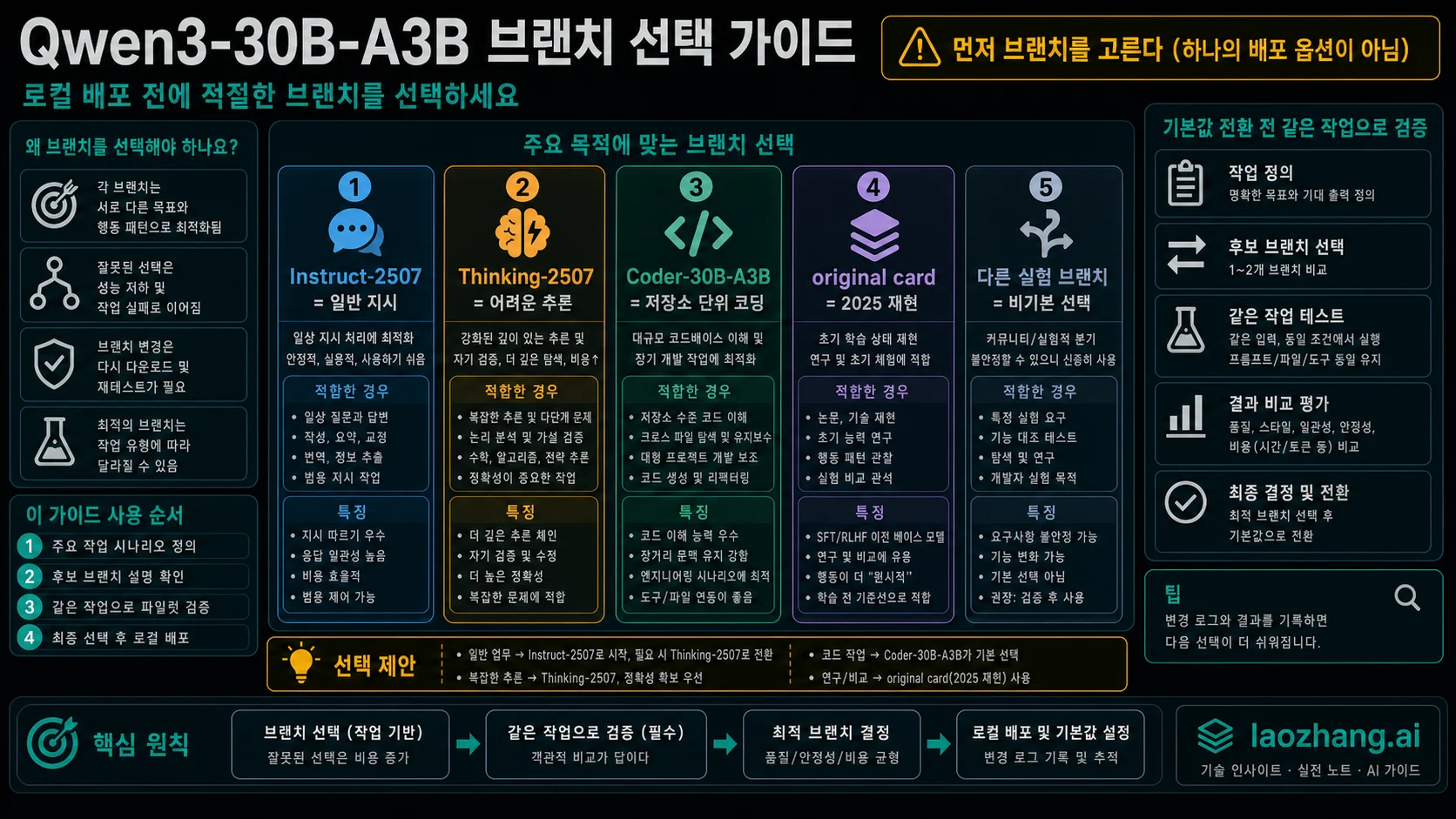
2026년 5월 22일 기준으로 Qwen3-30B-A3B를 하나의 로컬 배포 선택지처럼 다루면 판단이 흐려집니다. 먼저 브랜치를 고르세요. 일반 instruction, summary, chat, 가벼운 agent prompt라면 Qwen/Qwen3-30B-A3B-Instruct-2507을 먼저 봅니다. 어려운 reasoning이라면 Qwen/Qwen3-30B-A3B-Thinking-2507입니다. 저장소 단위 coding과 tool loop라면 Qwen/Qwen3-Coder-30B-A3B-Instruct를 먼저 테스트합니다. 2025년 4월의 hybrid model을 재현해야 할 때만 original Qwen/Qwen3-30B-A3B card가 첫 선택입니다.
A3B는 sparse MoE에서 활성화되는 parameter slice를 말합니다. 하지만 그것만으로 어떤 runtime tag를 써야 하는지, context를 얼마나 열 수 있는지, VRAM이 얼마나 필요한지, 기본값을 바꿔도 되는지는 알 수 없습니다. 실제 배포 판단은 branch, quantization, context budget, KV cache, inference framework, batch, concurrency, task type이 함께 결정합니다.
| 작업 | 먼저 테스트할 브랜치 | 기본값 전환 전 확인 |
|---|---|---|
| 일상 로컬 지시, 요약, chat, 일반 agent prompt | Qwen/Qwen3-30B-A3B-Instruct-2507 | non-thinking branch이므로 <think> trace를 기대하지 않습니다. |
| 다단계 추론, 계획, 긴 검토, 복잡한 분석 | Qwen/Qwen3-30B-A3B-Thinking-2507 | latency, verbosity, reviewer time, 실제 정답률을 봅니다. |
| repository 작업, tool loop, 긴 code context | Qwen/Qwen3-Coder-30B-A3B-Instruct | Coder branch로 측정하고 original card의 별칭으로 쓰지 않습니다. |
| 2025년 4월 재현, old eval, hybrid behavior 확인 | Qwen/Qwen3-30B-A3B | original owner card와 32K native context boundary를 씁니다. |
| 더 새로운 Qwen local/coding route 탐색 | Qwen3.6-35B-A3B를 별도로 평가 | Qwen3.6은 successor boundary이지 같은 model row가 아닙니다. |
중지 규칙은 단순합니다. 같은 prompt, 같은 files, 같은 tools, 같은 context budget, 같은 tests, 같은 latency budget, 같은 retry policy, 같은 reviewer rubric에서 candidate branch가 current default에 밀리지 않을 때까지 기본값을 바꾸지 마세요.
빠른 선택
Instruct-2507은 일반 로컬 assistant 후보입니다. 요약, 분류, 초안 작성, 문서 정리, 짧은 로그 설명, 평범한 agent task에서는 긴 reasoning trace보다 안정적인 format, 낮은 latency, 낮은 review cost가 중요합니다. Hugging Face branch card는 이 branch를 non-thinking으로 설명하고 262,144-token native context를 기록합니다.
Thinking-2507은 hard reasoning을 위해 따로 테스트해야 합니다. 다중 제약 planning, 긴 문서 종합, 복잡한 troubleshooting, 반례 검토처럼 reasoning behavior가 오류를 줄이는 작업에서 의미가 있습니다. 반대로 출력만 길어지고 reviewer time이 늘어난다면 routine default에는 맞지 않습니다.
Coder-30B-A3B는 code task의 첫 테스트입니다. Qwen3-Coder 자료는 coding and tool use를 중심으로 하므로 repo search, cross-file edits, test generation, refactor locality, tool-call discipline을 확인할 때 가장 먼저 둘 branch입니다. branch name은 품질 보장이 아니므로 실제 repository tests가 필요합니다.
Original Qwen/Qwen3-30B-A3B는 baseline으로 남겨야 합니다. April 2025 Qwen3 coverage, old quantized build, hybrid thinking/non-thinking behavior, previous eval parity를 재현할 때 올바른 owner card입니다. 새 default 후보로 쓰려면 updated branch보다 먼저 선택해야 하는 이유가 필요합니다.
A3B가 의미하는 것
Qwen의 Qwen3 announcement와 original Hugging Face card는 Qwen3-30B-A3B를 sparse mixture-of-experts model로 설명합니다. Owner card는 30.5B total parameters, 3.3B activated parameters, 48 layers, 128 experts, 8 active experts를 기록합니다. 그래서 A3B label은 로컬 실험에서 매력적으로 보입니다. 전체 모델 크기는 크지만 token마다 활성화되는 expert slice는 작기 때문입니다.
하지만 activated parameter label은 memory budget의 답이 아닙니다. 실제 memory pressure에는 loaded weights, quantization, context length, KV cache, inference framework, batch size, concurrency가 들어갑니다. 짧은 4-bit chat, 긴 context를 쓰는 code agent, 높은 concurrency service는 같은 model name을 쓰더라도 완전히 다른 배포입니다.
Context boundary도 branch마다 다릅니다. Original card는 32,768 native context와 131,072 with YaRN을 기록합니다. Instruct-2507과 Thinking-2507은 262,144 native context입니다. Coder card는 262,144 native context와 1M with YaRN boundary를 갖습니다. 이 행들을 하나로 합치면 speed, quality, memory 비교가 잘못됩니다.

브랜치 선택 기준
처음 봐야 할 것은 실패 비용입니다. 일반 instruction task는 약간의 수정으로 회복됩니다. Reasoning task는 잘못된 결론이 의사결정을 망칠 수 있습니다. Code task는 repository에 hidden defect를 남기거나 필요 없는 diff를 만들거나 tests를 깨뜨릴 수 있습니다. 그래서 하나의 branch가 모든 상황에서 첫 선택이 될 수 없습니다.
Instruct-2507은 default assistant 후보로 테스트합니다. 짧은 answer, format stability, instruction following, boundary handling, unnecessary verbosity를 봅니다. visible reasoning을 기대하는 eval prompt라면 branch selection 자체가 맞지 않습니다.
Thinking-2507은 무거운 추론 branch로 테스트합니다. 좋은 평가 작업은 긴 중간 추론이 최종 error를 줄이는 작업입니다. Multi-constraint planning, long synthesis, complex debug, adversarial review가 해당합니다. 품질이 올라가도 review time이 두 배가 되면 routine default로는 손해일 수 있습니다.
Coder-30B-A3B는 repository work에 씁니다. 올바른 file을 찾는지, 기존 style을 지키는지, edit scope가 작은지, 필요한 test command를 고르는지, tool failure에서 회복하는지 확인합니다. code snippet을 잘 쓰는 것과 repo-scale loop를 맡길 수 있는 것은 다릅니다.
Qwen3.6은 후속 비교로 다룹니다. Qwen3.6-35B-A3B를 Kimi나 GLM과 비교하려는 상황이라면 Qwen3.6, Kimi K2.6, GLM-5.1 route guide를 보세요. Qwen3-30B-A3B의 정확한 branch decision을 cross-model ranking으로 늘리는 것은 좋은 판단이 아닙니다.
Runtime route는 사실 소유자가 아니다
Ollama, LM Studio, llama.cpp, vLLM, SGLang은 model choice를 실행 가능한 local setup으로 바꾸는 데 중요합니다. 그러나 runtime tag는 upstream model identity가 아닙니다. Quantization, prompt template, default context, branch mapping, server parameter를 포함할 수 있습니다.
Ollama의 qwen3:30b-a3b는 빠르게 시작하는 entrance로 유용합니다. Local speed, memory pressure, basic prompt behavior를 볼 수 있습니다. 하지만 parameter count, expert count, context promise, branch behavior의 source of record는 아닙니다. 그 사실들은 Qwen과 Hugging Face owner pages로 돌아가야 합니다.
Community quantized package도 같습니다. 어떤 GGUF나 AWQ build가 특정 GPU에 딱 맞을 수 있습니다. 다만 quantization, template, context, server가 바뀌는 순간 평가 대상은 model card 하나가 아니라 deployment stack입니다. Model identity와 stack behavior를 나누면 실패 원인을 더 쉽게 찾을 수 있습니다.

Hardware와 context 주의점
정직한 hardware answer는 반드시 조건부입니다. Quantization을 낮추면 memory는 줄 수 있지만 quality나 compatibility가 변할 수 있습니다. Context를 늘리면 KV cache가 커집니다. Batch와 concurrency가 올라가면 peak memory가 빡빡해집니다. Framework마다 offload, attention, paging behavior도 다릅니다.
짧은 chat에서는 load time, first token, token speed, answer stability를 먼저 봅니다. Code agent에서는 repository files, tool outputs, retry, long context를 넣어야 합니다. Thinking branch에서는 output length, review time, error reduction을 기록해야 합니다. 작은 speed test 하나로 모든 default를 결정하지 마세요.
안전한 pilot은 작게 시작합니다. 실제로 쓰는 짧은 task에서 branch와 runtime을 확인한 뒤 context를 단계적으로 늘립니다. Memory pressure, crash, paging, quality drop, recovery behavior를 기록합니다. 짧은 task가 안정되기 전 최대 context로 뛰어가면 판단이 더 어려워집니다.
같은 작업 pilot
모델 비교는 같은 task에서 돌릴 때만 판단 자료가 됩니다. 다섯 개에서 열 개 정도의 실제 task를 고르세요. Log explanation, summary, multi-step reasoning, small bug fix, cross-file refactor, test writing, long-context reading, ambiguous requirement를 포함하면 실패 유형이 드러납니다.

| 테스트 항목 | 동일하게 유지 | 기록할 내용 |
|---|---|---|
| Prompt | user task, system rules, output format | 추가 수정 없이 task를 해결하는지 |
| Context | files, logs, snippets, token budget | reference miss, context drift, lost constraint |
| Tools | commands, permissions, retry policy | tool-call accuracy, unnecessary actions |
| Tests | unit tests, eval set, manual checks | accepted diff, failed checks, hidden defects |
| Operations | hardware, runtime, quantization, batch | latency, memory pressure, crash, recovery |
Candidate branch가 task completion, reviewer edits, retry count, hidden defects, operating cost에서 current default와 같거나 더 나을 때만 default로 올립니다. 빠르지만 수작업 수정이 늘어나는 model은 빠른 것이 아닙니다. 똑똑하지만 memory budget에 들어가지 않는 model도 더 나은 default가 아닙니다.
유지보수 때 볼 source
Qwen의 Qwen3 announcement는 family framing, open-weight MoE release, model table을 확인하는 source입니다. Qwen/Qwen3-30B-A3B Hugging Face card는 original model facts, parameters, experts, activated experts, hybrid behavior, original context boundary를 확인하는 source입니다. Instruct-2507과 Thinking-2507 cards는 branch behavior와 262K native context를 확인하는 source입니다.
Qwen3-Coder-30B-A3B card와 Qwen3-Coder blog는 coding-agent branch framing을 확인하는 source입니다. Ollama와 다른 runtime pages는 install convenience를 확인하는 source입니다. Qwen3.6 material은 successor boundary를 확인하는 source입니다. 소유자를 나누면 다음 branch update 때 필요한 행만 수정하면 됩니다.
자주 묻는 질문
Qwen3-30B-A3B는 아직 로컬에서 쓸 가치가 있나?
있습니다. 다만 branch가 작업에 맞아야 합니다. Instruct-2507은 일반 local instruction, Thinking-2507은 heavy reasoning, Coder-30B-A3B는 coding loop에 적합합니다. Original branch는 주로 April 2025 reproduction과 old comparison용입니다.
A3B는 3B model이라는 뜻인가?
아닙니다. A3B는 sparse MoE에서 활성화되는 parameter slice를 말합니다. Original owner card는 30.5B total parameters와 3.3B activated parameters를 기록합니다. Deployment memory는 full stack에 의존합니다.
Instruct-2507과 Thinking-2507은 어떻게 고르나?
빠르고 clean한 answer가 필요하면 Instruct-2507입니다. 문제가 충분히 어렵고 추가 reasoning이 error를 줄인다면 Thinking-2507을 테스트합니다.
Qwen3-Coder-30B-A3B는 같은 model인가?
관련 Coder branch이지만 original Qwen/Qwen3-30B-A3B card의 동의어가 아닙니다. Repository-scale coding과 tool use에서는 먼저 테스트할 가치가 있습니다.
Ollama만으로 branch를 판단할 수 있나?
Ollama는 실용적인 local route를 제공하지만 upstream model ID, quantization, context setting, prompt template은 별도로 확인해야 합니다.
VRAM은 얼마나 필요할까?
모든 설정에 공통되는 숫자는 없습니다. Quantization, context length, KV cache, framework overhead, batch, concurrency가 memory pressure를 바꿉니다.
언제 Qwen3.6을 봐야 하나?
더 새로운 Qwen local/coding route를 검토할 때입니다. Qwen3.6-35B-A3B는 successor comparison이지 Qwen3-30B-A3B의 조용한 replacement가 아닙니다.