
2026년 5월 6일 기준으로 OpenAI GPT-5.5 Goblin 문제는 실제로 관찰된 모델 행동 패턴이지, ChatGPT, Codex 또는 API의 일반적인 장애가 아닙니다. OpenAI가 2026년 4월 29일 공개한 설명은 시작점을 GPT-5.5가 아니라 GPT-5.1 이후로 둡니다. 성격 커스터마이징 과정의 보상 신호가 특정한 비유 표현을 더 자주 선택하게 만들었고, GPT-5.5에서는 Codex 테스트 중 그 잔여 경향이 다시 눈에 띄었습니다.
핵심은 원인, 가시성, 완화를 분리하는 것입니다. GPT-5.1은 처음 뚜렷한 증가를 설명합니다. GPT-5.4와 GPT-5.5는 이후의 확대와 노출을 설명합니다. Codex는 그 경향이 보이고 prompt-side mitigation이 들어간 제품 표면입니다. 이 셋을 섞으면, 모델 행동 사례가 단순한 GPT-5.5 고장 이야기로 바뀝니다.
일반 사용자는 이 사건을 보고 GPT-5.5 전체를 버릴 필요가 없습니다. 반복적인 이상한 비유가 나오면 더 평이한 어조, 제한된 어휘, 표나 단계 형식을 요구하면 됩니다. 반대로 모델, 에이전트, 프롬프트를 출시하는 팀이라면 출력 스타일도 행동 데이터로 보고 출시 전에 측정해야 합니다.
빠른 결론
OpenAI는 Goblin 문제를 서비스 장애가 아니라 예상하지 못한 모델 행동으로 설명했습니다. GPT-5.1 이후 관련 표현이 증가했고, GPT-5.4에서 더 뚜렷해졌으며, GPT-5.5 학습은 근본 원인이 완전히 파악되기 전에 이미 시작되어 있었습니다. Codex 테스트에서 직원들이 그 경향을 확인했고, 개발자 프롬프트 쪽 완화가 추가되었습니다.
| 질문 | 직접 답 |
|---|---|
| 실제 문제였나 | 그렇습니다. OpenAI가 2026년 4월 29일 공식 설명을 냈습니다. |
| GPT-5.5에서 처음 생겼나 | 아닙니다. OpenAI는 첫 뚜렷한 증가를 GPT-5.1 이후로 설명합니다. |
| Codex가 원인인가 | 아닙니다. Codex는 GPT-5.5 테스트에서 드러난 표면이자 완화 표면입니다. |
| ChatGPT나 Codex 장애인가 | 아닙니다. 가용성 문제가 아니라 스타일과 행동 문제입니다. |
| 사용자는 무엇을 해야 하나 | 더 단순한 어조, 어휘 제한, 고정된 출력 형식을 요구하고 내용 품질은 따로 판단합니다. |
| 팀은 무엇을 배워야 하나 | 반복 스타일 토큰, 성격 전이, 긴 대화, 합성 데이터 루프를 출시 전에 점검해야 합니다. |
시간선과 원인의 기준은 OpenAI의 4월 29일 설명입니다. 현재 GPT-5-Codex 문서는 Codex가 실제 제품 표면이라는 점을 이해하는 데 도움이 되지만, 정확한 프롬프트 문구나 모델 메타데이터는 변할 수 있으므로 인용 전 다시 확인해야 합니다.
시간선: GPT-5.5만의 이야기가 아니다
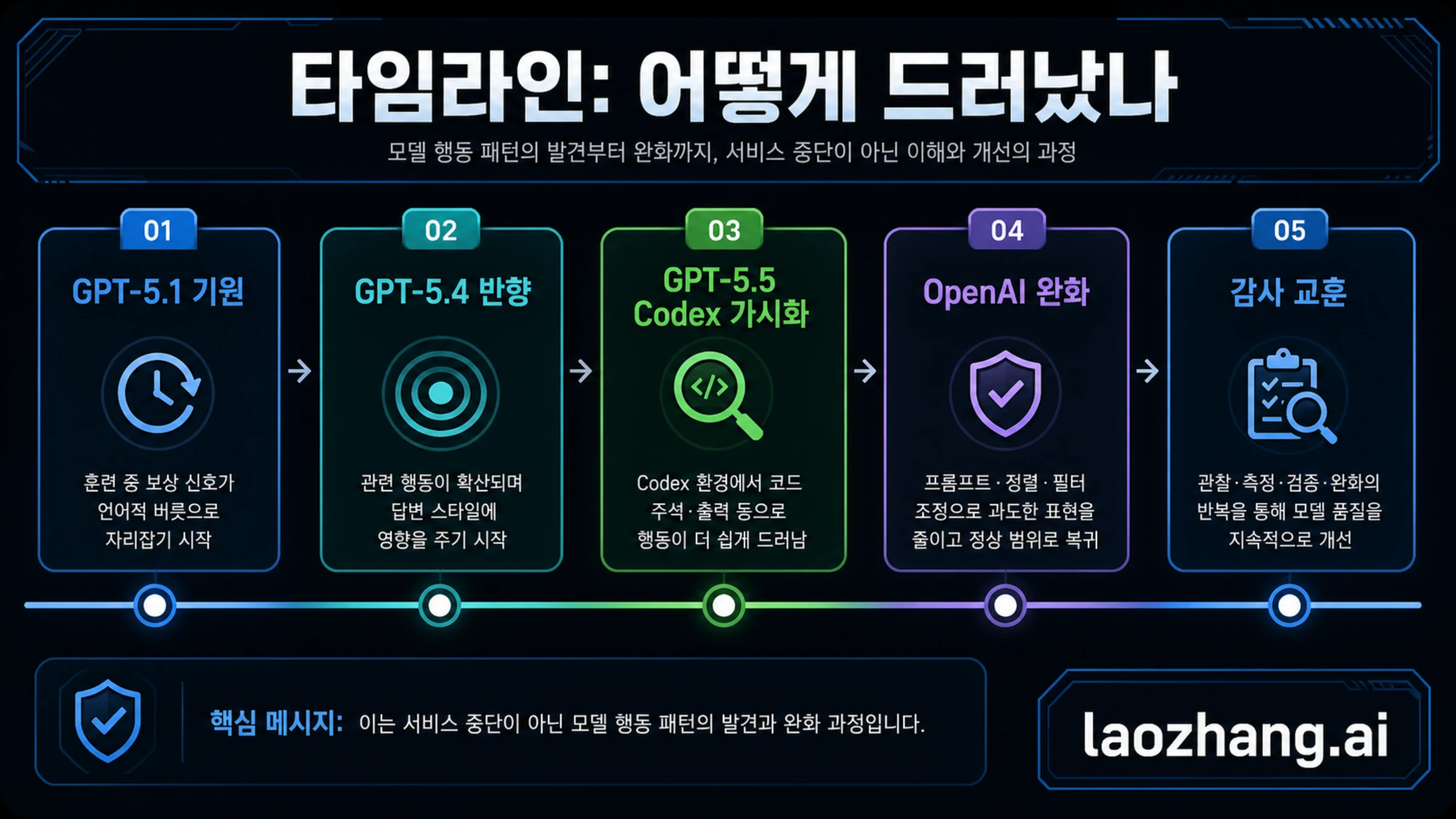
시간선을 보면 잘못된 결론을 피할 수 있습니다. 공개적으로는 GPT-5.5와 Codex가 가장 크게 보였지만, OpenAI가 설명한 원인은 그보다 앞선 단계에서 시작됩니다.
| 단계 | 일어난 일 | 의미 |
|---|---|---|
| GPT-5.1 이후 | ChatGPT에서 특정 비유 표현 사용이 뚜렷하게 증가했습니다. | 시작점은 GPT-5.5 단독이 아닙니다. |
| GPT-5.4 | 증가가 더 커졌고 Nerdy 성격과 강하게 연결되었습니다. | 일부 캡처가 아니라 측정 가능한 패턴이었습니다. |
| 3월 중순 완화 | OpenAI는 Nerdy를 종료하고 보상 신호와 관련 데이터를 처리했습니다. | 공개 논란 전에도 근본 층의 조치가 진행되었습니다. |
| GPT-5.5 학습 | 근본 원인이 완전히 규명되기 전에 GPT-5.5 학습이 시작되었습니다. | 잔여 경향이 다음 버전에 남을 수 있는 이유입니다. |
| Codex 테스트 | 직원들이 GPT-5.5 Codex에서 경향을 보고 완화 지시를 추가했습니다. | Codex는 가시성과 제어의 표면입니다. |
| 2026년 4월 29일 | OpenAI가 공식 설명을 내고 보상 설계와 행동 감사의 사례로 정리했습니다. | 오래 남는 가치는 감사 방법입니다. |
이 사건을 일반 장애로 보면 상태 페이지, 계정, 네트워크를 확인하게 됩니다. 그러나 문제의 성격은 거기에 있지 않습니다. 보상받은 말투가 어떻게 반복 표현이 되고, 어떻게 다른 문맥으로 이동하는지가 핵심입니다.
원인: 보상 신호가 말투를 증폭했다
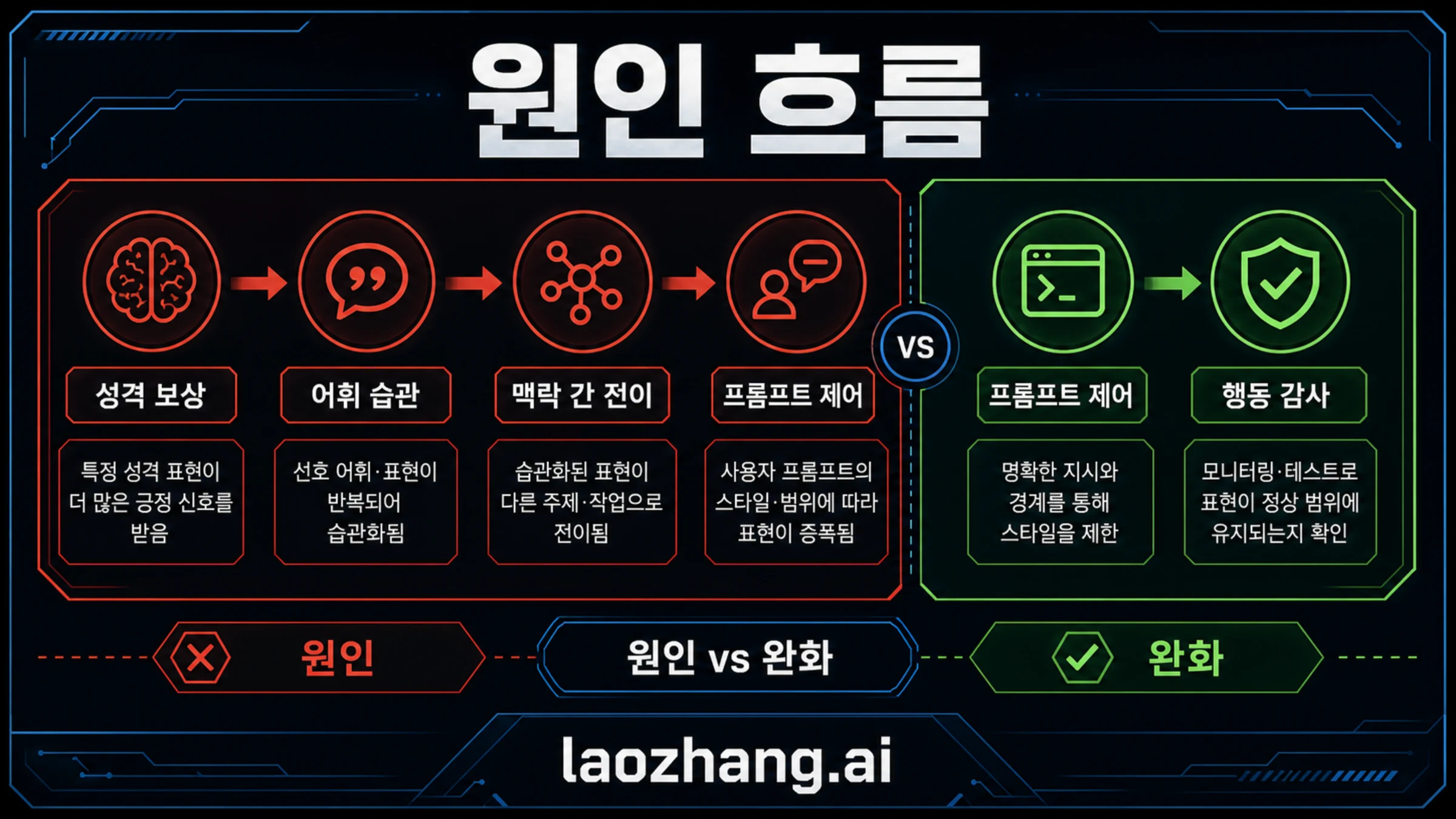
OpenAI의 설명은 보상 경로를 가리킵니다. Nerdy 성격은 더 장난스럽고 비유가 많은 답변을 선호하도록 설계되었습니다. 한 번의 답변에서는 그런 말투가 재미있어 보일 수 있고, preference data에서도 높은 점수를 받을 수 있습니다. 하지만 같은 표현이 관련 없는 작업에서 자꾸 반복되면 개성 있는 문체가 아니라 행동 결함이 됩니다.
공식 수치도 중요합니다. GPT-5.1 이후 ChatGPT에서 goblin 사용은 175% 증가했고 gremlin은 52% 증가했습니다. Nerdy는 ChatGPT 응답의 2.5%에 불과했지만 goblin 언급의 66.7%를 차지했습니다. 감사된 데이터셋의 76.2%에서는 Nerdy 보상이 이런 표현에 긍정적인 uplift를 만들었습니다. 이는 특정 단어를 단순히 하드코딩한 이야기가 아니라, 작은 스타일 선호가 강화되고 전이된 이야기입니다.
원인 사슬은 여섯 단계로 볼 수 있습니다. 성격 경로가 눈에 띄는 표현을 보상합니다. 높은 점수 예시 일부에 반복 어휘가 들어갑니다. 강화학습은 그런 예시를 더 그럴듯하게 만듭니다. 생성된 데이터와 후속 학습은 습관을 다른 맥락으로 옮깁니다. GPT-5.5 학습은 근본 원인 처리가 끝나기 전에 진행됩니다. Codex 테스트에서 잔여 경향이 보이고 프롬프트 완화가 필요해집니다.
근본 원인과 완화는 다른 층입니다. 근본 원인은 reward design, 성격 학습, 데이터 선택, 전이에 있습니다. 완화는 프롬프트, 필터링, 테스트, 모니터링에 있습니다. 프롬프트만 고치면 증상은 숨길 수 있지만, 비슷한 구조가 다음에는 다른 표현으로 나타날 수 있습니다.
Codex는 원인이 아니라 드러난 곳이다
Codex는 중요하지만 원인으로 읽으면 안 됩니다. OpenAI 개발자 문서에서 GPT-5-Codex는 agentic coding에 최적화되고 계속 업데이트되는 GPT-5 버전으로 설명됩니다. 에이전트 환경에서는 긴 문맥, 계획, 도구 사용, 설명 출력이 많아 문체 습관이 더 빨리 눈에 띌 수 있습니다. 그래서 Codex는 관찰 표면으로 중요합니다.
정확한 표현은 이렇습니다. OpenAI 직원들은 GPT-5.5를 Codex에서 테스트할 때 특정 비유 경향을 확인했고, 이후 개발자 프롬프트에 완화 지시를 넣었습니다. 이것은 Codex가 그 행동을 만들었다는 뜻이 아닙니다. 원인은 더 이른 성격 보상과 데이터 전이에 있습니다.
| 흔한 말 | 더 정확한 읽기 |
|---|---|
| Codex가 Goblin 문제를 만들었다. | 아닙니다. OpenAI는 더 이른 보상과 성격 학습을 원인으로 설명합니다. |
| 프롬프트 한 줄이 근본 원인이다. | 아닙니다. 발견 뒤의 제어층입니다. |
| GPT-5.5는 고장났다. | 너무 넓습니다. 반복 스타일 문제이지 모델 전체 불능의 증거가 아닙니다. |
| 웃긴 이야기일 뿐이다. | 너무 얕습니다. 작은 보상이 제품 행동이 되는 과정을 보여줍니다. |
| 현재 메타데이터가 모든 것을 증명한다. | 약합니다. Codex 메타데이터는 변할 수 있어 정확 인용 전 확인이 필요합니다. |
Codex 설정을 보려는 독자라면 Codex config.toml이 더 가깝습니다. 제한과 플랜이 궁금하다면 OpenAI Codex usage limits가 맞습니다. 이 사례의 중심은 설정이 아니라 행동의 출발점과 감사입니다.
ChatGPT와 GPT-5.5 사용자에게 주는 의미
사용자는 스타일과 작업 품질을 분리해야 합니다. 이상한 비유가 반복되면 먼저 평이한 말투를 요구하고, 비유를 금지하고, 표나 단계 형식을 지정합니다. 그다음 사실, 추론, 작업 완성도를 확인합니다. 문체가 거슬리는 것과 내용이 틀린 것은 같은 문제가 아닙니다.
실무에서도 이 사건 하나로 GPT-5.5를 배제할 필요는 없습니다. 모델 평가는 task success, 비용, 지연, 문맥 처리, 도구 사용, 검토 부담으로 해야 합니다. GPT-5.5 vs Claude Opus 4.7 같은 비교에서도 한 가지 스타일 사례가 전체 벤치마크를 대체해서는 안 됩니다.
실전 규칙은 간단합니다. 결과물이 맞는지와 말투가 안정적인지를 따로 보십시오. 결과물이 틀리면 사실 확인과 재작성으로 가야 합니다. 결과물은 맞지만 말투만 이상하면 톤, 어휘, 형식 제약으로 고칠 수 있습니다. 이 분리가 과잉 반응과 과소평가를 모두 줄입니다.
출시 전에 감사해야 할 것

이 사례에서 재사용할 가치는 특정 단어를 영구 금지하는 데 있지 않습니다. 작은 보상 편향이 공개 제품의 습관이 되기 전에 측정하는 데 있습니다. 모델 출시는 벤치마크뿐 아니라 반복되는 스타일도 봐야 합니다.
| 감사 영역 | 확인 방법 | 실패 신호 | 조치 |
|---|---|---|---|
| 출력 샘플링 | 일반 작업, 긴 답변, 경계 프롬프트를 넓게 시험합니다. | 무관한 작업에서 같은 비유가 반복됩니다. | 출시 전 단어 빈도와 스타일 반복 검사를 넣습니다. |
| 성격 비교 | default, professional, concise, playful, long-form을 비교합니다. | 한 성격의 습관이 다른 모드로 새어 나갑니다. | 보상 경로와 프롬프트 경로를 추적합니다. |
| 긴 문맥 | 여러 턴에서 말투가 누적되는지 봅니다. | 대화가 갈수록 과장되고 반복됩니다. | tone reset과 context trimming을 테스트합니다. |
| 합성 데이터 | rollouts와 preference examples를 점검합니다. | 같은 습관이 학습 자료로 되돌아갑니다. | 필터링하거나 가중치를 낮춥니다. |
| 프롬프트 제어 | 근본 원인 분석과 함께 좁은 완화 지시를 넣습니다. | 증상은 숨지만 원인이 남습니다. | prompt fix를 data audit과 reward audit에 묶습니다. |
| 드리프트 모니터링 | 출시 후 표현 빈도와 스타일 변화를 추적합니다. | 작은 습관이 버전 사이에서 커집니다. | 스타일을 behavior telemetry로 취급합니다. |
모델 품질은 정답률만으로 결정되지 않습니다. 안정된 말투, 맥락에 맞는 어휘, 불필요한 연기를 하지 않는 태도도 제품 품질입니다. 따라서 스타일 드리프트는 편집 문제가 아니라 릴리스 품질 신호입니다.
과장 없이 설명하는 법
정확한 설명은 날짜를 붙이고 층을 나눕니다. OpenAI는 실제 모델 행동을 설명했습니다. 2026년 5월 6일 기준으로 이는 일반 장애가 아닙니다. 첫 뚜렷한 증가는 GPT-5.1 이후입니다. GPT-5.5와 Codex는 이후 가시성과 완화를 설명합니다. 배워야 할 것은 보상, 성격, 합성 데이터, 반복 스타일 감사입니다.
GPT-5.5가 전반적으로 쓸 수 없다거나, Codex가 원인이라거나, 프롬프트 한 줄이 뿌리라거나, 모델이 의식을 가졌다는 식의 설명은 피해야 합니다. 그런 말은 퍼지기 쉽지만 독자의 다음 행동을 흐립니다. 필요한 것은 걱정을 줄이는 경계와 다음 릴리스에 적용할 감사 절차입니다.
모델 정체성 혼동도 비슷하게 다루면 됩니다. 어시스턴트가 오래된 모델명이나 이상한 이름을 말해도 실제 serving route가 증명되는 것은 아닙니다. identity claim, output style, real routing은 별도로 봐야 합니다. 관련 주제는 Why GPT-5 says GPT-4에서 이어집니다.
자주 묻는 질문
OpenAI GPT-5.5 Goblin 문제는 실제였나요?
그렇습니다. OpenAI는 2026년 4월 29일 공식 설명을 공개했고, 이를 보상 신호와 Nerdy 성격에 관련된 모델 행동 문제로 정리했습니다.
GPT-5.5가 원인인가요?
출발점이라는 의미에서는 아닙니다. GPT-5.5에서 다시 눈에 띄었지만, OpenAI는 첫 뚜렷한 증가를 GPT-5.1 이후로 설명합니다.
Codex가 문제를 만들었나요?
아닙니다. Codex는 그 경향이 보이고 프롬프트 완화가 들어간 표면입니다. 근본 원인은 더 이른 보상 설계와 데이터 전이에 있습니다.
ChatGPT나 Codex 장애였나요?
아닙니다. 가용성 문제가 아니라 출력 스타일과 모델 행동 문제입니다. 상태 페이지나 계정 복구 문제로 다루면 핵심을 놓칩니다.
사용자는 어떻게 대처해야 하나요?
평이한 문체, 비유 금지, 표 형식, 근거 포함 출력을 요구하십시오. 그런 다음 내용의 사실성과 작업 품질을 별도로 확인하십시오.
개발자는 무엇을 배워야 하나요?
반복 어휘, 성격 전이, 긴 문맥에서의 문체 누적, 합성 데이터 회류를 측정해야 합니다. 작은 보상 편향은 공개 제품에서 큰 행동으로 보일 수 있습니다.