local timeout |
| Best Claude workflow | Direct Anthropic | anthropic/claude-opus-4-6 или current Sonnet | Лёгкая | API key eligibility, rate limits, 1M-context beta access |
| OpenAI/Codex workflow | Native OpenAI или OpenAI Codex route | Current entitled GPT/Codex model | Средняя | Confusing native endpoint with proxy endpoint |
| Cloud enterprise controls | Amazon Bedrock | amazon-bedrock/... Claude profile/model | Сложная | AWS region/model access/IAM permissions |
| Regional or gateway access | OpenAI/Anthropic-compatible proxy | Provider-owned model id | Средняя | Missing metadata, unsupported headers, wrong API shape |
Если конфиденциальность — главный приоритет, начните с local runtime вроде Ollama или LM Studio. Решение не в том, free это или paid; важно, может ли модель надёжно следовать tool calls для agent job. Используйте local models для private drafts, simple file edits и offline fallback. Переходите на более сильный cloud route, когда нужны deep multi-file reasoning, long context или высокая tool-call reliability.
Если вам нужен лучший Claude workflow, используйте direct Anthropic provider или sanctioned Claude CLI/OAuth route, описанный в текущих docs OpenClaw. Так Anthropic-specific behavior, prompt caching и optional long-context settings остаются на маршруте, который действительно их понимает. Если нужны AWS controls, используйте Bedrock и принимайте другой request surface.
Если вам нужна cloud flexibility, сначала поймите разницу между native и proxy-style. OpenClaw пропускает native-only OpenAI request shaping на non-native endpoints и подавляет implicit Anthropic beta headers на non-direct Anthropic-compatible endpoints. Это защищает многие setups, но не означает, что каждый native feature переживёт proxy hop.
Если нужна максимальная устойчивость, комбинируйте один надёжный default model с небольшим fallback chain. Fallback chain не является автоматической экономией; обычно он срабатывает, когда primary route fails или unavailable. Для deliberate cost routing переключайте models явно или создавайте отдельных agents с разными defaults.
Настройка локальных моделей с помощью Ollama
Ollama — это самая популярная локальная среда выполнения LLM для OpenClaw, и на то есть веские причины: она бесплатна, хранит все данные на вашей машине и не требует API-ключей. Процесс настройки состоит из трёх этапов — установка Ollama, загрузка модели и подключение к OpenClaw. Весь процесс занимает менее десяти минут на современной машине с приличным интернет-подключением.
Установка Ollama проста на всех трёх основных платформах. На macOS можно загрузить установщик с ollama.com или использовать Homebrew. На Linux официальный установочный скрипт справляется со всем автоматически. На Windows Ollama теперь предоставляет нативный установщик.
bashbrew install ollama # Linux (official script) curl -fsSL https://ollama.com/install.sh | sh # Windows: download from ollama.com/download
После установки запустите сервер Ollama. На macOS и Windows десктопное приложение запускает его автоматически. На Linux может потребоваться запустить сервис вручную командой ollama serve. По умолчанию сервер слушает на http://127.0.0.1:11434 — это эндпоинт, к которому OpenClaw будет подключаться.
Выбор правильной модели полностью зависит от доступной оперативной памяти. Именно здесь большинство пользователей совершают первую ошибку: они пытаются загрузить модель с 70 миллиардами параметров на ноутбуке с 16 ГБ памяти и удивляются, почему всё зависает. Правило такое: вам нужно примерно 1 ГБ оперативной памяти на миллиард параметров для квантизированных моделей, плюс запас для операционной системы и самого OpenClaw.
| Доступная ОЗУ | Рекомендуемая модель | Параметры | Ожидаемая скорость | Применение |
|---|---|---|---|---|
| 8 ГБ | qwen2.5-coder:3b | 3B | 25-35 ток/с | Лёгкое редактирование, простые скрипты |
| 16 ГБ | qwen2.5-coder:7b | 7B | 15-20 ток/с | Работа с одним файлом, отладка |
| 32 ГБ | deepseek-coder-v2:16b | 16B | 12-18 ток/с | Многофайловые задачи, умеренные рассуждения |
| 64 ГБ+ | deepseek-coder-v2:33b | 33B | 10-15 ток/с | Сложный рефакторинг, архитектура |
Загрузите выбранную модель одной командой:
bash# For 16GB machines (most common) ollama pull qwen2.5-coder:7b # Verify the model is available ollama list
Подключение Ollama к OpenClaw происходит через мастер настройки. Запустите openclaw onboard и выберите Ollama в качестве провайдера. Мастер обнаружит модели, которые вы уже загрузили, и позволит выбрать нужную. Под капотом он записывает конфигурацию в файл настроек OpenClaw с ключом agents.defaults.model.primary.
bash# Start the setup wizard openclaw onboard # Or configure manually via CLI openclaw models set ollama/qwen2.5-coder:7b
Если вы предпочитаете настроить всё вручную, ключевая переменная окружения — OLLAMA_API_KEY. Несмотря на название, Ollama фактически не требует аутентификации — установите любую непустую строку вроде ollama-local, чтобы пройти валидацию OpenClaw:
bashexport OLLAMA_API_KEY="ollama-local"
Важная деталь из официальной документации: потоковая передача (streaming) для Ollama по умолчанию отключена в OpenClaw. Это означает, что вы увидите полный ответ сразу, а не токен за токеном. Для большинства агентных рабочих процессов это нормально, но если вы предпочитаете потоковый вывод, его можно включить в конфигурации провайдера.
Проверка настройки — критически важный шаг, который пропускают многие руководства. После подключения Ollama к OpenClaw отправьте простой тестовый промпт, чтобы убедиться, что всё работает от начала до конца. Если агент отвечает связным текстом и может выполнять базовые вызовы инструментов (например, вывести список файлов в директории), ваш локальный LLM настроен правильно и каждый токен обрабатывается на вашем собственном оборудовании. Если вы видите искажённый вывод или агент отказывается использовать инструменты, возможно, модель не обладает достаточной способностью tool calling. Прежде чем обвинять OpenClaw, переключитесь на локальную coding-модель с явной поддержкой function calling и проверьте её на реальной операции с файлом.
Оптимизация производительности локальных моделей ощутимо влияет на повседневное использование. Если ответы кажутся медленными, проверьте, сколько моделей Ollama загружены в память с помощью ollama ps. Ollama хранит недавно использованные модели в памяти, и одновременная загрузка нескольких крупных моделей снижает производительность. Используйте ollama stop MODEL_NAME, чтобы выгрузить модели, которые вы не используете в данный момент. На компьютерах Mac с чипами Apple Silicon убедитесь, что Ollama использует GPU-ускорение — это происходит автоматически, но можно проверить в логах Ollama. Для пользователей Linux с GPU NVIDIA Ollama поддерживает ускорение через CUDA при установленных соответствующих драйверах, что может увеличить скорость инференса в 3-5 раз по сравнению с выполнением только на CPU.
Настройка облачных провайдеров LLM

Облачные провайдеры дают OpenClaw более сильные reasoning-модели, но главный выбор здесь — не «какая модель лучшая», а какой route contract вы используете. Direct Anthropic, OpenAI/Codex, Google Gemini, AWS Bedrock, локальный Ollama и OpenAI-compatible gateway отличаются аутентификацией, именами моделей, beta headers и поддержкой tool calling. Большинство ошибок возникает, когда эти маршруты смешивают в один произвольный baseURL.
Маршрут OpenAI / Codex подходит пользователям, у которых уже есть OpenAI Platform billing, командные API-ключи и процесс аудита. Сохраните ключ через переменную окружения или onboarding wizard, затем проверьте фактически выбранный provider/model:
bashexport OPENAI_API_KEY="sk-proj-..." openclaw onboard --install-daemon openclaw models status
Direct Anthropic route нужен, если вы явно полагаетесь на native Claude behavior, Anthropic Messages API или explicit 1M context switch. Важно не просто вставить ключ, а убедиться, что вы используете direct Anthropic provider, а не отправляете Claude model name через OpenAI-compatible endpoint.
bashexport ANTHROPIC_API_KEY="sk-ant-..." openclaw config validate openclaw models status
Если вы столкнулись с проблемами при настройке, наше руководство по ошибкам конфигурации API-ключа Anthropic охватывает формат ключа, региональные ограничения и проверку активного provider. Если ошибка выглядит как invalid beta flag, не возвращайтесь к старому snippet beta_features: []; сначала определите route: direct Anthropic, Bedrock и custom proxy исправляются по-разному.
Маршрут AWS Bedrock подходит командам, которым нужны IAM, VPC endpoints, региональный контроль и compliance audit. Это не «Anthropic API с другим baseURL», а отдельный provider path, обычно с AWS credential chain и amazon-bedrock provider. Цена этого выбора — не все Anthropic beta/header behaviors переносятся из direct API.
OpenAI-compatible gateway route подходит, если у вас уже есть единый gateway, private proxy или multi-model platform, и OpenClaw должен говорить только с одним compatible endpoint. Проверьте три вещи: опубликованы ли нужные model IDs, передаётся ли tool calling, и возвращаются ли ошибки реального upstream. Не используйте любой proxy как Anthropic-native API без проверки.
Использование бесплатных или недорогих моделей с OpenClaw
OpenClaw можно запускать с локальными моделями для снижения API-расходов или подключать облачные маршруты с бесплатными квотами и недорогими моделями. Но «бесплатная модель» не должна подаваться как production-ответ. Она подходит для изучения OpenClaw, проверки tool calling, лёгкой организации файлов или outage fallback. Для сложных изменений кода, многофайлового reasoning и длинного контекста чаще нужна более сильная и стабильная модель.
bash# Discover configured models where supported openclaw models list # Check the active route openclaw models status
Оценивайте бесплатную модель не по ответу на hello world, а по реальной задаче: читает ли она файлы, следует ли ограничениям, выполняет ли tool calls, сохраняет ли контекст в длинной сессии. Если нет, оставьте её в fallback или learning environment, а не ставьте primary.
Локальный Ollama остаётся самым сильным privacy-first вариантом. Sensitive code, offline demo и данные, которые нельзя отправлять наружу, хорошо подходят для local route. Но ограничения локальных моделей — context window, скорость и качество tool calling. Выбор должен зависеть от hardware и workload, а не только от нулевой цены API.
Оптимизация затрат и мультимодельная маршрутизация
Оптимизация затрат здесь не означает цитирование фиксированной таблицы цен. Цены, free tiers и доступность моделей меняются, поэтому publish-страница не должна обещать конкретную экономию без текущей проверки. Более устойчивый подход — разделить задачи по сложности, настроить fallback chain и поставить billing alerts.
yamlagents: defaults: model: primary: "openai/gpt-current" fallbacks: - "anthropic/claude-current" - "ollama/qwen-coder-local"
Эта структура задаёт стратегию, а не фиксированную рекомендацию: primary обрабатывает ежедневную работу, второй cloud provider страхует rate limit и outage, локальная модель покрывает offline или sensitive tasks. Более дешёвую модель можно поставить primary только после проверки на реальном workflow. Иначе дешёвая модель создаст больше retries и фактическая стоимость вырастет.
На практике отслеживайте три показателя в openclaw dashboard и provider billing dashboard: длину контекста на сессию, частоту fallback и число повторов после ошибок. Рост контекста лечится /clear и дроблением задач; частый fallback говорит о лимитах или нестабильном provider; большое число retry часто означает слабую модель или неправильный route.
Устранение распространённых ошибок OpenClaw LLM

Каждый пользователь OpenClaw сталкивается хотя бы с одной из этих ошибок при настройке. Разочарование вполне реальное — вы потратили время на конфигурацию, и тут загадочное сообщение об ошибке блокирует дальнейшую работу. Этот раздел охватывает десять наиболее распространённых ошибок, связанных с LLM, с их точными сообщениями и проверенными решениями, чтобы вы могли вернуться к продуктивной работе за минуты, а не за часы.
Ошибка 1: «Connection refused» при использовании Ollama. Это означает, что OpenClaw не может достичь сервера Ollama по адресу http://127.0.0.1:11434. Исправление почти всегда заключается в том, что сервер Ollama не запущен. На macOS откройте десктопное приложение Ollama. На Linux выполните ollama serve в отдельном терминале. Проверьте доступность сервера командой curl http://127.0.0.1:11434/api/tags — если вы получаете JSON-ответ со списком моделей, сервер работает корректно, и проблема, вероятно, в конфигурации файрвола или прокси, блокирующей соединения через localhost.
bash# Check if Ollama is running curl http://127.0.0.1:11434/api/tags # Start Ollama server (Linux) ollama serve # If using a custom port, update OpenClaw config export OLLAMA_BASE_URL="http://127.0.0.1:YOUR_PORT"
Ошибка 2: «Model not allowed» или «Model not found». Это возникает, когда вы запрашиваете модель, которая либо не существует у вашего провайдера, либо недоступна для вашего уровня API. Для Ollama это означает, что вы ещё не загрузили модель — выполните ollama pull MODEL_NAME. Для облачных провайдеров дважды проверьте точный идентификатор модели: OpenClaw использует формат provider/model-name, и опечатка в любой части вызовет эту ошибку. Используйте openclaw models list для просмотра всех доступных моделей для ваших настроенных провайдеров.
Ошибка 3: «Invalid API key» или ошибки аутентификации. API-ключ отсутствует, неправильно сформирован или просрочен. Для Anthropic ключи начинаются с sk-ant-. Для OpenAI — с sk-proj- (новый формат) или sk- (устаревший формат). Для OpenRouter — с sk-or-. Убедитесь, что вы установили правильную переменную окружения (ANTHROPIC_API_KEY, OPENAI_API_KEY или OPENROUTER_API_KEY) и что она не содержит концевых пробелов или символов переноса строки. Распространённая ошибка — копирование ключа с невидимыми символами из менеджера паролей.
Ошибка 4: «Rate limit exceeded» (HTTP 429). Вы отправляете слишком много запросов слишком быстро. Это особенно часто встречается с бесплатными уровнями API, где установлены низкие лимиты частоты запросов. Немедленное решение — подождать 30-60 секунд и повторить попытку. Долгосрочное решение — настроить мультимодельную маршрутизацию с резервными моделями, чтобы при достижении лимита у одного провайдера агент автоматически переключался на другой. Для постоянных проблем с лимитами запросов наше подробное руководство по ошибкам превышения лимита запросов охватывает специфические лимиты провайдеров и стратегии их смягчения.
Ошибка 5: «Out of memory» при запуске локальных моделей. Вы пытаетесь запустить модель, которая превышает доступную оперативную память. Решение простое: переключитесь на модель меньшего размера. Если у вас 16 ГБ оперативной памяти и вы загрузили модель с 30 миллиардами параметров, переключитесь на вариант с 7 миллиардами. Используйте ollama list для просмотра установленных моделей и обратитесь к таблице соответствия оборудования и моделей в разделе настройки Ollama выше, чтобы найти подходящий вариант для вашей машины.
Ошибка 6: «Tool calling not supported» или агент не может выполнять команды. Некоторые модели, особенно небольшие open-source модели или endpoints после proxy-конверсии, не передают function calling полностью. Сначала проверьте, что текущий route передаёт tool schema, затем переключитесь на cloud или local coding model с явной поддержкой tool calling.
Ошибка 7: Ошибки «Invalid beta flag». Обычно это mismatch между provider route и Anthropic beta headers: direct Anthropic, Bedrock и custom proxy требуют разных исправлений. Сначала найдите реальный upstream через openclaw logs --follow и openclaw models status, затем используйте руководство по ошибке invalid beta flag.
Ошибка 8: Превышение контекстного окна. Длинные беседы или большие файлы могут привести к тому, что общее количество токенов превысит контекстное окно модели. Начните новую беседу командой /clear, сузьте файловый диапазон или переключитесь на route с большим подтверждённым context window. Не фиксируйте конкретное число контекста в конфигурационных советах, если не проверили его в текущем provider.
Ошибка 9: Медленные ответы при использовании локальных моделей. Если локальная модель отвечает, но каждый ответ занимает 30+ секунд, скорее всего, вы используете модель слишком большую для вашего оборудования. Проверьте текущее использование памяти модели командой ollama ps и обратитесь к таблице оборудования для правильного подбора размера модели. Также убедитесь, что никакие другие ресурсоёмкие приложения не запущены одновременно с OpenClaw при использовании локальных моделей.
Ошибка 10: OpenClaw не распознаёт провайдера после настройки. После запуска openclaw onboard агент по-прежнему использует неправильного провайдера по умолчанию. Используйте openclaw models status для проверки текущей конфигурации и openclaw models set PROVIDER/MODEL для явной установки нужной модели. Команда /model в активной сессии OpenClaw также позволяет переключать модели на лету без перезапуска.
Что делать после настройки — переход к продуктивной работе
После настройки и проверки провайдера LLM вы готовы начать использовать OpenClaw как полноценный инструмент повышения производительности, а не как игрушку для экспериментов. Разница между пользователями, которые получают реальную пользу от OpenClaw, и теми, кто бросает его через неделю, обычно сводится к трём привычкам, которые стоит выработать прямо сейчас, пока настройка ещё свежа в памяти.
Начните с тестирования конфигурации на реальной задаче, а не на промпте «привет, мир». Попросите OpenClaw проанализировать файл в вашем текущем проекте, провести рефакторинг функции или написать тест для существующего кода. Это немедленно подтвердит, что вызов инструментов работает корректно, что модель обладает достаточными возможностями для вашей работы и что время отклика приемлемо. Если что-то не так — медленные ответы, неполный код или сбои вызова инструментов — вернитесь к разделу выбора провайдера и подумайте, не подошла бы вам другая модель лучше.
Затем настройте цепочку резервных моделей, даже если вы довольны основной моделью. Сбои провайдеров случаются, лимиты запросов достигаются в самый неподходящий момент, и наличие резервной модели означает, что ваш рабочий процесс никогда не остановится полностью. Как минимум добавьте одну облачную альтернативу и одну локальную модель в конфигурацию резервных моделей. Пять минут, потраченных сейчас, сэкономят вам часы разочарования при неизбежном простое провайдера.
Наконец, установите практику регулярного мониторинга затрат, если вы используете облачные модели. Проверяйте панель использования API еженедельно, настройте оповещения о биллинге на комфортных для вас пороговых значениях и отслеживайте, соответствуют ли фактические расходы вашим бюджетным ожиданиям. Если расходы выше ожидаемых, стратегия мультимодельной маршрутизации из предыдущего раздела — ваш наиболее эффективный рычаг: направляйте рутинные задачи на более дешёвые модели и резервируйте премиальные модели для сложной работы, которая действительно выигрывает от более сильных рассуждений.
OpenClaw — это инструмент, который вознаграждает вложения в конфигурацию. Наибольшую пользу получают те пользователи, которые рассматривают первоначальную настройку не как одноразовую задачу, а как фундамент для постоянно развивающегося рабочего процесса. Ваш выбор модели, цепочка резервных моделей и стратегия управления затратами будут меняться по мере развития ваших потребностей и появления новых моделей. Мастер openclaw onboard и команда /model делают адаптацию простой — ключ в том, чтобы продолжать итерации, а не останавливаться на конфигурации, которая работает «достаточно хорошо».
Экосистема OpenClaw стремительно развивается. Новые провайдеры моделей добавляются регулярно, ценообразование меняется по мере усиления конкуренции, а возможности локальных моделей улучшаются с каждым поколением. Сохраните это руководство в закладках и возвращайтесь к системе принятия решений по выбору провайдера всякий раз, когда задумаетесь об изменении настройки. Принципы — соответствие возможностей модели сложности задачи, настройка резервных моделей для надёжности и активный мониторинг затрат — остаются постоянными, даже когда конкретные рекомендации по моделям эволюционируют. Ваши первоначальные пять минут настройки — это лишь начало рабочего процесса, который будет становиться мощнее по мере совершенствования на протяжении недель и месяцев ежедневного использования.
Часто задаваемые вопросы
Можно ли использовать несколько провайдеров LLM одновременно с OpenClaw?
Да. Конфигурация цепочки резервных моделей OpenClaw в agents.defaults.model.fallbacks поддерживает несколько провайдеров. Основная модель обрабатывает запросы первой, и если она терпит неудачу или достигает лимита, агент автоматически переходит к следующей модели в цепочке. Вы также можете переключать провайдеров прямо в ходе сессии с помощью команды /model. Многие пользователи настраивают локальную модель Ollama в качестве последнего резерва, чтобы гарантировать работу агента даже тогда, когда все облачные провайдеры недоступны.
Какие минимальные требования к оборудованию для запуска OpenClaw с локальным LLM?
Абсолютный минимум — 8 ГБ оперативной памяти, что позволяет запускать модели с 3 миллиардами параметров на приемлемой скорости. Для продуктивной работы с локальными моделями рекомендуется 16 ГБ ОЗУ и модель с 7 миллиардами параметров, такая как Qwen2.5-Coder. Также потребуется Node.js версии 24 или новее и достаточно дискового пространства для файлов моделей (обычно 4-8 ГБ на модель). Компьютеры Mac на базе Apple Silicon с унифицированной памятью предлагают лучшую производительность локального инференса в пересчёте на доллар.
Как переключить модель без перезапуска OpenClaw?
Используйте команду /model в активной сессии OpenClaw. Введите /model, а затем имя провайдера и модели (например, /model anthropic/claude-sonnet-4.5). Это вступает в силу немедленно для следующего взаимодействия. Вы также можете использовать openclaw models set из терминала, чтобы изменить модель по умолчанию для всех будущих сессий. Используйте openclaw models list для просмотра всех доступных моделей для ваших настроенных провайдеров.
Безопасны ли мои данные при использовании облачных провайдеров LLM с OpenClaw?
При использовании облачных провайдеров (OpenAI, Anthropic, OpenRouter) ваши промпты и контекст кода отправляются на серверы провайдера для обработки. У каждого провайдера своя политика хранения данных и конфиденциальности. Если конфиденциальность данных — обязательное требование, используйте Ollama — весь инференс происходит локально, и никакие данные не покидают вашу машину. В качестве компромисса рассмотрите использование локальных моделей для конфиденциальных задач и облачных моделей для неконфиденциальной работы, настроив их через систему мультимодельной маршрутизации.
Сколько стоит использование OpenClaw с облачными моделями?
Стоимость зависит от model pricing, длины контекста, числа tool calls, retries и fallback strategy. Не смотрите только на цену за миллион токенов: слабая модель может увеличить расходы за счёт переделок. Перед продуктивным использованием настройте billing alerts и отслеживайте длину сессии, частоту fallback и ошибки повторных запросов.