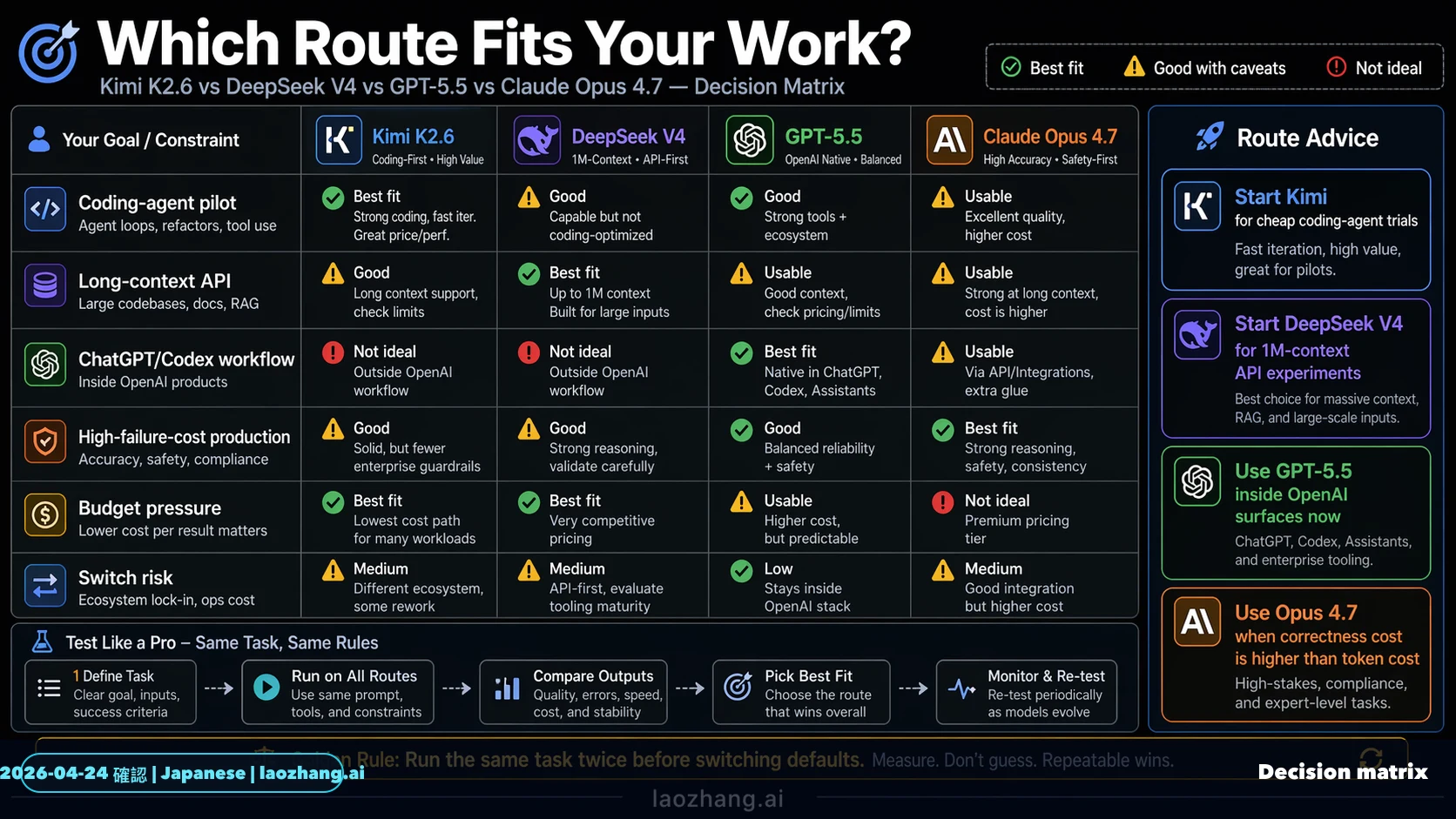
2026年4月24日時点では、この比較はDeepSeek V4を中心に作るべきです。低コストのcoding-agent実験ならKimi K2.6を先に試し、現在呼び出せる安いDeepSeek APIが必要ならDeepSeek V4 FlashまたはV4 Proを試します。OpenAIネイティブな操作体験が重要なら、GPT-5.5はChatGPTまたはCodex内で先に評価します。本番移行、長いコンテキスト、レビューコストが高い作業では、Claude Opus 4.7を最初のcontrol routeとして残します。
重要なのはランキングではなくルートです。公式のmodel ID、価格、context、tool boundaryがどこにあるかを確認し、その後で同じタスクを同じ条件で走らせます。同じrepository snapshot、同じprompt、同じtools、同じtests、同じreviewer、同じrollback thresholdでなければ、default変更の証拠にはなりません。
| ルート | 最初に試す場面 | 現在の境界 | Stop rule |
|---|---|---|---|
| Kimi K2.6 | 低リスクの大量試行、scaffolding、coding-agent pilot。 | KimiはK2.6、RMB pricing、multimodal input、256k級contextを文書化しています。 | 同じworkflowで繰り返し勝つまでproduction defaultにしない。 |
| DeepSeek V4 | 現在の安いDeepSeek APIが必要なとき。 | DeepSeekはdeepseek-v4-flash/pro、1M context、384K max outputを文書化しています。 | 古いDeepSeek labelをdeploy targetにしない。 |
| GPT-5.5 | ChatGPTやCodexの中でOpenAI-native flowを評価する。 | OpenAIはGPT-5.5がChatGPTとCodexで利用可能、APIはcoming soonとしています。 | API IDや価格を作らない。 |
| Claude Opus 4.7 | migration、security-adjacent code、long context、本番correctness。 | Anthropicはclaude-opus-4-7、1M context、Opus pricingを文書化しています。 | same-task dual-runなしに切り替えない。 |
速い答え
最初に試すべきモデルは、用途のルートで変わります。Kimi K2.6は安い試行回数を増やすpilot routeです。DeepSeek V4は、FlashとProのAPI契約が今見えるDeepSeek routeです。GPT-5.5はChatGPTやCodexの中で使うときに価値を見やすい一方、production APIは公式文書を待つ必要があります。Claude Opus 4.7は、hidden defectが高くつく作業のcontrol routeです。
つまりこれはleaderboardではありません。低リスクbulk workならKimiとDeepSeek V4を先に見ます。難しいrepo migrationならOpusをcontrolにします。Codex中心のチームならGPT-5.5をそのsurface内で測り、server-side API移行は後で判断します。
公式契約ルート
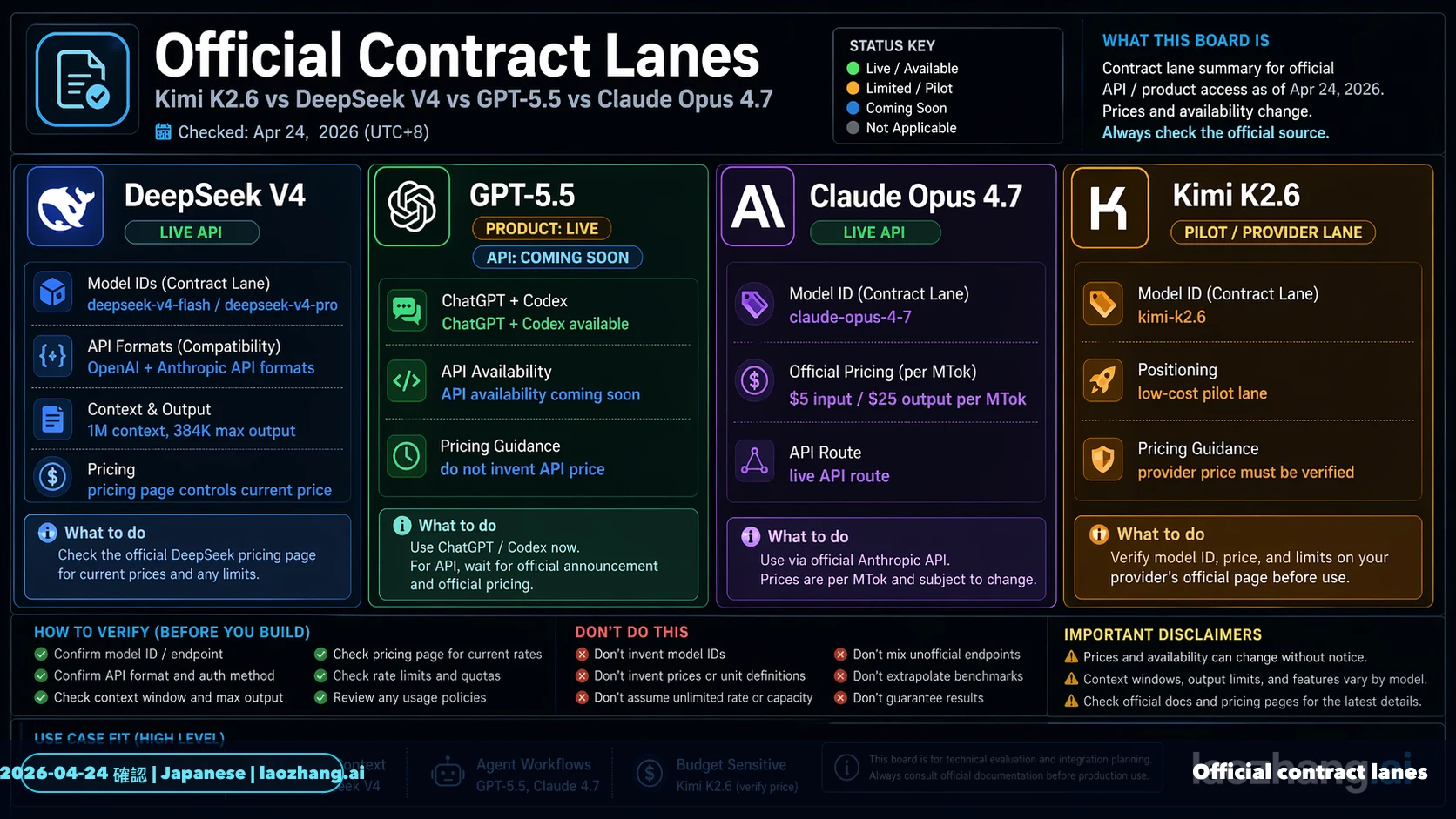
公式文書を見ると、比較の境界がはっきりします。KimiはK2.6を最新で賢いモデルとし、text、image、video inputと256k級contextを示しています。DeepSeekはdeepseek-v4-flashとdeepseek-v4-pro、OpenAI formatとAnthropic formatのbase URL、1M context、384K maximum output、cache hit、cache miss、output価格を示しています。OpenAIの現在のAPI guideはGPT-5.4を中心にしつつ、GPT-5.5はChatGPTとCodexで利用可能、API availability coming soonと書いています。AnthropicはClaude Opus 4.7の1M contextと$5 input / $25 output per MTokを示しています。
| Contract item | Kimi K2.6 | DeepSeek V4 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|---|---|
| Route owner | Kimi platform | DeepSeek API | ChatGPT and Codex first | Anthropic API and cloud |
| Deploy label | kimi-k2.6 | deepseek-v4-flash / deepseek-v4-pro | API docs公開後に再確認 | claude-opus-4-7 |
| Context | 256k級 | 1M、384K max output | API context pending | 1M |
| Price owner | Kimi RMB page | DeepSeek USD page | API price row未公開 | Anthropic USD page |
2026年4月24日に確認した情報源:DeepSeek V4 release、DeepSeek pricing、Kimi K2.6 pricing、OpenAI latest model guide、Claude model overview、Claude pricing。production defaultを変える前に必ず再確認します。
DeepSeek V4で比較が変わる理由
DeepSeek V4は単なる名前ではありません。現在のmodel ID、price row、context route、compatibility routeを持つため、DeepSeekを実際に測れる候補にします。Flashは安いDeepSeek candidate、Proはより強いDeepSeek candidateです。
そのため、現在のKimi、現在のOpenAI surface、現在のAnthropic APIを、古いDeepSeek表現と比べてはいけません。current route against current routeで測るべきです。今日developerが呼べるのがdeepseek-v4-flashまたはdeepseek-v4-proなら、その行を評価します。
価格はpilot signalでありreplacement verdictではない
安いtokensは重要です。agentic workではretry、variant、recoveryが必要だからです。ただしcheap runがhidden defects、manual review、tool loops、rollback workを増やすなら、実際には安くありません。
| Cost area | 記録するもの | 判断への使い方 |
|---|---|---|
| Token cost | input、cache hit、cache miss、output、retries、tool calls | invoice shapeを見る |
| Quality cost | blocker、major、minor、format miss | merge可能性を見る |
| Time cost | latency、queue、reviewer minutes、reruns | 人へのコスト移転を見る |
| Integration cost | model ID、auth、context behavior、tool behavior、billing owner | brittle defaultを避ける |
Same-task pilot checklist

default model switchはproduction changeです。小さなbug fix、refactor、test-writing、long-context analysis、曖昧なtaskを含む5から10個の実タスクを選びます。candidate routeとcurrent defaultは同じrepo snapshot、spec、tools、timeout、test command、reviewerで走らせます。
loss thresholdは事前に決めます。one blocker defectでpromotion停止。three major defectsならpilot modeに残します。reviewer timeがcontrol routeの2倍を超えるなら、token savingsが人間の作業に移った可能性があります。toolやformatが不安定なら、chatでは使えてもagent defaultには危険です。
既存ユーザーの選び方
すでにKimiを使っているなら、DeepSeek V4 FlashとProをcheap-route poolに入れ、Opusをhigh-risk controlにします。DeepSeekを使っているなら、まずtest harnessをV4 model IDsへ更新します。OpenAI API中心なら、GPT-5.5の学習はChatGPTとCodexで行い、server routingはofficial API contract後に判断します。Claude Opus 4.7を使っているなら、migration、correctness-sensitive work、long contextには維持し、安いrouteはlow-risk classで証明させます。
狭い比較なら Kimi K2.6 vs Claude Opus 4.7 と GPT-5.5 vs Claude Opus 4.7 が使えます。
よくある質問
今はDeepSeek V4が正しいkeywordですか?
はい。DeepSeek V4 FlashとProが現在のAPI rowsなので、この比較ではDeepSeek V4がtitleとdeploy decisionを持つべきです。
GPT-5.5はAPIで使えますか?
ChatGPTとCodexではliveとして扱えます。production APIはofficial model ID、price row、limits、tool behaviorが出るまで待つべきです。
coding-agent teamは何を先に試すべきですか?
低リスク量産はKimi、cheap callable APIはDeepSeek V4、OpenAI-native flowはCodex内のGPT-5.5、高リスクcorrectnessはOpus 4.7です。
DeepSeek V4はClaude Opus 4.7を置き換えますか?
価格だけでは置き換えません。DeepSeek V4はcheap API workloadsで勝つ可能性がありますが、high hidden-failure costではOpusがcontrol routeです。
最も安全なswitch ruleは何ですか?
same-task dual-runを行い、accepted diff、defect severity、reviewer time、latency、retry cost、rollback riskで繰り返し勝ってからpromoteします。