
2026년 5월 7일 기준으로, 장시간 coding agent, 여러 파일을 건드리는 수정, 큰 context를 유지해야 하는 autonomous execution은 GLM-5.1을 먼저 테스트하는 편이 맞습니다. 저비용 pilot, 많은 candidate patch, UI variant, low-risk implementation을 넓게 돌리고 싶다면 Kimi K2.6을 먼저 봅니다. Qwen3.6을 먼저 테스트하려면 분기를 먼저 정해야 합니다. Qwen3.6-35B-A3B는 open-weight control이고, Qwen3.6 Plus, Flash, Max Preview는 Alibaba hosted route의 실험입니다.
이 비교를 단순 순위표로 만들면 중요한 경계가 사라집니다. kimi-k2.6과glm-5.1은 Moonshot/Kimi와 Z.AI 문서에서 확인할 수 있는 model ID입니다. 반면 Qwen3.6은 이 의사결정에서 branch label입니다. Qwen3.6-35B-A3B local run, Qwen3.6 Plus hosted result, Qwen3.6 Max Preview launch-week test를 같은 행으로 합치면 보기에는 깔끔하지만 deploy decision에는 취약합니다.
| 먼저 테스트할 경로 | 적합한 상황 | default 전환 전 확인 |
|---|---|---|
| GLM-5.1 | 장시간 autonomous coding, multi-file migration, sustained context, 여러 tool call을 견뎌야 하는 작업. | glm-5.1, context/output limit, tool behavior, current pricing, Z.AI migration surface. |
| Kimi K2.6 | 저렴한 대량 pilot, UI variant, scaffolding, low-risk cleanup, 여러 candidate patch. | kimi-k2.6, pricing row, hosted route, open availability를 쓴다면 license와 self-host terms. |
| Qwen3.6 | Qwen family behavior, local control, open-weight deploy, Alibaba hosted branch test. | 35B-A3B, Plus, Flash, Max Preview 중 무엇인지 먼저 적기. |
중지 규칙은 테스트 전에 정해야 합니다. 한 번의 demo, 하나의 benchmark, 낮은 token price만 보고 현재 default를 바꾸지 않습니다. 같은 repo snapshot, prompt, tools, tests, reviewer로 accepted diff, hidden defect, retry cost, review time, rollback risk에서 current default에 지지 않아야 합니다.
빠른 답
GLM-5.1은 긴 agent loop를 평가할 때 첫 후보입니다. agent가 계획을 오래 유지하고, 중간 오류에서 회복하고, dependency를 추적하고, 여러 파일과 도구 호출을 지나도 coherence를 유지해야 한다면 Z.AI route를 current default와 일찍 비교해야 합니다.
Kimi K2.6은 저렴한 시도 횟수가 중요할 때 첫 후보입니다. frontend alternative, routine implementation, scaffolding, solution sketch, low-risk code cleanup처럼 실패 한 번이 치명적이지 않고 여러 안을 돌려보고 싶은 작업에 맞습니다. 다만 listed price가 낮아도 accepted-task cost가 낮지 않으면 실질적 이점은 없습니다.
Qwen3.6은 분기를 정한 뒤에야 비교할 수 있습니다. Qwen3.6-35B-A3B는 local deployment, open-weight access, reproducible deployment, custom orchestration을 측정하는 경로입니다. hosted Qwen3.6 branches는 Alibaba managed surface, quota, latency, billing, integration을 측정하는 경로입니다.
Qwen3.6은 먼저 분기를 정한다
Qwen3.6은 분기 이름이 나오기 전까지 family label입니다. Qwen과 Hugging Face 자료는 Qwen3.6-35B-A3B를 coding agent용 MoE model로 설명하며 35B total parameters와 3B active parameters를 제시합니다. model card는 Apache-2.0 license를 기록하고 262,144-token context setting의 serving example을 제공합니다. local control, reproducible deployment, custom orchestration이 중요한 팀에는 이 분기가 판단 대상입니다.
하지만 공개 Qwen3.6 비교가 모두 35B-A3B를 말하는 것은 아닙니다. Qwen3.6 Plus, Flash, Max Preview를 다루는 경우도 많습니다. hosted branch는 Alibaba route 사용자에게 맞는 선택일 수 있지만 open-weight branch와 섞으면 안 됩니다. Kimi K2.6, GLM-5.1과 비교하기 전에 먼저 "어떤 Qwen3.6 route를 측정할 것인가"를 적어야 합니다.
공식 계약 경로
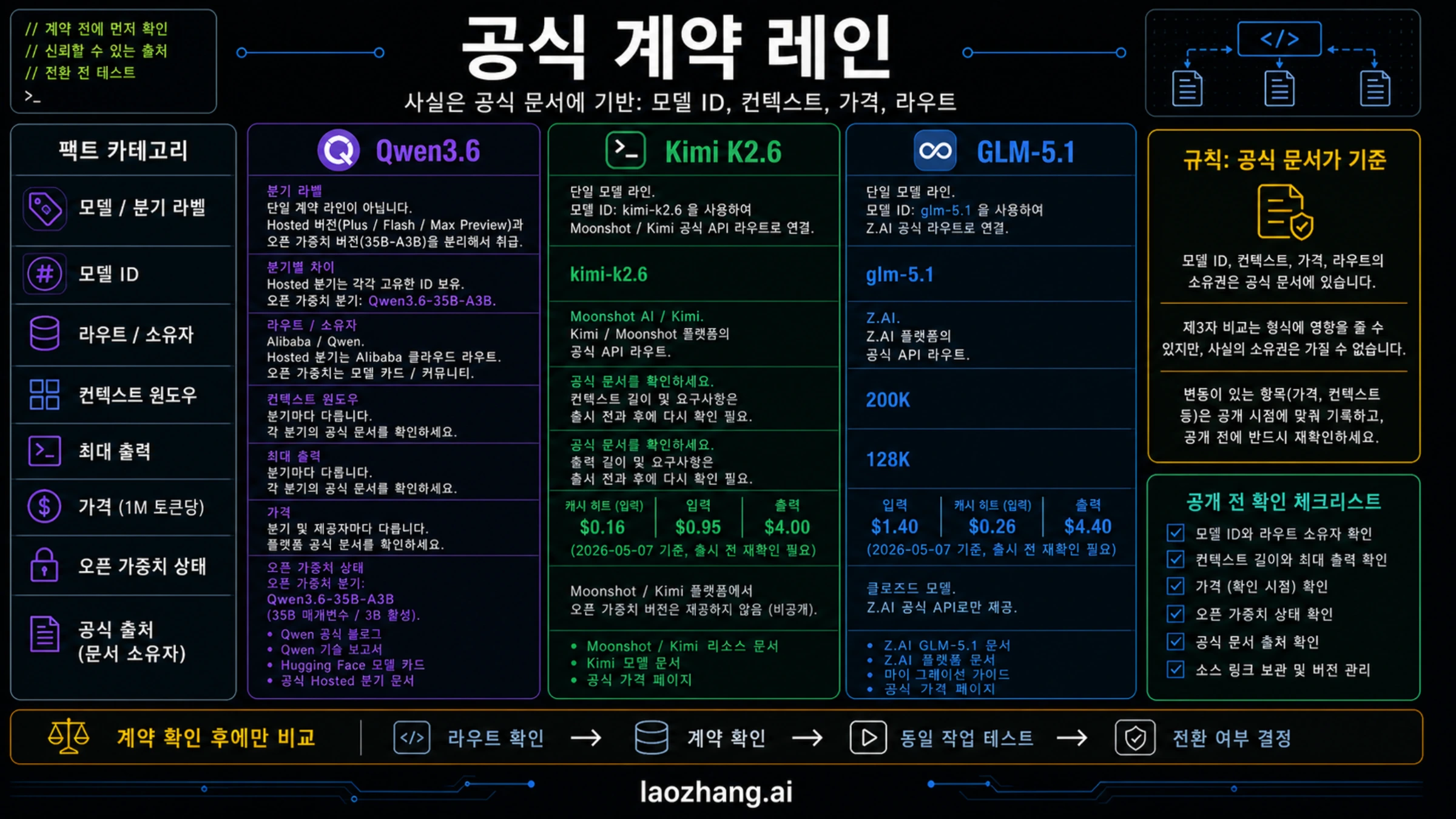
공식 문서를 기준으로 삼으면 비교 경계가 유지됩니다. 2026년 5월 7일 확인한 계약 행은 다음과 같습니다.
| 계약 항목 | Qwen3.6 | Kimi K2.6 | GLM-5.1 |
|---|---|---|---|
| 먼저 확인할 소유자 | Qwen official blog, Qwen model card, Alibaba hosted branch docs. | Moonshot/Kimi platform과 Kimi model documentation. | Z.AI GLM-5.1 docs, migration docs, pricing docs. |
| deploy label | open-weight branch는 Qwen3.6-35B-A3B. hosted branches는 별도로 명명. | kimi-k2.6 | glm-5.1 |
| 첫 테스트 이유 | local/open-weight control 또는 Alibaba branch experiment. | Moonshot/Kimi route에서 저렴한 broad pilot. | Z.AI route에서 long-horizon agent work. |
| context/output | branch-dependent. 35B-A3B card는 262,144-token serving example 포함. | Moonshot/Kimi 현재 문서에서 확인. | Z.AI docs는 200K context와 128K max output 명시. |
| pricing owner | hosted branch는 branch/provider 의존. open-weight는 infrastructure cost. | checked row: cache hit $0.16/MTok, input $0.95/MTok, output $4.00/MTok. | checked row: input $1.4, cached input $0.26, output $4.4 per 1M tokens. |
| open-weight boundary | Qwen3.6-35B-A3B가 open-weight lane. | open availability는 route, license, self-host terms 재확인 필요. | 여기서는 Z.AI hosted route가 contract row. |
Qwen3.6-35B-A3B 사실은 Qwen post와 Hugging Face card로 확인합니다. Kimi는 Kimi platform과 Kimi model documentation으로 확인합니다. GLM은 Z.AI GLM-5.1 docs, migration docs, pricing docs로 확인합니다. 가격, context, availability는 production default 전에 다시 확인해야 합니다.
Coding agent workload로 나눈다
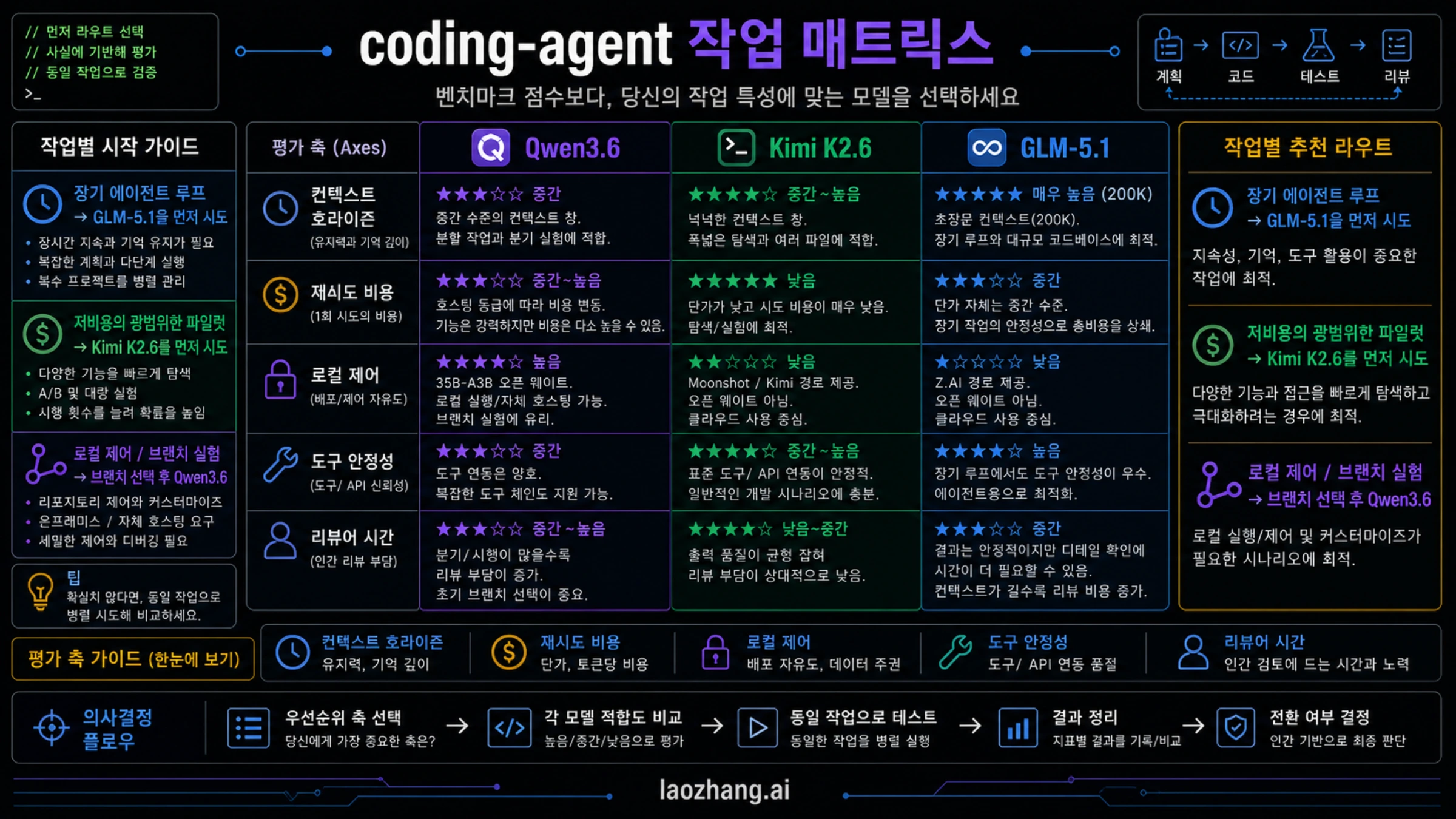
하나의 benchmark score보다 workload split이 더 실용적입니다. GLM-5.1은 long-horizon autonomous coding에 맞습니다. 긴 계획을 유지하고, 중간 error에서 회복하고, dependency를 추적하고, 여러 tool calls를 지나도 coherence를 유지해야 할 때 먼저 봅니다.
Kimi K2.6은 broad pilot volume에 맞습니다. UI alternatives, scaffolding, routine implementation, low-risk cleanup, 여러 candidate patch처럼 저렴한 시도 횟수가 가치가 되는 작업에서 먼저 테스트합니다. 하지만 reviewer가 많이 고쳐야 한다면 token이 싸도 accepted-task cost는 싸지 않습니다.
Qwen3.6은 branch-specific control에 맞습니다. Qwen3.6-35B-A3B는 local deployment, open-weight access, reproducibility, custom orchestration을 측정할 때 씁니다. hosted Qwen3.6 branch는 managed surface, latency, quota, billing owner, Alibaba integration을 측정할 때 씁니다.
동일 작업 pilot

모델 비교는 동일 작업 pilot으로 내려와야 쓸 수 있습니다. 다섯 개에서 열 개의 실제 작업을 고릅니다. small bug fix, multi-file refactor, test-writing, frontend/UI task, long-context analysis, ambiguous requirement를 포함하면 실패 유형이 보입니다.
각 route에는 같은 repo snapshot, prompt, tool permission, timeout, test command, review rubric을 사용합니다. accepted diff, test pass, missed references, hidden defects, reviewer edits, retry count, tool-call drift, latency, billing owner, rollback risk를 기록합니다. candidate route가 싸더라도 쉬운 task만 주거나 review를 느슨하게 하면 안 됩니다.
threshold는 pilot 전에 정합니다. one blocker defect는 promotion stop입니다. three major defects는 pilot mode 유지입니다. reviewer time이 current default의 2배를 넘으면 cost가 tokens에서 people로 옮겨진 것입니다. accepted patch마다 세 번 이상의 retry가 필요하면 exploration에는 쓸 수 있어도 default에는 위험합니다.
먼저 고르지 말아야 할 때
짧고 저렴한 variant를 몇 개만 볼 때, Z.AI route가 아직 없는 팀은 GLM-5.1부터 시작할 필요가 없습니다. long-horizon 장점은 작은 실험에서 덜 드러납니다.
high-risk production migration이라면 Kimi K2.6이 싸다는 이유만으로 default로 올리면 안 됩니다. Kimi는 pilot pool에 넣을 수 있지만 hidden defect cost가 model bill보다 큰 작업에는 control route가 필요합니다.
Qwen3.6 분기를 아무도 말하지 못하면 Qwen3.6부터 시작하면 안 됩니다. Qwen3.6 Flash, Qwen3.6 Max Preview, local Qwen3.6-35B-A3B는 같은 증거가 아닙니다. branch first, comparison second입니다.
기존 비교 페이지와의 분담
이 판단은 Qwen3.6 family branch, Kimi K2.6, GLM-5.1 세 경로만 다룹니다. Kimi K2.6이 premium Claude default를 대체할 수 있는지가 실제 질문이라면 Kimi K2.6 vs Claude Opus 4.7을 사용합니다. DeepSeek V4, GPT-5.5, Claude Opus 4.7도 후보라면 더 넓은 Kimi K2.6 vs DeepSeek V4 vs GPT-5.5 vs Claude Opus 4.7을 사용합니다.
경계를 나누면 이 세 경로 결정이 일반 모델 순위표로 흐르지 않습니다. 독자는 어떤 route를 먼저 test harness에 넣을지 결정할 수 있습니다.
자주 묻는 질문
Qwen3.6은 하나의 모델인가요?
아닙니다. 실무 선택에서 Qwen3.6은 route를 명명하기 전까지 branch label입니다. Qwen3.6-35B-A3B는 open-weight branch입니다. Plus, Flash, Max Preview는 route, pricing, limit를 별도로 확인해야 합니다.
Kimi K2.6은 GLM-5.1보다 저렴한가요?
2026년 5월 7일 확인한 owner rows에서는 Kimi K2.6의 listed input/output token price가 GLM-5.1보다 낮았습니다. 이것은 pilot advantage이지 default-switch verdict가 아닙니다. accepted-task cost는 retries, reviewer time, hidden defects, wrapper billing에 따라 달라집니다.
GLM-5.1은 coding agents에 더 좋은가요?
job이 long-horizon, context-heavy이고 Z.AI route와 맞는다면 GLM-5.1을 먼저 테스트합니다. cheap exploration, local control, 작은 routine task의 자동 첫 후보는 아닙니다.
언제 Qwen3.6을 먼저 봐야 하나요?
local control, open-weight deployment, Alibaba route compatibility, Qwen-family behavior가 판단의 중심일 때입니다. 결과를 해석하기 전에 반드시 branch를 명시해야 합니다.
이 중 하나를 현재 default로 바꿀 수 있나요?
same-task pilot을 통과한 뒤에만 가능합니다. candidate route는 accepted diffs, tests, hidden-defect severity, reviewer time, retry cost, tool reliability, rollback risk에서 current default에 지지 않아야 합니다.