
Самая дешевая LLM API модель не является одним постоянным победителем. Это самая низкая по полной стоимости модель, которая проходит ваш quality bar, выдерживает нужную длину ответа, подходит по privacy boundary, не ломает latency budget и не создает лишние retries. Проверка от 2 июля 2026 года начинается с официальных price rows владельцев моделей, а затем добавляет cached input, output tokens, Batch/Flex, free-tier terms, provider contracts и стоимость принятого результата.
| Workload | Первый дешевый тест | Официальный price anchor | Когда это уже не дешево |
|---|---|---|---|
| Bulk extraction, short answers, cache-heavy jobs | deepseek-v4-flash | $0.0028 cache-hit input, $0.14 cache-miss input, $0.28 output per 1M tokens | если качество, регион, latency или availability не проходят |
| OpenAI-native apps, low-cost calls, Batch/Flex | gpt-5-nano | $0.05 input, $0.005 cached input, $0.40 output; Batch/Flex ниже | если output length, tool calls или retries доминируют |
| Lowest Google scale lane | gemini-2.5-flash-lite | $0.10 input, $0.40 output; Batch/Flex $0.05 / $0.20 | если lifecycle или качество требуют 3.1 lane |
| Newer Google high-volume lane | gemini-3.1-flash-lite | $0.25 input, $1.50 output; Batch/Flex $0.125 / $0.75 | если нужен именно самый дешевый Google row |
| Cheap rows fail quality | Claude Haiku 4.5 | $1 input, $5 output / MTok plus caching and Batch modifiers | если более дешевый lane уже проходит качество |
Stop rule: не выбирайте модель только по input price. Прогоните одинаковые реальные prompts, посчитайте input, cached input, output, tools, retries, latency, free-tier terms и provider contract, а затем сравните accepted-output cost.
Сначала официальная таблица цен
Официальная страница владельца модели является первой доказательной поверхностью. Только она подтверждает model ID, billing unit, текущую цену, discount mode и caveats. Aggregators полезны для discovery, но они не превращаются в официальные цены OpenAI, Google, DeepSeek, Anthropic или Mistral. Поэтому таблицу нужно читать как shortlist, а не как production contract.
На 2 июля 2026 года OpenAI pricing показывает gpt-5-nano со standard input / cached input / output $0.05 / $0.005 / $0.40 per 1M tokens и более низкими Batch/Flex rows. Google pricing разделяет gemini-2.5-flash-lite и gemini-3.1-flash-lite: первая дешевле для Google scale lane, вторая новее, но дороже. DeepSeek pricing показывает deepseek-v4-flash с отдельными cache-hit, cache-miss и output rows. Anthropic pricing ставит Claude Haiku 4.5 как дешевый Claude quality lane, но не как raw cheapest row.
Формула реальной стоимости
Реальная цена API зависит от принятого результата, а не от красивой строки input tokens. Если модель требует длинных ответов, часто нарушает schema, возвращает слабое reasoning или создает много retries, ее invoice может стать выше, чем у более дорогой модели. Минимальная формула включает input tokens, cached input, output tokens, tool calls, quality retries, batch/flex latency tradeoff, region, tax, data terms и support boundary.

Практический тест должен использовать 20-50 representative prompts. Для каждого кандидата сохраните prompt, input size, output size, cache hit, attempts, accepted/rejected status, p50/p95 latency и причину отказа. Потом разделите total bill на количество accepted outputs. Такой расчет лучше отвечает на вопрос бизнеса, чем сортировка по одному input row.
Выбор первого дешевого lane по workload
Bulk extraction обычно выигрывает от кэша и строгой schema validity. Short summaries зависят от output length и factuality. Coding tasks требуют compile или test pass rate. Agent loops умножают tool calls и повторные запросы. Long-context analysis зависит от quote fidelity и latency. Quality-critical output может быть дешевле на более сильной модели, если она снижает human review.
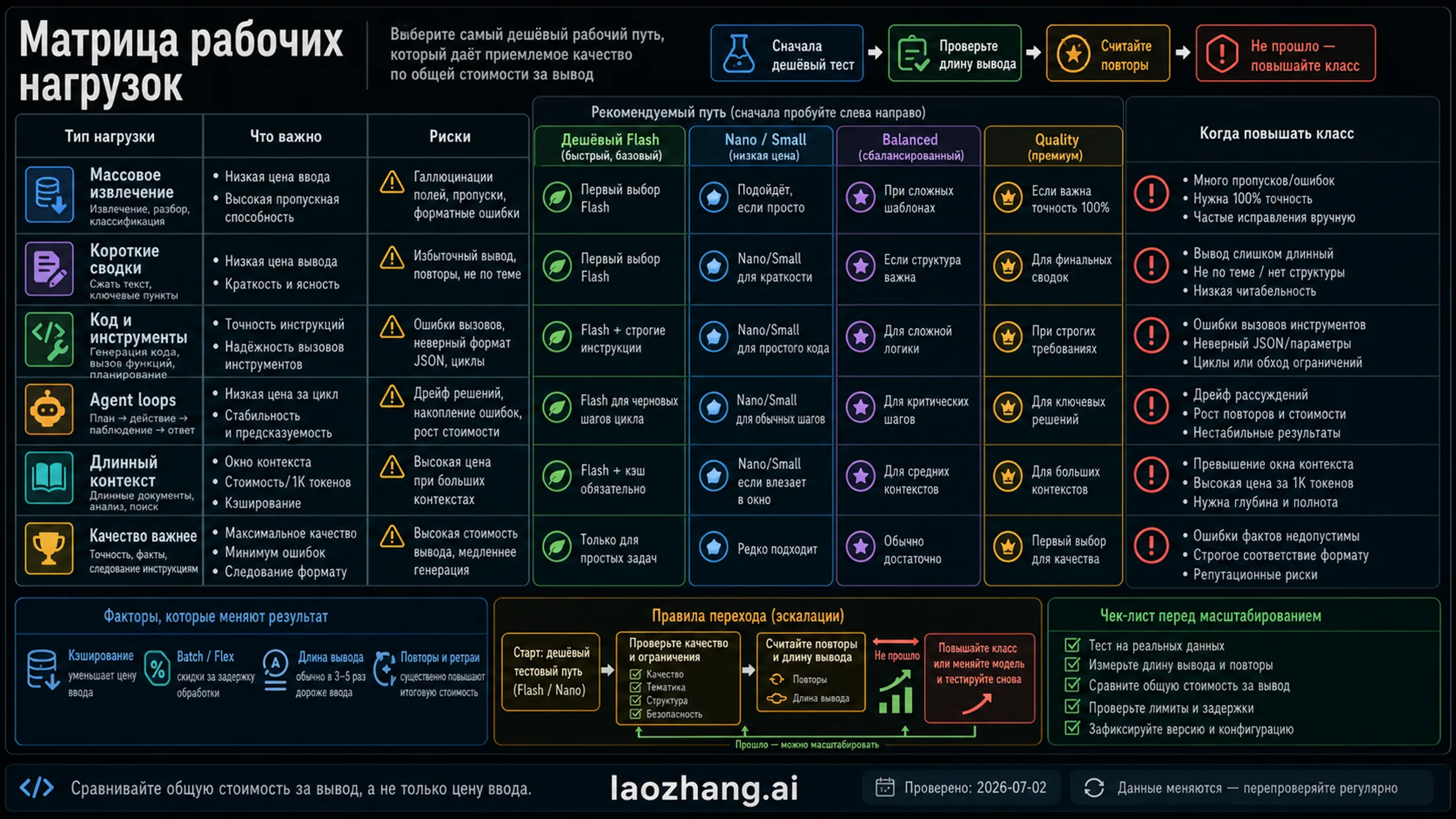
Не выбирайте десять моделей сразу. Выберите два дешевых lane, задайте acceptance bar и заранее запишите upgrade trigger. Если low-cost lane не проходит качество или растет retry rate, переходите на следующий уровень. Если два lane близки по цене, выберите тот, который проще поддерживать в вашем stack и контракте.
Free tier не равен production pricing
Free tier полезен для learning, prototype и prompt exploration. Но production traffic требует predictable capacity, billing owner, support path, data terms и план на quota failures. Google pricing показывает различие Free Tier и Paid Tier, а также data-use boundary. OpenAI, Anthropic, DeepSeek и другие поставщики тоже могут менять availability, rate limits и discounts.
Считайте free route proof-of-fit, а не budget. До запуска проверьте model ID, serving mode, quota, data policy, billing state, batch/flex availability и overage behavior. Если в prompts есть customer data, source code или logs, terms важнее, чем нулевая цена первых запросов.
Gateway и provider цены являются отдельным контрактом
Gateway может снизить migration cost: один OpenAI-compatible endpoint, model switching, logs и общий support owner. Но gateway price не является official vendor price. Если OpenRouter, SiliconFlow, laozhang.ai или другой provider показывает более дешевую строку, нужно отдельно проверить exact model ID, billing unit, cache behavior, failed-call billing, rate limits, refund rules и data policy.
Для laozhang.ai безопасная формулировка такая: это gateway route, который можно оценивать для OpenAI-compatible migration, model coverage, logs и routing. Точные цены нужно проверять в текущем console/API, а не переносить из старого screenshot или aggregator.
Checklist перед расходами

- Verify official model ID.
- Record input, cached input, output and Batch/Flex rows.
- Test the same representative prompts.
- Measure p50/p95 latency and concurrency.
- Count retries, refusals, malformed outputs and tool calls.
- Separate официальную цену владельца модели, цену провайдера и комиссию шлюза.
- Put spend cap and kill switch on agentic or bulk workflows.
- Recheck prices and availability before release.
Рекомендованные стартовые решения
Если нужен lowest official paid token floor, начните с DeepSeek V4 Flash, но не пропускайте quality and region checks. Если stack уже OpenAI-native, проверьте gpt-5-nano и Batch/Flex latency. Если нужна Google-owned low-cost lane, начните с gemini-2.5-flash-lite, а gemini-3.1-flash-lite держите как newer lane. Если дешевые модели не проходят, сравните Claude Haiku 4.5 как quality cost baseline.
Финальный вывод должен звучать не как brand ranking, а как workload result: на этой выборке prompts, output length, cache hit rate и quality bar, эта модель дает lowest accepted-output cost.
Шаблон бюджетного теста
Перед закупкой или запуском не переносите price table напрямую в бюджет. Сделайте небольшой ledger для собственного workload: одинаковые prompts, одинаковый system prompt, одинаковые RAG fragments, одинаковые output limits и одинаковый acceptance bar. Для каждого кандидата записывайте input tokens, reusable cached prefix, output tokens, failed schema attempts, refusals, manual repair time, p50/p95 latency, region, quota, support owner and final accepted status. Только после этого можно сравнивать lowest accepted-output cost.
| Budget field | How to record it | Why it changes the winner |
|---|---|---|
| Input tokens | Separate system prompt, user text, retrieval chunks and tool schemas | Long-context tasks reward a low input row only when context is truly needed |
| Cached input | Measure reusable prefix share and cache hit rate | A cheap cache-hit row is valuable only with high reuse |
| Output tokens | Set expected and maximum output length for each task | Output rows are often much higher than input rows |
| Quality retries | Count schema failures, factual errors, refusals and human repair | Cheap calls become expensive when acceptance rate falls |
| Batch/Flex | Mark async jobs separately from real-time jobs | Discounted latency is useful only when the workflow can wait |
| Contract boundary | Split official vendor price, provider contract and gateway fee | Support, logs, refunds and data terms are part of production cost |
Use at least three test sets. The first set should contain stable short-output jobs: extraction, classification, tagging, deduplication and field cleanup. This is where DeepSeek V4 Flash, OpenAI nano or Google Flash-Lite style lanes can show their advantage. The second set should contain longer but bounded outputs: summaries, comparisons, email drafts, product copy or report sections. Here output length and factual errors can erase the low input price. The third set should contain high-risk tasks: code changes, legal review, financial reasoning or multi-step agents. For those jobs, token price is only the entry point; test pass rate, auditability and manual review dominate.
If one cheap lane wins extraction but fails long summaries, do not call it the default cheapest LLM API model. Route by job. Put short deterministic tasks on the low-cost lane, cap answer length for medium tasks, and keep a stronger model as a quality baseline for code, compliance or agent loops. That routing model is easier to defend than a brand ranking because it explains when the cheapest row stops being the cheapest production choice.
Before launch, run a reverse review. The business owner confirms whether accepted outputs can be used without rewrite. The engineering owner checks latency, rate limit and failure handling. The security owner checks data policy, log retention, region and support path. If any owner rejects the lane, the low token row is not yet a production cost saving.
Pre-spend verification workflow
Price-sensitive pages need a dated verification routine. On release day, reopen the official pricing pages and confirm model ID, input price, cached-input price, output price and Batch/Flex rows. Then confirm that free-tier terms are not mixed with paid-tier assumptions, especially data use, quota, support and availability. If a gateway or OpenAI-compatible provider is involved, write its price as a separate provider contract with its own model ID, failed-call billing, rate limit, refund and log policy.
Next, run a small invoice test with the same prompts. Do not stop at average cost. Look at p95 cost, failed-task cost and accepted-output cost because batch jobs and agent loops often lose money in the tail. Finally, write upgrade triggers: schema failure above threshold, manual repair above threshold, p95 latency above threshold, regional availability failure or data terms mismatch. These triggers make the conclusion operational instead of just saying that one model is cheapest.
Часто задаваемые вопросы
Какая LLM API модель сейчас самая дешевая?
DeepSeek V4 Flash и OpenAI gpt-5-nano являются первыми cheap checks; gemini-2.5-flash-lite является низкой Google-owned lane. Но final winner зависит от workload и accepted-output cost.
DeepSeek всегда дешевле?
Нет. Его cache-hit и cache-miss rows очень низкие, но latency, availability, quality или region constraints могут поднять real cost через retries и review work.
Можно ли использовать free LLM API в production?
Обычно free tier стоит использовать для prototypes. Production требует quota, paid terms, support, data policy и predictable billing.
Что выбрать для coding?
Тестируйте DeepSeek, OpenAI nano, Google Flash-Lite и ваш existing provider на одном наборе реальных задач. Сортируйте по test pass rate and accepted-output cost.
Claude слишком дорогой?
Raw token row выше, но Claude Haiku 4.5 может быть дешевле для quality-sensitive work, если снижает retries и human review.
Стоит ли доверять pricing aggregators?
Используйте их для discovery, но перед spend возвращайтесь к official owner pages или provider console.