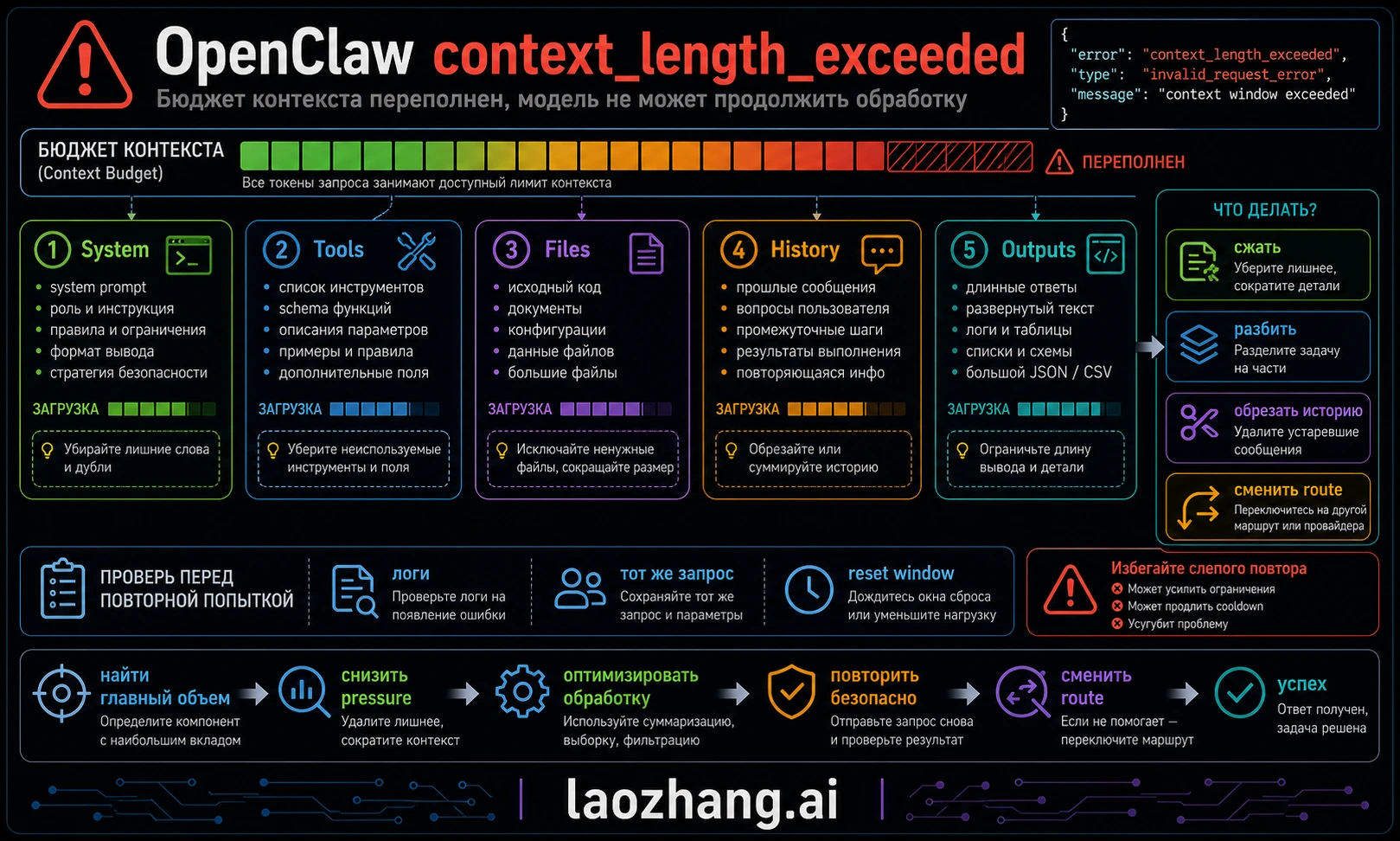
Ошибка context_length_exceeded в OpenClaw обычно означает, что собранный запрос больше, чем выбранный model route может принять. В этот запрос может входить не только последнее сообщение пользователя, но и системные инструкции, схемы инструментов, правила проекта, память, channel metadata, история диалога и свежий вывод инструментов. Но видимая ошибка не всегда является корнем проблемы: rate limit, provider cooldown, fallback на модель с меньшим контекстом или retry loop могут сделать quota/routing issue похожим на context overflow. Сначала определите владельца ошибки, затем выбирайте compaction, split task или re-route.
Короткий ответ
- Докажите симптом: проверьте
/status,/context listесли команда доступна в вашей версии, иopenclaw logs --follow. Если ошибка появилась сразу после 429, cooldown или fallback, сначала читайте provider logs. - Реальный контекст слишком большой: используйте
/compact, чтобы сохранить ключевые решения и сжать старую историю; если задача уже сменилась, начните чистую сессию через/new. - Слишком большой вывод инструментов: не вставляйте полные логи, широкие поиски и огромные файлы в одну сессию. Передавайте ключевые фрагменты, диапазоны файлов и краткие summaries.
- Workspace injection слишком тяжелый: сократите AGENTS/rules files, уберите устаревшие инструкции и дайте агенту читать точные файлы по запросу.
- Model route не подходит: проверяйте доступное окно в текущем аккаунте, provider, gateway и fallback, а не по старым таблицам из статей.
Сначала определите владельца ошибки
context_length_exceeded обычно имеет одного из нескольких владельцев.
| Симптом | Вероятный владелец | Следующее действие |
|---|---|---|
/status растет в длинной сессии, ошибка появляется постепенно | Реальное переполнение контекста | /compact, /new, split task, reduce tool output |
| Ошибка появляется в новой сессии или при низком использовании | Bootstrap, memory/search, channel metadata или неверный route | Проверьте /context list и logs, затем уменьшите injection source |
| Ошибка идет сразу после 429, cooldown или provider failover | Rate limit или fallback route | Сначала прочитайте первую provider error, не начинайте с context tuning |
| Ошибка есть только на одном provider/gateway | Route или proxy дает другое окно | Проверьте текущий provider docs и реальный response |
Порядок важен. Реальный context overflow лечится compaction. Fallback на меньшую модель лечится route change. Provider quota лечится ожиданием, снижением concurrency или проверенным fallback. Раздутая workspace injection лечится изменением входных данных.
Почему OpenClaw быстро расходует контекст
OpenClaw работает как agentic workflow. Один короткий запрос пользователя может запустить чтение файлов, поиск, команды, тесты, возврат tool output и несколько model calls. Следующий запрос часто несет часть этой истории дальше, поэтому рост зависит от того, что реально попало в payload, а не от количества минут работы.
Фиксированные расходы обычно приходят от system/tool instructions. Их нельзя просто удалить: они объясняют агенту, как пользоваться инструментами, соблюдать правила проекта и работать с файлами. Управлять нужно переменной частью: длинными логами, широким поиском, нерелевантными файлами, устаревшими правилами, повторными ошибками и старой историей из другой задачи.
Workspace injection часто незаметна. AGENTS.md, project rules, generated docs и memory полезны, но если они становятся длинными, устаревшими или противоречивыми, они занимают место в каждом запросе. Хорошая практика — держать долгосрочные правила короткими, сохранять одноразовый analysis в файлах и просить агента читать точные диапазоны только когда это нужно.
Восстановление работы
1. Прочитайте status и первую ошибку в logs.
bash/status /context list openclaw logs --follow
Если ваша версия не поддерживает /context list, восстановите цепочку действий: читали ли вы большой файл, запускали ли длинный test output, открывали ли несколько agents, перешли ли от старой задачи к новой, был ли перед этим provider 429 или fallback.
2. Если сессия действительно большая, используйте /compact. Эта команда подходит, когда нужно сохранить решения, file paths и текущий task state, но убрать лишнюю детализацию старой истории. Экономия зависит от transcript и версии OpenClaw, поэтому проверяйте результат через /status, а не ожидайте фиксированный процент.
3. Если задача сменилась, используйте /new. Когда старая сессия содержит нерелевантные logs, неудачные попытки и решения другой задачи, новая сессия часто лучше повторной compaction. Передайте короткий handoff: цель, измененные файлы, оставшиеся риски, важные команды и test results.
4. Уменьшите tool output. Вместо полного лога передавайте первую ошибку, верх stack trace, relevant config и reproduction command. Вместо "прочитай весь репозиторий" просите прочитать конкретные файлы и диапазоны.
5. Не лечите quota issue как context issue. Если ошибка появилась после 429, cooldown или fallback, сначала лечите provider owner: уважайте retry-after, снижайте concurrency, сокращайте context, переключайтесь на проверенный fallback или ждите восстановления quota window.
Безопасные границы настройки
Настройки контекста в OpenClaw меняются между версиями. Старые статьи полезны для принципов, но не должны быть источником точных default values. Перед изменением проверьте текущие docs, openclaw config output или реальный config file.
| Направление настройки | Когда помогает | Риск |
|---|---|---|
| Более ранняя compaction | Длинные сессии часто подходят к лимиту | Меньше дословной истории, нужен хороший summary |
| Меньше bootstrap/workspace injection | AGENTS или rules слишком большие | Агенту придется чаще читать файлы по запросу |
| Ограничить memory/search retrieval | Новая сессия уже тяжелая | Слабее continuity между сессиями |
| Перейти на route с большим проверенным context | Large repo review, long docs, multi-file work | Цена, latency, tool support и fallback требуют проверки |
Пример ниже показывает форму, но поля и числа нужно сверить с вашей версией:
json{ "agents": { "defaults": { "compaction": { "reserveTokens": 40000, "keepRecentTokens": 25000 }, "bootstrapMaxChars": 12000, "memorySearch": { "softThresholdTokens": 3000 } } } }
Смысл не в конкретных числах. Смысл в трех правилах: compaction должна срабатывать до hard failure, workspace injection должна быть короткой и актуальной, retrieval должен быть релевантен задаче.
Выбор model route
Advertised context window модели не равен полезному контексту внутри OpenClaw. Проверьте:
- доступна ли модель в текущем аккаунте;
- route идет напрямую к provider, через cloud route, gateway или proxy;
- fallback не переключает работу на меньшую модель;
- tool calls, file/image inputs, streaming и structured output остаются совместимыми;
- gateway сохраняет upstream context window и error details.
Если вам нужна маршрутизация между несколькими providers, OpenAI-compatible gateway вроде laozhang.ai может упростить credentials и fallback. Но model coverage, price, context window, quota behavior и tool compatibility должны быть проверены в текущей среде перед production use.
Профилактика
Держите rules files короткими. AGENTS.md и похожие файлы должны хранить долгосрочные правила, а не одноразовые логи, старые споры и устаревшие планы.
Делите длинные задачи на фазы. После фазы делайте compaction или новую сессию с понятным handoff. Не смешивайте research, implementation, testing, postmortem и другой проект в одной бесконечной thread.
Делайте tool output читаемым. Для test failure передавайте минимальное воспроизведение, ключевую ошибку и relevant files. Широкий output тратит context и мешает агенту понять настоящую причину.
Следите за context и cost. Context tokens — это также API cost. Меньше нерелевантной истории и шумных tool outputs обычно означает меньше ошибок, меньше ожидания и ниже счет.
FAQ
Что вызывает context_length_exceeded в OpenClaw?
Ошибка возникает, когда собранный request превышает доступное окно выбранного model route. В request могут входить system instructions, tool schemas, workspace files, history, memory/search results, channel metadata и tool output. Иногда fallback, quota или gateway behavior только выглядят как context error.
Как увеличить контекстное окно OpenClaw?
Нельзя увеличить окно самой модели, но можно перейти на route с большим проверенным context, уменьшить workspace injection, снизить retrieval noise, запускать compaction раньше, делить задачи и не отправлять огромные logs в одну session.
/compact теряет данные?
Она сжимает старую history в summary, сохраняя ключевые решения и recent context, но дословные детали могут не попасть в будущие requests. Важные commands, errors, file paths и conclusions лучше сохранять в локальный handoff или document.
Почему context_length_exceeded бывает в новой сессии?
Обычно из-за bootstrap files, memory/search retrieval, channel metadata или fallback route с меньшим window. Проверьте /status, /context list и первую provider error, затем уменьшайте injection source или меняйте route.