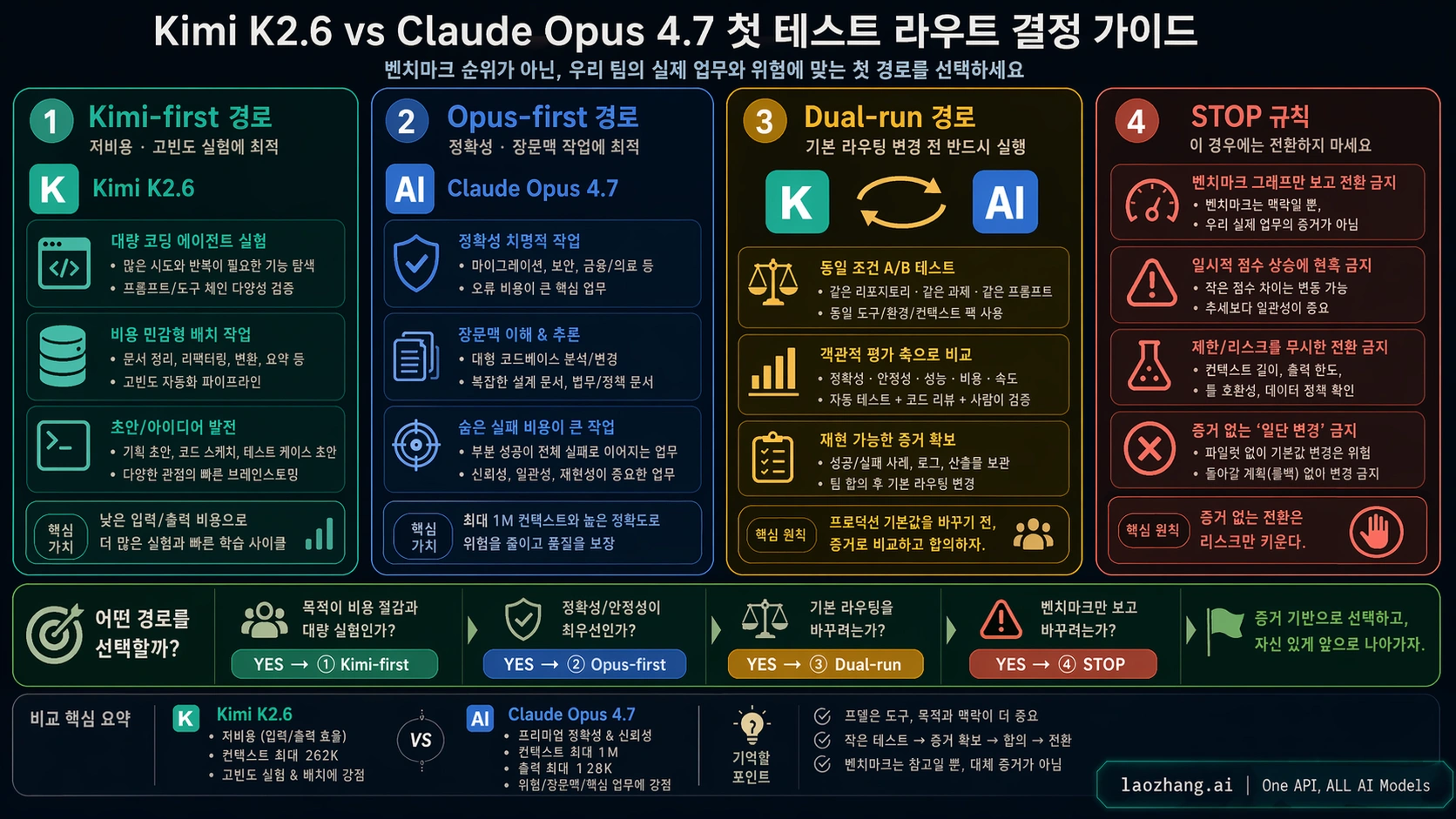
Kimi K2.6과 Claude Opus 4.7 비교의 핵심은 “누가 모든 벤치마크에서 이기나”가 아닙니다. 지금 필요한 것은 coding agent나 API workflow에서 어떤 모델을 먼저 테스트하고, 어떤 조건에서는 production default를 절대 바꾸면 안 되는지를 정하는 것입니다.
낮은 위험의 대량 실행, 테스트 보강, 반복 수정, open model route 평가가 목적이면 Kimi K2.6을 먼저 테스트하는 것이 합리적입니다. migration, 보안, 결제 주변 코드, 긴 context의 production analysis, 또는 숨은 버그가 token bill보다 더 비싼 작업이면 Claude Opus 4.7을 먼저 유지해야 합니다. 팀 default model을 바꾸려면 동일한 repository, 동일한 spec, 동일한 tool budget, 동일한 review rule로 dual-run 해야 합니다.
| 경로 | 먼저 쓰는 경우 | 이유 | 멈춤 규칙 |
|---|---|---|---|
| Kimi first | 저렴한 대량 agent 실험이 필요할 때 | 가격 차이가 pilot 자체를 정당화함 | 한 번 통과했다고 Opus replacement라 부르지 않음 |
| Opus first | 정확성, migration, long-context risk가 중요할 때 | 1M context와 mature API contract가 강함 | 가격만 보고 default를 바꾸지 않음 |
| Dual-run | routing policy나 default model을 바꿀 때 | replacement quality는 workflow claim | loss threshold 없이는 전환하지 않음 |
2026-04-23 기준 공식 계약만 놓고 보면 경계가 선명합니다. Kimi K2.6은 cache hit $0.16/MTok, input $0.95/MTok, output $4.00/MTok, 262,144 token context를 제시합니다. Claude Opus 4.7은 input $5/MTok, output $25/MTok, 1M context, 128k max output을 제시합니다. 이 사실은 Kimi의 cost route와 Opus의 premium control route를 보여주지만, 모든 coding task에서의 승패를 증명하지는 않습니다.
빠른 결론
한국어 검색 화면에서는 AI 요약, Reddit, 동영상, provider 비교가 같이 보이기 쉽습니다. 그래서 한국어 독자에게 필요한 첫 판단은 요약을 반복하는 것이 아니라 공식 계약과 운영 판단을 분리하는 것입니다. “Kimi가 싸다”는 사실과 “Kimi가 production Opus를 대체한다”는 주장은 같은 문장이 아닙니다.
Kimi를 먼저 테스트할 곳은 attempt volume이 실제 가치가 되는 업무입니다. 낮은 위험의 batch edit, test scaffolding, 반복적인 agent draft, open route 평가에서는 더 많은 시도를 할 수 있다는 점이 큰 장점입니다. Opus를 먼저 유지할 곳은 실패 비용이 큰 업무입니다. migration, 권한, 결제, 복잡한 refactor에서는 한 번의 숨은 버그가 token 가격 차이를 지워 버립니다.
default 변경은 별도 문제입니다. 팀이 이미 Opus를 높은 가치의 coding route로 쓰고 있다면, 질문은 “Kimi가 더 싸냐”가 아니라 “Kimi가 같은 workflow에서 real defect와 review cost를 허용 범위에 묶을 수 있냐”입니다. 그 답이 나올 때까지는 dual-run이 안전한 방식입니다.
공식 계약부터 비교하기

| 계약 항목 | Kimi K2.6 | Claude Opus 4.7 |
|---|---|---|
| 사실 소유자 | Moonshot / Kimi | Anthropic |
| API 표기 | Kimi 플랫폼의 K2.6 경로 | claude-opus-4-7 |
| 2026-04-23 기준 가격 | cache hit $0.16/MTok, input $0.95/MTok, output $4.00/MTok | input $5/MTok, output $25/MTok |
| context / output | 262,144 token context | 1M context, 128k max output |
| 의사결정 의미 | 더 많은 실험을 저렴하게 돌리기 좋음 | 위험한 작업에 premium control을 남기기 좋음 |
Kimi의 가격, cache-hit row, context window, availability는 Moonshot/Kimi가 소유한 first-party fact입니다. Claude Opus 4.7의 model ID, price, 1M context, 128k output, API behavior note는 Anthropic이 소유한 first-party fact입니다. provider page나 비교 사이트는 유용하지만, 공식 사실의 소유자가 되지는 않습니다.
단순히 1M input과 1M output을 보면 Kimi는 cache 없이도 약 $4.95, Opus는 $30입니다. 이 차이는 Kimi pilot을 강하게 정당화합니다. 하지만 실제 workflow cost에는 retry, tool calls, wall-clock time, reviewer intervention, hidden defect, rollback이 들어갑니다. 위험한 코드에서는 싼 token이 싼 작업을 보장하지 않습니다.
Opus 쪽에는 tokenization caveat도 있습니다. Anthropic은 같은 텍스트가 content type에 따라 약 1.0x에서 1.35x의 token으로 처리될 수 있다고 설명합니다. 고정 surcharge로 쓰면 안 되지만, 실제 prompt를 측정해야 하는 이유는 됩니다.
증거가 말할 수 있는 것
Kimi K2.6 공식 자료는 Kimi가 current이고 low-cost pilot으로 진지하게 볼 만하다는 점을 보여줍니다. 그러나 Kimi 공식 benchmark table은 Claude Opus 4.7을 직접 비교 열로 포함하지 않습니다. 따라서 그 표만으로 Kimi가 Opus 4.7을 production에서 대체한다고 말할 수 없습니다.
third-party comparison은 방법을 알려주는 자료입니다. 어떤 failure mode를 재현해야 하는지, passing test가 실제 좋은 diff인지, tool loop가 얼마나 길어지는지, reviewer가 어떤 bug를 찾는지 같은 점을 볼 수 있습니다. 그러나 공식 price, context, API behavior를 대신 소유하지 않습니다.
| 증거 유형 | 말할 수 있는 것 | 말할 수 없는 것 |
|---|---|---|
| Kimi first-party | Kimi가 저렴하고 pilot 가치가 있음 | Opus 4.7의 일반 대체품임 |
| Anthropic first-party | Opus의 model ID, price, context, migration boundary | 모든 task에서 premium price가 항상 맞음 |
| third-party page | 테스트 아이디어와 risk signal | 공식 가격이나 production default |
| 자체 dual-run | 우리 workflow의 교체 가능성 | 모든 팀에 적용되는 결론 |
coding agent pilot 방법
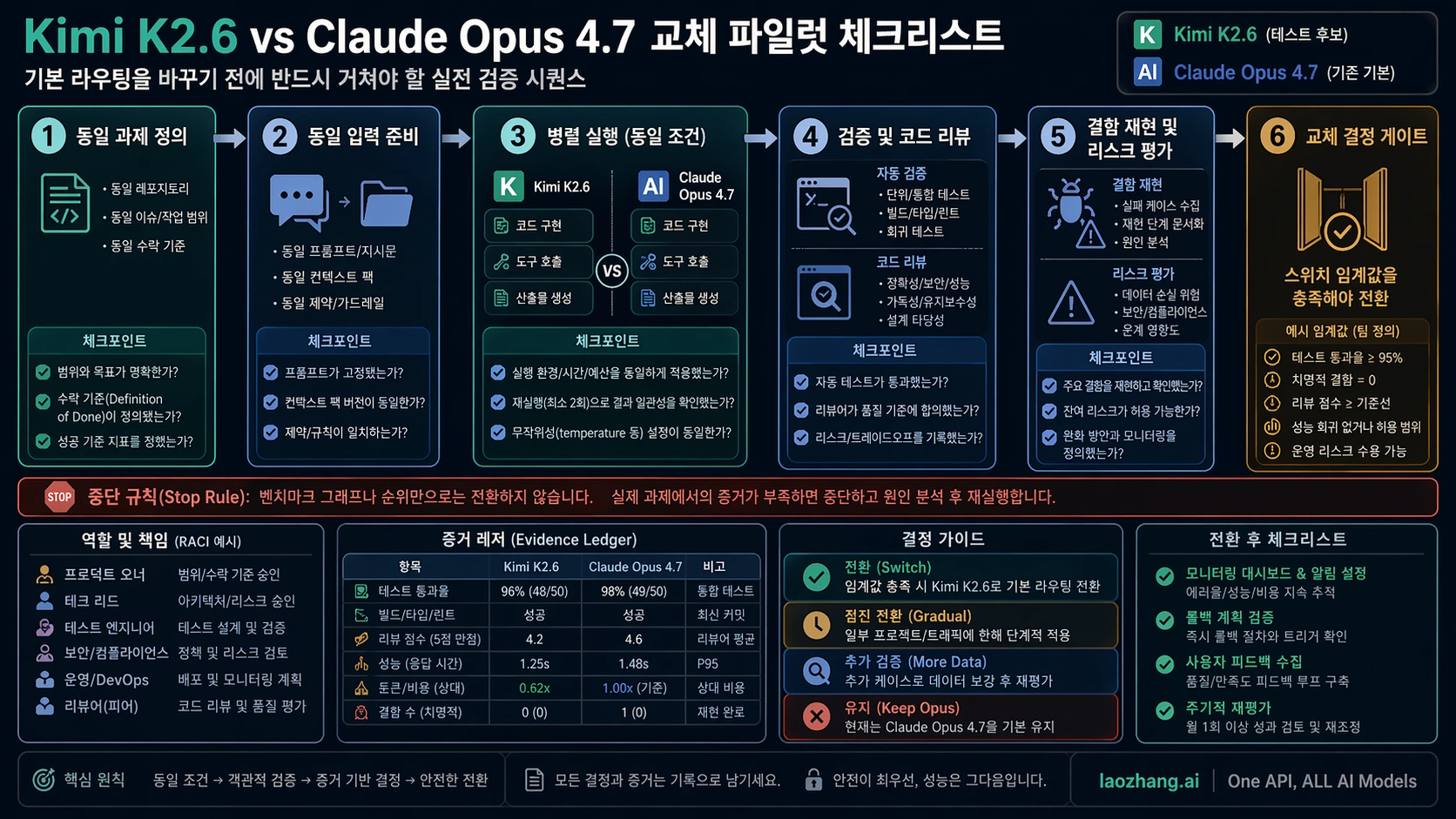
좋은 pilot은 단순해야 합니다. Opus가 실제로 도움이 되었던 task pack을 만듭니다. 작은 bug fix, 중간 refactor, test-writing, long-context task, 요구사항이 불완전해 모델이 질문해야 하는 task를 포함합니다. agentic coding이면 tool use와 repo navigation을 유지하고, API batch이면 실제 prompt template, timeout, retry policy를 유지합니다.
두 모델에는 같은 repository snapshot, 같은 task description, 같은 success criteria, 같은 tool budget, 같은 stop condition을 줍니다. unit, integration, lint, smoke check도 같습니다. 이후 diff를 직접 봅니다. test가 통과해도 over-broad refactor, fragile abstraction, migration step 누락, 주변 코드 오해가 남을 수 있습니다.
전환 기준은 시작 전에 써야 합니다. 예를 들어 low-risk batch edit은 Kimi의 real defect가 Opus보다 10% 이상 나쁘지 않고 cost가 절반 이하일 때 default 후보가 될 수 있습니다. security-sensitive code는 near-parity를 요구하고 더 오래 dual-run 해야 합니다.
workload별 경로

| workload | Kimi 먼저 | Opus 먼저 | default 전 dual-run |
|---|---|---|---|
| 대량 agent 실험 | 예 | quality sample로만 | 중요 repo 전 필요 |
| low-risk cleanup/test scaffolding | 예 | review time이 병목일 때 | auto-merge 전 필요 |
| repo-wide migration | control run 후 | 예 | 예 |
| security/payment code | 보통 아님 | 예 | 예 |
| long-context production analysis | 262k로 충분하고 cost가 우선일 때 | 1M 또는 128k output이 필요할 때 | Opus 판단을 대체하기 전 필요 |
| open-source/self-host 평가 | Kimi가 자연스러운 first route | Opus는 open route가 아님 | production decision과 경쟁 전 필요 |
Anthropic 내부 migration이 핵심이면 Claude Opus 4.7 vs Claude Opus 4.6을 보십시오. Anthropic, OpenAI, Google 사이의 broader frontier routing이면 Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro가 더 맞습니다.
API default 변경 전 점검
Kimi first-party와 provider route는 같은 것이 아닙니다. OpenRouter, Microsoft Foundry, 기타 marketplace는 latency, quota, billing, logs, support, failure terms가 다릅니다. 보고서에 가격을 쓰려면 그 가격의 owner를 같이 적어야 합니다.
Claude도 model ID만 바꾸는 작업이 아닙니다. Opus 4.7은 sampling parameters, extended thinking, tokenizer behavior, high-resolution image handling, task budgets 같은 API behavior를 확인해야 합니다. client가 오래된 top_p, top_k, temperature 조합을 던진다면 migration 문제는 prompt가 아니라 harness에 있을 수 있습니다.
rollout log는 cost, quality, time, route를 분리해야 합니다. cost는 cached input, input, output, retry, tool calls로 나누고, quality는 blocker/major/minor로 나눕니다. time은 reviewer minutes와 rerun을 기록합니다. route는 Kimi-only, Opus-only, dual-run, rollback으로 남깁니다.
평가 템플릿
| 기록 항목 | 기록 방법 | 이유 |
|---|---|---|
| cost | input, cached input, output, retry, tools | 싼 token과 싼 workflow를 구분 |
| quality | blocker, major, minor, style | 심각한 defect를 평균으로 숨기지 않음 |
| review | reviewer minutes, manual edits, rerun | agent coding의 실제 비용 확인 |
| route | Kimi-only, Opus-only, dual-run, rollback | pilot을 routing rule로 변환 |
자주 묻는 질문
Kimi K2.6이 Claude Opus 4.7보다 저렴한가요?
2026-04-23 first-party price 기준으로는 그렇습니다. Kimi는 input $0.95/MTok, output $4.00/MTok, cache hit $0.16/MTok입니다. Opus는 $5/$25입니다. provider price는 별도 계약입니다.
Kimi K2.6이 Opus를 대체할 수 있나요?
같은 workflow에서 증명한 뒤에는 가능합니다. 하지만 초기 주장은 “cost-sensitive coding work에서 Kimi pilot이 타당하다”이지, 자동 대체가 아닙니다.
coding agent에는 어느 쪽이 더 낫나요?
high-risk coding, migration, long-context production work는 Opus 4.7이 더 안전한 first choice입니다. 낮은 위험의 대량 시도는 Kimi K2.6을 먼저 테스트할 만합니다.
Kimi benchmark가 Opus 4.7 승리를 증명하나요?
아니요. Kimi 공식 table은 K2.6이 강하고 current라는 증거지만, Opus 4.7 직접 비교 증거는 아닙니다.
default model 변경 전에 무엇을 해야 하나요?
같은 repo, 같은 spec, 같은 tool budget, 같은 tests, 같은 reviewer, 같은 loss threshold로 dual-run 해야 합니다.
provider comparison page를 참고해도 되나요?
테스트 아이디어와 risk scouting에는 좋습니다. 공식 model ID, price, context, output, API behavior는 Kimi와 Anthropic first-party docs로 돌아가야 합니다.
1M context가 필요하면?
Claude Opus 4.7부터 시작하세요. Kimi의 262k context도 크지만 같은 계약은 아닙니다.