
GPT-5가 GPT-4라고 말했다고 해서 그것만으로 ChatGPT가 정말 GPT-4로 돌아간 것은 아니다. OpenAI는 이제 이 점을 꽤 분명하게 설명한다. 응답 안에서 모델이 자신을 어떻게 부르는지는 생성된 텍스트이며, 틀릴 수도 있고 지나치게 일반적인 표현일 수도 있다. 만약 UI에 Used GPT-5 같은 메시지 단위 표식이 함께 보인다면, OpenAI는 그 표식을 그 메시지의 진짜 근거로 보라고 말한다.
이 혼란이 요즘 더 자주 보이는 이유는 지금의 ChatGPT가 더 이상 "하나의 채팅창 = 하나의 고정 모델" 구조가 아니기 때문이다. 상단 picker는 채팅의 기본 모델을 보여주지만, 특정 메시지는 다른 모델 경로로 라우팅될 수 있다. 오래된 대화는 모델 은퇴 이후 새로운 동등 모델로 이어질 수 있고, Custom GPT나 custom instructions 안에 남아 있는 오래된 GPT-4 문구는 답변 속으로 다시 스며들 수 있다. 이런 층들이 어긋날 때 가장 먼저 의심해야 할 것은 backend가 아니라, 답변 속 자기소개 문장이다.
이 글은 2026년 4월 1일 기준 OpenAI Help Center, ChatGPT Release Notes, GPT-5 System Card, OpenAI 개발자 문서를 다시 확인한 뒤 정리했다.
먼저 결론: 어떤 신호를 믿어야 하나
우선 아래 우선순위를 기억하면 된다.
| 신호 | 실제로 뜻하는 것 | 신뢰도 | 언제 쓰나 |
|---|---|---|---|
| 답변 속 "나는 GPT-4다" | 생성된 자기소개 | 낮음 | 단서 정도로만 보고 증거로 쓰지 않는다 |
Used GPT-5 같은 표식 | 그 메시지를 처리한 실제 모델 | 높음 | ChatGPT에서는 이걸 먼저 본다 |
| 상단 모델 picker | 해당 채팅의 기본 모델 | 중간 | 대화 기본값 확인용이지, 개별 답변 확정용은 아니다 |
| API request / logs | 앱이 실제로 호출한 모델 | API에서는 최고 | 구현, 검증, 회귀 테스트에서 사용 |

핵심은 단순하다. ChatGPT에서는 OpenAI가 메시지 단위 표식을 authoritative 하다고 설명하고, 답변 속 모델 자기소개는 fallible 한 생성 텍스트라고 설명한다. API에서는 request와 logs가 authoritative 신호이고, 모델이 자연어로 뭐라고 말했는지는 그보다 훨씬 약하다.
왜 지금 더 자주 보이나: ChatGPT의 GPT-5는 라우팅되는 시스템이다
OpenAI의 공식 설명만 봐도 이유의 대부분이 드러난다. GPT-5 System Card는 GPT-5를 실시간 router를 가진 통합 시스템으로 설명한다. router는 문맥, 복잡도, 도구 필요성, 명시적 의도를 보고 어떤 모델 경로를 쓸지 정한다. ChatGPT release notes 역시 GPT-5를 auto-switching 시스템으로 설명했고, 이후 Instant, Thinking, legacy model access 같은 제어를 점점 더 표면에 드러냈다.
즉 지금의 ChatGPT에서 "모델"이라는 말은 한 층이 아니다. 채팅의 기본 모델, 특정 메시지를 실제로 처리한 모델, 오래된 대화가 지금 어떤 동등 모델로 이어졌는지, 그리고 답변 속에서 모델이 자신을 뭐라고 불렀는지. 이 층들은 대체로 같지만 항상 같지는 않다. 어긋날 때 사용자는 자연스럽게 "모델 이름이 왜 서로 다르지?"라고 느낀다.
Used GPT-5에 대한 OpenAI 도움말은 이 구조를 더 선명하게 만든다. OpenAI는 특정 메시지가 별도로 다른 모델에 라우팅될 수 있고, 사용자가 선택한 모델은 채팅의 기본값으로 남는다고 설명한다. 다시 말해, picker에 보이는 라벨과 방금 그 답변을 실제로 처리한 모델은 잠깐 동안 다를 수 있다.
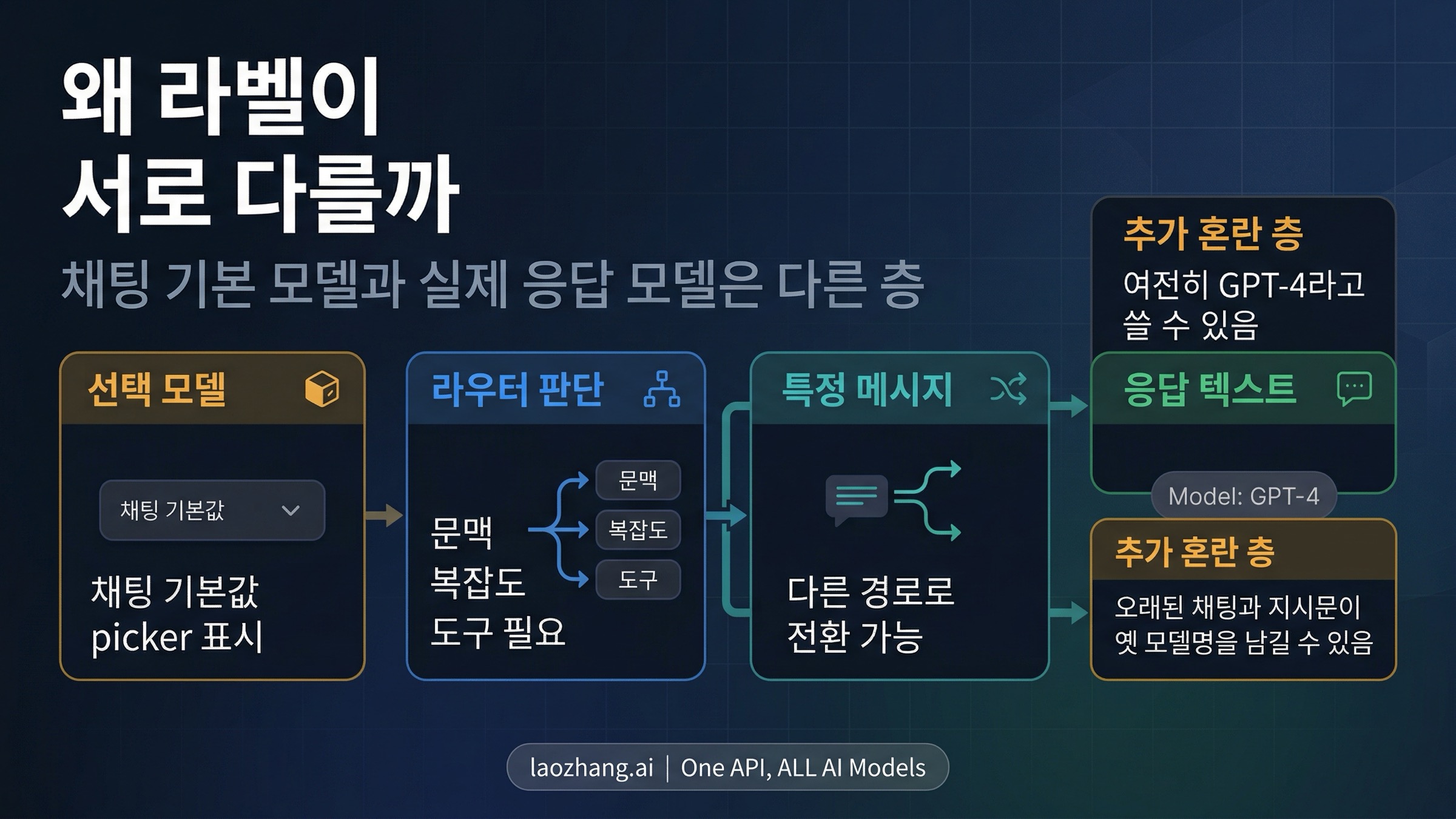
그래서 아래 세 가지가 동시에 나타나도 이상하지 않다.
- picker에는 원래 선택한 기본 모델이 남아 있다
- 특정 답변에는
Used GPT-5표식이 붙어 있다 - 답변 본문은 "GPT-4 모델로서..."라고 말한다
서로 완전히 모순되는 것이 아니다. 서로 다른 층의 정보일 뿐이며, 그중 가장 약한 신호가 본문 속 자기소개다.
가장 흔한 원인은 세 가지다
실제 사례 대부분은 세 가지 중 하나로 들어간다. 고치는 방법도 각각 다르다.
1. 특정 메시지만 다른 모델로 라우팅되었다. 이것이 OpenAI가 가장 명확하게 설명한 경우다. 도움말에는 시스템이 메시지 단위로 다른 모델 경로를 사용할 수 있다고 적혀 있다. 공개 문서에서 가장 분명한 예시는 sensitive topic 처리지만, System Card를 보면 복잡도, 도구 필요성, 문맥도 영향을 준다. UI가 Used GPT-5라고 말한다면, 그 메시지에 대해서는 본문 속 자기소개보다 이 표식을 더 믿어야 한다.
2. 오래된 채팅이나 오래된 모델 surface가 앞으로 이관되었다. OpenAI는 2026년에 여러 구형 ChatGPT 모델을 은퇴시키고, 기존 대화를 새로운 동등 모델로 이어 붙였다. release notes에 따르면 GPT-5.1을 쓰던 대화는 GPT-5.3 Instant 또는 GPT-5.4 Thinking / Pro 경로로 자동 이어진다. GPT-4o 등 은퇴 공지에도 conversations와 projects가 GPT-5.3 Instant / GPT-5.4의 동등 경로로 넘어간다고 적혀 있다. 그래서 "이 채팅은 예전에 이런 모델이었지"라는 기억이 현재 backend보다 뒤처지기 쉽다.
3. 지시문 안에 오래된 GPT-4 문구가 남아 있다. OpenAI는 "그래서 GPT-5가 GPT-4라고 말한다"는 전용 도움말을 낸 적은 없으므로, 이 부분은 공식 문장이라기보다 inference로 다루는 것이 정직하다. 하지만 꽤 강한 inference다. OpenAI는 personality와 custom instructions가 이제 모든 채팅에 즉시 적용된다고 말한다. 또 GPT-5 prompting guide에서는 GPT-5가 지시에 매우 민감하고, 모호하거나 충돌하는 지시가 특히 이상한 동작을 만들 수 있다고 설명한다. 두 사실을 합치면, builder prompt, system prompt, 저장된 템플릿, custom instructions 어딘가에 You are GPT-4 같은 오래된 identity 문구가 남아 있을 때 GPT-5가 여전히 GPT-4라는 이름을 반복할 수 있다는 결론은 충분히 자연스럽다.
세 번째 유형이 문제를 가장 끈질기게 보이게 만든다. 메시지 라우팅은 보통 일시적이고, 오래된 채팅 이관도 날짜와 release notes를 보면 설명된다. 하지만 낡은 prompt 문구는 지우기 전까지 계속 같은 이름을 끌고 나온다.
실제로 무엇이 답했는지 어떻게 확인하나
확인 방법은 surface에 따라 달라야 한다.
ChatGPT에서는 먼저 OpenAI가 직접 authoritative 하다고 말한 것을 본다. 답변에 Used GPT-5 같은 표식이 있다면 그 메시지의 source of truth로 취급한다. 그 다음 picker를 보면 채팅의 기본 모델을 알 수 있다. 하지만 그것만 보고 방금 그 답변의 처리 모델까지 확정했다고 생각하면 안 된다.
오래된 스레드라면, 예전 기억만으로 판단하지 말고 최신 release notes와 retirement notice를 먼저 확인하는 편이 낫다. OpenAI는 이미 오래된 대화가 새로운 동등 모델로 이어지는 동작을 문서화했다.
Custom GPT를 쓰는 경우라면, 모델에게 계속 "너 누구냐"고 묻는 것보다 builder 설정과 instruction text를 확인하는 편이 훨씬 낫다. 자연어 자기소개는 가치가 낮고, 실제 지시문 텍스트는 가치가 높다.
API는 더 분명하다. ChatGPT의 메시지 단위 routing 감각을 API에 그대로 가져오면 안 된다. API에서 authoritative 한 것은 request와 logs다. 앱이 GPT-5를 요청했는데 답변이 "나는 GPT-4"라고 말했다면, 그것은 backend의 비밀 교체를 증명하기보다 prompt / output 층의 문제를 시사하는 경우가 더 많다.
잘못된 이름이 계속 나올 때는 이렇게 고친다
원인 층을 알면 고치는 길은 짧다.
- 새 채팅으로 다시 테스트한다. 오래된 스레드에는 오래된 문맥, 오래된 전환, 오래된 지시문이 너무 많이 남아 있다.
- 모델 설정에서 switching과 legacy access를 확인한다. 이 기능 자체가 문제는 아니지만, default와 actual message model을 헷갈리게 만들기 쉽다.
- Custom GPT instructions, personal instructions, 오래 쓰던 prompt template를 점검한다.
You are GPT-4,As GPT-4같은 옛 identity 문구를 찾는다. 지속적으로 재발하는 경우 원인은 여기에 있는 경우가 많다. - API에서는 반드시 logs를 본다. 자연어 자기소개를 검증 수단으로 쓰는 것은 회귀 테스트나 배포 확인에 적합하지 않다.

지금의 ChatGPT에서 가장 버려야 할 습관 하나를 꼽으면, "네 모델 이름을 말해 봐"를 검증 절차로 쓰는 것이다. 예전보다 훨씬 unreliable 하고, API 디버깅에서는 특히 그렇다.
그렇다면 실제로 GPT-4를 쓰고 있다는 뜻인가
대부분은 아니다. 적어도 그 문장 하나만으로는 그렇게 결론 내릴 수 없다.
답변 본문에 GPT-4가 나왔다는 사실만으로는 약한 증거다. OpenAI는 이런 자기지칭이 틀리거나 지나치게 일반적일 수 있다고 인정한다. 반대로 UI가 Used GPT-5라고 말한다면 그쪽이 더 강한 증거다. API logs에 GPT-5 request가 남아 있다면 그것도 본문 자기소개보다 훨씬 강한 증거다.
정말 중요해지는 순간은 잘못된 이름이 더 강한 신호와 함께 맞아떨어질 때다. 예를 들어 builder instructions 안에 실제로 낡은 GPT-4 identity text가 남아 있거나, 사용자가 의도적으로 legacy surface를 고른 경우, 혹은 logs의 model path가 기대와 다를 경우다. 그럴 때에만 단순한 wording mismatch가 아니라 configuration 또는 product layer 문제라고 봐야 한다.
가장 실용적인 규칙
GPT-5가 GPT-4라고 말하면, 먼저 backend가 틀렸다고 의심하기 전에 그 한 문장이 틀렸다고 가정하자.
그리고 surface에 맞는 가장 강한 신호를 확인하면 된다. ChatGPT라면 메시지 표식과 settings, API라면 request와 logs, Custom GPT라면 builder와 instruction text. 그러면 흐릿한 모델 이름 미스터리는 짧은 진단 절차로 바뀐다.