
Codex와 Claude Code를 오가면서도 컨텍스트를 잃고 싶지 않다면 전체 대화를 복사하지 마세요. 옮겨야 할 것은 repo 규칙, 현재 작업 목표, 수정한 파일, 실행한 명령, 실패 근거, 이미 내린 결정, 다음 best action입니다. 코드 상태는 Git에 두고, 오래가는 규칙은 AGENTS.md와 CLAUDE.md에 두며, 임시 작업 상태는 짧은 handoff packet으로 남기는 편이 안전합니다.
Claude Code와 Codex는 이제 "어느 쪽이 코드를 쓸 수 있나"로 고를 도구가 아닙니다. 둘 다 충분히 강합니다. 실제로 틀리기 쉬운 지점은 작업 방식과 맞지 않는 도구에 돈을 쓰고, limit 표시를 잘못 읽고, 긴 transcript를 믿을 만한 기억으로 착각하는 것입니다. 5시간 창은 5시간의 실제 coding 시간을 보장하지 않습니다. 봐야 할 것은 context, model, tool, retry, review를 모두 지나서 얼마나 review 가능한 결과가 남는지입니다.
2026년 5월 23일 기준 결론은 이렇습니다. 월 20달러에서 처음 고른다면 Codex Plus가 더 넓은 실험 경로입니다. web, CLI, IDE, iOS, cloud task, code review를 한 플랜에서 볼 수 있고 현재 Codex 모델도 포함됩니다. 예외는 로컬 중심 개발자입니다. 하루 대부분이 로컬 repo, 권한 규칙, 긴 대화, 미커밋 변경 속에서 진행된다면 Claude Pro와 Claude Code가 더 잘 맞습니다. 월 100달러나 200달러에서는 브랜드가 아니라 작업 종류를 보세요. Claude Max는 긴 Claude Code 세션을 넓히고, Codex Pro는 local messages, cloud tasks, reviews의 작업 창을 넓힙니다. 최종 판단은 accepted diff, limit hit, 재작업 시간으로 해야 합니다.
빠른 선택표
| 상황 | 먼저 쓸 도구 | 이유 |
|---|---|---|
| 작업 중간에 두 도구를 전환 | 먼저 handoff packet | 다음 agent가 긴 transcript에서 결정을 추측하게 만들지 않는다. |
| 월 20달러로 넓게 테스트 | Codex | 여러 Codex surface와 최신 모델을 한 플랜에서 확인할 수 있다. |
| 월 20달러로 로컬 긴 작업 | Claude Code | 로컬 상태, 권한, 긴 steering에 강하다. |
| 월 100달러에서 Claude 사용이 많음 | Claude Max 5x | Claude 세션 공간을 늘리는 선택이다. |
| 월 100달러에서 Codex task와 review가 많음 | Codex Pro 5x | Codex의 다섯 시간 작업 창을 늘리는 선택이다. |
| 월 200달러, 병렬 작업 많음 | 역할별 병행 | Max 20x는 큰 Claude 세션, Codex Pro 20x는 위임과 review에 맞다. |
| 팀이 이미 둘 다 사용 | 라우팅 규칙 | 도구 통일보다는 작업 분류가 중요하다. |
컨텍스트 핸드오프: 전환해도 작업을 잃지 않는 법
믿을 수 있는 컨텍스트는 한쪽 채팅 기록이 아니라 두 도구가 다시 읽을 수 있는 곳에 있어야 합니다. Codex는 AGENTS.md 프로젝트 지침을 읽습니다. Claude Code는 AGENTS.md가 아니라 CLAUDE.md를 주로 읽습니다. 이미 AGENTS.md가 있는 repo라면 CLAUDE.md에서 @AGENTS.md를 import하고, Claude 전용 주의사항만 아래에 추가하세요. 이렇게 해야 공통 규칙이 한 곳에 남습니다.
| 컨텍스트 층 | 위치 | 핸드오프 규칙 |
|---|---|---|
| repo 장기 규칙 | AGENTS.md, 이를 import하는 CLAUDE.md | 같은 규칙을 두 파일에 수동 복제하지 않는다. |
| 현재 작업 상태 | issue, PR note, HANDOFF.md | 목표, 진행, 실패, 다음 행동을 적고 전체 transcript는 붙이지 않는다. |
| 코드 사실 | Git diff, branch, 테스트 출력, log | 다음 도구는 파일과 검증 결과에서 시작한다. |
| 접근과 안전 | task packet의 허용/금지 범위 | API key, token, private log를 붙이지 않는다. |
| 장기 기억 | 반복되는 규칙만 | 일회성 작업 소음은 policy가 아니다. |
최소 packet은 이 정도면 충분합니다.
md## Agent handoff packet Goal: Current state: Files touched: Commands/tests run: Known failures: Decisions already made: Do not redo: Next best action: Safety/permissions:
좋은 handoff는 “위 대화를 이어서 해줘”가 아닙니다. 어떤 테스트가 실패했는지, 어떤 파일을 건드렸는지, 무엇을 바꾸면 안 되는지, 다음에 어떤 명령을 실행해야 하는지 적습니다. 그래야 Claude Code의 로컬 조사를 Codex가 구현 task로 이어받고, Codex의 diff를 Claude Code가 로컬 문맥에서 설명할 수 있습니다.
팀에서 쓰려면 handoff packet에 세 가지를 더 넣으세요. 먼저 Git status를 분리합니다. 이미 commit된 변경, dirty 파일, untracked 파일, agent가 만든 임시 산출물을 한 줄씩 구분해야 다음 도구가 과거 diff를 새 목표로 오해하지 않습니다. 둘째, “다시 하지 말 것”을 적습니다. 인증 흐름 재설계 금지, 비싼 migration 재실행 금지, reviewer가 이미 받아들인 파일 수정 금지처럼 명시해야 합니다. 셋째, 두 번째 도구의 책임을 좁힙니다. Codex는 review 가능한 diff와 검증 명령을 돌려주고, Claude Code는 로컬 실패 원인, 권한 경계, 애매한 설계 판단을 설명해야 합니다. 이렇게 해야 전환이 같은 작업의 중복 실행이 아니라 검토 가능한 엔지니어링 인수인계가 됩니다.
handoff packet을 채울 수 없다면 아직 작업이 충분히 분해되지 않은 것입니다. 그때는 더 강한 모델이나 다른 도구로 밀어붙이지 말고, 사람이 수락 기준, 금지 디렉터리, 실패 조건을 먼저 정해야 합니다.
한도, token, 실제 작업 시간
개발자 논의에서는 "Claude Code 100 hours vs Codex 20 hours"나 "5-hour limit" 같은 표현이 자주 보입니다. 이는 실제 사용자 불만을 보여 주지만 계산식은 아닙니다. 실제 작업 시간은 매 턴 다시 보내는 context, 선택한 model, local/cloud 실행 위치, 마지막 human review 시간에 따라 달라집니다.
Codex는 capacity를 기록하기 쉽습니다. OpenAI의 현재 Codex pricing은 local messages와 cloud tasks가 5시간 창을 공유하고, 추가 weekly limits가 있을 수 있다고 설명합니다. 같은 message라도 model, repo 크기, 복잡도, 실행 surface에 따라 무게가 다릅니다. 남은 퍼센트만 보지 말고 완료한 task, accepted diff, 실패한 branch, review 시간을 기록하세요.
Claude Code는 세션 중 steering이 쉽지만 세션이 길어질수록 token burn이 커집니다. Anthropic 문서는 매 turn마다 이전 대화, project context, 새 prompt가 전송된다고 설명합니다. 읽은 파일, 생성한 diff, 논의한 판단이 다음 turn에 다시 붙습니다. '/clear', '/compact', model choice, 필요 없는 tool 끄기는 실제 지속 시간을 늘리는 방법입니다.
비교 기준은 "달러당 시간"이 아니라 "limit에 닿기 전 accepted work unit"입니다. Claude Code가 어려운 원인 조사 두 개를 끝내고, Codex가 review 가능한 branch 여섯 개를 만든다면 둘 다 가치가 있습니다. 현재 workflow에서 limit에 닿았을 때 더 쉽게 복구할 수 있는 쪽을 고르세요.
실측할 때는 작업 목표, agent가 실제로 읽거나 수정한 범위, 사람이 review한 시간, 최종적으로 main branch에 들어갔는지를 같은 표에 적으세요. Claude Code의 가치는 방향을 빨리 좁히고 로컬 혼란을 줄이는 데서 나오는 경우가 많습니다. Codex의 가치는 작업을 queue에 넣고 실패 branch를 쉽게 버릴 수 있는 데서 나오는 경우가 많습니다. 이 둘은 단순한 시간 나누기로 비교하기 어렵습니다.
또 하나는 중단 비용입니다. Claude Code에서 limit에 닿으면 로컬 조사 흐름을 다시 만들어야 할 수 있습니다. Codex task가 실패하면 branch를 버릴 수 있지만 setup 시간과 review 대기는 남습니다. limit hit 횟수뿐 아니라 다시 일할 수 있는 상태로 돌아오는 데 걸린 시간도 같이 기록하세요.
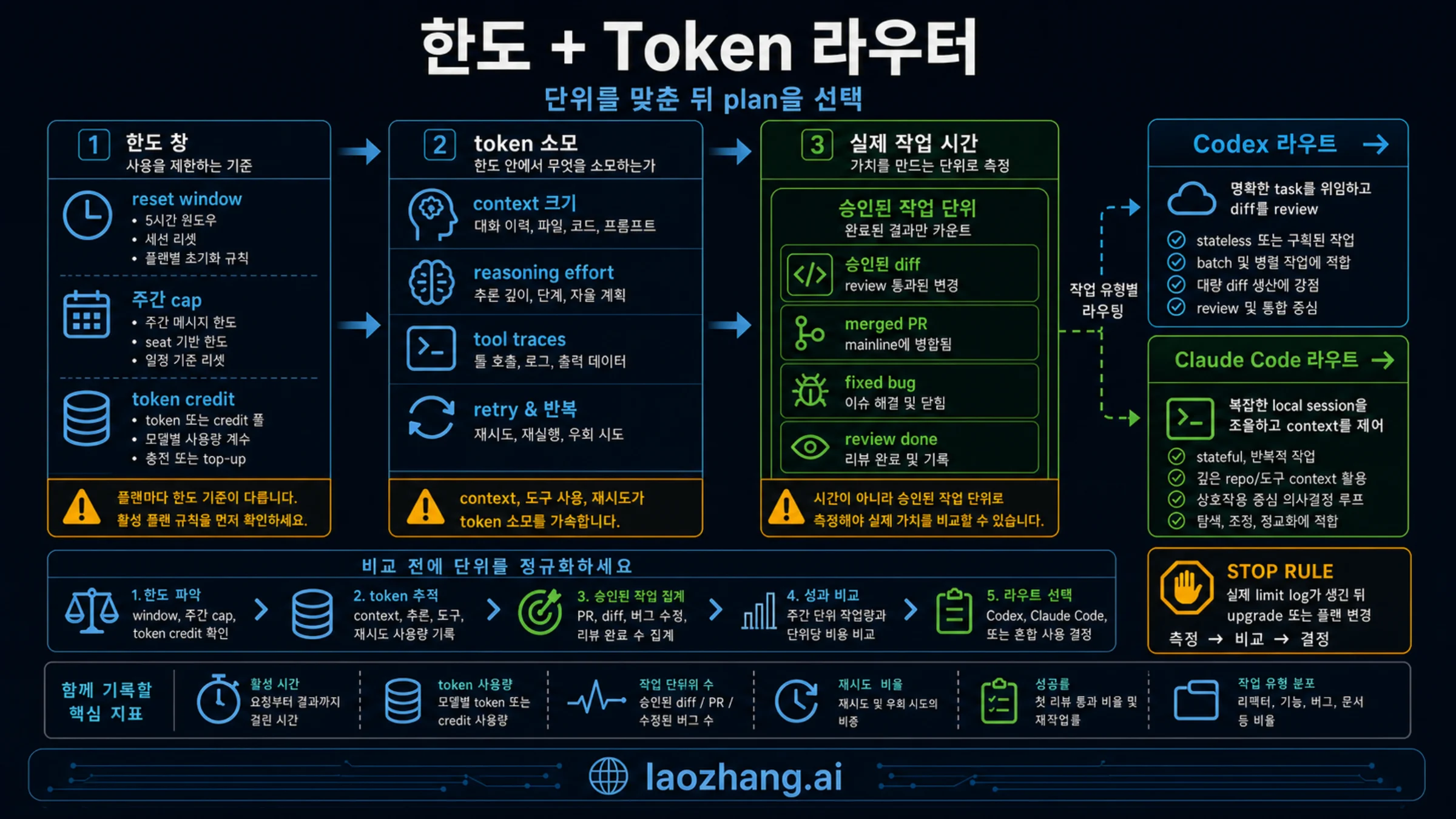
한도: 하나의 숫자로 줄이면 안 됩니다
OpenAI의 현재 Codex pricing은 한도를 세분화해서 보여줍니다. Plus는 월 20달러이고, 주 몇 번의 focused coding session에 맞는 플랜으로 설명됩니다. 포함 항목은 web, CLI, IDE extension, iOS, automatic code review, Slack 같은 cloud integration, GPT-5.5, GPT-5.4, GPT-5.3-Codex, GPT-5.4-mini입니다.
핵심은 Codex 한도가 local messages, cloud tasks, code reviews, model choice로 나뉜다는 점입니다. 누군가 "Codex 한도가 많다" 또는 "Codex가 빨리 막힌다"고 말해도 모델, 작업 종류, 시간 창을 모르면 판단할 수 없습니다. Codex는 이 분류가 보인다는 장점이 있지만, 그래서 더더욱 오래된 숫자를 복사하면 위험합니다.
Claude Code는 다르게 읽어야 합니다. Claude Code usage 문서는 사용자가 어떻게 로그인했는지에 따라 metering이 달라진다고 말합니다. Enterprise seat는 조직 플랜에 포함된 사용량을 쓰고, API key는 token 기반 pay-as-you-go입니다. 또한 context window가 가득 차면 오래된 대화가 흐려지고 품질이 떨어질 수 있다고 설명합니다. '/clear'는 새 작업을 시작할 때, '/compact'는 긴 작업을 이어갈 때 쓰는 핵심 도구입니다.
Anthropic은 2026년 5월 6일에 Pro, Max, Team, seat-based Enterprise의 Claude Code five-hour rate limits를 두 배로 올리고 Pro와 Max의 peak-hour reduction을 제거했습니다. 그래서 예전 limit 불만을 그대로 믿으면 안 됩니다. 하지만 늘어난 한도는 무제한이 아닙니다.
비용: 구독 가격 뒤에 실제 사용 비용이 있습니다
표면 가격은 비슷합니다. Claude Pro는 월 20달러, Max 5x는 월 100달러, Max 20x는 월 200달러입니다. Codex Plus도 월 20달러이고, Codex Pro는 100달러부터 시작하며 Plus보다 높은 한도를 제공합니다.
차이는 아래 계층입니다. Claude Code는 구독으로도 쓰지만 API key로 쓰면 token consumption에 따라 비용이 발생합니다. Anthropic cost docs는 API 사용은 token 소비로 과금되고, Pro와 Max subscriber는 사용량이 구독에 포함되며 '/usage'의 dollar figure가 실제 청구액은 아니라고 설명합니다. 기업 배포 평균은 active developer day당 약 13달러, 월 150-250달러로 제시되지만 모델, codebase size, 여러 instance, automation, context가 모두 비용을 바꿉니다.
Codex는 개인에게 더 단순합니다. Plus와 Pro에 Codex가 직접 포함됩니다. 그러나 GPT-5.5 local messages, cloud tasks, reviews는 여전히 제한된 작업 기회를 씁니다. API 청구서가 아니더라도 고가치 실행 창을 쓰는 것입니다.
가장 좋은 시작은 한 달 20달러 실험입니다. 일주일 동안 어떤 작업에서 limit에 가까워졌는지, 어떤 도구가 더 reviewable diff를 냈는지, 어떤 도구가 재작업을 줄였는지 기록하세요. 기록 없이 100달러 플랜으로 가면 생산성이 아니라 기대를 사는 경우가 많습니다.
안정성: 감이 아니라 상태를 봐야 합니다
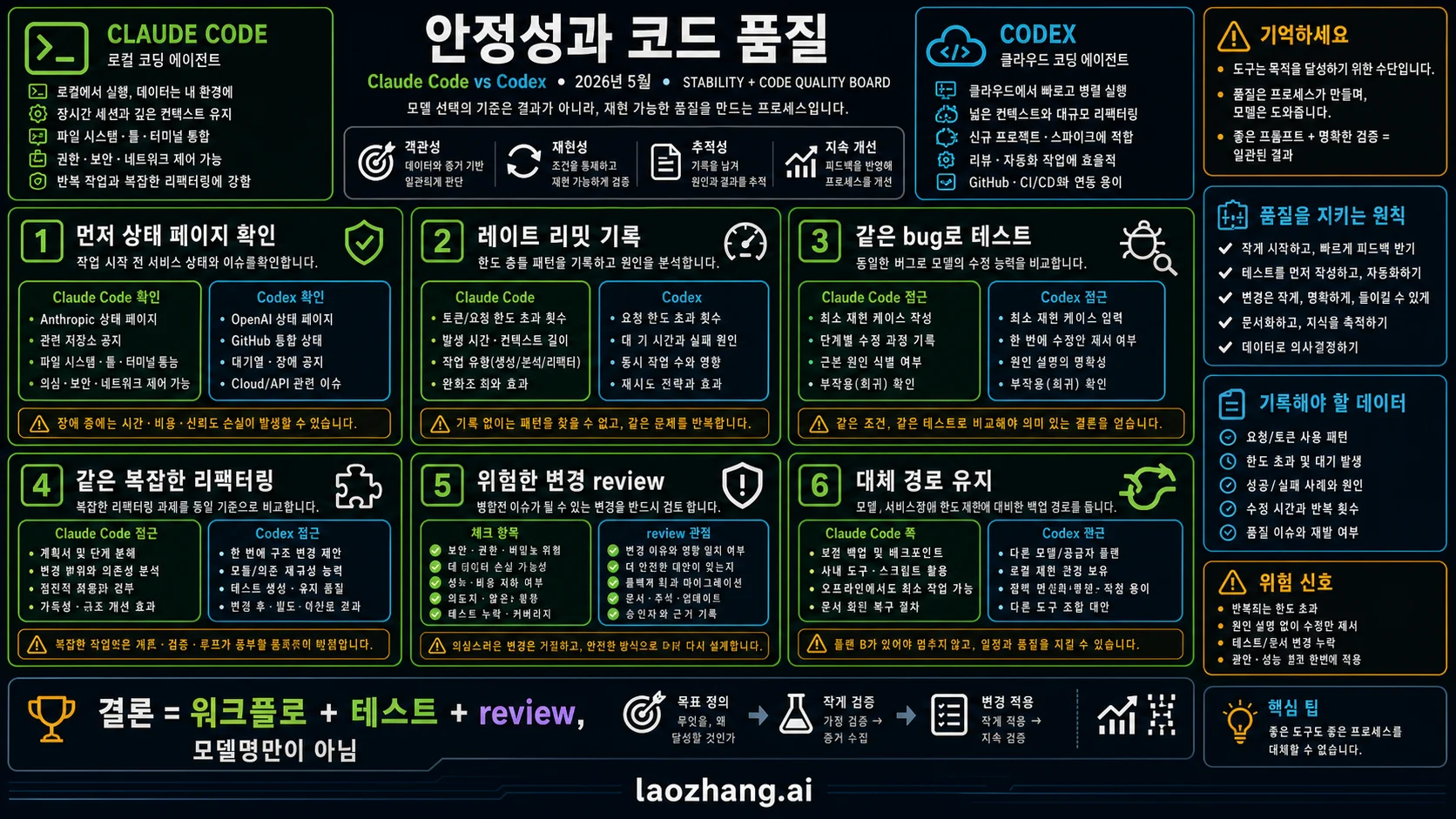
2026년 5월 23일 OpenAI status는 Codex rate limits와 관련된 ongoing incident를 표시했습니다. 동시에 February-May 2026 창에서 Codex uptime은 99.98%로 표시되었습니다. 이는 모순이 아닙니다. 전체 uptime이 높아도 특정 날짜에 사용자가 가장 많이 쓰는 quota surface가 아플 수 있습니다.
같은 날 Claude status는 5월 23일 incident가 없다고 표시했습니다. 하지만 5월 12일부터 22일까지 Claude.ai, Opus 4.7, Haiku 4.5, Claude Code login, web surface에 여러 resolved incidents가 있었습니다. 안정성 판단은 브랜드 인상이 아니라 작업 위험으로 해야 합니다.
대화형 작업은 끊기면 집중이 깨집니다. 그래서 fallback 모델이나 작은 대체 task가 필요합니다. 비동기 작업은 실패가 시간 낭비로 이어집니다. 그래서 버릴 수 있는 branch와 review checkpoint가 필요합니다.
코드 품질: 모델명이 아니라 작업 루프를 평가하세요
OpenAI는 GPT-5.5가 agentic coding에 강하고, Codex tasks에서 더 적은 token으로 결과를 내며, GPT-5.4보다 coding evals가 좋아졌다고 설명합니다. Codex가 강한 지점은 명확한 task를 맡기고 tool로 확인하며 reviewable diff로 돌려받는 작업입니다.
Anthropic은 Claude Opus 4.7이 advanced software engineering, long-running tasks, instruction following, self-verification에서 개선되었다고 설명합니다. Claude Code에서는 Opus 4.7의 default effort가 xhigh로 올라갔습니다. 이는 어려운 로컬 작업에서 더 오래 생각하고 검증하는 쪽으로 설계가 움직였다는 의미입니다.
두 도구를 고르기 전 같은 네 가지 테스트를 하세요. 기존 테스트가 있는 bug, 로컬 미커밋 상태가 있는 refactor, 명확한 async implementation, 위험한 변경을 거절해야 하는 code review. 더 자신 있게 말하는 도구가 이기는 것이 아닙니다. 더 깨끗한 diff, 적은 재작업, 좋은 테스트, 명확한 불확실성을 남기는 도구가 이깁니다.
권한과 신뢰 경계
Claude Code는 permission vocabulary가 더 세밀합니다. allow, ask, deny rules를 만들고 version control에 넣어 조직에 배포할 수 있습니다. mode에는 'default', 'acceptEdits', 'plan', 'auto', 'dontAsk', 'bypassPermissions'가 있습니다. 'bypassPermissions'는 격리 환경에서만 써야 합니다.
Codex는 경계가 더 간단합니다. Codex cloud는 OpenAI-managed container에서 실행되고, setup phase는 의존성 설치를 위해 network를 쓸 수 있으며, agent phase는 기본적으로 offline입니다. CLI와 IDE는 OS-level sandbox를 사용하고 기본값은 no network, active workspace write입니다. Auto preset은 작업 디렉터리 안에서 읽기, 수정, 명령 실행을 자동화하고, 외부 쓰기나 network는 approval을 요구합니다.
조직이 세밀한 로컬 정책을 원하면 Claude Code가 유리합니다. 더 적은 preset과 명확한 local/cloud 경계를 원하면 Codex가 표준화하기 쉽습니다.
실전 하이브리드
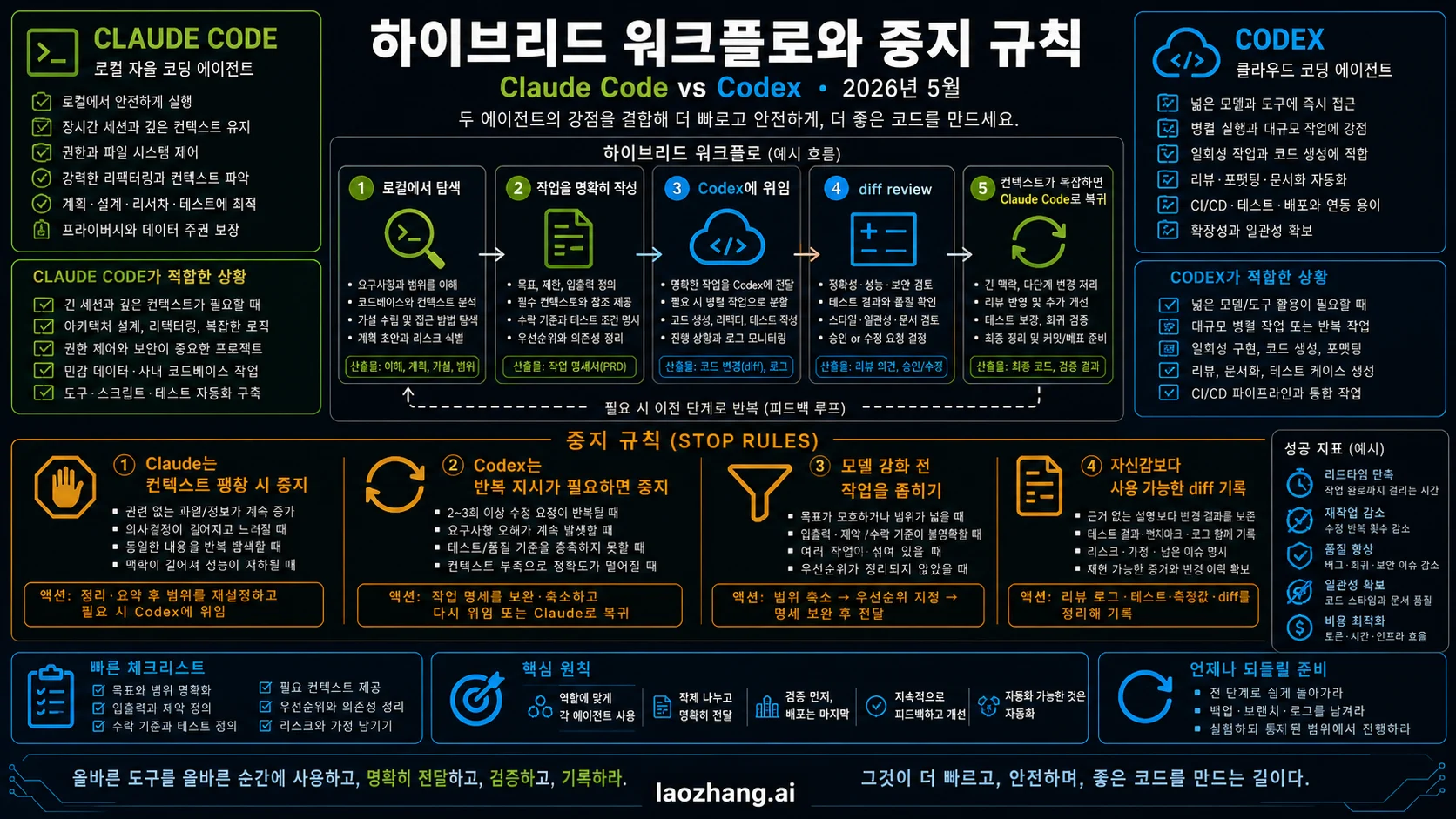
불확실한 첫 단계는 Claude Code에서 시작하세요. repo를 읽고, 실패를 확인하고, 가설을 검증하고, 수정 위치를 정합니다. 작업이 명확한 implementation ticket이 되면 Codex로 넘겨 branch, review, cloud task로 실행합니다.
Claude Code는 context가 너무 커졌거나 같은 논리를 반복하거나 작업이 이미 깨끗한 ticket이 되었을 때 멈추세요. Codex는 로컬 문맥을 반복해서 놓치거나, 중간 steering이 계속 필요하거나, diff가 review하기 어려울 때 멈추세요.
구매 전 1주 테스트
처음 선택은 하루 체험이 아니라 1주일 기록으로 판단해야 합니다. 첫날에는 위험이 낮은 작업만 넣습니다. Codex에는 범위가 명확한 작은 수정이나 review 작업을 맡기고, Claude Code에는 이미 잘 아는 로컬 저장소를 읽게 합니다. 이때 볼 것은 말투나 자신감이 아닙니다. 실제로 쓸 수 있는 diff가 얼마나 빨리 나오는지, 어느 순간 한도에 닿는지, 컨텍스트가 길어졌을 때 품질이 흔들리는지, review하기 어려운 큰 변경을 만들지는 않는지가 핵심입니다.
둘째 날부터 넷째 날까지는 작업을 세 갈래로 나눕니다. 첫 번째는 위임 가능한 작업입니다. 테스트 추가, 명확한 bug 수정, 설정 이전, review 코멘트 반영처럼 목표와 검증 명령을 쓸 수 있는 일은 Codex가 맞습니다. 실패해도 branch를 버리면 되기 때문입니다. 두 번째는 방향을 보면서 진행해야 하는 작업입니다. 여러 미커밋 파일을 읽고, 과거 설계 부채를 추적하고, 실패 원인을 함께 좁히는 일은 Claude Code가 더 자연스럽습니다. 세 번째는 아직 사람이 문제를 정의하지 못한 작업입니다. 이런 일은 어떤 agent에도 바로 던지지 말고 목표, 실패 조건, 실행 명령, 수정 금지 범위를 먼저 써야 합니다.
다섯째 날부터는 가격이 아니라 쓸 수 있는 결과의 비용을 봅니다. 20달러 플랜도 매주 반복 review를 크게 줄여 준다면 충분히 값어치가 있습니다. 반대로 100달러 플랜도 다시 써야 할 diff만 늘린다면 비쌉니다. 기록할 항목은 네 가지입니다. 실제로 사용한 diff 수, 완전히 다시 작성한 수, 한도나 대기 때문에 멈춘 수, agent 출력 때문에 추가 조사한 수입니다. 이 기록이 커뮤니티의 승패 논쟁보다 현재 팀에 더 가까운 답을 줍니다.
업그레이드 전에 물어야 할 질문은 하나입니다. 부족한 것이 Claude Code의 긴 로컬 세션 공간인지, Codex의 위임과 review 공간인지입니다. 로컬 탐색이 자주 끊기고 권한 규칙을 세밀하게 다뤄야 한다면 Claude Max를 먼저 봅니다. 명확한 backlog와 review가 쌓여 있고 병렬로 넘길 일이 많다면 Codex Pro를 먼저 봅니다. 둘 중 하나를 고른 뒤에도 고정하지 말고, 작업 형태가 바뀌면 예산 배분도 바꿔야 합니다.
팀 적용 메모
팀에서는 도구 이름보다 작업 라벨을 먼저 정해야 합니다. local-investigation은 Claude Code로 보냅니다. 로컬 테스트, 권한 범위, 중지 조건을 사람이 보면서 진행해야 하기 때문입니다. delegated-implementation은 Codex로 보냅니다. 목표 파일, 검증 명령, 수정 금지 디렉터리, 기대하는 diff 크기를 작업 카드에 적을 수 있기 때문입니다. review-only는 Codex review나 Claude Code의 보조 설명을 사용할 수 있지만, merge 판단은 사람이 가져야 합니다. blocked-human-decision은 agent에게 맡기지 않습니다. 아직 문제 소유자와 판단 기준이 정해지지 않았기 때문입니다.
안정성도 막연하게 기록하지 않습니다. “불안정했다”가 아니라 로그인 실패, rate limit, cloud task 실패, 로컬 권한 차단, 출력 품질 저하, review 지연, 모델 전환 뒤 변화로 나눠 적습니다. 날짜, 플랜, 모델, 작업 종류, 영향 범위를 함께 남기면 몇 주 뒤에는 하나의 승자를 고르는 대신 어떤 작업을 어느 도구로 보내야 하는지 보입니다.
이미 두 도구를 모두 쓰고 있다면 같은 작업을 두 번 돌린 뒤 더 그럴듯한 결과를 고르는 방식도 피해야 합니다. 먼저 주 경로와 검증 경로를 나눕니다. 보안이나 권한이 중요한 변경은 Claude Code에서 로컬 조사를 하고 Codex로 독립 review를 합니다. 의존성 업그레이드처럼 기계적인 변경은 Codex가 branch를 만들고, 실패한 테스트의 원인 설명은 Claude Code에 맡깁니다. 비교 대상은 취향이 아니라 하나의 검증 질문이어야 합니다.
이 원칙이 있어야 비용과 품질을 같은 기준으로 다시 볼 수 있습니다.
이 규칙은 issue 템플릿에도 넣을 수 있습니다. 주 경로, 검증 경로, 검증할 질문, 멈출 시간을 먼저 적으면 두 agent가 같은 구현을 경쟁하는 대신 서로 다른 책임을 갖게 됩니다. 팀은 결과를 더 쉽게 review하고 다음 작업에 같은 기준을 다시 적용할 수 있습니다.
검증 경로가 구현 문제가 아니라 작업 정의의 모호함을 발견했다면, 다음 단계는 모델 업그레이드가 아니라 사람이 조건을 다시 나누는 것입니다.
이 기록이 있어야 다음 선택도 같은 기준으로 다시 검토할 수 있습니다.
자주 묻는 질문
Claude Code는 AGENTS.md를 직접 읽나요?
주요 지침 파일로는 아닙니다. Claude Code는 CLAUDE.md를 읽습니다. Codex용 AGENTS.md가 이미 있다면 CLAUDE.md에서 @AGENTS.md를 import해 공통 규칙을 한 곳에 모으세요.
Codex transcript 전체를 Claude Code에 붙여야 하나요?
아닙니다. 목표, 파일, 명령, 실패, 결정, 반복하지 말 것, 다음 행동을 handoff packet으로 전달하세요. 나머지 컨텍스트는 repo, diff, 테스트, task packet에 있어야 합니다.
월 20달러에서는 무엇을 먼저 써야 하나요?
넓게 실험하려면 Codex Plus가 더 좋은 시작입니다. 로컬 긴 작업이 대부분이면 Claude Pro와 Claude Code가 더 잘 맞습니다.
Claude Code는 아직 limit에 걸리나요?
그렇습니다. 5월의 증가는 큰 변화지만 context, model, effort가 여전히 사용량을 좌우합니다.
코드 품질은 누가 더 좋나요?
위임하고 review하는 작업은 Codex, 로컬에서 깊게 조정하는 작업은 Claude Code가 유리합니다. 품질은 모델뿐 아니라 테스트와 review, context hygiene으로 결정됩니다.
누가 더 안정적인가요?
중요한 작업 전에는 status를 확인해야 합니다. OpenAI는 5월 23일 Codex rate-limit incident가 있었고, Claude는 그날 incident가 없었지만 직전 기간에 여러 resolved incidents가 있었습니다.
팀은 하나만 표준화해야 하나요?
대부분은 아닙니다. 불확실하고 로컬인 작업은 Claude Code, 명확하고 reviewable한 작업은 Codex라는 routing rule이 더 실용적입니다.