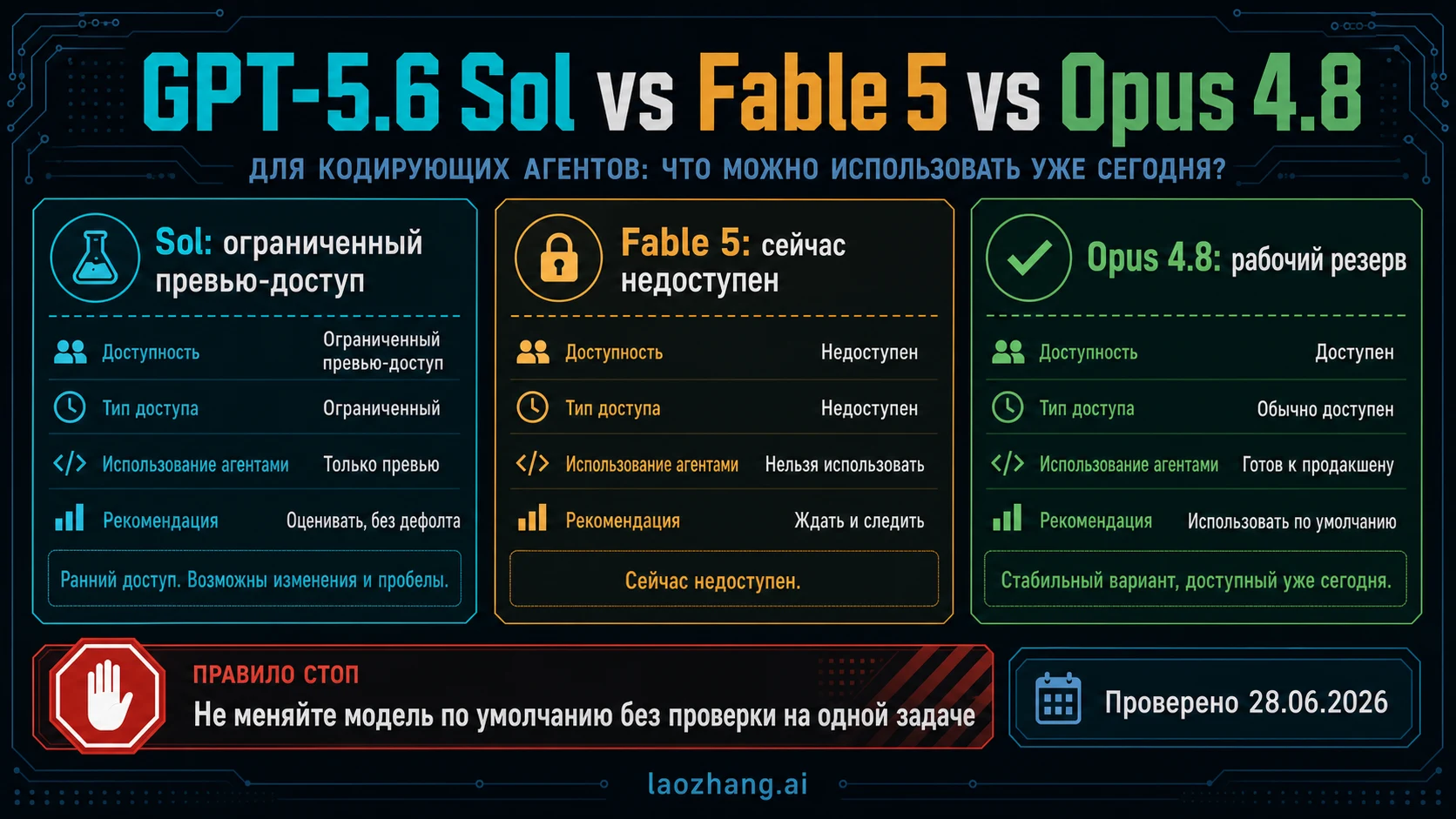
GPT-5.6 Sol, Claude Fable 5 и Claude Opus 4.8 сейчас не являются тремя одинаково доступными вариантами. На 28 июня 2026 года OpenAI описывает GPT-5.6 Sol как limited preview для одобренных организаций; Anthropic указывает, что Claude Fable 5 сейчас unavailable; Claude Opus 4.8 остается тем Anthropic route, который можно реально поставить в оценку coding-agent уже сегодня.
Практический вывод такой: держите Opus 4.8 как live fallback, если у вашей организации нет нужного доступа к GPT-5.6 Sol preview. Sol стоит тестировать только в том API org или Codex workspace, где доступ действительно выдан. Fable 5 остается строкой wait-and-recheck, пока Anthropic не изменит официальный access status. Production default нельзя менять без одной и той же задачи, одного prompt, тех же tools, тех же tests и того же cost log.
| Текущий route на 28.06.2026 | Первое действие | Почему | Stop rule |
|---|---|---|---|
| Есть нужный Sol preview access | Тестировать Sol на сложных coding-agent задачах | OpenAI позиционирует Sol как flagship GPT-5.6 и подчеркивает terminal-driven coding. | Не переносить результат preview workspace на команды без доступа. |
| Рассматривается Claude Fable 5 | Ждать и перепроверять Anthropic access | Anthropic сейчас указывает Fable 5 как unavailable. | Не считать list price или старые demo deployability proof. |
| Нужен production model сегодня | Использовать Claude Opus 4.8 как live baseline | Opus 4.8 указан как доступный через Anthropic и партнерские платформы. | Не менять default без same-task evidence. |
Быстрый ответ
Для coding teams это сравнение начинается не с короны модели, а с доступа. Sol является интересной preview-моделью, Fable остается недоступным premium promise, а Opus 4.8 является live fallback. Порядок может измениться, поэтому рядом с доступом, ценой и платформами нужен явный date stamp: эти строки проверены по официальным OpenAI и Anthropic материалам 28 июня 2026 года.

Используйте Sol, если у вас уже есть approved OpenAI route и задача стоит preview risk. Используйте Opus 4.8, если нужен поддерживаемый endpoint, policy, logs и rollout path прямо сейчас. Fable 5 стоит держать в waitlist/recheck, а не в production recommendation, пока Anthropic не восстановит доступ.
Многие сравнения начинают с benchmark table. Это удобно для сканирования, но скрывает главный engineering decision: сильная модель без доступа не является вашим production default. Даже высокая list price у недоступной модели остается только planning number.
Доступ является первым разделителем
Материалы OpenAI по GPT-5.6 Sol описывают limited preview, а не self-service launch. Help page дополнительно разделяет API organization access и Codex workspace access. Это важно: approval для API org не доказывает, что ваш Codex workspace тоже может использовать Sol. Если migration зависит от Codex, проверяйте workspace entitlement до планирования теста.
У Anthropic вокруг Fable 5 противоположная граница. Продуктовая страница может сохранять model page, price row и benchmark framing, но current access statement говорит, что Fable 5 unavailable. Поэтому Fable стоит смотреть, но не использовать как traffic route. Старые видео, screenshots и third-party demos не заменяют текущий official access status.
Claude Opus 4.8 имеет самый ясный deployability contract сегодня. Anthropic Opus page и model overview перечисляют Claude products, Claude Platform, AWS, Google Cloud и Microsoft Foundry. Implementation row для проверки: `claude-opus-4-8`. Не заменяйте его social shorthand или старым Opus ID.
| Contract item | GPT-5.6 Sol | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|---|
| Access status | Limited preview для approved organizations и scoped workspaces. | Current Anthropic materials: unavailable. | Generally available через Anthropic и listed partner routes. |
| Роль сегодня | Preview test при наличии доступа. | Wait and recheck. | Live baseline или fallback. |
| API/model ID | Проверять в approved OpenAI org перед кодом. | Не планировать production calls, пока access disabled. | `claude-opus-4-8`. |
| Главный риск | Entitlement mismatch и слишком широкий вывод из preview. | Принять старые demos или list price за live access. | Считать модель победителем без same-task test. |
Цена: сравнивайте одну задачу
Official list prices полезны только при одном unit of work. OpenAI указывает Sol preview pricing: `5\` input и \`30` output за миллион tokens. Anthropic указывает Fable 5 list price: `10\` input и \`50` output, но эта строка не deployable пока access unavailable. Anthropic model docs указывают Opus 4.8: `5\` input и \`25` output.
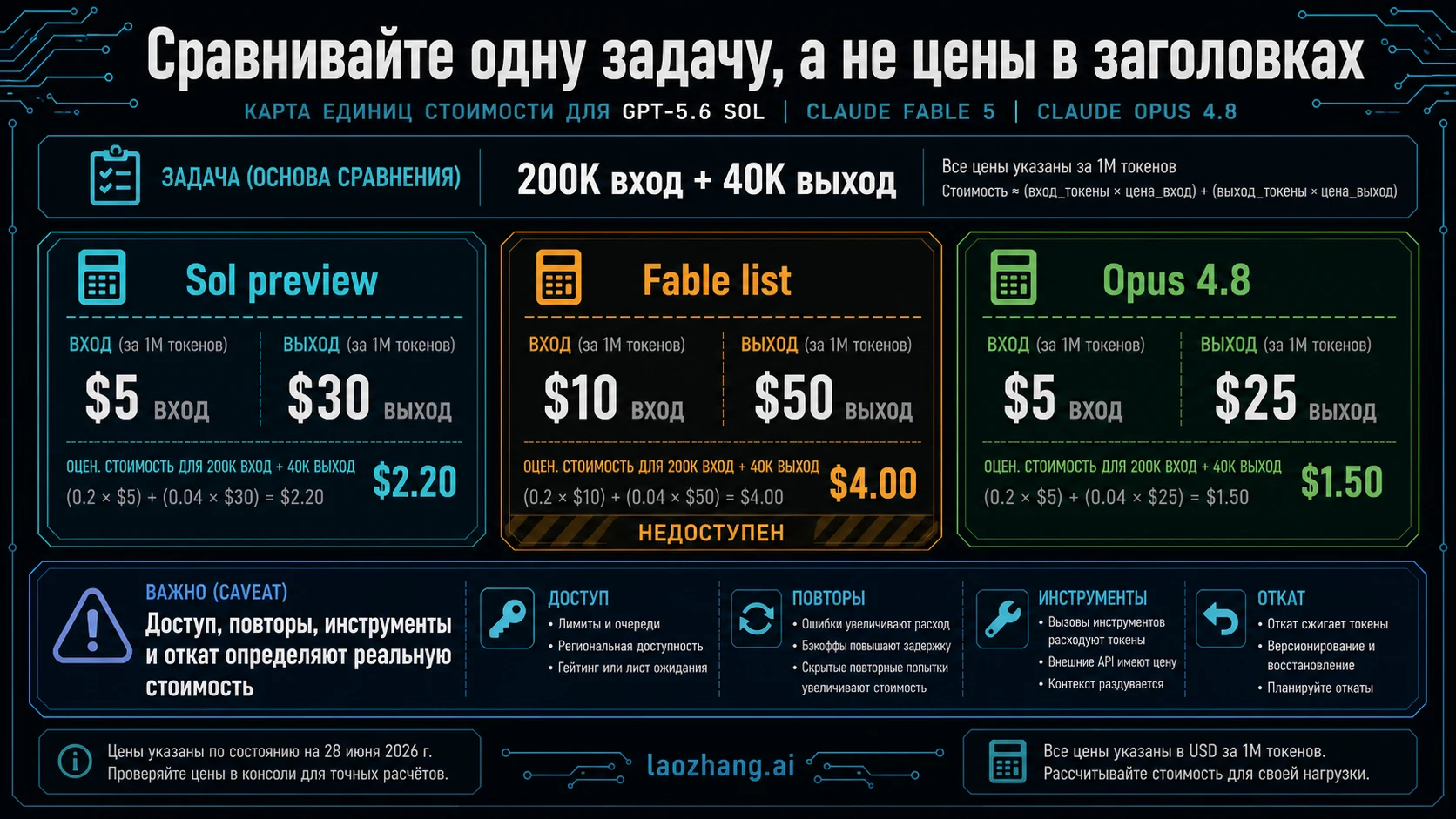
Для задачи 200k input плюс 40k output грубая list math до cache, batch, retries и региональных условий такая: Sol около `2.20\`, Fable был бы около \`4.00`, но unavailable, Opus 4.8 около `$2.00`. Это не доказывает, что Opus всегда выигрывает. Это делает Opus live price baseline, который Sol должен превзойти качеством, временем или снижением failure rate.
Реальная стоимость - это task cost. Модель с чуть более дорогим output может быть дешевле, если она закрывает задачу за один проход и снижает review minutes. Модель с хорошей строкой цены может стать дорогой, если вызывает tools в цикле, ломает формат или требует ручного ремонта. Логируйте input, cached input, output, retries, tool calls, latency и human review minutes до утверждения switch.
Как читать benchmarks
Benchmarks должны решать, что тестировать первым, а не отменять access table. Запуск Sol от OpenAI выделяет terminal-driven agentic coding и сильные результаты. Для команд с preview access это серьезный сигнал, особенно когда задачи похожи на repository edits, terminal recovery и multi-step coding.
Но provider benchmark claims отвечают на более узкий вопрос, чем production teams. Они не доказывают, что у вашего аккаунта есть доступ, что tool harness совместим, что prompts переживут long-context drift, или что модель снижает total review time. Они также не делают Fable 5 deployable, пока Anthropic пишет unavailable.
Используйте benchmark rows как workload hints. Terminal coding и Sol access - Sol идет в первый pilot lane. Live API agent с customer-facing output - Opus 4.8 идет в stable lane. Fable-specific research можно держать готовым, но production cutover не планируется до изменения Anthropic access page.
План проверки coding-agent
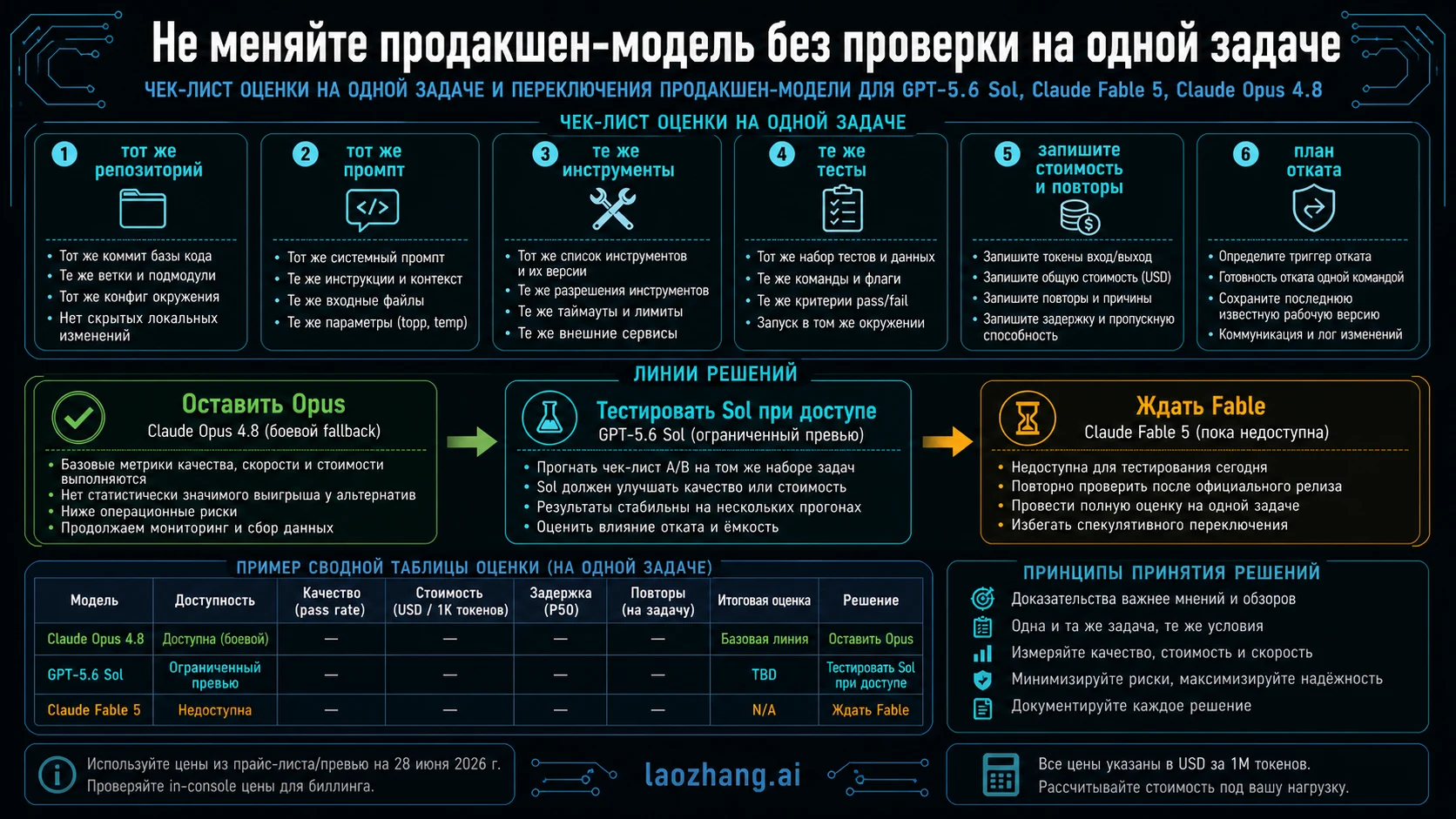
Справедливое сравнение использует одну и ту же работу, а не один headline. Возьмите 10-20 задач из реального review load: исправление failing test, refactor с hidden constraints, long-context bug hunt, docs update с code verification, tool recovery после ошибки. Не выбирайте demo prompts, которые заранее подходят любимой модели.
Opus 4.8 запускайте через endpoint, который можно реально deploy. Sol запускайте только через approved OpenAI surface, который у вас есть. Fable держите в future-test column, пока доступ не восстановлен. Для каждого run записывайте first-pass correctness, tool recovery, format stability, output length, total tokens, retry count, latency и review minutes.
Default-switch threshold должен быть строгим. Модель не становится production default, если она не уменьшает total work на том же наборе задач и не имеет rollback route. Если Sol выигрывает только внутри preview workspace, держите его specialist route. Если Opus выигрывает надежностью и live support, держите его baseline. Если Fable позже вернется, повторите тот же harness.
Если вы уже используете соседнюю модель
Если вы недавно читали сравнение GPT-5.5 или Opus 4.7, переносите только route-first привычку, не старые факты. Страница GPT-5.5 vs Claude Opus 4.7 полезна как структура оценки, но access state, model names и price rows изменились. Любая строка цены, context или availability требует свежей официальной проверки.
Если вопрос именно в том, стоит ли ждать Fable, более узкое сравнение Claude Fable 5 vs GLM 5.2 дает прежний context. В этой статье правило жестче: пока Anthropic пишет unavailable, Fable 5 нельзя рекомендовать как следующий production step.
Устойчивое правило короткое: сохраняйте live model, который поддерживает систему сегодня; добавляйте preview model только там, где есть доступ и риск приемлем; недоступные модели держите в watchlist; ничего не повышайте до default без same-task evidence.
Часто задаваемые вопросы
GPT-5.6 Sol доступен публично?
Нет. OpenAI описывает GPT-5.6 Sol как limited preview для approved organizations, причем API org и Codex workspace нужно проверять отдельно. Без соответствующего доступа Sol сегодня не production option для этой route.
Claude Fable 5 доступен сейчас?
Anthropic current Fable materials говорят unavailable, а заявление от 12 июня говорит, что Fable 5 и Mythos 5 должны быть disabled for all customers. Сейчас это wait-and-recheck model.
Claude Opus 4.8 самый безопасный default?
В этой тройке Opus 4.8 является самым понятным live Anthropic baseline. Но даже он требует same-task evaluation перед заменой работающего default.
Какая модель дешевле?
По простой list math для 200k input и 40k output Opus 4.8 около `2.00\`, Sol preview около \`2.20`, а Fable list row около `$4.00`, но unavailable. Реальная цена зависит от cache, batch, retries, latency и review minutes.
Могут ли benchmarks решить победителя?
Нет. Benchmarks выбирают first pilot. Production default выбирают access status, task fit, cost logs, failure rate и rollback safety.