
Gemma 4는 하나의 모델이 아닙니다. 하나만 기억해야 한다면 이 구분을 기억하면 됩니다. E2B와 E4B는 단말 쪽이고, 26B A4B와 31B는 워크스테이션 쪽입니다. 2026년 4월 3일 기준으로 이 구분은 어떤 benchmark 스크린샷보다 중요합니다. 출발점이 휴대폰인지, 노트북인지, 워크스테이션인지, 아니면 온라인 시험판인지가 이 단계에서 갈리기 때문입니다.
이 점이 Gemma 4를 흔한 “신규 모델 발표”와 다르게 보이게 만듭니다. 단순히 Google이 다음 open release를 냈다는 이야기가 아닙니다. Apache 2.0으로 공개된 4개 모델 패밀리이며, 작은 가지는 효율, 로컬 실행, 모바일에 초점을 맞추고 큰 가지는 긴 컨텍스트와 더 무거운 로컬 추론에 초점을 맞춥니다. 공개 자료만 읽으면 제품 표면이 넓어 보여 복잡하게 느껴질 수 있지만, 실제로 유용한 질문은 하나입니다. 지금 필요한 것이 단말용 모델인가, 아니면 워크스테이션용 모델인가.
이 글의 핵심 사실은 2026년 4월 3일 기준으로 Google의 Gemma release log, launch blog, Gemma 4 model card, Gemini Developer API pricing page, Android Developers Blog를 기준으로 확인했습니다.
먼저 결정해야 할 것: 어디서 시작할까
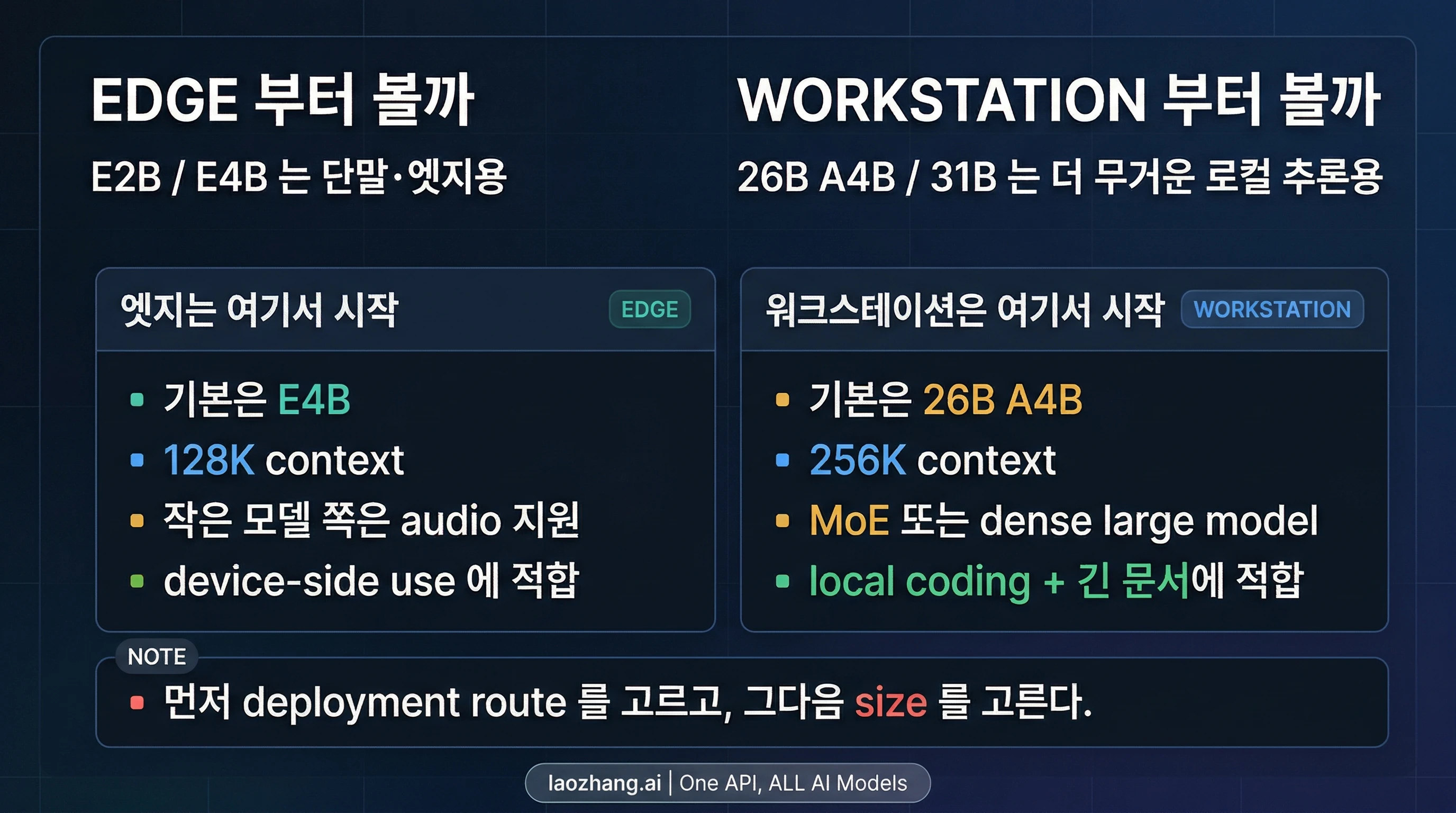
| 실제 목표 | 먼저 볼 모델 | 이유 | 주요 주의점 |
|---|---|---|---|
| 오프라인, 저지연, 단말, 모바일, 더 작은 로컬 디바이스 | E4B | 가장 무난한 단말 기본값. E2B보다 여유가 있으면서도 efficient local use에 맞음 | 큰 가지보다 context ceiling이 낮고 가장 무거운 workstation reasoning에는 부족할 수 있음 |
| Gemma 4에서 가장 가벼운 진입점 | E2B | RAM, battery, latency가 핵심 병목일 때 가장 합리적 | E4B보다 ceiling이 낮음 |
| 워크스테이션급 로컬 추론을 현실적으로 시작하고 싶다 | 26B A4B | 3.8B active parameters의 MoE 구조라 큰 가지의 실전 default가 되기 쉬움 | 단순 dense 대형 모델보다 제품 해석이 조금 더 복잡함 |
| dense 대형 모델을 의도적으로 고르고 싶다 | 31B | raw quality나 fine-tuning 기반을 더 중시할 때 적합 | 26B A4B보다 하드웨어 부담이 큼 |
| 자가 운영 전에 큰 가지를 먼저 체험하고 싶다 | AI Studio의 26B A4B / 31B | 가장 빠른 공식 체험 경로 | 현재 pricing page는 일반 paid Gemma SKU처럼 보여주지 않음 |
| on-device audio / speech 이해 | E4B 또는 E2B | native audio는 작은 가지에 있음 | 큰 가지는 같은 audio 포지션이 아님 |
가장 실용적인 기본 추천은 단순합니다. 단말 하드웨어에서 출발하면 E4B, 워크스테이션에서 출발하면 26B A4B를 먼저 보세요. 아주 작은 footprint가 정말 필요하거나, dense 31B가 목적일 때만 이 기본 경로에서 벗어나는 편이 좋습니다.
Gemma 4는 무엇인가
Gemma 4는 Google의 최신 오픈 모델 패밀리입니다. 공식 release log에는 2026년 3월 31일, 공개 launch blog에는 2026년 4월 2일로 기록돼 있습니다. Google은 Gemma 4를 Gemini 3와 이어지는 open-model 계열로 배치하지만, 그렇다고 해서 Gemma 4가 “더 싼 Gemini”라는 뜻은 아닙니다. 진짜 중요한 차이는 deployment boundary입니다. Gemma는 직접 실행하고, 적응시키고, 배포할 수 있는 open-weight family이고, Gemini는 Google이 관리하는 model line입니다.
이 차이는 독자가 하는 결정의 종류 자체를 바꿉니다. Gemini를 고를 때는 대개 API 계약과 가격을 판단합니다. Gemma 4를 고를 때는 먼저 어디에서 돌릴지를 판단합니다. 로컬 단말용 모델을 돌릴지, workstation급 로컬 모델을 돌릴지, 아니면 open model을 먼저 평가하기 위한 온라인 시험판을 사용할지부터 정해야 합니다.
Google은 이번에 product boundary도 꽤 명확하게 설명합니다. official model card에 따르면 Gemma 4는 text와 image input을 받는 multimodal open model family이며, 작은 모델은 native audio input도 지원하고 출력은 text입니다. 이 부분은 특히 오해가 생기기 쉬우므로 분명히 말할 필요가 있습니다. Gemma 4는 이미지 생성 모델도, 비디오 생성 모델도 아닙니다. OCR에 가까운 이해, coding, reasoning, 텍스트 중심 작업을 위한 오픈 멀티모달 패밀리입니다.
진짜 갈림길: edge 모델 vs workstation 모델

Gemma 4를 이해할 때 가장 도움이 되는 방법은 “추상적으로 뭐가 최고인가”를 묻는 것이 아닙니다. 각 가지가 어떤 deployment problem을 푸는지 보는 것입니다.
edge 가지는 E2B와 E4B입니다. official model card 기준으로 두 모델 모두 128K context, text와 image input, 그리고 native audio input을 지원합니다. Google의 Android announcement도 이 가지가 AICore / 차세대 Gemini Nano on-device path와 연결된다고 분명히 보여줍니다. 즉 이것은 단지 “작은 모델”이 아니라, latency, battery, local execution, 제한된 하드웨어가 중요한 환경을 위해 존재하는 가지입니다.
이 edge 가지 안에서는 E4B가 대부분의 사용자에게 가장 자연스러운 default입니다. E2B보다 여유가 있으면서도 Google이 on-device와 AI Edge 방향으로 밀고 있는 부분에 속해 있기 때문입니다. E2B는 efficiency-first 선택입니다. footprint를 최우선으로 둬야 할 때에만 적극적으로 선택하는 편이 맞습니다.
workstation 가지는 26B A4B와 31B입니다. 두 모델 모두 256K context로 올라가며, 긴 문서, 더 넓은 코드 컨텍스트, 더 무거운 로컬 추론 흐름에 더 잘 맞습니다. 여기서 특히 중요한 모델은 26B A4B입니다. official model card는 이를 total 25.2B, inference 시 3.8B active parameters의 Mixture-of-Experts 모델로 설명합니다. 실무적으로는 이것이 workstation 쪽의 첫 default 후보라는 뜻입니다. 더 긴 context와 더 강한 reasoning tier를 얻으면서도, 가장 무거운 dense 모델을 시작점으로 강제하지 않습니다.
31B는 dense large model입니다. raw dense-model quality나 fine-tuning 기반을 더 중요하게 보는 경우에는 맞는 선택입니다. 하지만 중요한 점은 숫자가 가장 크다고 해서 자동 default로 받아들이지 않는 것입니다. 많은 local developer에게 첫 번째로 시험할 모델은 31B보다 26B A4B일 가능성이 큽니다.
Gemma 3와 비교해 무엇이 달라졌나
Gemma 4의 업그레이드를 단순히 “benchmark가 올랐다”라고만 읽는 것은 얕습니다. 더 중요한 변화는 Google이 이 family를 훨씬 쓰기 쉬운 형태로 정리했다는 점입니다.
먼저 큰 가지는 256K context까지 올라갔고, 작은 가지는 **128K**를 유지합니다. 이 차이는 Gemma 4를 긴 문서와 repository-scale 로컬 작업에서 훨씬 진지한 후보로 만듭니다. 다음으로 launch materials와 model card는 native system-role support와 native function-calling posture를 분명하게 강조합니다. agentic / structured workflow에서는 이 차이가 큽니다. 마지막으로 family split 자체가 더 읽기 쉬워졌습니다. edge 모델은 더 이상 덤처럼 붙어 있는 작은 버전이 아니고, workstation 쪽도 하나의 애매한 큰 모델로 뭉개지지 않습니다.
능력 상승도 실제입니다. official model card에서 31B는 Gemma 3 27B보다 AIME 계열 수학과 LiveCodeBench 계열 coding에서 눈에 띄는 향상을 보여줍니다. 여기서 중요한 것은 benchmark 숭배가 아니라, 이번 launch가 cosmetic이 아니라는 점입니다. Gemma 4 아래에는 실제 capability gain과 실제 family design 개선이 함께 있습니다.
또 하나의 핵심 변화는 어디에 써야 하는지가 훨씬 또렷해졌다는 점입니다. Google은 AI Studio를 큰 가지의 온라인 시험장으로, AI Edge / Android를 작은 가지의 on-device 경로로, 그리고 Hugging Face, Ollama, MLX, llama.cpp, vLLM을 자가 운영 경로로 배치합니다. 결국 Gemma 4의 가치 중 하나는 “더 똑똑해졌다”보다 어디에 써야 하는 패밀리인지가 전보다 훨씬 선명해졌다는 점입니다.
지금 어디서 Gemma 4를 돌려야 하나

어디서 Gemma 4를 돌려야 하는지는 선택한 가지에 따라 달라집니다.
큰 가지를 가장 쉽게 시험하고 싶다면 Google의 launch blog는 31B와 26B A4B를 AI Studio로 안내합니다. 로컬 스택을 먼저 만들지 않고 workstation 가지를 체감하는 가장 빠른 공식 경로입니다. 다만 한 가지 경계는 분명히 해야 합니다. 현재 Gemini Developer API pricing page는 Gemma 4를 free only로 보여주며, 일반 paid managed model line item처럼 다루지 않습니다. 즉 “지금 바로 써볼 수 있다”는 말은 맞지만, “일반적인 유료 Gemini API SKU처럼 운영할 수 있다”는 현재 공개 pricing과 어긋납니다.
반대로 edge 가지를 보고 있다면 공식 시그널은 다른 방향입니다. Android Developers Blog는 Gemma 4를 AICore Developer Preview와 향후 Gemini Nano 4 기기 흐름에 연결하고, launch materials는 E4B / E2B를 AI Edge 흐름에 배치합니다. 작은 가지는 장난감 릴리스가 아니라 실제 on-device 경로로 읽어야 합니다.
self-hosted local control이 필요하다면 Google의 launch materials가 강조하는 open-model ecosystem, 즉 Hugging Face, Kaggle, Ollama, Transformers, MLX, llama.cpp, vLLM이 본선입니다. 워크스테이션에서 Gemma 4를 돌리고, 로컬 coding workflow에 넣고, broader local stack의 일부로 삼고 싶다면 이 길을 가야 합니다. 다음 단계가 local provider 설정이라면, 이어서 볼 만한 자료는 영어版 OpenClaw LLM setup guide입니다.
더 큰 production-scale deployment를 생각한다면 Google은 이 이야기를 Google Cloud 쪽으로 끌고 갑니다. 현재 pricing page로는 Gemma 4가 일반적인 paid hosted Gemini line item처럼 보이지 않습니다. 이것 역시 product boundary로 읽어야 합니다.
시나리오별로 가장 실용적인 선택
일반적인 edge 기본값이 필요하다면 **E4B**부터 보세요. Google이 edge 방향에 두고 있는 제품 포지션과 로컬 multimodal use에서 필요한 여유를 가장 잘 균형 잡는 모델이기 때문입니다.
진짜 병목이 memory, battery, latency라면 **E2B**에서 시작하는 편이 맞습니다. 패밀리 전체의 default는 아니지만, footprint가 가장 중요할 때는 가장 정직한 답입니다.
workstation급 로컬 coding / reasoning 모델이 필요하다면 **26B A4B**가 핵심 추천입니다. MoE 설계 덕분에 큰 가지에 들어가기 위해 가장 무거운 dense 모델을 바로 선택할 필요가 없습니다. 로컬에서 coding, reasoning, 긴 context 작업을 하려는 개발자에게 가장 현실적인 첫 평가 대상입니다.
raw dense-model quality나 fine-tuning headroom이 더 중요하다면 **31B**로 이동합니다. 하드웨어 예산에 여유가 있고 dense한 대형 모델을 의도적으로 선택할 때에만 이것이 맞는 시작점이 됩니다.
on-device audio understanding이 필요하다면 **E2B / E4B**에 머물러야 합니다. audio support의 product boundary는 model card가 충분히 분명하게 제시하고 있고, 단순한 parameter count보다 중요합니다.
아직 Gemma 4가 정말 필요한지 판단하는 단계라면 로컬 구축부터 시작하지 마세요. 큰 가지는 AI Studio, 작은 가지는 Android / AI Edge preview에서 먼저 보는 편이 훨씬 낫습니다. 가지를 고르기도 전에 local deployment를 먼저 만드는 것이 가장 비용이 큰 첫 실수입니다.
Gemma 4가 맞지 않는 경우
Gemma 4는 open weights, Apache 2.0, 긴 context, 강한 reasoning posture, 분명한 edge ambition 같은 매력적인 요소가 한꺼번에 붙어 있어 과대평가되기 쉽습니다. 그래도 모든 사용자에게 최적의 답이 되는 것은 아닙니다.
만약 실제로 필요한 것이 안정적인 managed API와 명확한 paid pricing이라면, Gemma 4는 지금 시점에서 managed Gemini route만큼 직선적이지 않습니다. 오히려 현재 pricing page의 가치는 그 경계를 솔직하게 드러낸다는 데 있습니다. 이런 경우에는 영어版 Gemini API pricing guide를 보는 편이 더 맞습니다.
또한 원하는 것이 최상위 closed frontier model stack이고, open weights나 self-hosting의 운영 부담을 전혀 원하지 않는다면 Gemma 4는 애초에 찾고 있는 답이 아닐 수 있습니다. Gemma 4의 강점은 openness와 deployability이지, open model과 managed frontier system의 차이를 지우는 데 있지 않습니다.
그리고 이미지 생성이나 비디오 생성이 목적이라면 Gemma 4는 명확하게 다른 제품군입니다. official model card가 보여주듯 Gemma 4는 text와 visual input을 받아 text output을 내는 multimodal open model family이지, 이미지 생성 라인이나 비디오 생성 라인이 아닙니다.
마지막으로 가져가야 할 사고방식
Gemma 4는 “새 브랜드 이름”으로 보기보다 두 갈래의 오픈 패밀리로 보는 편이 정확합니다.
첫 번째는 단말용 라인입니다. E2B와 E4B가 여기에 속하며, local execution, multimodal on-device use, device-level practicality가 중심입니다. 두 번째는 워크스테이션용 라인입니다. 26B A4B와 31B가 여기에 속하며, 긴 context와 더 무거운 로컬 추론이 중심입니다. 이 라인만 먼저 제대로 고르면 Gemma 4는 생각보다 단순해집니다. 반대로 이 단계를 건너뛰면 네 모델이 다시 하나의 흐릿한 덩어리로 보입니다.
그래서 가장 유용한 quick answer도 단순합니다. 단말 쪽을 진지하게 볼 거라면 E4B, 워크스테이션 쪽을 진지하게 볼 거라면 26B A4B입니다. 더 작은 쪽으로 내려가는 것은 효율이 진짜 병목일 때만, 더 무거운 dense 쪽으로 가는 것은 31B의 대가를 알고 있을 때만 하세요.