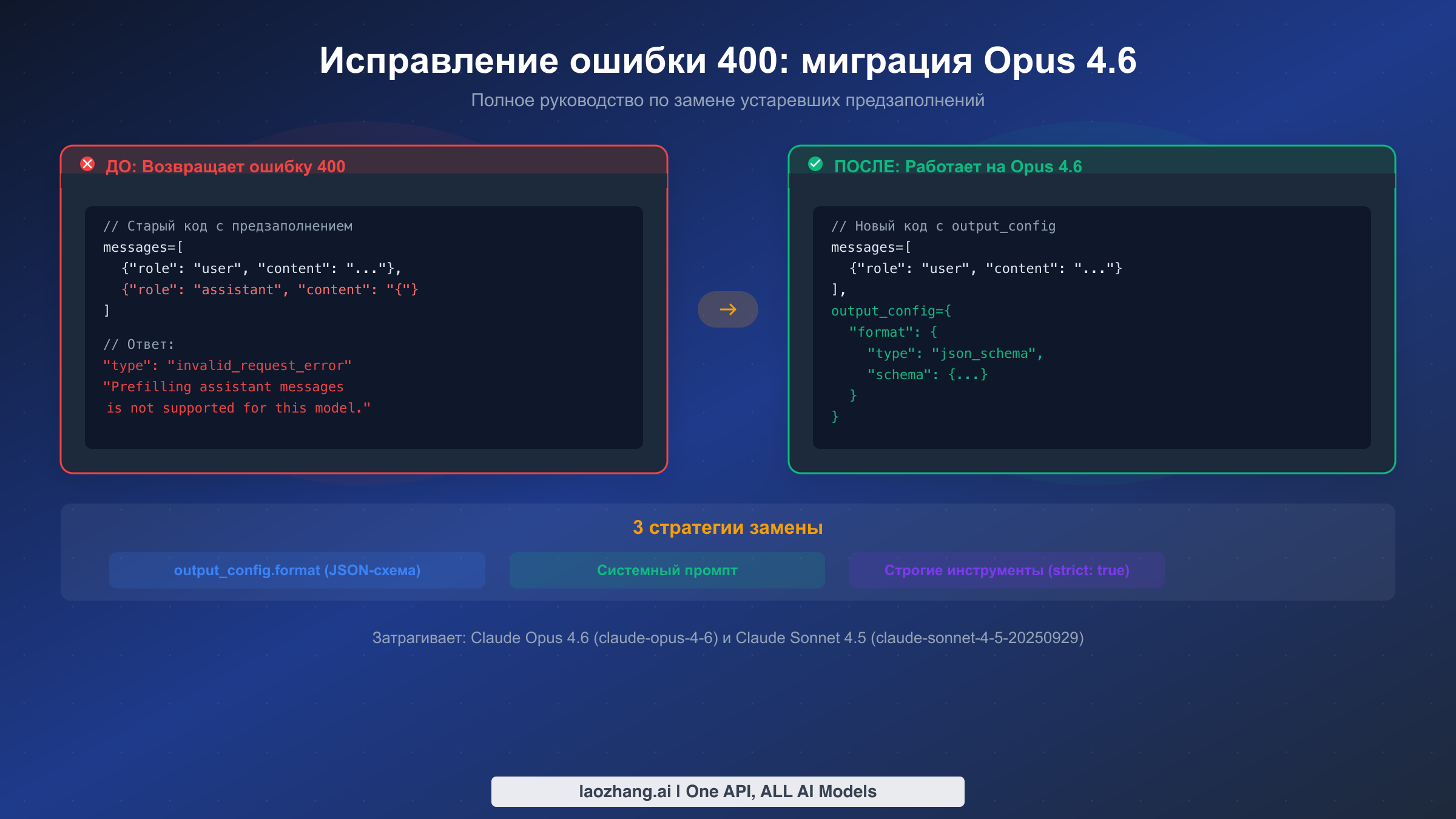
В Claude Opus 4.6 появилось критическое изменение, которое застаёт многих разработчиков врасплох: предзаполнение сообщений ассистента больше не работает. Если вы недавно обновили идентификатор модели на claude-opus-4-6 и ваши API-запросы начали возвращать ошибку 400, вы далеко не одиноки. В этом руководстве подробно разобрано, что именно изменилось, почему Anthropic принял такое решение и как исправить код с помощью трёх конкретных стратегий с полными примерами «до и после».
Краткое содержание
Anthropic убрал поддержку предзаполнения сообщений ассистента в Claude Opus 4.6 (claude-opus-4-6) и Sonnet 4.5 (claude-sonnet-4-5-20250929). Любой API-запрос, содержащий частично заполненное сообщение ассистента в качестве последнего элемента массива messages, вернёт ошибку 400 invalid_request_error с текстом: «Prefilling assistant messages is not supported for this model.»
У вас есть три варианта замены, в зависимости от сценария использования:
| Стратегия | Лучше всего подходит для | Сложность | Гарантия JSON |
|---|---|---|---|
output_config.format | Структурированные JSON-ответы | Средняя | Да, с валидацией по схеме |
| Инструкции в системном промпте | Управление стилем и форматом вывода | Низкая | Нет гарантии |
Строгие инструменты (strict: true) | Агентные рабочие процессы с вызовом функций | Высокая | Да, для параметров инструментов |
Самое быстрое исправление -- удалить предзаполненное сообщение ассистента из массива messages и добавить инструкции по форматированию в системный промпт. Для продакшн-приложений, требующих гарантированного JSON-вывода, переходите на output_config.format с определением JSON-схемы. Далее в руководстве показано, как именно реализовать каждый подход.
Почему Claude API возвращает 400 после обновления до Opus 4.6
Прежде чем переходить к исправлениям, важно понять, что такое предзаполнение и почему Anthropic его убрал. Этот контекст важен, потому что выбор стратегии замены зависит от того, для чего именно вы использовали предзаполнение.
Что такое предзаполнение. В более ранних моделях Claude можно было включить сообщение ассистента в качестве последнего элемента массива messages. Модель продолжала генерацию с этой точки, воспринимая ваш текст как начало своего ответа. Разработчики часто использовали эту технику, чтобы принудительно получить JSON-вывод, начав с {, контролировать формат ответа предзаполнением определённой структуры или направить модель к нужному стилю ответа, задав первые слова.
Вот типичный пример того, как предзаполнение выглядело на практике. Вы отправляли пользовательское сообщение с запросом данных, а затем добавляли сообщение ассистента, содержащее только открывающую фигурную скобку. Модель подхватывала эту скобку и достраивала JSON-объект, что с высокой вероятностью (но без гарантии) давало валидный JSON на выходе.
pythonresponse = client.messages.create( model="claude-3-5-sonnet-20241022", max_tokens=1024, messages=[ {"role": "user", "content": "List the top 3 programming languages"}, {"role": "assistant", "content": "{"} # Prefilling ] )
Что происходит теперь в Opus 4.6. Когда вы отправляете такой же запрос с model="claude-opus-4-6", API немедленно отклоняет его ещё до начала генерации токенов. Ответ, который вы получите -- не вывод модели, а объект ошибки:
json{ "type": "error", "error": { "type": "invalid_request_error", "message": "Prefilling assistant messages is not supported for this model." } }
HTTP-код ответа -- 400, что означает ошибку на стороне клиента. Ваш запрос не соответствует требованиям новой модели. Токены не расходуются, тарификация не производится, но приложение перестанет работать в этом месте, если вы не обработаете ошибку.
Почему Anthropic принял это решение. Удаление предзаполнения -- часть более широкого архитектурного перехода в моделях Claude 4.x к надёжным механизмам структурированного вывода. Предзаполнение всегда было обходным решением, а не полноценной функцией API. У него было несколько фундаментальных ограничений: оно не могло гарантировать валидный JSON (модель всё равно могла выдать некорректный вывод), расходовало токены контекстного окна без чёткой атрибуции и конфликтовало с новыми функциями вроде расширенного мышления, где модели необходимо контролировать собственный поток ответа. Убрав предзаполнение, Anthropic получила возможность предложить по-настоящему гарантированный структурированный вывод через output_config.format, который валидирует данные по JSON-схеме на уровне API, а не полагается на трюк с генерацией.
Какие модели затронуты. Согласно актуальной документации Anthropic (февраль 2026), предзаполнение не поддерживается в Claude Opus 4.6 (claude-opus-4-6) и Claude Sonnet 4.5 (claude-sonnet-4-5-20250929). Более старые модели, такие как Claude 3.5 Sonnet и Claude 3 Opus, по-прежнему поддерживают предзаполнение, поэтому существующий код, нацеленный на эти идентификаторы моделей, продолжит работать. Однако эти модели рано или поздно будут объявлены устаревшими, так что миграция неизбежна.
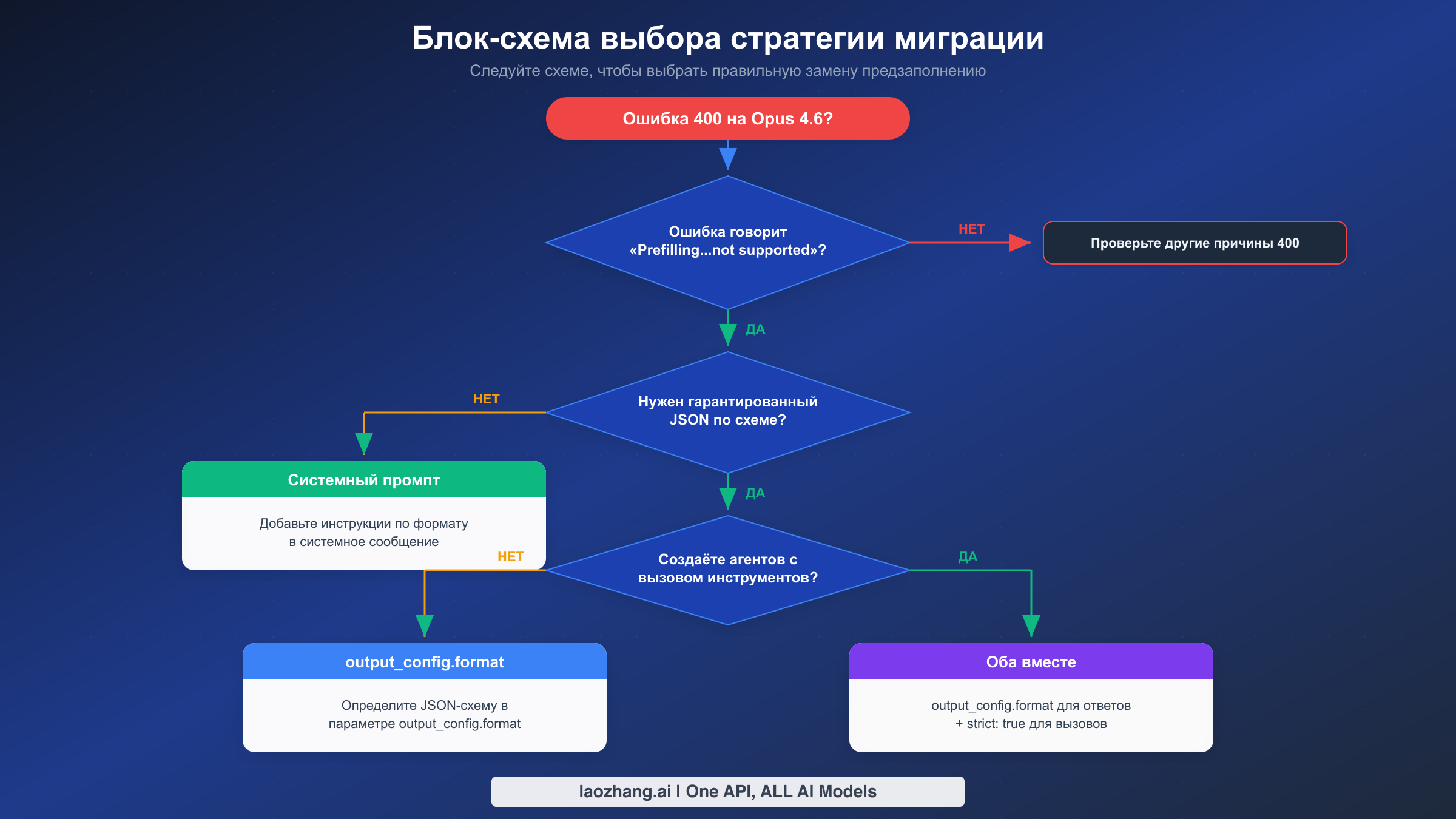
Как убедиться, что проблема именно в этом. Самый быстрый способ проверить, что вы столкнулись именно с ошибкой предзаполнения (а не с другой ошибкой 400) -- посмотреть текст сообщения об ошибке в теле ответа API. Точный текст: «Prefilling assistant messages is not supported for this model.» Если вы видите другое сообщение, например «messages: roles must alternate between 'user' and 'assistant'» или «model not found», это другая проблема. Также проверьте обработку ошибок вашего HTTP-клиента: некоторые фреймворки перехватывают код 400, но отбрасывают тело ответа, что затрудняет просмотр фактического сообщения об ошибке. Убедитесь, что ваш обработчик ошибок логирует полный JSON ответа, а не только код состояния.
Три способа заменить предзаполнение в коде для Claude
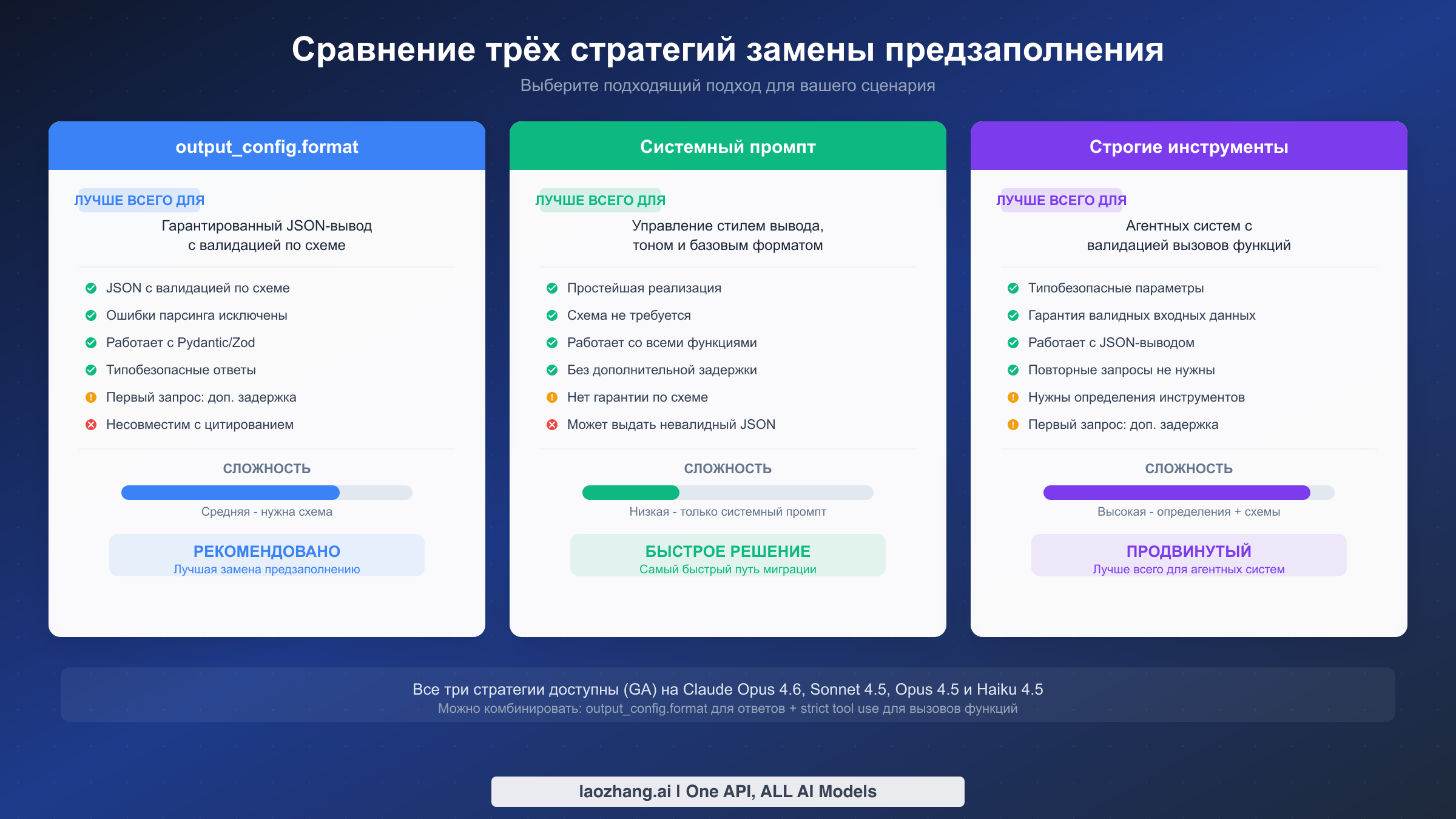
Выбор правильной замены зависит от того, для чего вы использовали предзаполнение. У каждой стратегии свои компромиссы в плане сложности реализации, гарантий вывода и совместимости с другими функциями Claude. Рассмотрим каждый подход подробно, чтобы вы могли принять обоснованное решение.
Стратегия 1: output_config.format с JSON-схемой. Это рекомендованная Anthropic замена предзаполнения, когда нужен гарантированный структурированный вывод. Вы определяете JSON-схему, описывающую точную форму нужного ответа, и API обеспечивает соответствие вывода модели этой схеме. Валидация происходит на уровне API, а не через промпт-инженерию, что означает: вы никогда не получите некорректный JSON.
Ключевое преимущество -- надёжность. В отличие от предзаполнения, которое лишь подталкивало модель к JSON-выводу, output_config.format даёт жёсткую гарантию. Если вы определите схему с обязательными полями, ответ всегда будет содержать эти поля с правильными типами данных. Это устраняет необходимость в логике повторных запросов или обработке ошибок парсинга JSON, которые были обычным делом при подходе через предзаполнение. Компромисс в том, что нужно заранее определить схему, а первый запрос с новой схемой потребует дополнительное время на компиляцию ограничений схемы. Последующие запросы с той же схемой работают быстро.
Важное ограничение, которое стоит учесть: output_config.format сейчас несовместим с цитированием. Если ваше приложение использует функцию цитирования Claude, придётся выбрать другую стратегию.
Стратегия 2: Инструкции в системном промпте. Это самый простой путь миграции, который хорошо работает, когда строгая валидация по схеме не нужна. Вместо предзаполнения сообщения ассистента для подсказки о нужном формате вы включаете явные инструкции по форматированию в системный промпт. Например, можно добавить: «Всегда отвечай валидным JSON следующей структуры:», после чего привести пример.
Преимущество -- нулевая дополнительная сложность. Не нужно определять схемы, устанавливать новые версии SDK или менять логику парсинга ответов. Подход с системным промптом также работает со всеми функциями Claude, включая цитирование, расширенное мышление и использование инструментов. Недостаток в том, что нет гарантии, что модель каждый раз будет выдавать валидный JSON. Модели Claude 4.x очень надёжны в следовании инструкциям системного промпта, но крайние случаи существуют, особенно при очень сложных вложенных структурах или когда модели нужно выразить неопределённость.
Стратегия 3: Строгое использование инструментов с strict: true. Этот подход лучше всего подходит для агентных рабочих процессов, где модели нужно выдавать структурированные данные в рамках конвейера вызова функций. Вы определяете инструменты с входными схемами и устанавливаете strict: true для каждого определения инструмента. API тогда гарантирует, что параметры вызова инструмента соответствуют схеме, аналогично тому, как output_config.format работает для прямых ответов.
Эта стратегия наиболее оправдана, когда вы уже используете вызов инструментов в приложении. Можно определить инструмент «response», единственная цель которого -- структурировать вывод модели, фактически превращая использование инструментов в механизм структурированного вывода. Сложность выше, чем у двух других подходов, поскольку нужны определения инструментов и особая обработка ответов с использованием инструментов (в отличие от обычных текстовых ответов). Однако строгие инструменты можно комбинировать с output_config.format: первое -- для параметров вызова функций, второе -- для прямых ответов, обеспечивая полное покрытие всего приложения.
| Функция | output_config.format | Системный промпт | Строгие инструменты |
|---|---|---|---|
| Гарантия JSON | Да | Нет | Да (параметры) |
| Требуется схема | Да | Нет | Да |
| Задержка при первом запросе | Повышенная | Нет | Повышенная |
| Работает с цитированием | Нет | Да | Да |
| Работает с мышлением | Да | Да | Да |
| Сложность реализации | Средняя | Низкая | Высокая |
| Лучше всего для | API-ответов | Быстрой миграции | Агентных систем |
Пошаговая миграция с примерами кода
В этом разделе представлен полный код «до и после» для каждой стратегии замены. Вы можете скопировать эти примеры прямо в свой проект. Все примеры используют актуальные версии SDK Anthropic и соответствуют официальной спецификации API по состоянию на февраль 2026.
Путь миграции 1: от предзаполнения к output_config.format
Это самый распространённый путь миграции для приложений, которые использовали предзаполнение для принудительного JSON-вывода. Старый код включал сообщение ассистента с открывающей скобкой; новый код вместо этого использует определение структурированной схемы.
До (не работает на Opus 4.6):
pythonimport anthropic client = anthropic.Anthropic() # This returns 400 on Opus 4.6 response = client.messages.create( model="claude-opus-4-6", max_tokens=1024, system="You are a helpful assistant that provides data in JSON format.", messages=[ {"role": "user", "content": "List the top 3 programming languages by popularity"}, {"role": "assistant", "content": "{"} # BREAKS on Opus 4.6 ] )
После (работает на Opus 4.6):
pythonimport anthropic client = anthropic.Anthropic() response = client.messages.create( model="claude-opus-4-6", max_tokens=1024, system="You are a helpful assistant that provides data in JSON format.", messages=[ {"role": "user", "content": "List the top 3 programming languages by popularity"} ], output_config={ "format": { "type": "json_schema", "schema": { "type": "object", "properties": { "languages": { "type": "array", "items": { "type": "object", "properties": { "name": {"type": "string"}, "rank": {"type": "integer"}, "description": {"type": "string"} }, "required": ["name", "rank", "description"], "additionalProperties": False } } }, "required": ["languages"], "additionalProperties": False } } } ) # Response content is guaranteed valid JSON matching your schema import json data = json.loads(response.content[0].text) print(data["languages"][0]["name"]) # Guaranteed to exist
Если вы используете Pydantic для валидации данных, Python SDK от Anthropic предоставляет удобный метод .parse(), который объединяет генерацию схемы и парсинг ответа в одном шаге:
pythonfrom pydantic import BaseModel from typing import List class Language(BaseModel): name: str rank: int description: str class LanguageList(BaseModel): languages: List[Language] # Pydantic integration - schema auto-generated from model response = client.messages.parse( model="claude-opus-4-6", max_tokens=1024, messages=[ {"role": "user", "content": "List the top 3 programming languages by popularity"} ], output_format=LanguageList, ) # response.parsed is already a LanguageList instance for lang in response.parsed.languages: print(f"{lang.rank}. {lang.name}: {lang.description}")
Эквивалент на TypeScript:
typescriptimport Anthropic from "@anthropic-ai/sdk"; import { z } from "zod"; const client = new Anthropic(); // Using Zod schema const LanguageSchema = z.object({ languages: z.array(z.object({ name: z.string(), rank: z.number(), description: z.string(), })), }); const response = await client.messages.create({ model: "claude-opus-4-6", max_tokens: 1024, messages: [ { role: "user", content: "List the top 3 programming languages by popularity" } ], output_config: { format: { type: "json_schema", schema: LanguageSchema, }, }, }); const data = JSON.parse(response.content[0].text); console.log(data.languages[0].name);
Путь миграции 2: от предзаполнения к системному промпту
Это самая быстрая миграция, когда гарантии на уровне схемы не нужны. Вы просто удаляете сообщение ассистента и переносите инструкции по форматированию в системный промпт.
До (не работает на Opus 4.6):
pythonresponse = client.messages.create( model="claude-opus-4-6", max_tokens=1024, messages=[ {"role": "user", "content": "Analyze this code for bugs"}, {"role": "assistant", "content": "## Bug Analysis\n\n"} # BREAKS ] )
После (работает на Opus 4.6):
pythonresponse = client.messages.create( model="claude-opus-4-6", max_tokens=1024, system=( "You are a code review assistant. Always structure your response as follows:\n" "1. Start with a '## Bug Analysis' heading\n" "2. List each bug with severity level\n" "3. Provide fix suggestions for each bug" ), messages=[ {"role": "user", "content": "Analyze this code for bugs"} ] )
Подход с системным промптом особенно эффективен для управления стилем и структурой ответа без необходимости JSON. Если вы использовали предзаполнение для начала ответа определённым текстом -- заголовком или конкретной фразой -- в подавляющем большинстве случаев это правильная стратегия замены. Один приём, который хорошо работает, -- включить явный пример нужного формата вывода прямо в системный промпт. Вместо того чтобы надеяться, что модель последует расплывчатым инструкциям, покажите ей, как именно должны выглядеть первые строки хорошего ответа. Модели Claude 4.x отлично следуют продемонстрированным паттернам, и этот подход надёжнее старого трюка с предзаполнением, оставаясь при этом гораздо проще определения полной JSON-схемы.
Для случаев, когда нужно единообразное форматирование в тысячах API-запросов (например, чат-бот для клиентов, который должен всегда отвечать в определённом тоне), комбинируйте системный промпт с примерами few-shot в пользовательском сообщении. Включите один-два примера нужного формата «вопрос-ответ», а затем задайте фактический вопрос. Это даёт модели чёткие ориентиры без ограничений предзаполнения или накладных расходов на определение схемы.
Путь миграции 3: от предзаполнения к строгим инструментам
Этот путь идеален при создании агентов или когда нужны структурированные параметры вызова функций. Вы определяете инструмент со строгой схемой, и вызовы модели гарантированно соответствуют этой схеме.
До (не работает на Opus 4.6):
pythonresponse = client.messages.create( model="claude-opus-4-6", max_tokens=1024, messages=[ {"role": "user", "content": "What's the weather in Tokyo?"}, {"role": "assistant", "content": '{"tool": "get_weather", "args": {"city": "'} ] )
После (работает на Opus 4.6):
pythonresponse = client.messages.create( model="claude-opus-4-6", max_tokens=1024, messages=[ {"role": "user", "content": "What's the weather in Tokyo?"} ], tools=[ { "name": "get_weather", "description": "Get current weather for a city", "strict": True, "input_schema": { "type": "object", "properties": { "city": {"type": "string", "description": "City name"}, "units": { "type": "string", "enum": ["celsius", "fahrenheit"], "description": "Temperature units" } }, "required": ["city"], "additionalProperties": False } } ] ) # Tool calls are guaranteed to match the schema for block in response.content: if block.type == "tool_use": print(f"Tool: {block.name}") print(f"Input: {block.input}") # Always valid JSON matching schema
Пример cURL для output_config.format:
bashcurl https://api.anthropic.com/v1/messages \ -H "content-type: application/json" \ -H "x-api-key: $ANTHROPIC_API_KEY" \ -H "anthropic-version: 2023-06-01" \ -d '{ "model": "claude-opus-4-6", "max_tokens": 1024, "messages": [ {"role": "user", "content": "List 3 programming languages"} ], "output_config": { "format": { "type": "json_schema", "schema": { "type": "object", "properties": { "languages": { "type": "array", "items": { "type": "object", "properties": { "name": {"type": "string"}, "rank": {"type": "integer"} }, "required": ["name", "rank"], "additionalProperties": false } } }, "required": ["languages"], "additionalProperties": false } } } }'
Типичные подводные камни и граничные случаи
Даже после удаления предзаполненного сообщения ассистента и реализации одной из трёх стратегий замены существует ряд тонких проблем, которые могут осложнить миграцию. В этом разделе рассмотрены наиболее распространённые проблемы, с которыми сталкиваются разработчики, на основе issues в GitHub, отчётов сообщества и официальной документации по миграции.
Взаимодействие расширенного мышления и предзаполнения. Если ваше приложение ранее использовало предзаполнение совместно с функцией мышления Claude, при миграции нужно быть особенно внимательным. Opus 4.6 также изменил API мышления: thinking: {type: "enabled", budget_tokens: 32000} объявлен устаревшим в пользу thinking: {type: "adaptive"} в сочетании с новым параметром effort. Попытка использовать старую конфигурацию мышления вместе со старым паттерном предзаполнения приведёт к ошибке, отличной от ошибки только предзаполнения, что может усложнить отладку.
Правильная миграция для приложений, использующих обе функции, выглядит так:
python# Before: prefilling + old thinking (broken on Opus 4.6) response = client.messages.create( model="claude-opus-4-6", max_tokens=16000, thinking={"type": "enabled", "budget_tokens": 10000}, betas=["interleaved-thinking-2025-05-14"], messages=[ {"role": "user", "content": "Analyze this dataset"}, {"role": "assistant", "content": "{"} ] ) # After: output_config + adaptive thinking (works on Opus 4.6) response = client.messages.create( model="claude-opus-4-6", max_tokens=16000, thinking={"type": "adaptive"}, output_config={ "effort": "high", "format": { "type": "json_schema", "schema": { "type": "object", "properties": { "analysis": {"type": "string"}, "key_findings": { "type": "array", "items": {"type": "string"} } }, "required": ["analysis", "key_findings"], "additionalProperties": False } } }, messages=[ {"role": "user", "content": "Analyze this dataset"} ] ) # No beta headers needed - both features are GA on Opus 4.6
Обратите внимание на три одновременных изменения: предзаполнение удалено, конфигурация мышления обновлена и бета-заголовок убран. Пропуск любого из этих изменений вызовет другую ошибку, поэтому обрабатывайте их вместе.
Различия в экранировании параметров инструментов. Opus 4.6 обрабатывает JSON-экранирование в параметрах вызова инструментов иначе, чем более ранние модели. Если ваш код полагается на определённые паттерны форматирования JSON во входных параметрах вызова инструментов (например, предполагает двойное экранирование кавычек или определённое форматирование пробелов), могут возникнуть ошибки парсинга, даже если вызов инструмента семантически корректен. Исправление простое: всегда используйте стандартный JSON-парсер (json.loads() в Python, JSON.parse() в JavaScript) вместо поиска строк или извлечения через регулярные выражения из параметров вызова инструментов.
Требование additionalProperties: false. При использовании output_config.format с type: "json_schema" каждый объект в схеме должен содержать "additionalProperties": false. Это не просто лучшая практика -- API отклонит схемы, в которых это поле отсутствует. Если вы генерируете схемы программно из классов данных или интерфейсов TypeScript, убедитесь, что ваш генератор схем добавляет это свойство. Pydantic и Zod обрабатывают это автоматически при использовании с соответствующими методами SDK, но кастомные генераторы схем часто пропускают это.
python# This will be rejected by the API bad_schema = { "type": "object", "properties": {"name": {"type": "string"}}, "required": ["name"] # Missing: "additionalProperties": false } # This works good_schema = { "type": "object", "properties": {"name": {"type": "string"}}, "required": ["name"], "additionalProperties": False # Required! }
Проверка версий в мультимодельных приложениях. Если ваше приложение поддерживает несколько моделей Claude (например, Opus 4.6 для сложных задач и Haiku 4.5 для простых), нужна условная логика для предзаполнения. Нельзя использовать один и тот же массив messages для обоих путей модели. Самый чистый подход -- динамически собирать массив messages на основе целевой модели, а ещё лучше -- перевести все пути моделей на одну из трёх стратегий замены, которые единообразно работают на всех текущих моделях Claude.
Стриминг и output_config.format. При использовании output_config.format с включённым стримингом ответ по-прежнему приходит в виде инкрементальных текстовых фрагментов. JSON не валидируется до завершения полного ответа. Это означает, что нельзя надёжно парсить частичный JSON из фрагментов стрима. Если нужна инкрементальная обработка, используйте подход с системным промптом для сценариев стриминга и output_config.format для запросов без стриминга. Как альтернатива -- спроектируйте схему с массивами на верхнем уровне, где каждый элемент может быть обработан независимо по мере поступления.
Особенности Vertex AI и Amazon Bedrock. Если вы обращаетесь к Claude через Google Cloud Vertex AI или Amazon Bedrock, а не напрямую через API Anthropic, ограничение предзаполнения действует точно так же. Сообщение об ошибке и поведение одинаковы вне зависимости от хостинг-платформы. Однако названия методов SDK и пути параметров могут немного отличаться. На Vertex AI параметр output_config передаётся через ту же структуру messages API. На Bedrock убедитесь, что используете последнюю версию AWS SDK, поддерживающую параметр output_config, так как старые версии SDK могут не предоставлять это поле. Ознакомьтесь с документацией конкретной платформы для точного соответствия параметров и имейте в виду, что новые функции Anthropic API иногда появляются на Vertex AI и Bedrock через несколько дней после запуска на прямом API.
Плавный переход в переходный период. Во время миграции вы, возможно, захотите, чтобы приложение поддерживало и старые, и новые модели одновременно, особенно если разные клиенты или окружения используют разные версии моделей. Практичный подход -- создать функцию-обёртку, которая проверяет идентификатор модели и соответственно корректирует запрос:
pythondef create_message(client, model, messages, system=None, output_schema=None, **kwargs): """Wrapper that handles prefilling differences across model versions.""" # Models that don't support prefilling no_prefill_models = ["claude-opus-4-6", "claude-sonnet-4-5-20250929"] # Check if last message is an assistant prefill if messages and messages[-1]["role"] == "assistant": if model in no_prefill_models: # Remove prefill and use output_config instead messages = messages[:-1] if output_schema: kwargs["output_config"] = { "format": { "type": "json_schema", "schema": output_schema } } return client.messages.create( model=model, messages=messages, system=system, **kwargs )
Этот паттерн позволяет мигрировать инкрементально, не ломая существующую функциональность. По мере подтверждения работы каждого пути кода с новым подходом можно убирать слой совместимости и использовать output_config.format напрямую.
Если вы столкнётесь с другими ошибками Claude API помимо проблемы предзаполнения, например с проблемами аутентификации по API-ключу, руководство по диагностике ошибок аутентификации Claude API может помочь разобраться с ними отдельно.
Полный чек-лист миграции

Используйте этот чек-лист, чтобы убедиться, что вы учли все аспекты миграции. Каждый пункт помечен как критическое изменение (нужно исправить до развёртывания) или рекомендуемое изменение (стоит исправить для соответствия лучшим практикам). Сначала пройдите критические изменения, затем займитесь рекомендуемыми.
Критические изменения, которые необходимо исправить:
Следующие пункты приведут к сбою ваших API-вызовов, если их не устранить. Каждый из них вызывает ошибку 400 или неожиданное поведение на Opus 4.6.
Во-первых, найдите во всём коде все случаи, когда сообщение ассистента является последним элементом массива messages. Это основная причина ошибки предзаполнения. Удалите эти сообщения ассистента и замените их одной из трёх описанных выше стратегий. Обратите особое внимание на пути кода, динамически формирующие массив messages, поскольку логика предзаполнения может быть спрятана во вспомогательных функциях или промежуточном ПО.
Во-вторых, обновите идентификатор модели на claude-opus-4-6. Если вы привязаны к конкретной версии модели, а не используете алиас, убедитесь, что строка совпадает в точности. Формат идентификатора модели для Opus 4.6 не включает суффикс даты, в отличие от моделей Sonnet и Haiku.
В-третьих, убедитесь, что парсинг JSON использует стандартный парсер. Если вы извлекали JSON из предзаполненных ответов через срезы строк (например, удаляя предзаполненную { из начала ответа), эта логика больше не нужна и сломается с новым форматом структурированного вывода. Используйте json.loads() или JSON.parse() для полного содержимого ответа.
В-четвёртых, при миграции с Claude 3.x убедитесь, что вы не отправляете temperature и top_p в одном запросе одновременно. Opus 4.6 требует указания только одного из этих параметров семплирования.
В-пятых, обработайте новые причины остановки. Opus 4.6 может возвращать refusal и context_window в качестве причин остановки в дополнение к существующим end_turn, max_tokens, stop_sequence и tool_use. Если в вашем коде есть switch-оператор или условная логика по причине остановки, добавьте обработку этих новых значений для предотвращения непредвиденного поведения.
Рекомендуемые изменения для лучших практик:
Эти пункты не вызовут немедленных сбоев, но представляют устаревшие паттерны, которые будут удалены в будущих версиях. Если устранить их сейчас, это избавит от ещё одной экстренной миграции позже.
Перейдите с thinking: {type: "enabled"} на thinking: {type: "adaptive"}. Старая конфигурация мышления пока работает на Opus 4.6, но помечена как устаревшая и будет удалена. Адаптивное мышление эффективнее, поскольку модель динамически распределяет усилия на мышление в зависимости от сложности задачи, вместо фиксированного бюджета.
Перейдите с output_format на output_config.format. Устаревший параметр output_format пока работает, но объявлен устаревшим. Новый параметр output_config является надмножеством, которое также поддерживает параметр effort для управления усилиями на мышление.
Удалите бета-заголовки, которые больше не нужны. Следующие бета-флаги теперь являются GA-функциями на Opus 4.6, и их включение не даёт эффекта: interleaved-thinking-2025-05-14, effort-2025-11-24, fine-grained-tool-streaming-2025-05-14. Также удалите устаревшие бета-заголовки token-efficient-tools-2025-02-19 и output-128k-2025-02-19, которые тоже стали GA.
Финальные шаги перед развёртыванием:
Перед выпуском в продакшн запустите полный набор тестов для Opus 4.6 в среде разработки. Обратите особое внимание на тесты, проверяющие формат ответа, так как именно они с наибольшей вероятностью будут затронуты удалением предзаполнения. Убедитесь, что все API-ответы корректно парсятся с новым форматом структурированного вывода. После развёртывания мониторьте частоту ошибок в течение 24 часов и держите план отката наготове. Возврат к claude-sonnet-4-5-20250929 или предыдущей модели -- это допустимая краткосрочная стратегия при возникновении непредвиденных проблем.
Другие критические изменения в Opus 4.6, которые стоит знать
Хотя удаление предзаполнения -- самое разрушительное изменение, Opus 4.6 включает несколько других критических изменений, которые могут затронуть ваше приложение. Если устранить их в рамках той же миграции, это сэкономит несколько циклов развёртывания.
Адаптивное мышление заменяет фиксированные бюджеты мышления. Конфигурация thinking: {type: "enabled", budget_tokens: N} объявлена устаревшей. Замена -- thinking: {type: "adaptive"}, которая позволяет модели самой решать, сколько усилий на мышление применить в зависимости от сложности задачи. Влиять на это можно параметром effort (доступны уровни max, high, medium, low, min), который теперь является GA-функцией и больше не требует бета-заголовка effort-2025-11-24. Если вы тонко настраивали бюджеты мышления для определённых сценариев, параметр effort обеспечивает аналогичный уровень контроля с меньшими операционными издержками.
Параметр output_format объявлен устаревшим. Если вы уже использовали структурированный вывод через старый параметр output_format, имейте в виду, что он теперь устарел в пользу output_config.format. Синтаксис немного отличается:
python# Deprecated (still works, will be removed) response = client.messages.create( model="claude-opus-4-6", output_format={"type": "json_schema", "schema": {...}}, ... ) # Current (recommended) response = client.messages.create( model="claude-opus-4-6", output_config={ "format": {"type": "json_schema", "schema": {...}} }, ... )
Параметр output_config является контейнером, который также поддерживает effort наряду с format, делая его более расширяемым.
Новые возможности, которые стоит освоить. Opus 4.6 приносит несколько улучшений, которые могут оправдать усилия по миграции помимо простого исправления ошибки предзаполнения. Модель теперь поддерживает 128K выходных токенов (вдвое больше предыдущих лимитов), что делает её подходящей для задач генерации длинных текстов, которые раньше требовали нескольких API-вызовов. Доступен новый быстрый режим в качестве исследовательского превью по цене 30 /M выходных токенов, предлагающий примерно 2,5-кратное ускорение генерации для приложений, чувствительных к задержке. API компактификации (бета) позволяет выполнять серверное сжатие контекста для длинных диалогов, что особенно ценно для чат-приложений, упирающихся в лимиты контекстного окна. Контроль размещения данных позволяет указать, где происходит обработка инференса, через параметр inference_geo, что отвечает требованиям комплаенса для организаций, работающих в рамках GDPR или аналогичных требований к суверенитету данных.
Ценовая структура Opus 4.6 составляет 15 за миллион выходных токенов в стандартном режиме (документация Anthropic, февраль 2026). Для сравнения, Sonnet 4.5 предлагает значительно более низкую цену -- 3/15 за MTok. Если миграция с предзаполнения совпадает с более широкой оптимизацией расходов, рассмотрите, могут ли некоторые из ваших нагрузок на Opus обрабатываться Sonnet 4.5 со структурированным выводом, который обеспечивает те же возможности output_config.format за пятую часть стоимости.
Для подробного сравнения Opus 4.6 и Sonnet 4.5 по различным категориям задач, включая бенчмарки и компромиссы по стоимости, смотрите наше сравнение Claude Opus и Sonnet.
Следите за изменениями Claude API
API Claude развивается стремительно, и своевременное отслеживание критических изменений предотвращает инциденты в продакшне вроде удаления предзаполнения. Anthropic публикует руководства по миграции для каждого крупного релиза модели, которые являются наиболее надёжным источником информации об устаревших функциях и их заменах. Официальная документация на platform.claude.com/docs обновляется в реальном времени и должна быть вашим основным справочником при любой миграции.
Независимо от того, исправляете ли вы ошибку предзаполнения прямо сейчас или планируете более масштабную миграцию на Opus 4.6, ключевой вывод таков: предзаполнение сообщений ассистента окончательно удалено из текущих моделей Claude. Чем скорее вы перейдёте на одну из трёх стратегий структурированного вывода (output_config.format, системные промпты или строгие инструменты), тем устойчивее станет ваше приложение к будущим изменениям API. Начните со стратегии, соответствующей вашему текущему сценарию использования, тщательно протестируйте в среде разработки и развёртывайте с уверенностью.
Миграция с предзаполнения на структурированный вывод -- это в конечном счёте позитивное изменение для продакшн-приложений. Хотя предзаполнение было изобретательным хаком, который удивительно хорошо работал, оно никогда не проектировалось как полноценная продакшн-функция. Новые подходы предлагают настоящие гарантии, лучшую обработку ошибок и интеграцию с остальной экосистемой API Claude. Краткосрочные усилия на миграцию окупаются более надёжным, поддерживаемым кодом, который продолжит работать по мере эволюции моделей Claude.