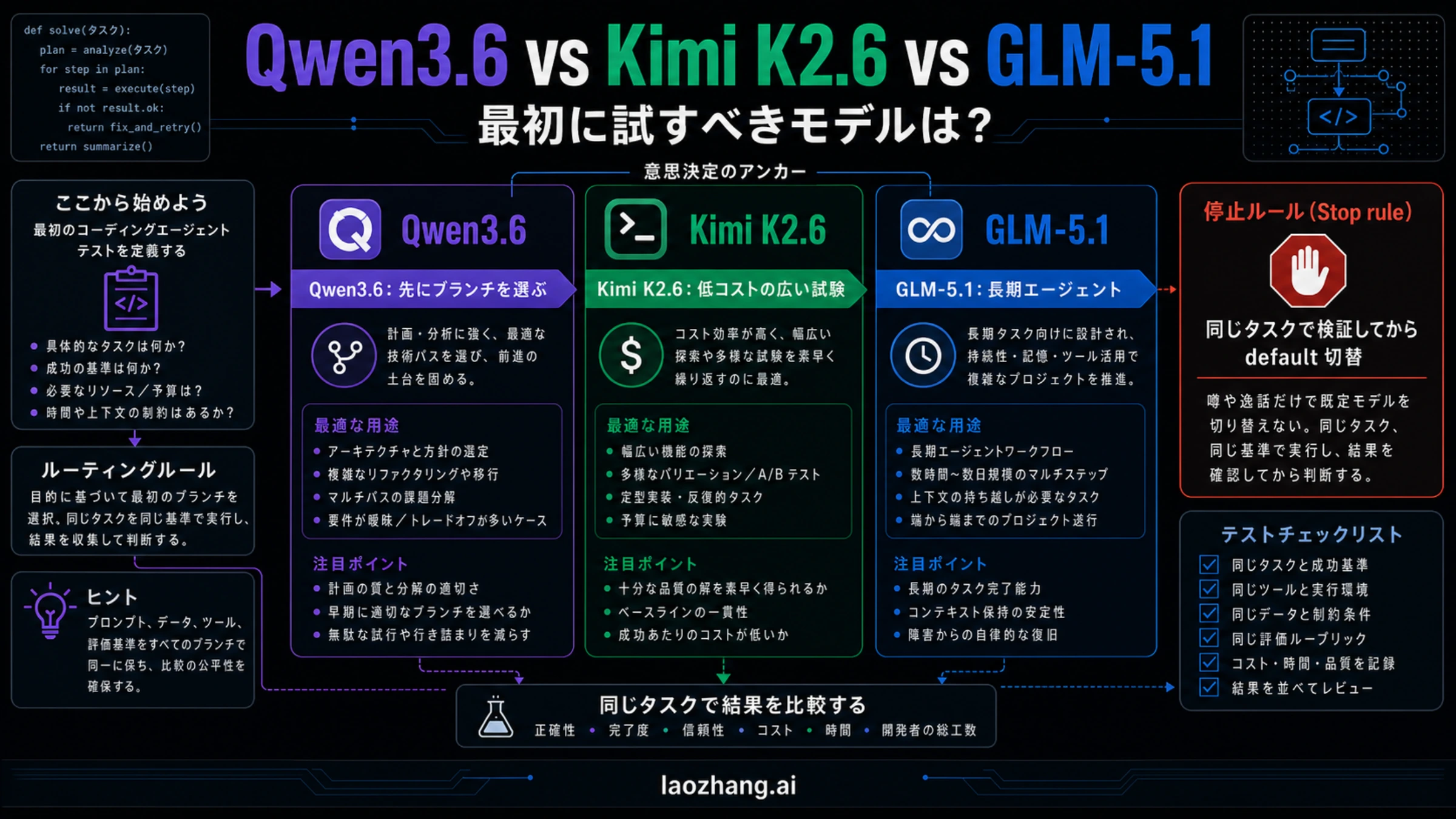
2026年5月7日時点では、長時間のcoding agent、複数ファイルの修正、大きなcontextを保った自律実行を測るならGLM-5.1を先に試します。安いpilot、たくさんの候補patch、UI variant、低リスクな実装を広く試したいならKimi K2.6を先に見ます。Qwen3.6を先に試すのは、まず分岐を決めたあとです。Qwen3.6-35B-A3Bはopen-weight control、Qwen3.6 Plus、Flash、Max PreviewはAlibaba hosted routeの実験です。
この比較を単純な順位表にすると、最初の判断を誤ります。kimi-k2.6とglm-5.1はMoonshot/KimiとZ.AIの文書で検証できるmodel IDです。一方でQwen3.6は、この文脈ではbranch labelです。Qwen3.6-35B-A3Bのlocal run、Qwen3.6 Plusのhosted result、Qwen3.6 Max Previewのlaunch-week reportを同じ行に置くと、見た目は整いますが、deployの根拠にはなりません。
| 最初に試すルート | 使う場面 | default変更前に確認すること |
|---|---|---|
| GLM-5.1 | 長時間の自律coding、複数ファイルmigration、大きなcontext、長いtool use。 | glm-5.1、context/output limit、tool behavior、current pricing、Z.AI migration surface。 |
| Kimi K2.6 | 安い大量pilot、UI variant、scaffolding、低リスクcleanup、複数候補patch。 | kimi-k2.6、pricing row、hosted route、open availabilityを使うならlicenseとself-host terms。 |
| Qwen3.6 | Qwen family behavior、local control、open-weight deploy、Alibaba hosted branch test。 | 35B-A3B、Plus、Flash、Max Previewのどれかを先に書く。 |
停止ルールは先に決めます。一つのdemo、一つのbenchmark、より安いtoken priceだけで現在のdefaultを替えてはいけません。同じrepo snapshot、同じprompt、同じtools、同じtests、同じreviewerで、accepted diff、hidden defect、retry cost、review time、rollback riskが現在のdefaultに負けないことが必要です。
速い答え
GLM-5.1は、長いagent loopを測るときに最初に置く候補です。agentが計画を保ち、途中の失敗から回復し、依存関係を追い、複数ファイルをまたぐ作業を最後まで持続できるかを見るなら、Z.AI routeを早い段階でcurrent defaultと比較します。
Kimi K2.6は、安い試行回数が重要なときに最初に置く候補です。frontend alternative、routine implementation、scaffolding、solution sketch、low-risk code cleanupのように、一回の失敗が致命的でなく、複数案を走らせたい場面に向いています。ただし、安いlisted priceはaccepted-task costが低いときだけ意味があります。
Qwen3.6は、分岐を決めたあとで初めて比較できます。Qwen3.6-35B-A3Bはlocal deployment、open-weight access、reproducible deployment、自前orchestrationを測るルートです。hosted Qwen3.6 branchesは、Alibabaのmanaged surface、quota、latency、billing、integrationを測るルートです。
Qwen3.6は先に分岐を決める
Qwen3.6は、分岐名が出るまではfamily labelです。QwenとHugging Faceの資料では、Qwen3.6-35B-A3Bはcoding agent向けMoE modelとして説明され、35B total parameters、3B active parametersを持ちます。model cardはApache-2.0 licenseを示し、262,144-token context settingのserving exampleを載せています。local controlやreproducible deploymentを重視するチームには、この分岐が判断対象になります。
しかし、公開されているQwen3.6比較のすべてが35B-A3Bについて話しているわけではありません。Qwen3.6 Plus、Flash、Max Previewを扱うものもあります。hosted branchはAlibaba routeのユーザーには正しい選択肢ですが、open-weight branchと混ぜてはいけません。Kimi K2.6やGLM-5.1と比べる前に、まず「どのQwen3.6 routeを測るのか」を書きます。
公式契約ルート
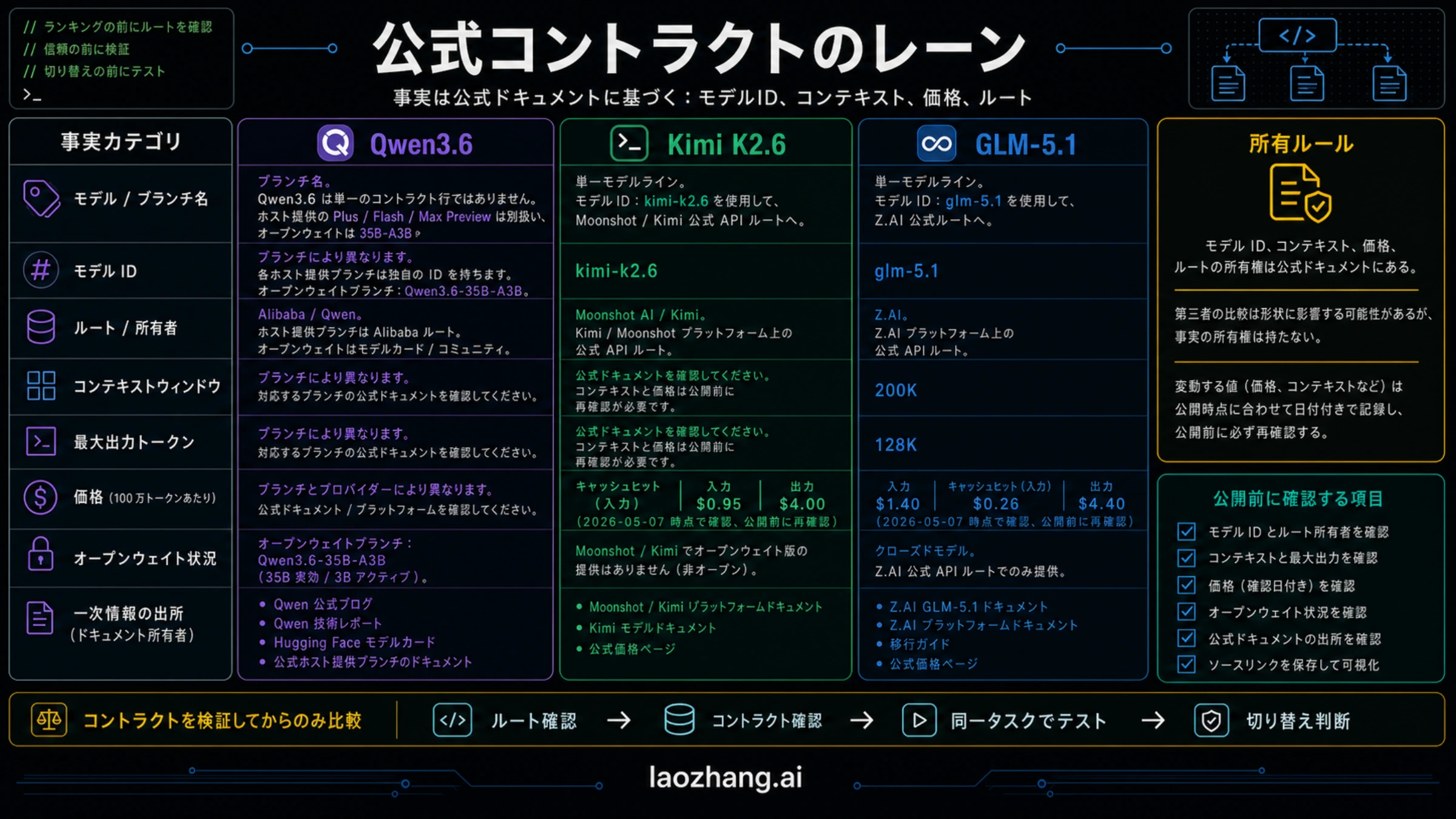
公式文書を基準にすると、比較の境界が崩れません。2026年5月7日に確認した契約行は次の通りです。
| 契約項目 | Qwen3.6 | Kimi K2.6 | GLM-5.1 |
|---|---|---|---|
| 最初に確認する所有者 | Qwen公式blog、Qwen model card、Alibaba hosted branch docs。 | Moonshot/Kimi platformとKimi model documentation。 | Z.AI GLM-5.1 docs、migration docs、pricing docs。 |
| deploy label | open-weight branchはQwen3.6-35B-A3B。hosted branchesは別名で書く。 | kimi-k2.6 | glm-5.1 |
| 最初に測る理由 | local/open-weight control、またはAlibaba branch experiment。 | Moonshot/Kimi routeで安い広範囲pilot。 | Z.AI routeでlong-horizon agent work。 |
| context/output | branch-dependent。35B-A3B cardは262,144-token serving exampleを含む。 | Moonshot/Kimiの現在文書で確認。 | Z.AI docsは200K contextと128K max outputを列挙。 |
| pricing owner | hosted branchはbranch/provider依存。open-weightは自分のinfrastructure cost。 | checked row: cache hit $0.16/MTok、input $0.95/MTok、output $4.00/MTok。 | checked row: input $1.4、cached input $0.26、output $4.4 per 1M tokens。 |
| open-weight boundary | Qwen3.6-35B-A3Bがopen-weight lane。 | open availabilityはroute、license、self-host termsを再確認。 | ここではZ.AI hosted routeをcontract rowにする。 |
Qwen3.6-35B-A3Bの事実はQwen postとHugging Face cardで確認します。KimiはKimi platformとKimi model documentationで確認します。GLMはZ.AI GLM-5.1 docs、migration docs、pricing docsで確認します。価格、context、availabilityはproduction defaultの前に必ず再確認します。
Coding agentの負荷で分ける
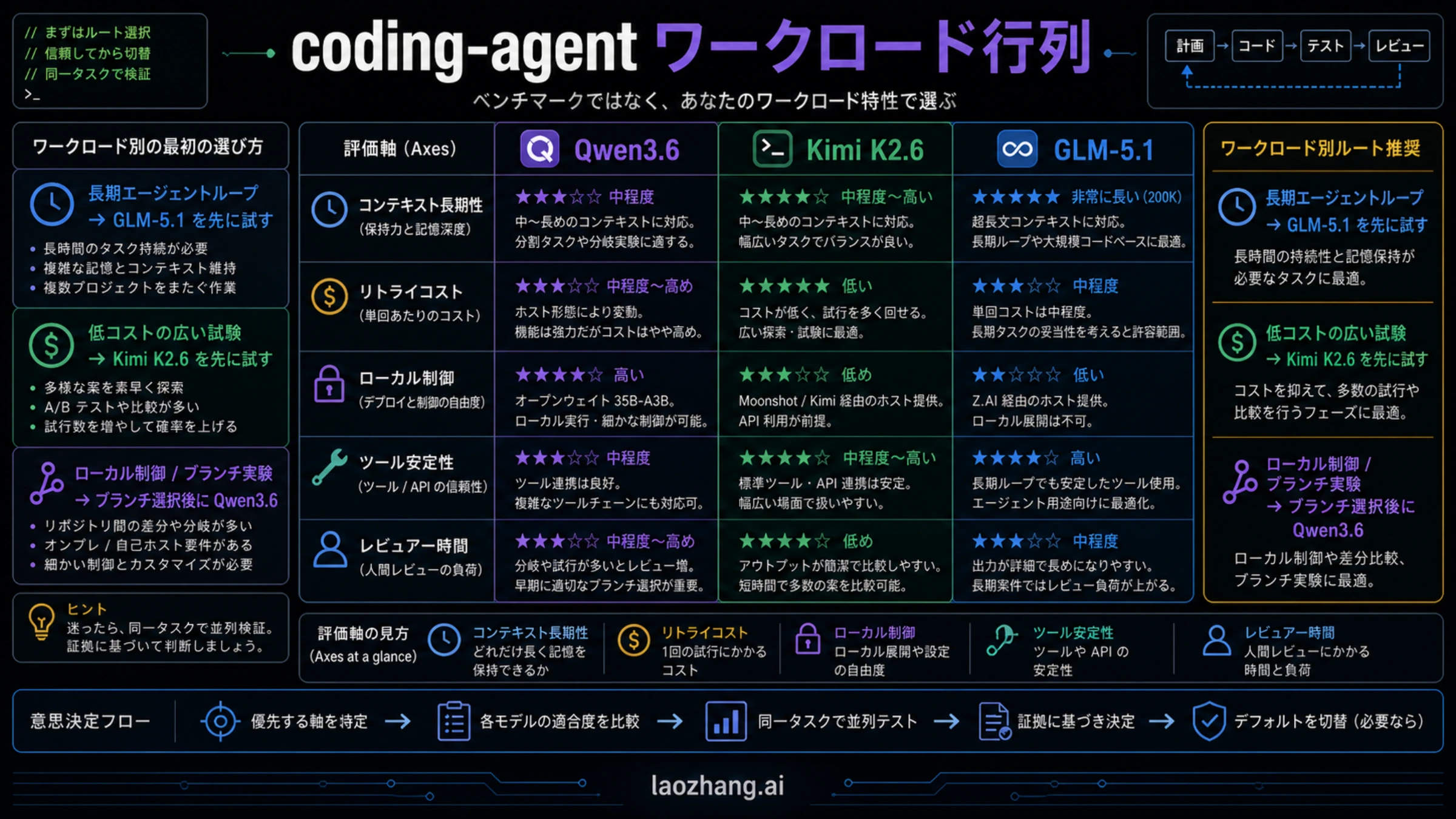
一つのbenchmark scoreより、workload splitのほうが判断しやすいです。GLM-5.1はlong-horizon autonomous codingに向きます。計画を長く保持し、途中のerrorから戻り、dependencyを追い、tool callsを何度もまたいでcoherenceを保つ必要があるときに先に測ります。
Kimi K2.6はbroad pilot volumeに向きます。UI alternatives、scaffolding、routine implementation、low-risk cleanup、複数candidate patchのように、安い試行回数が価値になる場面で先に測ります。ただし、reviewerが大量に直すなら、tokenが安くてもaccepted-task costは安くありません。
Qwen3.6はbranch-specific controlに向きます。Qwen3.6-35B-A3Bはlocal deployment、open-weight access、reproducibility、custom orchestrationを測るときに使います。hosted Qwen3.6 branchはmanaged surface、latency、quota、billing owner、Alibaba integrationを測るときに使います。
同一タスクpilot
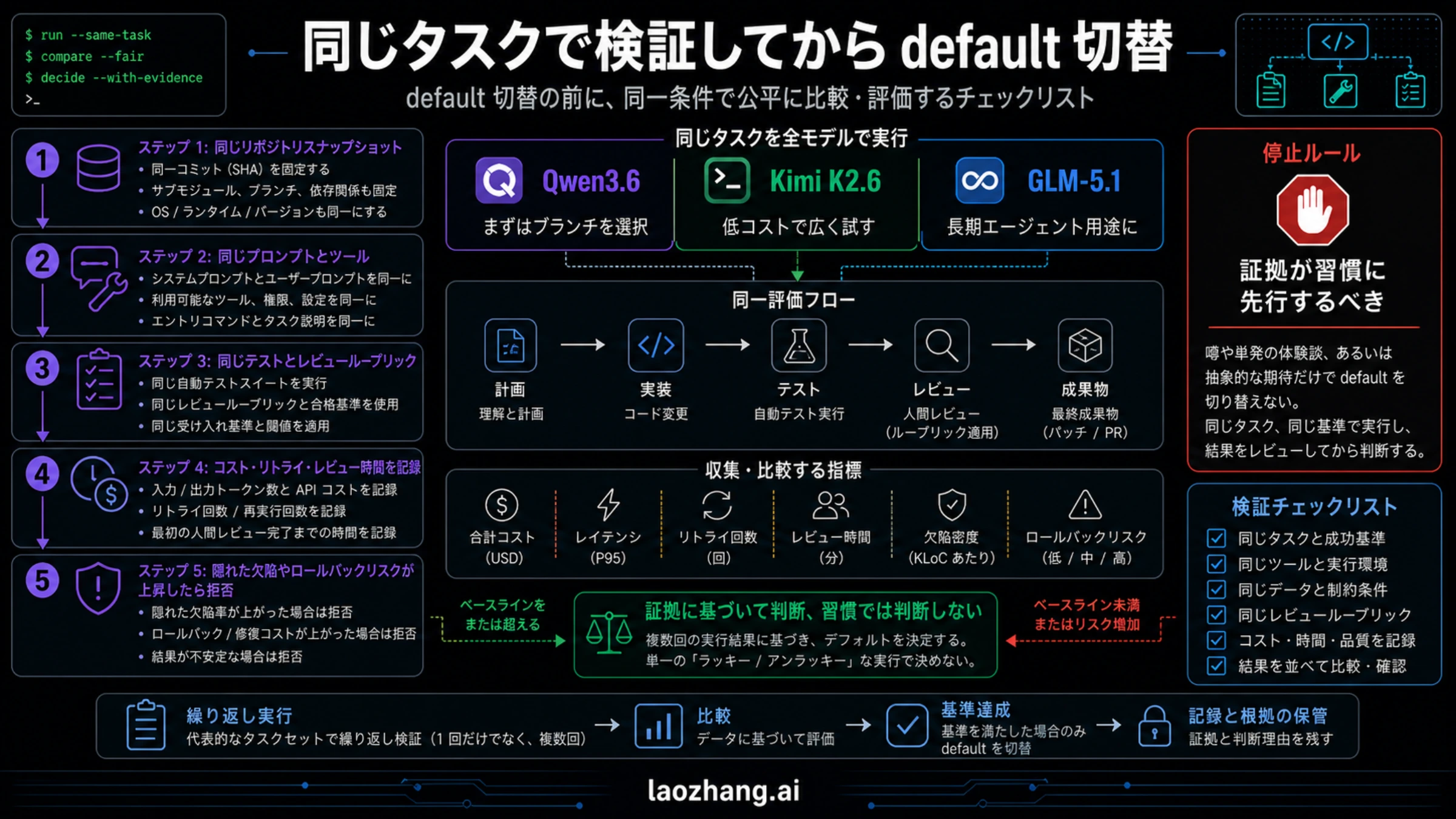
モデル比較は、同一タスクのpilotに落として初めて使えます。五から十個の実タスクを選びます。small bug fix、multi-file refactor、test-writing、frontend/UI task、long-context analysis、ambiguous requirementを含めると、失敗の種類が見えます。
各routeには同じrepo snapshot、prompt、tool permission、timeout、test command、review rubricを使います。accepted diff、test pass、missed references、hidden defects、reviewer edits、retry count、tool-call drift、latency、billing owner、rollback riskを記録します。候補routeが安くても、簡単なtaskだけを渡したり、reviewを甘くしたりしてはいけません。
thresholdはpilot前に決めます。one blocker defectでpromotion stop。three major defectsならpilot modeに残します。reviewer timeがcurrent defaultの2倍を超えるなら、costはtokensからpeopleへ移っただけです。accepted patchごとに三回以上retryが必要なrouteは、探索には使えてもdefaultには危険です。
最初に選ばない場面
短い安いvariantを十数個だけ試すなら、Z.AI routeがまだないチームはGLM-5.1から始める必要はありません。long-horizonの強みが、小さな実験では目立ちにくいからです。
high-risk production migrationなら、Kimi K2.6を安いからという理由だけでdefaultにしてはいけません。Kimiはpilot poolに入れられますが、hidden defectのcostがmodel billより大きい作業ではcontrol routeが必要です。
Qwen3.6の分岐を誰も言えないなら、Qwen3.6から始めてはいけません。Qwen3.6 Flash、Qwen3.6 Max Preview、local Qwen3.6-35B-A3Bは同じ証拠ではありません。branch first、comparison secondです。
既存の比較ページとの分担
この判断は、Qwen3.6 family branch、Kimi K2.6、GLM-5.1の三ルートだけを扱います。Kimi K2.6がpremium Claude defaultを置き換えるかを知りたいなら、Kimi K2.6 vs Claude Opus 4.7を使います。DeepSeek V4、GPT-5.5、Claude Opus 4.7も候補に入るなら、より広いKimi K2.6 vs DeepSeek V4 vs GPT-5.5 vs Claude Opus 4.7を使います。
境界を分けておくと、この三ルート判断は一般的なモデルランキングになりません。readerは、どのrouteを先にtest harnessへ入れるかを決められます。
よくある質問
Qwen3.6は一つのモデルですか?
いいえ。実務選定では、Qwen3.6はrouteを名付けるまでbranch labelです。Qwen3.6-35B-A3Bはopen-weight branchです。Plus、Flash、Max Previewは別々にroute、pricing、limitを確認します。
Kimi K2.6はGLM-5.1より安いですか?
2026年5月7日に確認したowner rowsでは、Kimi K2.6のlisted input/output token priceはGLM-5.1より低いです。これはpilot advantageであり、default-switch verdictではありません。accepted-task costはretries、reviewer time、hidden defects、wrapper billingで変わります。
GLM-5.1はcoding agentsに強いですか?
jobがlong-horizon、context-heavyで、Z.AI routeに合うならGLM-5.1を最初に測ります。cheap exploration、local control、小さなroutine taskの自動的な第一候補ではありません。
Qwen3.6を先に測るべきなのはいつですか?
local control、open-weight deployment、Alibaba route compatibility、Qwen-family behaviorが判断の中心にあるときです。結果を解釈する前に、必ずbranchを明記します。
どれかを現在のdefaultにできますか?
same-task pilotを通ったあとだけです。candidate routeはaccepted diffs、tests、hidden-defect severity、reviewer time、retry cost、tool reliability、rollback riskでcurrent defaultに負けてはいけません。