
Ошибка 429 в OpenAI API обычно ломает работу не потому, что разработчик не знает термина rate limit, а потому, что одно и то же число 429 скрывает несколько разных владельцев проблемы. Иногда вы упираетесь в слишком частые запросы. Иногда в слишком тяжелые prompt plus output. Иногда в квоту, биллинг или usage budget. Иногда запрос уходит не в тот project, model или organization. А иногда проблема вообще принадлежит ChatGPT, Codex или стороннему gateway, а не Platform API.
Поэтому самый быстрый честный путь выглядит так: сначала определить владельца ограничения, затем посмотреть reset signal, после этого выбрать минимальное действие. Пока вы не знаете owner, любые покупки кредитов, rotation keys или более агрессивные retry loop остаются гаданием.
Русскоязычная выдача по 429 часто смешивает официальную справку OpenAI, Reddit, неофициальные зеркала документации и обсуждения insufficient_quota. Из-за этого вопрос "что делать" быстро превращается в хаотичный выбор между sleep, billing, новым ключом и сменой продукта. Практический runbook должен разорвать эту смесь.
Короткий ответ
| Вопрос | Короткий ответ |
|---|---|
| Что обычно означает 429 в OpenAI API? | Текущий API route превысил request limit, token limit, quota, billing boundary, scope или reset window. |
| Что проверять первым? | x-ratelimit headers и страницу Limits в аккаунте. |
| Кто чаще всего владеет технической проблемой? | Burst traffic, избыточная concurrency, слишком большой token budget. |
| Кто чаще всего владеет нетехнической проблемой? | Недостаточная квота, billing issue, trial boundary, неправильный product surface. |
| Что сделать до запроса higher limits? | Уменьшить concurrency, добавить exponential backoff с jitter, сократить token output, вынести background work в queue или Batch API. |
| Чего не делать вслепую? | Не ротировать ключи, не спамить retries, не считать кредиты эквивалентом throughput и не путать ChatGPT/Codex лимиты с Platform API. |
Сначала владелец ограничения, потом retry loop
Полезный первый вопрос звучит не как "какой лимит у OpenAI API", а как "какой лимит сработал на этом запросе". Request-rate owner и token-rate owner обе возвращают 429, но ведут к разным исправлениям. Quota или billing owner тоже может выглядеть как rate problem, но backoff там не лечит корень. Неверный project, org, model или endpoint могут делать вид, что речь о capacity, хотя в реальности проблема в scope.
Официальные материалы OpenAI задают понятную рамку: live limits принадлежат странице Limits, usage tiers влияют на headroom, headers помогают понять, сколько бюджета осталось и когда откроется окно, а mitigation начинается с bounded retry, а не с brute-force resend.
Практический порядок из четырёх шагов:
- Прочитать owner.
- Прочитать reset.
- Применить самое маленькое безопасное исправление.
- Эскалировать только после того, как route, billing и traffic shape уже доказанно стабильны.
Если ваш реальный вопрос связан с org, project или ключами, идите в OpenAI API Key и Organization ID. Если вы на самом деле разбираете окна Codex или подписочный продукт, правильные соседние страницы — OpenAI Codex usage limits и Codex API key vs subscription.
Что именно измеряют лимиты OpenAI
OpenAI не описывает лимиты как одно фиксированное число, одинаковое для всех. Для реальной эксплуатации важны несколько измерений:
- Requests per minute: слишком много вызовов в коротком окне.
- Tokens per minute: слишком большой суммарный объём prompt plus output.
- Usage tier: уровень аккаунта влияет на доступный headroom.
- Live account limits: реальный потолок живёт на странице Limits, а не в старой таблице из статьи.
- Reset signals: headers могут сказать, когда окно откроется снова.
Отсюда следует неприятная, но полезная вещь: универсальные статьи с точными RPM/TPM цифрами опасны как главная опора. Они превращают живую account boundary в якобы вечную истину. Безопаснее использовать публичные документы для понятий и шаблонов смягчения, а Limits page — как контракт текущего аккаунта.
Разделение request pressure и token pressure особенно важно. RPM problem чаще приходит от burst, tight loop и слишком высокой concurrency. TPM problem появляется, когда prompt history слишком длинная, max output завышен, контекста слишком много или каждый отдельный вызов дороже, чем кажется. Если эти случаи не разъединить, вы рискуете лечить не ту причину.
Даже средние расчёты по минуте не гарантируют безопасность: quantized windows могут сработать раньше, чем ваше "в среднем мы укладываемся". Поэтому график трафика важен не меньше среднего числа запросов.
Прочитайте response прежде, чем менять код
Cookbook и rate-limit guide сходятся в одной привычке: сначала читайте response. Любой failed retry продолжает расходовать budget. Поэтому blind repetition превращает одиночный limit event в длинную cooldown spiral.
Наиболее полезные headers:
- x-ratelimit-limit-requests
- x-ratelimit-remaining-requests
- x-ratelimit-reset-requests
- x-ratelimit-limit-tokens
- x-ratelimit-remaining-tokens
- x-ratelimit-reset-tokens
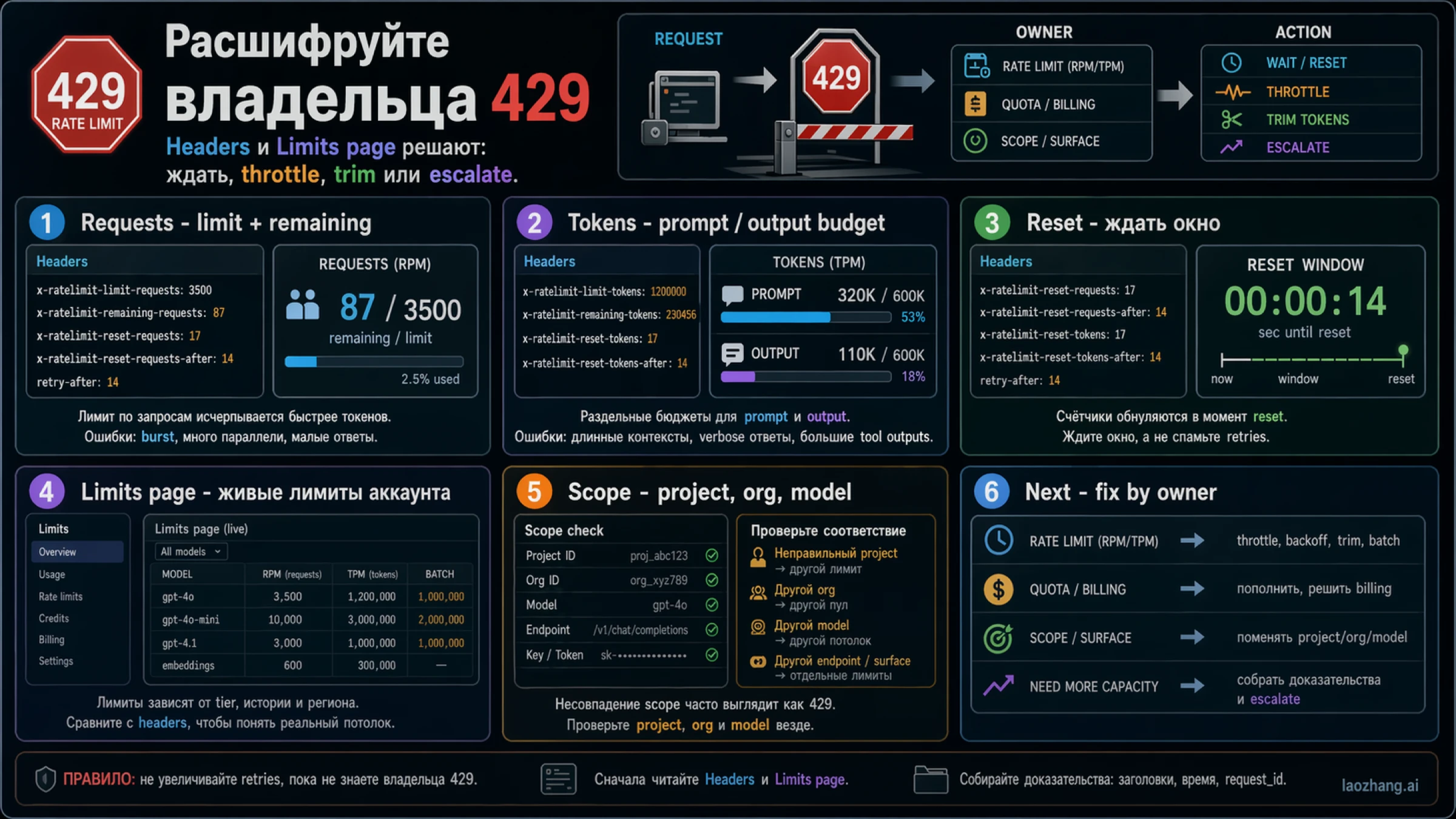
Эти сигналы говорят больше, чем просто текст ошибки:
| Сигнал | Что он обычно означает | Первое действие |
|---|---|---|
| remaining-requests около нуля | Слишком высокая частота или concurrency | Снизить parallelism, сгладить burst, добавить backoff |
| remaining-tokens около нуля | Prompt и output слишком дорогие | Сократить payload, уменьшить expected output |
| Reset короткий | Route вероятно корректен, нужно переждать окно | Подождать reset plus jitter |
| В Limits мало headroom | Потолок принадлежит аккаунту или route | Сначала оптимизировать, потом думать о higher limits |
| Headers нормальные, но ошибка остаётся | Вероятны scope, billing, wrapper или endpoint issues | Проверить project, org, model и product surface |
На практике лучше логировать статус, error body, endpoint, model, project context и x-ratelimit значения так, чтобы сравнивать инцидент между попытками. Это защищает от ложных воспоминаний.
Минимальная схема классификации может выглядеть так:
tsconst resetRequests = res.headers.get("x-ratelimit-reset-requests"); const resetTokens = res.headers.get("x-ratelimit-reset-tokens"); const remainingRequests = res.headers.get("x-ratelimit-remaining-requests"); const remainingTokens = res.headers.get("x-ratelimit-remaining-tokens"); const owner = remainingRequests === "0" ? "requests" : remainingTokens === "0" ? "tokens" : "unknown"; // Если важны оба окна, используйте более поздний reset.
Здесь не нужна идеальная система с первого раза. Нужна достаточная доказательная база, чтобы не уйти в неверную ветку.
Диагностируйте owner, а не только статус-код
После response и страницы Limits следующий шаг — классификация.
1. Request-rate owner
Это классический burst problem. Слишком много одновременных вызовов, слишком плотный цикл или агрессивные повторные попытки. Обычно видно низкий remaining-requests, короткое reset window и паттерн одновременных запросов. Исправление почти всегда связано с traffic shaping, а не с billing.
2. Token-rate owner
Этот owner часто недооценивают, потому что число запросов кажется умеренным. Но каждый запрос дорогой. Длинная история, oversized system prompt, высокий max output, неоправданный контекст и длинные ответы быстро съедают TPM. В этой ветке throughput лечится не покупкой, а сокращением token budget.
3. Quota или billing owner
Здесь retry path становится почти бесполезным. Если у аккаунта нет доступной квоты, billing unhealthy или закончился релевантный trial state, вы уже не боретесь с per-minute window. Нужно проверять account availability: кредит, способ оплаты, статус биллинга, лимит бюджета. Если вопрос на самом деле про кредиты и пробный доступ, смотрите OpenAI API free trial.
4. Project, organization или model scope owner
Синтаксис запроса может быть правильным, а route — нет. У разных project и model могут быть разные профили лимитов и доступа. Неправильный organization context или скопированный config из другого окружения легко маскируется под throughput issue.
5. Wrong product surface owner
Это один из самых дорогих по времени сценариев. Разработчики путают OpenAI Platform API с ChatGPT, Codex или wrapper-level limits. Подписка ChatGPT не обязана исправлять API 429. Окно Codex usage — не то же самое, что throughput Platform API. Совместимый gateway может добавить собственные ограничения, даже если underlying model совместима с OpenAI.
Этот разрыв меняет не формулировку, а владельца следующего шага.
Исправляйте трафик маленькими безопасными действиями
Когда owner уже известен, начинайте с минимального исправления. Публичные рекомендации OpenAI и Cookbook сходятся вокруг bounded backoff with jitter, а не немедленного resend.
Практическая лестница обычно такая:
- Подождать reset, если route иначе выглядит корректным.
- Снизить concurrency, если проблема в burst.
- Добавить exponential backoff с jitter.
- Уменьшить prompt и expected output, если pressure лежит в токенах.
- Вынести не срочную работу в queue или Batch API.
- Просить более высокие лимиты только после стабилизации route и traffic shape.

Главная ошибка в коде — относиться к backoff как к украшению. Retry path должен затихать после каждой новой ошибки. Базовый шаблон:
tsconst base = 500; // ms const max = 15000; for (let attempt = 0; attempt < 6; attempt += 1) { const wait = Math.min(max, base * 2 ** attempt); const jitter = Math.random() * 0.25 * wait; await sleep(wait + jitter); }
Для TPM pressure часто дешевле всего сократить token output: уменьшить max output, сократить историю, убрать лишние блоки контекста. Если workload не требует мгновенного ответа, лучше рассматривать queue или Batch API, чем продолжать давить synchronous path.
Повышайте throughput только после устойчивых доказательств
Многие команды слишком рано переходят к higher limits. Это маскирует архитектурную проблему и не даёт понять, стабилизировалась бы система сама после исправления трафика.
Эскалация уместна, если одновременно верно всё следующее:
- route корректен;
- billing здоровый;
- owner известен;
- retries уже ограничены;
- prompt и output budget разумны;
- workload по-прежнему требует больше sustained capacity.
Только тогда usage tier и запрос на limit increase становятся частью решения. Публичные документы OpenAI объясняют общую механику, но фактическая точка управления остаётся в Limits page вашего аккаунта.
Перед запросом повышения полезно собрать evidence pack:
- какой model и endpoint используется;
- какая request и token pressure реально наблюдается;
- как ведут себя reset windows;
- какой профиль concurrency у трафика;
- что уже было оптимизировано;
- почему queue или Batch API недостаточно.
Такой пакет нужен не только для внешнего запроса. Он защищает саму команду от преждевременного вывода "нам просто нужно больше лимита".
Stop rules
Некоторые действия настолько привычны и настолько вредны, что их проще назвать отдельным чек-листом запретов.

Не делайте это по умолчанию:
- Не ротируйте ключи. Если limit owner остался тем же аккаунтом, project или route, смена ключа не чинит проблему.
- Не покупайте кредиты, не проверив throughput. Кредиты могут решить quota или billing, но не поднимут автоматически RPM или TPM.
- Не обновляйте ChatGPT или Codex plan ради Platform API 429. Это разные поверхности.
- Не копируйте точные цифры из старых tutorials как текущую правду. Live limits принадлежат странице Limits.
- Не повторяйте запросы вслепую. Failed retries тоже сжигают budget.
Полезная рабочая таблица:
| Если проблема в | Делайте дальше |
|---|---|
| Request burst | Снижайте parallelism и добавляйте jitter |
| Token pressure | Урезайте prompt и output size |
| Коротком reset window | Ждите и повторяйте безопасно |
| Billing или quota | Чините состояние аккаунта |
| Project или model scope | Исправляйте route и scope |
| Не API поверхности | Выходите из API-статьи и переключайтесь на правильный продукт |
Последняя строка важнее, чем кажется. Если реальный вопрос звучит как "почему Codex или ChatGPT перестал принимать работу", то этот runbook уже не ваш.
FAQ
Что означает 429 в OpenAI API?
Это означает, что текущий API route превысил request, token, quota, billing, scope или reset-window boundary. Начинайте с классификации, а не с общего retry.
Где смотреть точные текущие лимиты OpenAI API?
На странице Limits в аккаунте. Публичные документы нужны для понятий и headers, а живой ceiling — это свойство вашего аккаунта и route.
Дают ли кредиты автоматически больше throughput?
Нет. Они важны только тогда, когда owner — quota или billing. Они не повышают автоматически request-rate и token-rate ceilings.
Могут ли ChatGPT Plus, Pro или подписка Codex исправить Platform API 429?
Нет. Потребительские планы и продуктовые окна Codex — отдельные контракты относительно Platform API throughput.
Когда помогает Batch API?
Когда работа не срочная. Если ответ не нужен синхронно, batching снижает нагрузку на живой request path и обычно лучше подходит, чем бесконечный realtime loop.
Когда уже уместно просить higher limits?
После того как route корректен, billing здоровый, retry path ограничен, token budget разумен, а workload всё ещё требует большей устойчивой ёмкости.
Практический вывод
Самое быстрое честное исправление OpenAI API 429 — не "попробовать позже" и не "что-нибудь обновить". Это "понять владельца ограничения, прочитать reset signal и сделать минимальное безопасное действие". Если owner — requests, сгладьте burst. Если owner — tokens, сократите payload. Если owner — billing или quota, чините аккаунт. Если owner — scope, переходите к правильному project, organization, model или endpoint. А если задача не срочная, не заставляйте её жить в synchronous path, когда queue или Batch API подходят лучше.