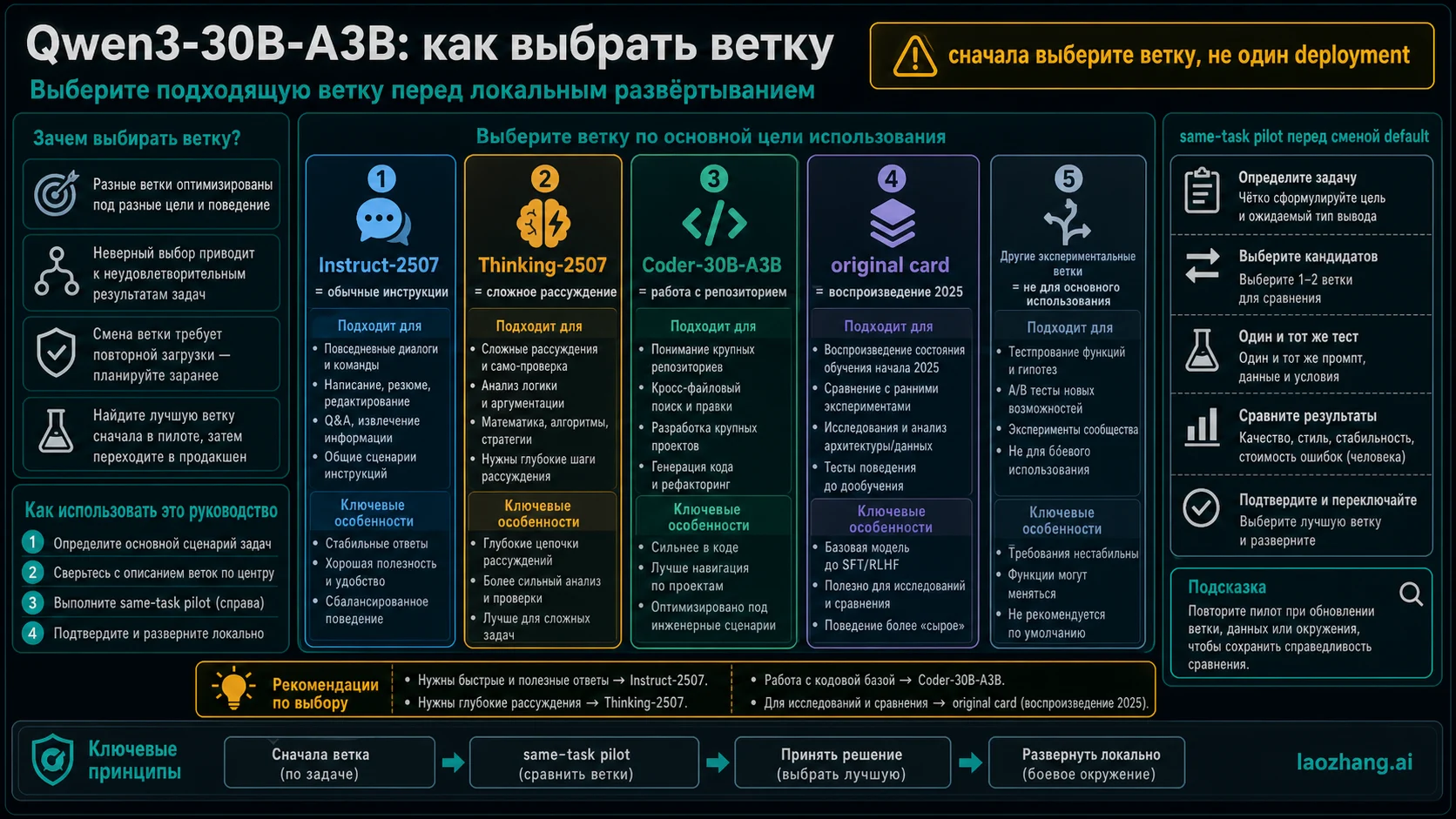
На 22 мая 2026 года Qwen3-30B-A3B нельзя воспринимать как один локальный deployment choice. Сначала выберите ветку: Qwen/Qwen3-30B-A3B-Instruct-2507 для обычных инструкций, summaries and chat; Qwen/Qwen3-30B-A3B-Thinking-2507 для задач, где длинное reasoning оправдывает задержку; Qwen/Qwen3-Coder-30B-A3B-Instruct для repo-scale coding; original Qwen/Qwen3-30B-A3B только когда нужно воспроизвести April 2025 hybrid model.
A3B объясняет sparse MoE shape, но не решает вопрос hardware, runtime tag или context length. На практике deployment зависит от branch, quantization, context budget, KV cache, inference framework, batch size, concurrency и типа задачи.
| Задача | Первая ветка | Проверка перед default switch |
|---|---|---|
| Fast local instruction, summaries, chat, ordinary agent prompts | Qwen/Qwen3-30B-A3B-Instruct-2507 | Это non-thinking branch, поэтому не ждите <think> traces. |
| Hard reasoning, planning, adversarial review | Qwen/Qwen3-30B-A3B-Thinking-2507 | Измерьте latency, verbosity, reviewer time и качество на сложных задачах. |
| Repository work, tool loops, long-context code tasks | Qwen/Qwen3-Coder-30B-A3B-Instruct | Оценивайте как Coder branch, не как alias original card. |
| April 2025 reproduction or old eval parity | Qwen/Qwen3-30B-A3B | Используйте original owner card и его 32K native context boundary. |
| Newer Qwen local/coding exploration | Оцените Qwen3.6-35B-A3B отдельно | Qwen3.6 является successor boundary, не той же model row. |
Stop rule: не заменяйте текущий default, пока same prompt, same files, same tools, same context budget, same tests, same latency budget, same retry policy и same reviewer rubric не пройдены на candidate branch без роста скрытых дефектов.
Быстрый выбор
Instruct-2507 является первой веткой для everyday local instruction. Она подходит для summaries, classification, drafting, ordinary agent prompts, small support tasks и ситуаций, где важны чистый answer shape и низкий review cost. Ее Hugging Face card позиционирует branch как non-thinking и фиксирует 262,144-token native context, поэтому ее проще тестировать как low-friction default.
Thinking-2507 стоит тестировать отдельно. Она нужна там, где reasoning behavior действительно снижает ошибку: multi-step math, planning, document synthesis, difficult review, adversarial checks. Риск не только в latency. Более длинный ответ может увеличить reviewer time, поэтому branch должен выигрывать не по впечатлению, а по accepted task rate and lower repair cost.
Coder-30B-A3B стоит ставить первым для code. Qwen3-Coder materials описывают coding and tool-use surface, поэтому он является правильным first test для repo search, cross-file edits, test-writing, refactor locality and tool-call discipline. Он все равно должен пройти реальные tests in your repo; branch name не заменяет verification.
Original card сохраняет ценность как baseline. Если задача связана с April 2025 Qwen3 writeups, old quantized builds, hybrid thinking/non-thinking behavior or previous eval parity, original Qwen/Qwen3-30B-A3B является правильным owner card. Для fresh default in 2026 нужна причина использовать более старую branch surface.
Что означает A3B
Qwen announcement и original Hugging Face card описывают sparse mixture-of-experts model. Owner card records 30.5B total parameters, 3.3B activated parameters, 48 layers, 128 experts and 8 active experts. Это объясняет привлекательность label для local experiments: per token активируется меньшая expert slice, хотя full model footprint остается крупным.
Но activated parameter label не превращается в простую VRAM formula. Loaded weights, quantization format, context length, KV cache, framework overhead, batch and concurrency меняют memory pressure. Short 4-bit chat, long-context code agent and high-concurrency service are different deployments.
Context rows также различаются. Original card records 32,768 native context and 131,072 with YaRN. Instruct-2507 and Thinking-2507 cards record 262,144 native context. Coder card records 262,144 native context and a 1M-with-YaRN boundary. Эти строки нужно держать в отдельных buckets before comparing speed or quality.

Как выбирать ветку
Выбор должен начинаться с cost of being wrong. Everyday instruction tasks чаще всего требуют stable format and fast correction. Reasoning tasks требуют fewer wrong conclusions. Coding tasks могут испортить repository, пропустить tests or create hidden defects. Поэтому одна ветка не должна автоматически выигрывать все сценарии.
Для normal local assistant work ставьте Instruct-2507 первым. Проверяйте answer quality, refusal boundary, formatting stability, concise behavior and ability to follow instructions without extra reasoning spillover. Если eval prompt ожидает visible thinking, вы тестируете не ту ветку.
Для hard reasoning ставьте Thinking-2507 отдельно. Хорошие tasks: multi-constraint planning, long synthesis, complex troubleshooting and review where explanation depth prevents mistakes. Если output becomes longer but does not reduce repair, branch remains experiment, not default.
Для code ставьте Coder-30B-A3B первым. Оценивайте file targeting, edit locality, test command choice, unnecessary changes, tool-loop recovery and review burden. Generic branch can write code snippets, but repo-scale work needs stricter measurement.
Для newer Qwen exploration отделите Qwen3.6. Если реальный вопрос уже про Qwen3.6 versus Kimi or GLM, используйте broader Qwen3.6 vs Kimi K2.6 vs GLM-5.1 route guide, а не растягивайте exact Qwen3-30B-A3B decision into a cross-model ranking.
Runtime route не владеет model facts
Ollama, LM Studio, llama.cpp, vLLM and SGLang полезны, потому что превращают model choice into runnable local setup. Но runtime tag не является upstream identity. Он может скрывать quantization, prompt template, default context and branch mapping. Перед quality comparison нужно проверить upstream model ID and branch.
Ollama qwen3:30b-a3b is useful as a convenience route. Use it to start quickly, observe local speed and memory behavior, and verify rough workflow fit. Do not use it as source of record for parameter count, expert count or context promises. These facts belong to Qwen and Hugging Face cards.
Community quantized packages follow the same rule. A GGUF, AWQ or GPTQ build can be exactly right for one GPU, but once quantization, template, context or server changes, you evaluate a deployment stack. Separating model identity from stack behavior makes failures easier to diagnose.

Hardware and context caveats
Honest hardware guidance is conditional. Quantization changes memory and sometimes quality. Longer context increases KV cache. Batch and concurrency raise peak pressure. Frameworks differ in offload, attention implementation and paging. A single VRAM number can describe one setup, not all Qwen3-30B-A3B deployments.
For quick chat, start with short context and measure load, first-token behavior, token speed and output stability. For code agents, include repository files, tool output, retries and realistic long context. For reasoning branch, record output length, reviewer time and whether mistakes actually decrease. Different tasks have different bottlenecks.
A conservative pilot starts small. Run the same branch and runtime on real but controlled tasks, then expand context step by step. Record memory pressure, crashes, paging, degraded quality and recovery. Do not jump straight to maximum context before short tasks are stable.
Same-task pilot
Model comparison becomes useful only when tasks stay identical. Choose five to ten real tasks: log explanation, summary, multi-step reasoning, small bug fix, cross-file refactor, test-writing, long-context reading and one ambiguous requirement. Current default and candidate Qwen branch must receive the same material.

| Test row | Keep identical | Record |
|---|---|---|
| Prompt | User task, system rules, output format | Whether it solves the task without repair |
| Context | Files, logs, snippets, token budget | Missed references, context drift, lost constraints |
| Tools | Commands, permissions, retry rules | Tool accuracy and unnecessary actions |
| Tests | Unit tests, eval set, manual checks | Accepted diff, failed checks, hidden defects |
| Operations | Hardware, runtime, quantization, batch | Latency, memory pressure, crashes, recovery time |
Switch only when candidate branch matches or beats current default on task completion, reviewer edits, retry count, hidden defects and operating cost. Faster output that creates more manual repair is not faster. Smarter output that misses your latency or memory budget is not a better default.
Owner sources to keep open
Keep source lanes separate. Qwen's Qwen3 announcement owns family framing, open-weight MoE context and model table. Qwen/Qwen3-30B-A3B Hugging Face card owns original model facts: parameters, experts, activated experts, hybrid behavior and original context boundary. Instruct-2507 and Thinking-2507 cards own branch behavior and 262K native context rows.
Qwen3-Coder-30B-A3B card and Qwen3-Coder blog own coding-agent branch framing. Ollama and local runtime pages own install convenience. Qwen3.6 material owns successor boundary. This separation keeps maintenance small when a branch or runtime tag changes.
FAQ
Qwen3-30B-A3B still worth running?
Yes, when the branch fits the job. Instruct-2507 is worth testing for compact local instruction work, Thinking-2507 for reasoning-heavy tasks, and Coder-30B-A3B for coding loops. Original branch is mostly for April 2025 reproduction and old comparisons.
Is A3B the same as a 3B model?
No. A3B refers to activated parameters in sparse MoE. Original owner card records 30.5B total parameters and 3.3B activated parameters. Deployment memory depends on the full stack.
Instruct-2507 or Thinking-2507?
Use Instruct-2507 for fast, clean answers without thinking traces. Use Thinking-2507 when hard reasoning is worth extra latency and review time.
Is Qwen3-Coder-30B-A3B the same model?
No. It is a related Coder branch. Test it first for repo-scale coding and tool use, but do not cite it as if it were the original card.
Can Ollama tell which branch is running?
Ollama gives a practical local route, but verify upstream model ID, quantization, context setting and prompt template. Runtime convenience is not official source ownership.
How much VRAM is needed?
No single number is honest for every setup. Quantization, context length, KV cache, framework overhead, batch and concurrency all change memory pressure.
When should Qwen3.6 be tested instead?
Test Qwen3.6-35B-A3B when the job is newer Qwen local/coding exploration rather than the exact Qwen3-30B-A3B branch decision. Keep it as successor comparison, not a silent replacement.