
첫 단계에서 확인하려는 것이 더 저렴한 코딩 에이전트 실험이고, 터미널 중심의 반복 작업이나 도구 호출이 많은 작업이라면 GPT-5.3-Codex부터 시작하는 편이 합리적이다. 반대로 진짜 비용이 토큰 단가가 아니라 긴 작업 흐름, 큰 저장소 컨텍스트, 혹은 약한 첫 시도가 큰 재작업을 만드는 큰 출력에서 발생한다면 Claude Opus 4.6부터 시험하는 편이 낫다. 이것이 2026년 4월 3일 기준으로 여전히 가장 실용적인 답이다.
다만 표를 보기 전에 한 가지는 먼저 정리해야 한다. GPT-5.3-Codex는 지금도 실제로 쓸 수 있는 OpenAI 모델이지만, 더 이상 현재 Codex 제품 전체를 대표하는 이름은 아니다. OpenAI는 2026년 3월 5일 Codex에 GPT-5.4를 넣었고, 2026년 3월 17일에는 더 큰 모델이 계획과 최종 판단을 맡고 GPT-5.4 mini가 더 좁은 보조 작업을 맡는 구조도 설명했다. 따라서 여기서 비교하는 것은 Claude Opus 4.6과 GPT-5.3-Codex라는 두 모델이지, 현재 Codex 제품 전체가 아니다. 만약 정말 궁금한 것이 제품 선택이라면 OpenAI Codex 2026년 3월 업데이트와 Claude Code vs Codex를 먼저 보는 편이 맞다.
| 병목이 이런 모습이라면 | 먼저 시험할 모델 | 이유 |
|---|---|---|
| 더 저렴한 터미널 중심 코딩 루프 | GPT-5.3-Codex | 공식 API 가격이 낮고, OpenAI 쪽 공개 벤치마크 근거가 더 분명하다 |
| 저장소 규모의 긴 실행 작업 | Claude Opus 4.6 | 1M 컨텍스트, 128k 출력, 그리고 재시도가 비싼 작업에서 더 설득력 있는 모델이다 |
| 같은 시스템 안에 두 단계가 모두 있다 | 둘 다 사용 | GPT-5.3-Codex를 값싼 첫 시험에 두고, 컨텍스트나 재작업 비용이 커질 때 Opus로 올린다 |
근거 메모: 이 글은 OpenAI와 Anthropic의 현재 공식 페이지를 2026년 4월 3일 기준으로 다시 확인해 작성했다. 공개 벤치마크 근거는 대칭적이지 않다. OpenAI는 GPT-5.3-Codex에 대해 더 풍부한 출시 부록을 제공하고, Anthropic은 Opus 4.6에 대해 더 좁지만 여전히 유용한 공개 에이전트 벤치마크를 제공한다. 아래 판단은 완벽하게 대칭인 점수표가 아니라, 무엇부터 시험해야 하는지 판단하는 근거로 읽는 편이 맞다.
먼저 비교 대상을 분명히 하자
이 비교가 유효하려면 비교 대상을 정확히 고정해야 한다. GPT-5.3-Codex는 2026년 2월 5일에 등장했고, OpenAI의 현재 API 문서에서도 여전히 현행 코딩 모델로 소개되며 가격, reasoning effort, 엔드포인트, 40만 토큰 컨텍스트, 12만 8천 토큰 최대 출력이 명시되어 있다. 따라서 이 이름은 지금도 유효하며 Claude Opus 4.6과 직접 비교할 가치가 있다.
바뀐 것은 그 바깥의 제품 설명이다. OpenAI의 현재 모델 페이지는 이미 GPT-5.4를 agentic, coding, 전문 작업의 주력 계열로 두고 있고, 2026년 3월 17일 GPT-5.4 mini 글은 더 큰 모델이 계획과 최종 판단을 맡고 더 작은 모델이 좁은 지원 작업을 처리하는 Codex 구성을 보여준다. 이것은 GPT-5.3-Codex가 사라졌다는 뜻이 아니라, 많은 사용자가 "Codex"라고 말할 때 이미 한 개 모델보다 넓은 질문을 함께 묻고 있다는 뜻이다.
왜 이 차이가 중요한가? 모델 선택과 제품 선택은 답해야 하는 질문이 다르기 때문이다. 모델 비교가 답해야 하는 것은 어떤 모델을 먼저 시험할까이고, 제품 비교가 답해야 하는 것은 어떤 도구와 작업 방식, 어떤 도입 경로를 택할까다. 이 페이지가 모델 수준에 머무는 이유는 질문을 더 날카롭게 만들기 위해서다. 지금 개발 작업에서 어느 모델을 먼저 시험할 것인가.
빠른 비교: 실제로 차이가 나는 지점
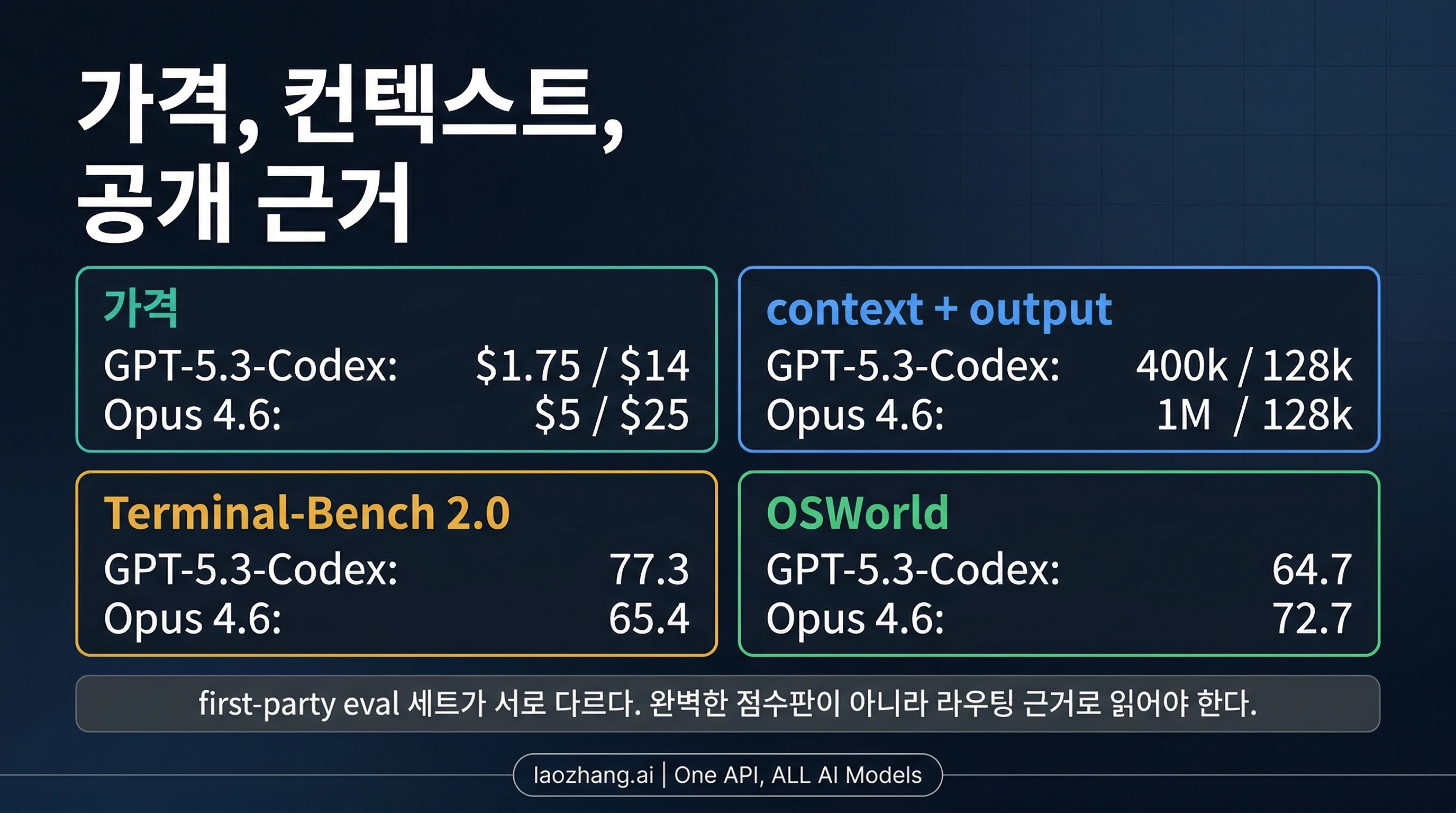
여기서 읽어야 할 것은 "누가 더 많은 항목에서 앞서나"가 아니라 각 항목이 어떤 실패 비용을 가리키는가다. GPT-5.3-Codex는 공격적으로 반복 평가를 돌리기 좋은 가격대의 모델처럼 보인다. Claude Opus 4.6은 더 비싼 실패를 줄여줄 것으로 기대되는 가격대의 모델처럼 보인다.
| 항목 | GPT-5.3-Codex | Claude Opus 4.6 | 실제 해석 |
|---|---|---|---|
| 공식 API 가격 | $1.75 input / $14 output / 1M tokens | $5 input / $25 output / 1M tokens | GPT-5.3-Codex는 반복 평가를 더 많이 돌리기 쉽다 |
| Cached input | $0.175 / 1M tokens | Anthropic은 cache 규칙을 별도 문맥에서 제시 | OpenAI 쪽이 반복 평가를 더 싸게 돌리기 쉽다 |
| Context window | 400k | 1M | Opus는 더 큰 저장소나 긴 명세를 한 번에 넣기 쉽다 |
| 최대 출력 | 128k | 128k | 출력 길이 자체가 가장 큰 차이는 아니다 |
| Public Terminal-Bench 2.0 | 77.3 | 65.4 | OpenAI는 저비용 코딩 에이전트 평가에 대한 공개 근거가 더 강하다 |
| Public OSWorld | 64.7 | 72.7 | Anthropic은 환경이 얽힌 긴 실행 작업에 대한 공개 근거가 더 강하다 |
이 표만 봐도 큰 방향은 보인다. GPT-5.3-Codex는 더 싸게 먼저 시험하기 좋은 모델이다. 특히 질문이 "Opus 가격을 내기 전에 코딩 에이전트를 어디까지 밀 수 있나?"라면 더 그렇다. 반대로 Claude Opus 4.6은 컨텍스트 깊이와 실패 비용이 전체 비용을 좌우할 때 더 설득력 있다. 더 많은 작업 상태를 유지하면서도 출력 여유를 잃지 않기 때문이다.
주의할 점은 이것을 완전히 대칭적인 벤치마크 이야기로 만들지 않는 것이다. OpenAI의 숫자는 2026년 2월 5일 공개 부록에서 왔고 xhigh reasoning effort 조건이다. Anthropic의 공개 근거는 더 좁지만 여전히 유용하다. 현재 공개 문서는 Terminal-Bench 2.0 65.4%, OSWorld 72.7%, 공개 1M 컨텍스트를 함께 제시한다. 먼저 무엇을 시험할지 결정하기에는 충분하지만 어느 한쪽을 만능 승자라고 부르기에는 충분하지 않다.
GPT-5.3-Codex를 먼저 시험해야 하는 경우
결론: 가까운 질문이 "낮은 가격으로 터미널 중심 코딩 루프를 얼마나 밀 수 있는가"라면 GPT-5.3-Codex가 첫 시험 대상으로 더 적합하다.
근거: OpenAI의 현재 모델 페이지는 GPT-5.3-Codex를 $1.75 / $14 per million tokens, $0.175 cached input, 400k context, 128k output, 조절 가능한 reasoning effort와 함께 제공한다. 공개 부록은 **Terminal-Bench 2.0 77.3%**와 **OSWorld-Verified 64.7%**를 보여주며 OpenAI 쪽 공개 코딩 벤치마크 근거를 더 선명하게 만든다.
판단: 코딩 에이전트의 한계를 아직 탐색 중이고 반복 실행, 재시도, 평가 배치가 많이 예상된다면 GPT-5.3-Codex부터 시작하는 편이 맞다.
이 판단은 리더보드보다 비용 구조에 더 가깝다. 반복적인 터미널 작업, 패치 시도, 도구 호출, 자기 수정으로 움직이는 개발 자동화는 거대한 컨텍스트보다 먼저 반복 횟수에 비용을 쓴다. 이런 시스템에서 GPT-5.3-Codex는 "이 작업에 진짜로 어느 정도 모델이 필요한가"를 더 싸게 배울 수 있는 방법이다. 실패해도 더 적은 비용으로 한계를 알 수 있고, 충분히 통하면 파이프라인 전체에 Opus 가격을 걸 필요가 없다.
또 하나의 이유는 OpenAI가 터미널 중심 작업에 대해 비교적 정리된 공개 근거를 보여준다는 점이다. 단순히 "코딩에 강하다"가 아니라 가격, 컨텍스트, 벤치마크가 한 묶음으로 나온다. 첫 평가 대상을 고를 때는 이런 투명성이 생각보다 중요하다.
Claude Opus 4.6을 먼저 시험해야 하는 경우
결론: 진짜 병목이 토큰 단가가 아니라 긴 컨텍스트, 긴 작업 흐름, 그리고 약한 첫 시도가 만드는 비싼 재작업이라면 Claude Opus 4.6을 먼저 시험할 가치가 있다.
근거: Anthropic의 현재 문서는 Opus 4.6을 $5 / $25 per million tokens, 1M context, 128k max output으로 제시한다. 공개 자료는 Terminal-Bench 2.0 65.4%, **OSWorld 72.7%**와 함께, 더 긴 실행과 에이전트 작업에 맞는 모델 성격도 함께 보여준다.
판단: 큰 저장소나 여러 단계를 거치는 작업에서 첫 시도의 실패가 비싼 재작업을 만든다면 Claude Opus 4.6을 먼저 시험해야 한다.

여기서 중요한 것은 "더 똑똑하다"는 추상적 표현이 아니다. 어떤 종류의 일은 문맥을 놓치거나, 긴 흐름에서 줄거리를 잃거나, 리뷰를 통과하지 못하는 얕은 출력을 내놓는 순간 비용이 급격히 커진다. 큰 저장소, 긴 설계 문서, 긴 사고 대응 기록, 큰 결과물을 다뤄야 한다면 1M 컨텍스트와 128k 출력은 일의 형태 자체를 바꾼다.
이 지점에서는 가격표가 전부가 아니다. 더 비싼 모델이라도 재시도, 리뷰 시간, "거의 맞지만 몇 단계 뒤에 무너지는" 결과물을 줄여준다면 실제 총비용은 더 낮아질 수 있다. Anthropic의 공개 자료는 바로 그런 읽기를 뒷받침한다. OpenAI 공개 부록만큼 대칭적이지는 않더라도, Opus 4.6을 긴 작업과 비싼 실패 비용에 맞는 모델로 보기에는 충분하다.
대부분의 팀이 실제로 테스트해야 할 두 모델 분업
2026년의 가장 정직한 답은 영원한 승자가 아니라 분명한 사용 규칙인 경우가 많다.
GPT-5.3-Codex는 값싸게 첫 검증을 돌릴 구간에 둔다. 터미널 중심 반복 작업, 폭넓은 평가 배치, 아직 실패 패턴을 배우는 초기 자동화가 여기에 속한다. 그리고 작업이 큰 저장소 전체를 다루는 단계, 긴 다단계 실행, 혹은 한 번의 실패가 큰 재작업으로 이어지는 산출물 단계로 넘어가면 Claude Opus 4.6으로 올린다. 이것은 "둘 다 좋다"는 외교적 결론이 아니라 분명한 두 단계 분업이다.
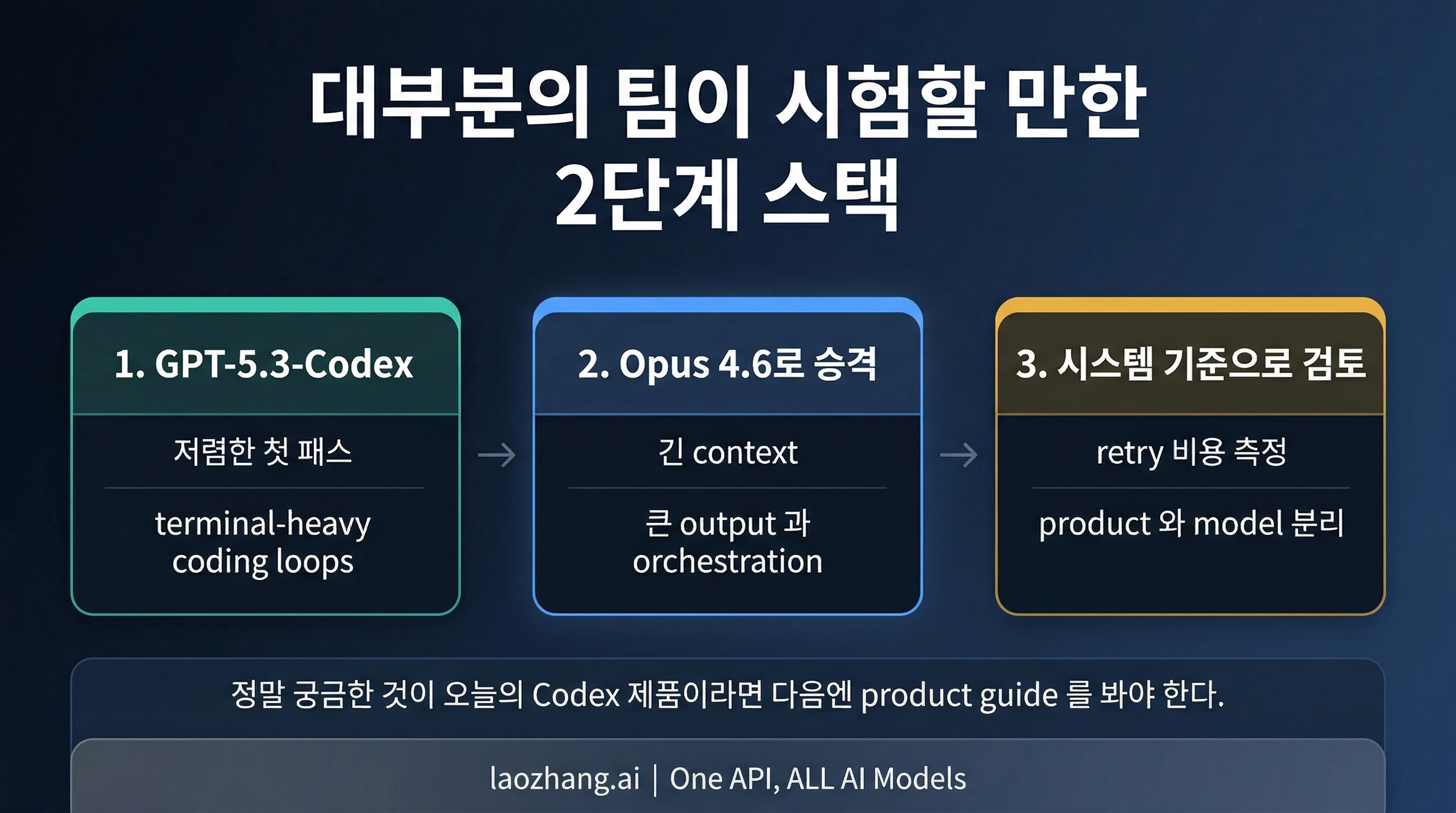
핵심은 전환 기준이다. 작업 요구가 아직 비교적 좁고 주된 관심이 저비용 평가 반복이라면 GPT-5.3-Codex에 남겨야 한다. 작업이 그 단계를 넘어 컨텍스트가 커지고, 재시도가 많아지며, 출력 자체가 가치 있는 결과물이 되면 Opus로 올린다. 그리고 이 전환은 토큰 단가가 아니라 재시도 비용과 후처리 비용으로 판단해야 한다. 정가만 비교하는 팀은 평범한 첫 결과가 만드는 실제 총비용을 놓치기 쉽다.
이 지점에서 제품 이야기도 실용적이 된다. OpenAI와 Anthropic 두 경로를 모두 유지하려면 laozhang.ai 같은 통합 게이트웨이가 과금, 인증, 모델 전환을 따로 관리하는 마찰을 줄일 수 있다. 여기서 그것을 언급하는 이유는 간단하다. 이 글의 가장 실용적인 답이 종종 멀티모델 구성이기 때문이다.
더 큰 결론은 이것이다. 모델 선택은 작업 단계에 맞춰야 한다. 값싼 첫 검증용 모델과 무거운 실행용 모델은 하나의 개발 시스템 안에서 충돌 없이 공존할 수 있다. 2026년에는 그것이 하나의 최고가 모델에 모든 일을 맡기는 것보다 더 강한 엔지니어링 해법인 경우가 많다.
진짜 궁금한 것이 지금의 Codex라면
"GPT-5.3-Codex"라고 입력하는 많은 독자는 사실 다른 질문도 함께 하고 있다. 지금의 Codex는 무엇인가? 이 질문에 대해 이 페이지가 너무 넓게 답하면 안 된다. OpenAI의 현재 제품 설명은 이미 GPT-5.4 시대의 Codex 쪽으로 이동했고, app, CLI, IDE, cloud, 그리고 큰 모델과 작은 모델의 분업이 중심이 되었다. 그래서 GPT-5.3-Codex는 여기서 유효한 비교 대상으로 남지만, 제품 전체의 답은 더 이상 아니다.
실용적인 다음 단계는 단순하다. 선택하려는 것이 모델이라면 이 페이지에 머물면서 위의 분업 규칙을 쓰면 된다. 선택하려는 것이 제품이나 작업 방식이라면 다음으로 볼 것은 OpenAI Codex 2026년 3월 업데이트다. Anthropic 도구 경로와 OpenAI 도구 경로 사이의 선택이 본론이라면 Claude Code vs Codex를 보라. Anthropic 쪽에서 역할 분담이나 비용 설계가 더 궁금하다면, 그다음은 Claude 4.6 Agent Teams 가이드와 Opus 가격 가이드가 더 정확하다.
결론
가장 짧지만 여전히 정직한 답으로 압축하면 이렇다. 더 싼 코딩 에이전트 검증을 먼저 돌리려면 GPT-5.3-Codex부터 시작하라. 컨텍스트 깊이, 실행의 안정성, 출력 규모가 토큰 단가보다 더 비싸지는 긴 작업이라면 Claude Opus 4.6부터 시작하라. 그리고 시스템 안에 두 단계가 모두 있다면, 가짜 만능 승자를 찾는 대신 두 모델을 의도적으로 역할 분담하는 편이 더 현실적이다.