
The cheapest LLM API provider is not a fixed company. It is the route that stays cheapest after your workload passes quality review. As of July 1, 2026, DeepSeek V4 Flash is the lowest verified official paid token floor in this comparison. That statement is useful only as a starting point. A production decision also depends on output length, cache hit rate, rejection rate, retry behavior, latency, quota, gateway fee, support owner, data terms, and the cost of moving code.
Start with route ownership. A direct official API gives you the model vendor's price row, billing unit, lifecycle notice, and support contract. A gateway or aggregator can be cheaper in practice when it provides one OpenAI-compatible surface, many models, logs, failover, and one operational support path. A free route is useful for experiments and same-prompt samples. BYOK or self-hosting can win only when operations, utilization, and latency are under control.
| Route | First test | Why it can be cheap | Stop rule |
|---|---|---|---|
| Official direct API | DeepSeek V4 Flash for the paid token floor; Gemini 2.5 Flash-Lite Batch/Flex for low-cost batch work | Vendor-owned prices, clearer billing units, direct lifecycle notices | Stop if quality, region, quota, or lifecycle does not match the workload. |
| Gateway or aggregator | OpenRouter, SiliconFlow, or laozhang.ai after live model/API verification | One compatible API, model switching, logs, and support consolidation can reduce engineering cost | Stop if fee, failed-call billing, support owner, quota, or data policy is unclear. |
| Free experiment route | Free models, trial credits, sandbox quotas | Useful for prototypes and prompt comparisons | Stop before production unless limits, terms, uptime, and support are verified. |
| BYOK or self-hosted | Your key, your cloud, or your inference stack | More control over data path and long-term unit economics | Stop if operations, maintenance, GPU utilization, or latency erase savings. |
The quick formula is simple: effective cost equals total bill divided by accepted outputs. Do not move production traffic until you have run the same prompts, verified current billable units, recorded failures and retries, and placed the rollout behind a spend cap.
Current Low-Cost Official Price Lanes
Official prices are the safest anchor because the model vendor owns the row. They are still incomplete. A model with a very low input price can lose when it writes longer answers, fails schema checks, times out, or needs a stronger fallback for the tasks it cannot complete.
The dated rows checked on July 1, 2026 are: DeepSeek V4 Flash: $0.14 cache-miss input and $0.28 output per 1M tokens, cache-hit input much lower; Gemini 2.5 Flash-Lite: $0.10 input and $0.40 output, Batch/Flex $0.05/$0.20; OpenAI gpt-5.4-nano: $0.20 input and $1.25 output; Mistral Small 4: $0.15/$0.60; Claude Haiku 4.5: $1/$5. These rows are not procurement advice by themselves. They are candidate lanes for a controlled sample run.
| Official route | Current low-cost row | Why it matters | Boundary |
|---|---|---|---|
| DeepSeek direct | DeepSeek V4 Flash: $0.14 cache-miss input and $0.28 output per 1M tokens; cache-hit input is far lower | The lowest verified official paid token floor in this comparison | Do not treat it as the best coding, reasoning, region, or reliability choice for every product. DeepSeek also notes compatibility-name deprecation for deepseek-chat and deepseek-reasoner on 2026-07-24 15:59 UTC. |
| Google Gemini API | Gemini 2.5 Flash-Lite: $0.10 input and $0.40 output per 1M tokens; Batch/Flex: $0.05 input and $0.20 output | Strong official low-cost lane when latency can be batch-like | Do not reuse older Gemini 2.0 Flash-Lite rows as current pricing. |
| OpenAI API | gpt-5.4-nano: $0.20 input and $1.25 output per 1M tokens; Batch/Flex rows are lower | Useful low-cost OpenAI-owned baseline when tooling, policy, and compatibility matter | Not the lowest paid floor, but it can reduce migration and reliability risk. |
| Mistral API | Mistral Small 4: $0.15 input and $0.60 output per 1M tokens | Competitive official route for open-model and European governance needs | Compare governance, quality, latency, and route availability together. |
| Anthropic API | Claude Haiku 4.5: $1 input and $5 output per MTok; Sonnet 5 introductory pricing ends on 2026-08-31 | Raw token price is not the cheapest, but output behavior can reduce review work | Keep the Sonnet 5 date boundary visible and schedule a recheck. |
The practical interpretation is: use DeepSeek V4 Flash as the first cheap paid test for many text workloads, then prove that the workload accepts the output. If a cheap model doubles rejected answers, the price table has hidden the real cost.
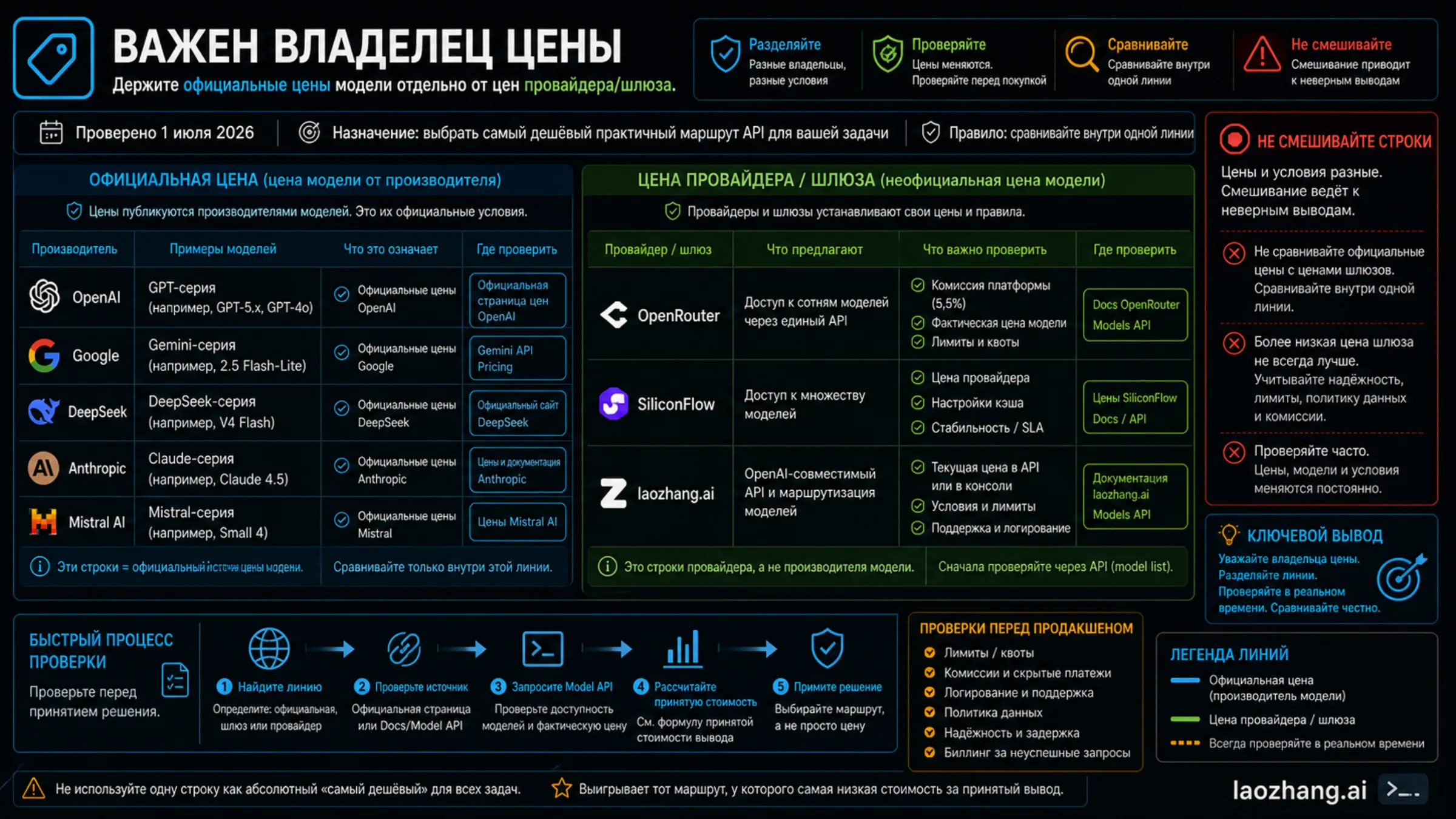
Gateway And Provider Routes
Gateways and aggregators are provider routes. They can reduce total cost when API compatibility, model breadth, logs, routing, and support consolidation save more engineering time than the platform fee. They can also create a second contract boundary, different regional behavior, unclear failed-call billing, or provider-specific price rows that are not official vendor prices.
| Provider route | What to verify | Why it may be useful | Do not claim |
|---|---|---|---|
| OpenRouter | Model row, provider route, tokenizer differences, free-model limits, and the 5.5% Pay-as-you-go platform fee | Broad catalog, no-minimum testing, and a Models API that can sort by pricing-low-to-high | Do not call OpenRouter metadata an official OpenAI, Google, Anthropic, DeepSeek, or Mistral price. |
| SiliconFlow | Provider-owned model price, version, region, terms, and current availability | Visible DeepSeek-family provider route that may help with payment, region, or operations | Do not treat a SiliconFlow DeepSeek row as DeepSeek direct pricing. |
| laozhang.ai | Current model list, feature flags, exact row, billing mode, logs, support path, console/API data | Useful when the job is OpenAI-compatible migration, model switching, usage visibility, or one support owner | Do not publish exact per-model prices unless the current Models API or console row proves them. |
For laozhang.ai, the safe recommendation is conditional. It belongs in the comparison when the reader needs gateway access, OpenAI-compatible migration, multi-model coverage checks, usage logs, or support-owner consolidation. It should not replace official vendor pricing when the reader needs vendor-owned price rows, lifecycle terms, or direct vendor support. The public documentation describes pay-as-you-go API integration and an OpenAI-compatible Models API for model list, features, and pricing; that is a verification path, not permission to freeze stale prices.
Calculate Accepted-Output Cost
The cheapest practical provider is the provider with the lowest cost per accepted output at your quality bar. A static input-token price ignores the variables that usually move the bill.
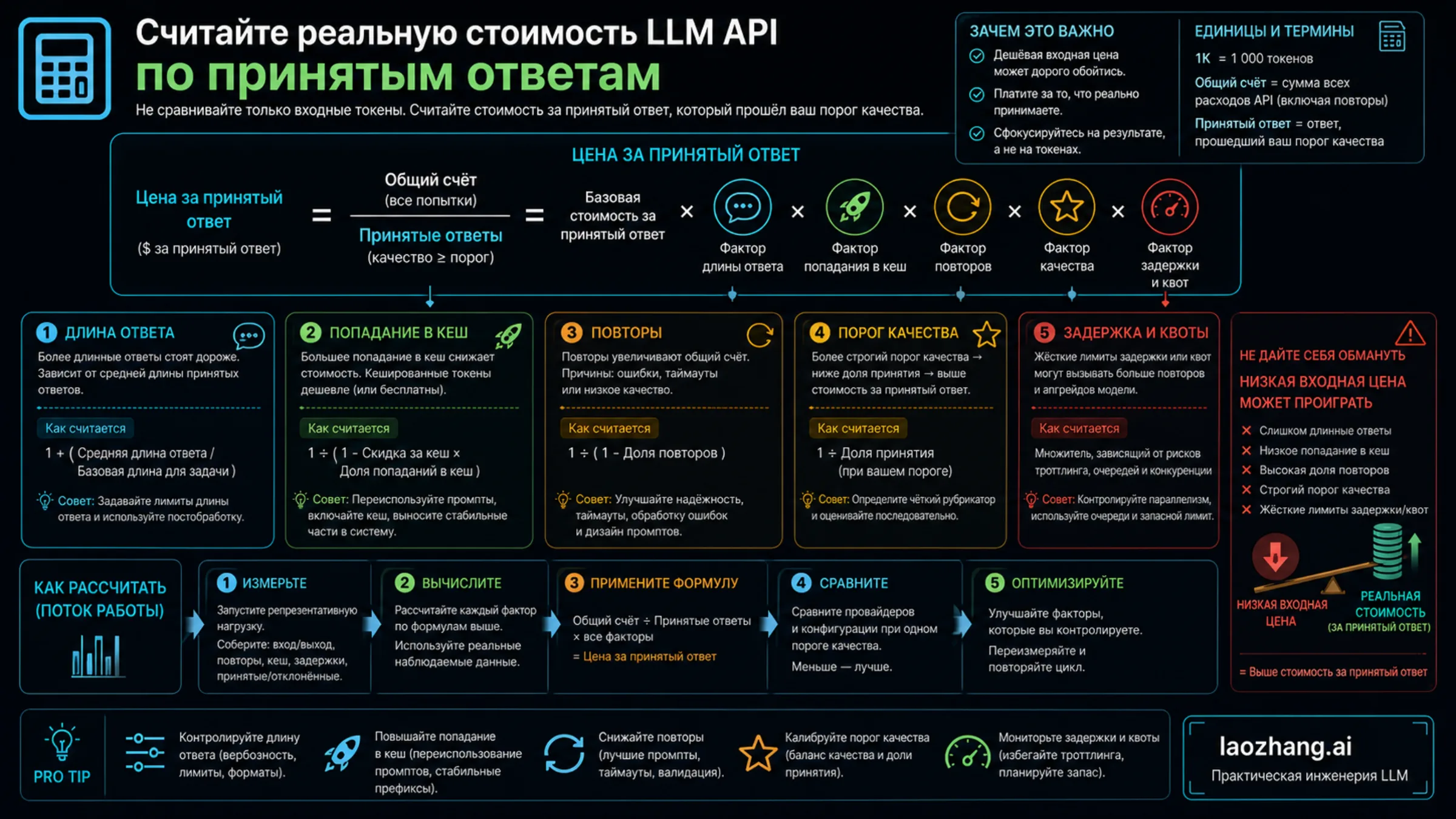
Accepted-output cost equals total bill for the sample run divided by outputs that passed your acceptance bar.
| Variable | Why it changes the winner | What to measure |
|---|---|---|
| Input tokens | System prompts, tool schemas, retrieval chunks, and history can dominate short tasks | Average billable input per accepted task |
| Output tokens | Some models need longer answers to pass review | Average accepted output length |
| Cache hit rate | Prompt-heavy workflows can become cheaper when cached input applies | Cacheable prefix share and hit percentage |
| Retry rate | Timeouts, schema failures, weak reasoning, and refusals create billable attempts | Attempts per accepted answer |
| Quality threshold | A higher bar rejects weak cheap outputs more often | Acceptance rate from a labeled sample |
| Latency and quota | Rate limits can force a higher-cost fallback or delay batch work | P95 latency, TPM/RPM headroom, fallback share |
| Gateway fee | Platform fee, markup, failed-call billing, or minimum spend changes the invoice | Full provider invoice divided by accepted outputs |
Example: Provider A costs $0.20 for 1,000 candidate outputs, but only 600 are accepted. Its cost is $0.000333 per accepted output. Provider B costs $0.25, but 900 outputs pass. Its cost is $0.000278. B is more expensive in the raw table and cheaper in the product. This is why the same spreadsheet must include bill, acceptance rate, latency, failed attempts, and support boundary.
Free, Trial, BYOK, And Self-Hosted Lanes
Free access is valuable, but it is not a production price. It usually means a trial, a quota-limited gateway model, an educational sandbox, or a temporary provider promotion. Each route should feed the same-prompt test rather than replace due diligence.
| Lane | Good for | Hidden cost | Production boundary |
|---|---|---|---|
| Free model through a gateway | Prototypes, demos, prompt comparisons | Strict limits, lower priority, route changes, fallback behavior | Do not depend on it until terms, rate limits, and uptime expectations are verified. |
| Trial credits from a vendor | Comparing a new official API | Expiration, account limits, regional availability | Move to paid rows before launch math. |
| BYOK through a gateway | Keeping your vendor account while using one router | Gateway fee, key management, support split, data path | Know whether the vendor or gateway owns the failure. |
| Self-hosted open model | Data control and high-utilization workloads | GPU utilization, monitoring, quantization quality, maintenance | Only cheaper when utilization is high and quality is good enough. |
The key local rule is to avoid mixing "free for a demo" with "cheap for production." Free routes are useful because they create evidence. They are unsafe when they become the evidence.
Verification Workflow Before Switching
Do not migrate production traffic from a price table. Use the table to choose candidates, then verify the live route.
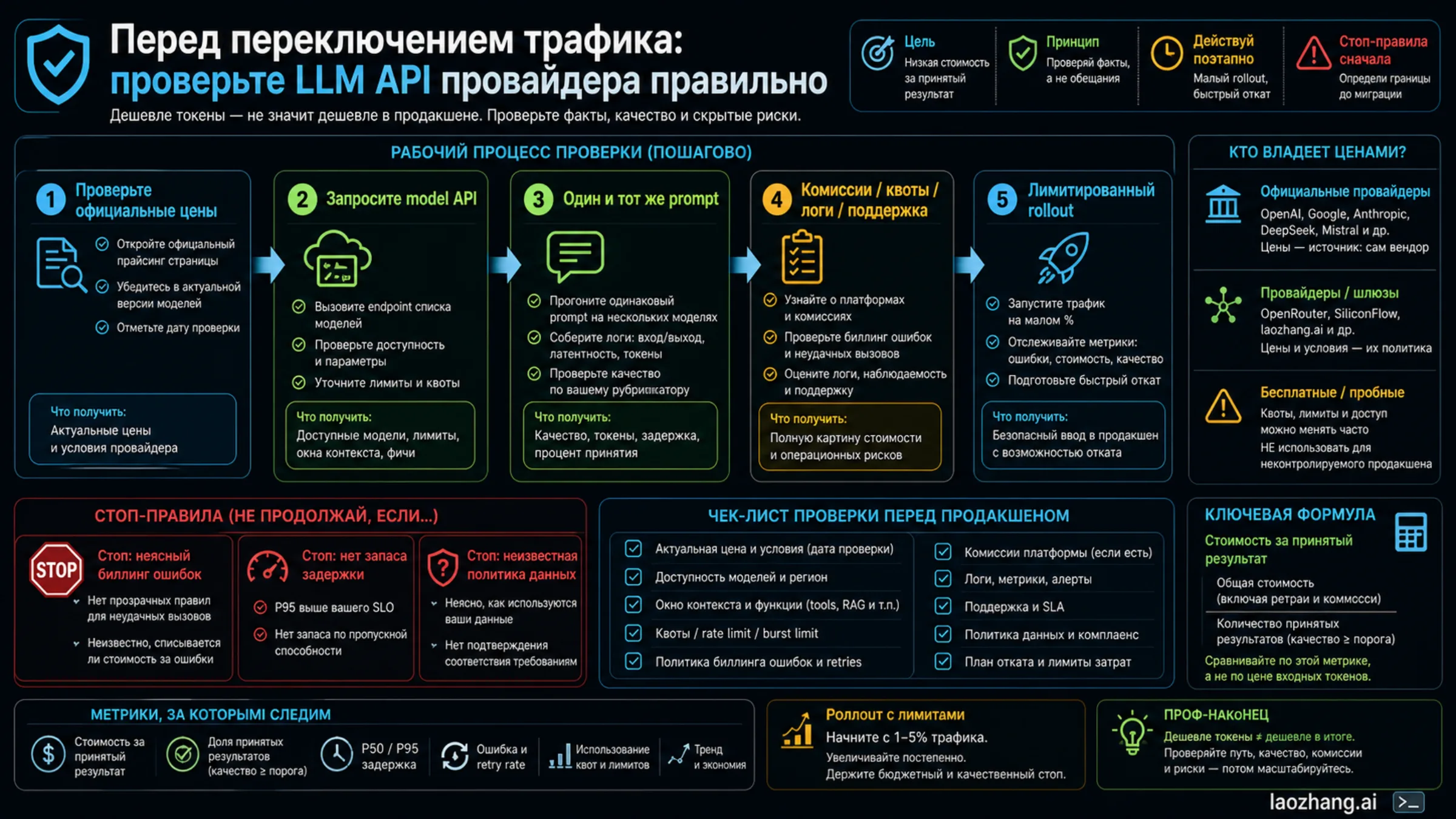
- Check the official model-vendor pricing page for the direct API row.
- If a gateway is involved, query its current model/API metadata or console before quoting a provider price.
- Run the same prompt set against each candidate route.
- Record input tokens, output tokens, cache behavior, failures, retries, latency, and accepted outputs.
- Compare total bill divided by accepted outputs.
- Inspect failed-call billing, quota, logs, support owner, data retention, and regional terms.
- Move only a small traffic slice behind a spend cap, quality fallback, and rollback path.
Stop the migration if failed-call billing is unclear, latency has no concurrency headroom, a model name is near a lifecycle change, usage logs cannot support budget control, data retention conflicts with the workload, or the provider cannot explain who owns upstream failures. A cheap route that cannot be monitored is not cheap enough for production.
Recommendations By Workload
Use these rows as first tests, not final procurement answers.
| Workload | First route to test | Backup route | Why |
|---|---|---|---|
| Cheap chat, extraction, light summarization | DeepSeek V4 Flash direct | Gemini 2.5 Flash-Lite or OpenAI gpt-5.4-nano | Start at the official paid floor, then test acceptance rate and output length. |
| Large asynchronous summarization | Gemini 2.5 Flash-Lite Batch/Flex | OpenAI Batch/Flex low-cost rows | Batch-style lanes can beat interactive routes when latency is not urgent. |
| OpenAI-compatible migration with many candidate models | OpenRouter or laozhang.ai after live model/API verification | Official direct API for the winning model | Gateway convenience can save engineering time after fee and source-owner checks. |
| DeepSeek-family access through a provider route | DeepSeek direct first, then SiliconFlow if region, payment, or operations help | Another gateway with verified model metadata | Provider-owned DeepSeek rows need provider labels and current verification. |
| Coding or agentic tasks | Same-prompt test across DeepSeek, OpenAI, Claude, and a gateway fallback | The model with the lowest accepted-output cost | Retry rate and tool reliability can dominate raw token price. |
| Governance-sensitive workloads | Mistral or a vendor/direct route with required region and data terms | BYOK or self-hosting if operations are realistic | Compliance and data owner can be worth paying for. |
One product can use several providers. A classifier can run on a cheap official row, a coding assistant can use a stronger model, and a gateway can own only fallback routing. Forcing one provider to own every task is usually more expensive than routing by job.
Provider Checklist
Before calling a route cheapest, answer each question in writing. Which organization owns the price row: model vendor, gateway, cloud platform, reseller, or your infrastructure team? Is the row input-only, output-only, cached input, batch/flex, per request, per second, or tool-call based? What model version, region, and lifecycle status does it cover? How are failed calls, timeouts, safety refusals, and retries billed? What are the RPM, TPM, daily quota, and spend-limit behaviors? Are logs, usage export, and alerting enough for budget control? Who owns support when the upstream model fails? What data retention, training, and regional terms apply? Does the route pass your same-prompt set at the chosen quality bar? Is the rollout capped so a failure cannot create an open-ended bill?
This checklist is stricter than a price comparison because it turns price into deployable cost. It also creates the audit trail that a team needs when a provider changes a model name, platform fee, or free-route rule.
FAQ
Who is the cheapest LLM API provider right now?
For the official paid token floor checked on July 1, 2026, DeepSeek V4 Flash is the lowest verified row in this comparison. It is not automatically the cheapest practical provider for every workload. Compare accepted-output cost after output length, cache rate, retries, latency, quota, and support owner.
Is OpenRouter cheaper than direct API access?
Sometimes. OpenRouter can reduce integration work and expose many models through one gateway, but Pay-as-you-go includes a platform fee and pricing depends on the selected route. Treat its prices as gateway-owned metadata and verify the live row before production.
Should laozhang.ai be used as the cheapest provider?
Use laozhang.ai when the job is gateway access: OpenAI-compatible API migration, model switching, usage visibility, and one support owner. Do not call it the cheapest provider unless the current Models API or console row proves the exact model price for your workload.
Are free LLM APIs safe for production?
Assume no until limits, terms, uptime, quota, logs, and support path are verified. Free routes are excellent for prompt comparison and early prototypes. Production needs predictable billing and rollback.
Why can a low input price lose?
Because the bill is not only input tokens. Long outputs, low cache hit rate, schema failures, retries, stricter review, latency fallbacks, and gateway fees can make a low input row more expensive per accepted output.
How often should prices be rechecked?
Recheck before every production migration, before major volume increases, and whenever a model lifecycle note, platform fee, or free-route term changes. Date-bound rows need a scheduled recheck before the cutoff.
Bottom Line
Use the official token floor to pick a first candidate, not a final provider. DeepSeek V4 Flash deserves the first cheap paid test for many text workloads. Gemini 2.5 Flash-Lite Batch/Flex deserves a serious test for asynchronous scale. OpenAI, Anthropic, and Mistral can win when compatibility, quality, governance, or reliability reduces rejected output. Gateways such as OpenRouter, SiliconFlow, and laozhang.ai can win when routing, logs, API compatibility, or support consolidation saves more than the provider fee. The final decision is operational: verify the current row, run the same prompts, divide the full bill by accepted outputs, and roll out behind a cap.