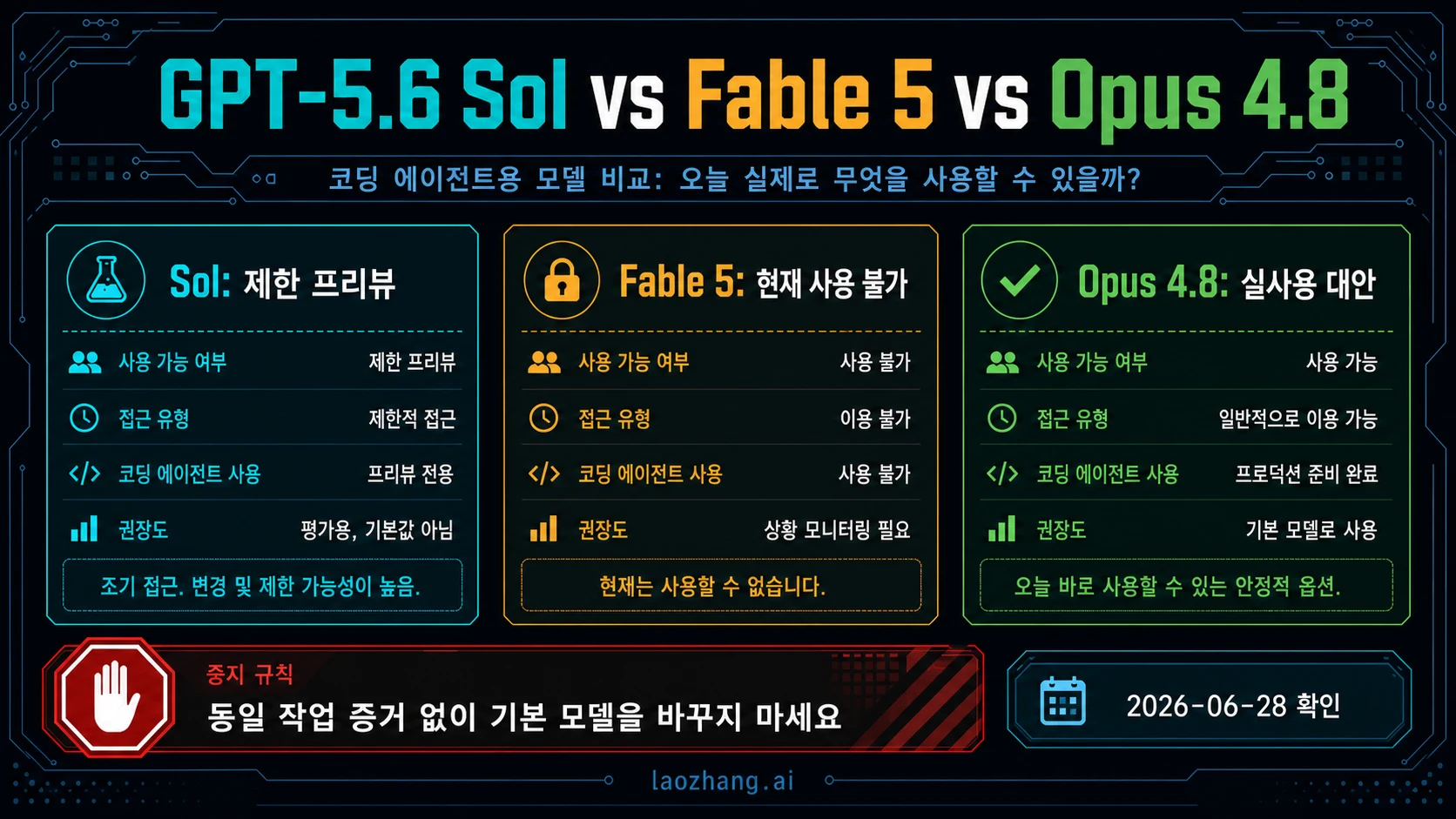
GPT-5.6 Sol, Claude Fable 5, Claude Opus 4.8은 지금 같은 수준의 live 선택지가 아닙니다. 2026년 6월 28일 기준 OpenAI는 GPT-5.6 Sol을 approved organization 대상 limited preview로 설명합니다. Anthropic은 Claude Fable 5를 current access unavailable로 표시합니다. Claude Opus 4.8은 오늘 coding-agent evaluation에 넣을 수 있는 live Anthropic route입니다.
실무 결론은 간단합니다. 필요한 API org 또는 Codex workspace에 Sol preview access가 있으면 Sol을 어려운 coding task pilot에 넣습니다. Fable 5를 검토 중이면 Anthropic official access가 바뀔 때까지 기다리고 다시 확인합니다. 오늘 production endpoint, logs, policy, rollback path가 필요하면 Opus 4.8을 live baseline으로 둡니다. 동일 repo, 동일 prompt, 동일 tools, 동일 tests, 동일 cost log에서 이기기 전에는 default model을 바꾸지 않습니다.
| 2026-06-28 current route | 첫 행동 | 이유 | stop rule |
|---|---|---|---|
| 관련 surface에 Sol preview access가 있음 | Sol을 hard coding-agent tasks로 테스트 | OpenAI는 Sol을 GPT-5.6 flagship으로 설명하고 terminal-driven coding을 강조합니다. | preview workspace 결과를 access 없는 team에 일반화하지 않습니다. |
| Claude Fable 5를 고려 중 | Anthropic access를 기다리고 재확인 | current Anthropic material은 Fable 5 unavailable입니다. | list price나 오래된 demo를 deployability로 보지 않습니다. |
| 오늘 production model이 필요 | Claude Opus 4.8을 live baseline으로 사용 | Opus 4.8은 Anthropic 및 listed partner routes에서 available로 표시됩니다. | same-task evidence 없이 default를 바꾸지 않습니다. |
빠른 답
coding team의 비교는 모델 왕관이 아니라 access에서 시작합니다. Sol은 흥미로운 preview model이고, Fable은 현재 production route가 아닌 premium promise이며, Opus 4.8은 live fallback입니다. 이 순서는 바뀔 수 있으므로 access, price, platform claim에는 2026년 6월 28일 공식 자료 재확인 날짜가 붙어야 합니다.

Sol은 approved OpenAI route가 있고 preview risk를 감수할 가치가 있는 일에 씁니다. Opus 4.8은 supported endpoint, account policy, logs, rollout path가 지금 필요한 일에 씁니다. Fable 5는 Anthropic이 access를 복구하기 전까지 waitlist/recheck에 두고 production recommendation으로 쓰지 않습니다.
정확한 비교 페이지는 benchmark table부터 보여주는 경우가 많습니다. scan에는 좋지만 가장 중요한 engineering decision을 가릴 수 있습니다. 접근할 수 없는 강한 모델은 production default가 아닙니다. unavailable model의 list price도 planning number일 뿐입니다.
Access status가 첫 분기입니다
OpenAI의 GPT-5.6 Sol material은 limited preview를 말하며 self-service launch가 아닙니다. Help page는 API organization access와 Codex workspace access도 분리합니다. 즉 API org approval이 Codex workspace의 Sol 사용을 증명하지 않습니다. Codex migration이면 workspace entitlement를 먼저 확인해야 합니다.
Anthropic의 Fable 5는 반대 경계입니다. model page, price row, benchmark discussion이 있어도 current access statement가 unavailable이면 traffic route가 아닙니다. 오래된 video, screenshot, third-party demo는 official access status를 덮을 수 없습니다.
Claude Opus 4.8은 오늘 deployability contract가 가장 명확합니다. Anthropic Opus page와 model overview는 Claude products, Claude Platform, AWS, Google Cloud, Microsoft Foundry를 listed route로 보여줍니다. implementation에서 확인할 row는 `claude-opus-4-8`입니다. social shorthand나 old Opus ID로 바꾸면 안 됩니다.
| contract item | GPT-5.6 Sol | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|---|
| access status | approved organization 및 scoped workspace limited preview. | current Anthropic materials: unavailable. | Anthropic 및 listed partner routes에서 generally available. |
| 오늘 역할 | access가 있을 때 preview test. | wait and recheck. | live baseline 또는 fallback. |
| API/model ID | approved OpenAI org에서 재확인 후 구현. | access disabled 중에는 production calls를 계획하지 않음. | `claude-opus-4-8`. |
| 주요 위험 | entitlement mismatch와 preview 결과 과대 일반화. | 오래된 demo나 list price를 live access로 착각. | same-task test 없이 winner로 취급. |
비용은 같은 작업 단위로 봐야 합니다
official list price는 같은 unit of work에 놓을 때만 유용합니다. OpenAI는 Sol preview pricing을 `5\` input, \`30` output per million tokens로 표시합니다. Anthropic은 Fable 5 list price를 `10\` input, \`50` output으로 표시하지만 unavailable 동안 deployable row가 아닙니다. Anthropic model docs는 Opus 4.8을 `5\` input, \`25` output으로 표시합니다.
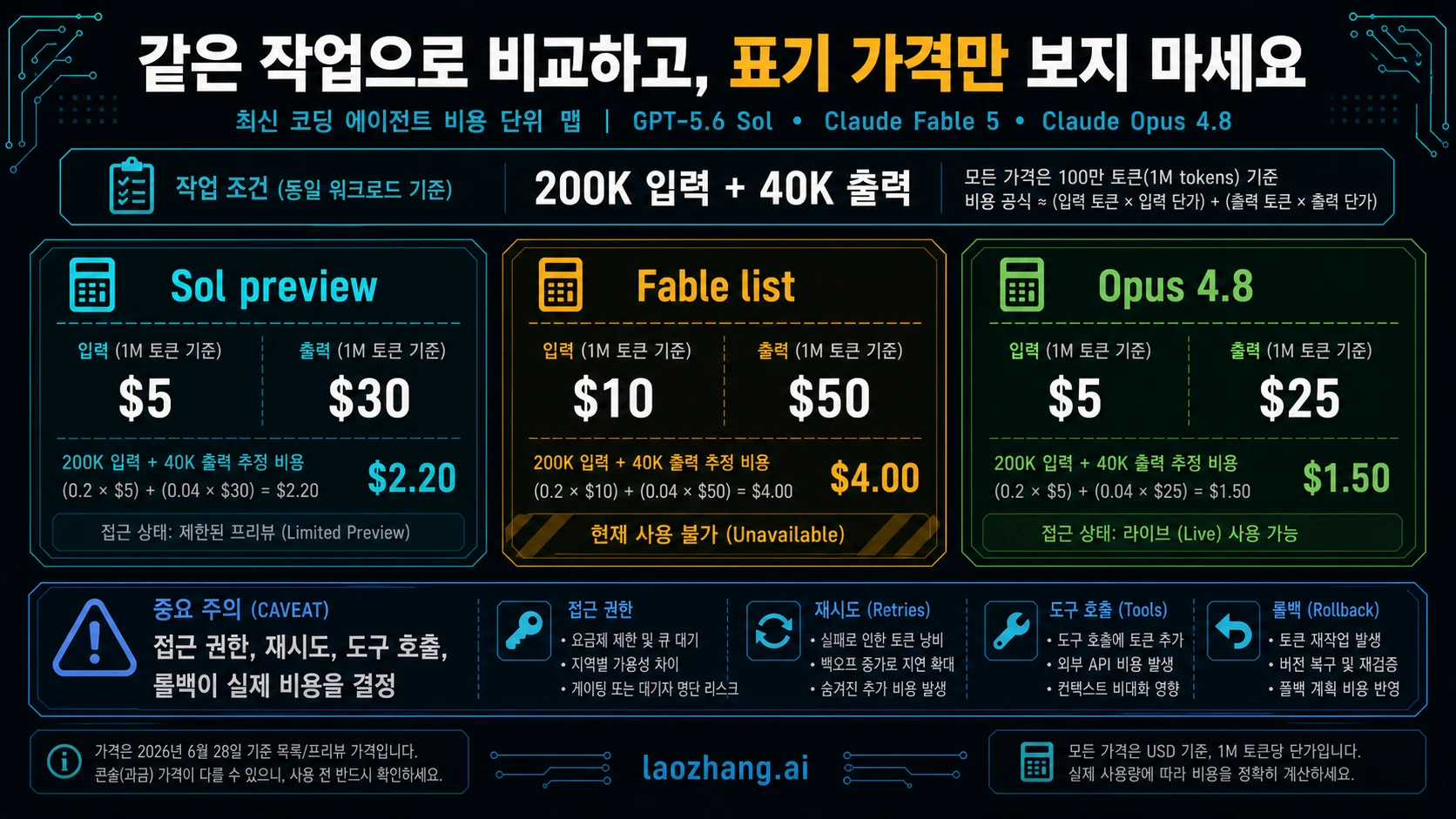
200k input과 40k output coding-agent run에서 cache, batch, retry, regional terms를 빼고 단순 계산하면 Sol은 약 `2.20\`, Fable은 약 \`4.00`이지만 unavailable, Opus 4.8은 약 `$2.00`입니다. 이것은 Opus가 항상 이긴다는 뜻이 아닙니다. Sol이 품질, 시간 절감, failure rate 감소로 넘어야 할 live price baseline이 Opus라는 뜻입니다.
진짜 비용은 task cost입니다. output rate가 조금 높아도 한 번에 끝내고 review minutes를 줄이면 더 쌀 수 있습니다. token row가 좋아도 tool loop, format drift, manual repair가 많으면 더 비쌉니다. input, cached input, output, retries, tool calls, elapsed time, human review minutes를 기록한 뒤 switch를 승인해야 합니다.
Benchmark는 먼저 테스트할 대상을 정할 뿐입니다
benchmark는 access table을 건너뛰는 이유가 아닙니다. OpenAI의 Sol launch는 terminal-driven agentic coding을 강조하고 강한 결과를 보여줍니다. Sol preview access가 있고 workload가 repository edits, terminal recovery, multi-step coding에 가깝다면 pilot에 넣을 이유가 충분합니다.
하지만 provider benchmark claims는 production team이 필요한 답보다 좁습니다. account access, tool harness compatibility, long-context prompt drift, total review time 감소를 증명하지 않습니다. Anthropic이 unavailable이라고 표시하는 Fable 5를 deployable로 만들지도 않습니다.
benchmark rows는 workload hints로 사용합니다. terminal coding이고 Sol access가 있으면 Sol을 first pilot lane에 둡니다. customer-facing output이 있는 live API agent라면 Opus 4.8을 stable lane에 둡니다. Fable-specific research는 harness만 보관하고 Anthropic access page가 바뀔 때까지 production cutover를 잡지 않습니다.
Coding-agent test plan
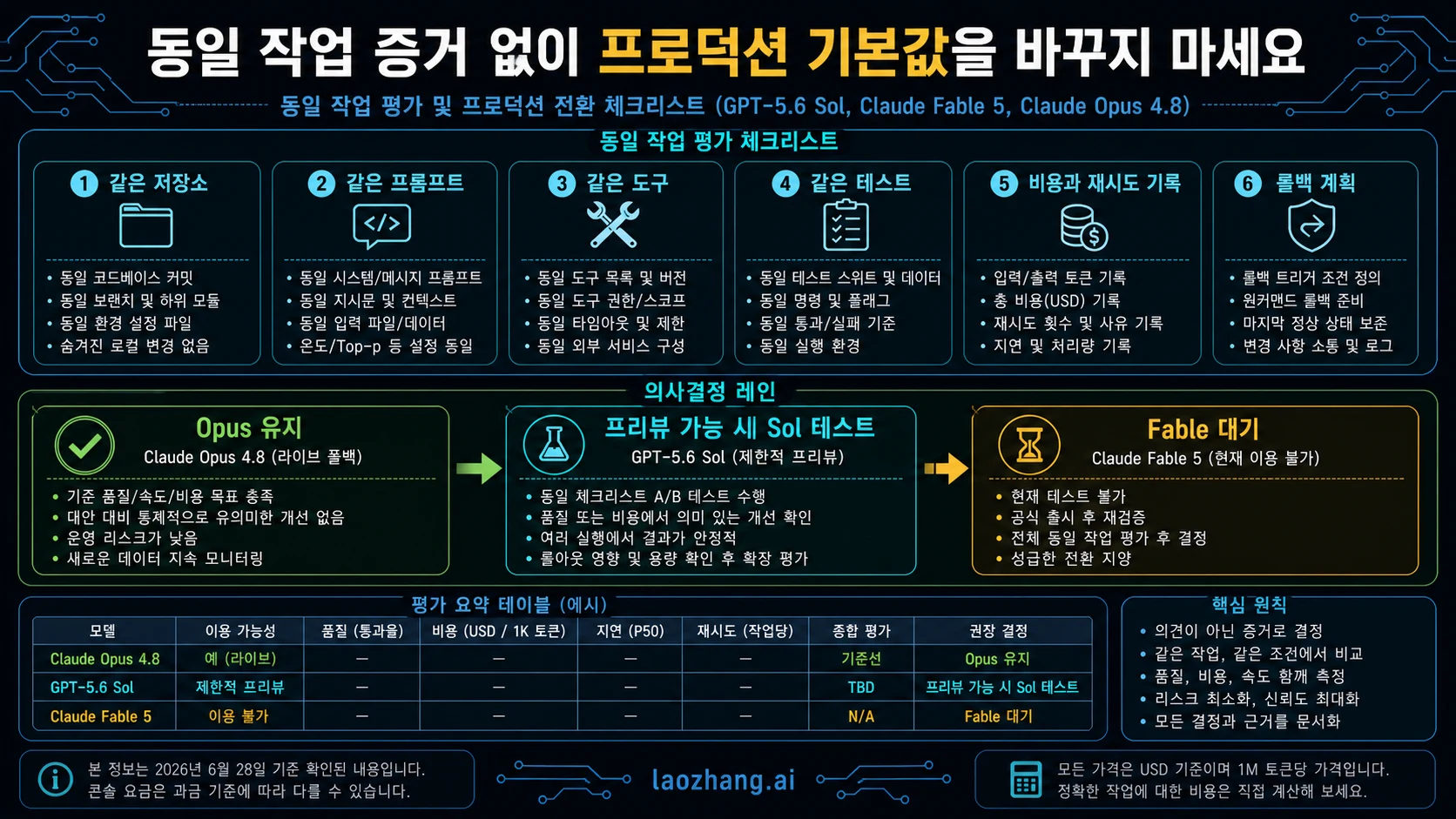
공정한 비교는 같은 headline이 아니라 같은 일을 사용합니다. 이미 review time을 쓰고 있는 10-20개의 task를 고릅니다. failing test fix, hidden constraints가 있는 refactor, long-context bug hunt, code verification이 필요한 docs update, tool recovery task를 포함합니다. 선호 모델이 이기기 쉬운 demo prompt는 고르지 않습니다.
Opus 4.8은 실제 deploy 가능한 endpoint에서 실행합니다. Sol은 실제 approved된 OpenAI surface에서만 실행합니다. Fable은 access가 돌아올 때까지 future-test column에 둡니다. 각 run마다 first-pass correctness, tool recovery, format stability, output length, total tokens, retry count, latency, review minutes를 기록합니다.
default-switch threshold는 보수적이어야 합니다. 같은 task set에서 total work를 줄이고 rollback route가 있을 때만 production default가 됩니다. Sol이 preview workspace에서만 이기면 specialist route로 둡니다. Opus가 reliability와 live support로 이기면 baseline을 유지합니다. Fable이 돌아오면 old comparison이 아니라 같은 harness로 다시 평가합니다.
이미 가까운 모델을 쓰고 있다면
GPT-5.5나 Opus 4.7 비교를 읽었다면 가져올 것은 route-first habit이지 old facts가 아닙니다. GPT-5.5 vs Claude Opus 4.7은 평가 구조로는 유용하지만 access state, model names, price rows가 바뀌었습니다. price, context, availability는 official page에서 다시 확인해야 합니다.
Fable을 기다릴 가치가 있는지가 핵심이면 Claude Fable 5 vs GLM 5.2가 이전 Fable framing을 보충합니다. 하지만 current production rule은 더 분명합니다. Anthropic이 unavailable이라고 쓰는 동안 Fable 5는 next production step이 아닙니다.
오래가는 규칙은 짧습니다. 오늘 시스템을 지탱하는 live model을 유지합니다. access가 있고 risk를 감수할 수 있는 곳에만 preview model을 추가합니다. unavailable model은 watchlist에 둡니다. same-task evidence 없이 default로 올리지 않습니다.
자주 묻는 질문
GPT-5.6 Sol은 공개적으로 사용할 수 있나요?
아니요. OpenAI는 GPT-5.6 Sol을 approved organizations 대상 limited preview로 설명합니다. API org와 Codex workspace access는 별도로 확인해야 합니다. 해당 access가 없으면 Sol은 오늘 production option이 아닙니다.
Claude Fable 5는 지금 사용할 수 있나요?
Anthropic current Fable materials는 unavailable이라고 표시하고, 6월 12일 statement도 Fable 5와 Mythos 5가 disabled for all customers라고 말합니다. 지금은 wait-and-recheck model입니다.
Claude Opus 4.8이 가장 안전한 default인가요?
이 세 가지 중 Opus 4.8은 가장 명확한 live Anthropic baseline입니다. 그래도 이미 작동하는 default를 바꾸려면 same-task evaluation이 필요합니다.
어느 모델이 더 저렴한가요?
200k input과 40k output simple list math에서는 Opus 4.8이 약 `2.00\`, Sol preview가 약 \`2.20`, Fable list row가 약 `$4.00`이지만 unavailable입니다. 실제 비용은 cache, batch, retries, latency, review minutes에 따라 달라집니다.
Benchmark로 winner를 정할 수 있나요?
아니요. benchmark는 first pilot을 정합니다. production default는 access status, task fit, cost logs, failure rate, rollback safety로 정합니다.