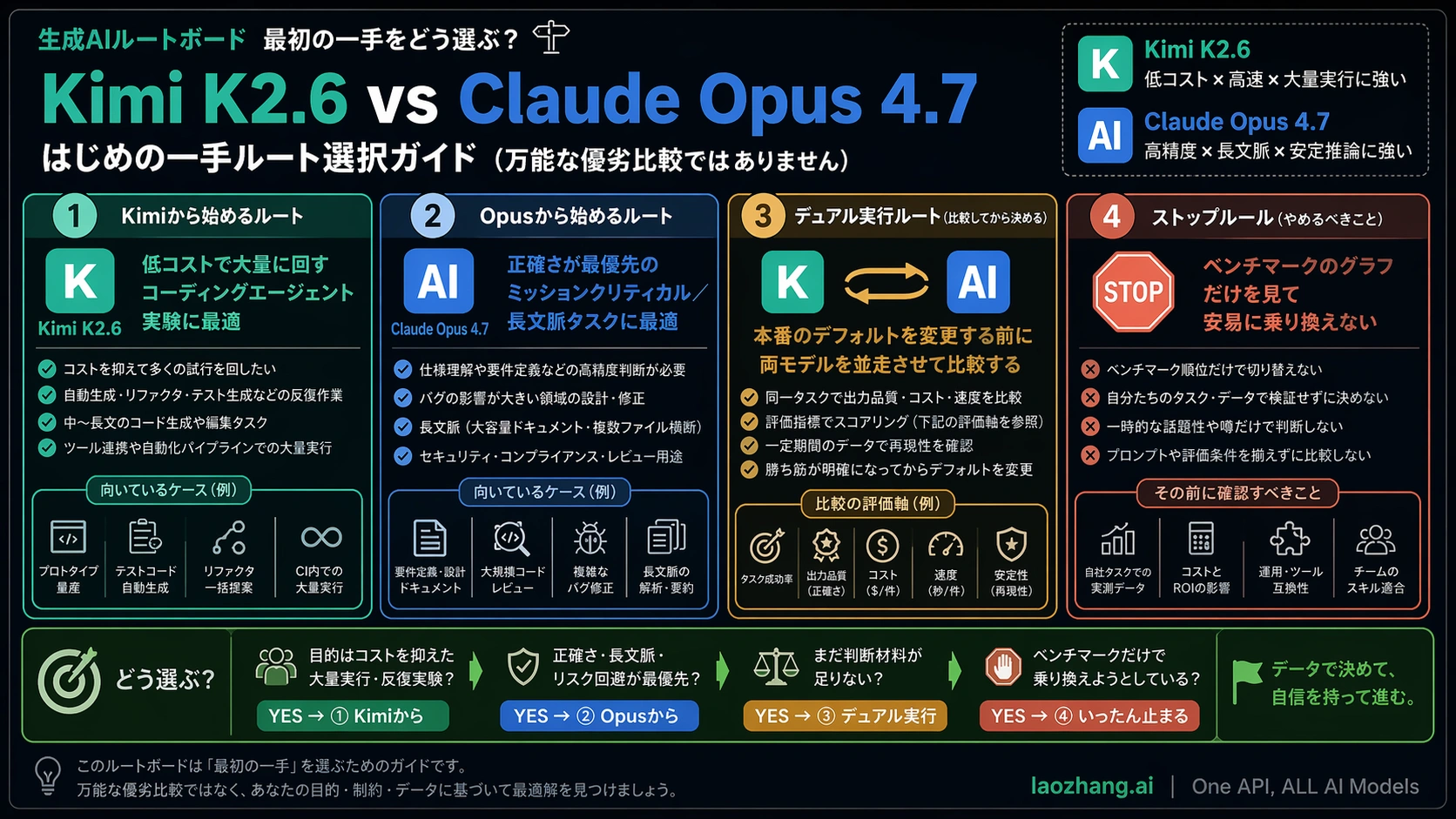
Kimi K2.6 と Claude Opus 4.7 の比較は、総合ランキングを作るためではありません。実務で必要なのは、次の coding-agent 評価や API route の最初の一回をどちらで始めるか、そしてどの時点で production default を変えてはいけないかです。
低リスクの大量試行、batch 修正、test scaffolding、open model route の検証なら、まず Kimi K2.6 を試す価値があります。migration、security、payment-adjacent code、長い context の production analysis、または hidden bug のコストが token bill より高い仕事なら、まず Claude Opus 4.7 を残すべきです。default model を変える判断だけは、同じ repository、同じ spec、同じ tool budget、同じ review rule で dual-run してからです。
| route | 先に試す場面 | その理由 | stop rule |
|---|---|---|---|
| Kimi first | 低コストで試行回数を増やしたい | 価格差が pilot を正当化する | 一度通っただけで Opus replacement と呼ばない |
| Opus first | 正確性、長文脈、migration risk が重要 | 1M context と mature API contract が強い | 価格だけで production default を変えない |
| Dual-run | routing policy や default model を変える | replacement quality は workflow claim | loss threshold なしでは切り替えない |
2026-04-23 時点の公式 contract では、Kimi K2.6 は cache hit $0.16/MTok、input $0.95/MTok、output $4.00/MTok、262,144 token context を示しています。Claude Opus 4.7 は input $5/MTok、output $25/MTok、1M context、128k max output です。この差は Kimi の cost route と Opus の premium route を強く示しますが、全ての coding task での勝敗を決めるものではありません。
先に結論
日本語の検索面では、動画、Reddit、OpenRouter のような比較ページ、そして古い Kimi K2.5 系の話題が混ざりやすいです。だから最初に必要なのは、どの情報が公式 contract で、どの情報が third-party signal なのかを分けることです。読者が欲しいのは「どちらが強いらしいか」ではなく、「自分の最初のテストをどう組むか」です。
Kimi を先に見るべき場面は、attempt volume が価値になるときです。低リスクなコード整理、テスト追加、探索的 agent、草稿生成、open model route の評価では、安い一回を何度も回せること自体が戦略になります。Opus を先に見るべき場面は、失敗が後で大きく返ってくるときです。repo-wide migration、認可や決済、長い依存関係を持つ refactor では、token price より failure price が支配的です。
default change は別問題です。Kimi が安いからといって、今まで Opus が担当していた production route をすぐ置き換えるのは危険です。Kimi が勝つための条件は、同じ task pack、同じ checks、同じ reviewer の下で、real defect と review cost が許容範囲に収まることです。
公式 contract を先に読む

| 契約ポイント | Kimi K2.6 | Claude Opus 4.7 |
|---|---|---|
| 事実の所有者 | Moonshot / Kimi | Anthropic |
| API 表記 | Kimi platform の K2.6 route | claude-opus-4-7 |
| 2026-04-23 時点の価格 | cache hit $0.16/MTok、input $0.95/MTok、output $4.00/MTok | input $5/MTok、output $25/MTok |
| context / output | 262,144 token context | 1M context、128k max output |
| 判断への影響 | 試行回数を増やしやすい | リスクの高い仕事で premium control を残しやすい |
Kimi の価格、cache hit row、context window は Moonshot/Kimi 側の first-party fact として扱います。Claude Opus 4.7 の model ID、価格、1M context、128k output、API behavior change は Anthropic 側の first-party fact として扱います。provider comparison や translated result は便利ですが、公式事実の所有者にはなりません。
1M input と 1M output の単純な形で見ると、Kimi は cache を使わない input plus output でも約 $4.95、Opus は $30 です。この差は pilot の理由として十分です。ただし production cost はそこで終わりません。retry、tool call、timeout、manual review、hidden defect、rollback が実コストに乗ります。
Opus 側では tokenization caveat も重要です。Anthropic は、同じ入力が content type によって約 1.0x から 1.35x の token に見える可能性を説明しています。これは固定 surcharge ではありませんが、実 prompts で測る理由になります。
証拠が言えることと言えないこと
Kimi K2.6 の公式 material は、Kimi が current で serious な低コスト候補であることを示します。しかし公式 benchmark table は Claude Opus 4.7 を直接比較列として含んでいません。したがって、そこから Kimi が Opus 4.7 を production で置き換えると書くのは境界を越えています。
third-party comparison は方法の材料です。どの test category を再現するか、どの failure mode を見るか、passing summary と実際の diff がずれることをどう扱うか、そういう点で役立ちます。しかし価格、context、model ID、API behavior の所有者にはなりません。
| evidence | 使えること | 使えないこと |
|---|---|---|
| Kimi first-party | 低コスト pilot の正当化 | Opus 4.7 の完全 replacement 証明 |
| Anthropic first-party | Opus の premium contract と migration notes | 全 task で価格差を正当化する証明 |
| third-party page | test idea と risk signal | official price や default routing |
| 自分の dual-run | 自分の workflow での置き換え判断 | 他チームへの universal claim |
coding agent の pilot 方法
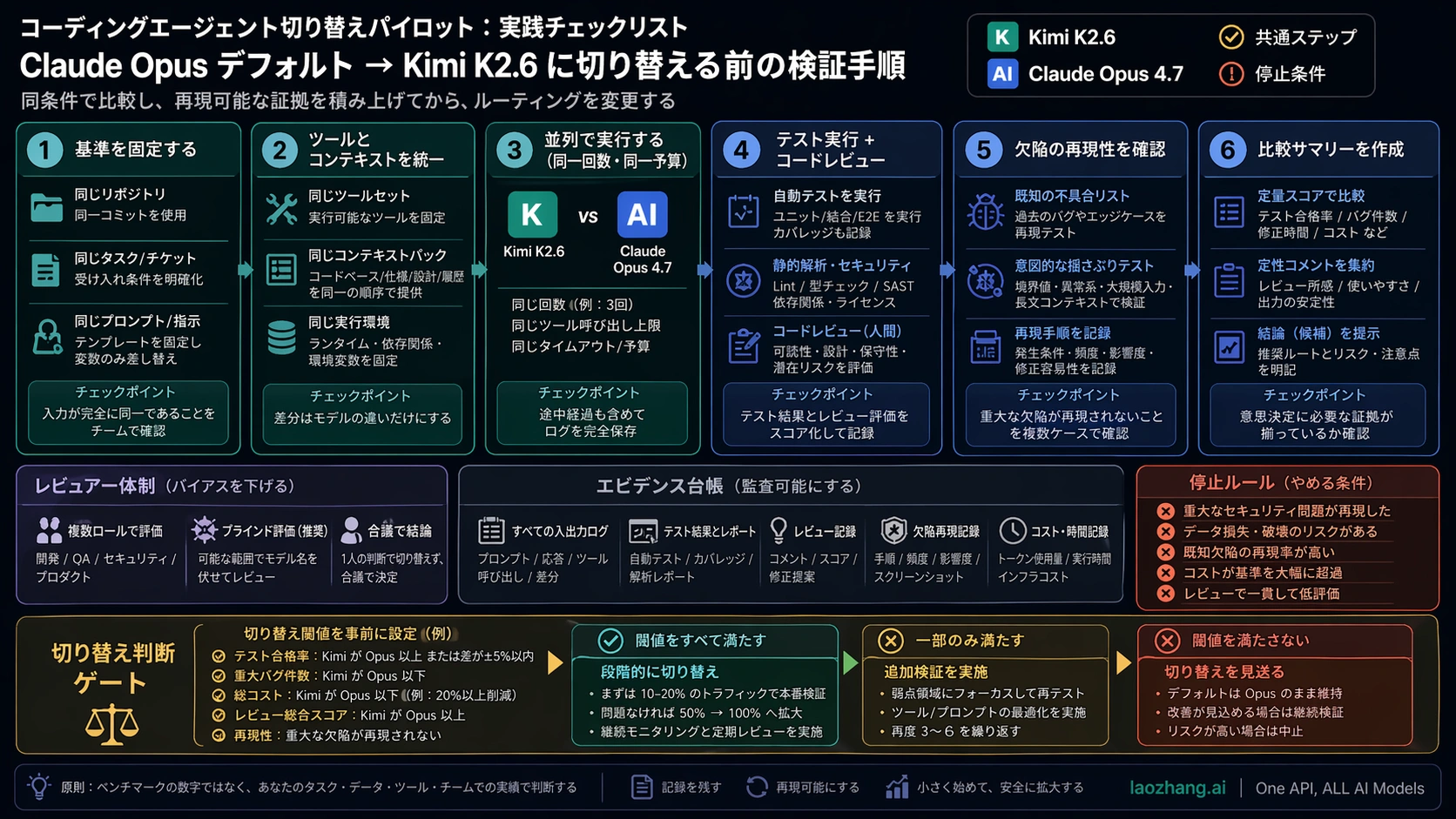
pilot は派手にしないほうがよいです。Opus がすでに役立った real task から、小さい bug fix、中規模 refactor、test-writing、long-context analysis、仕様が曖昧で model が反問すべき task を選びます。agentic coding なら tool use と repo navigation を残し、API batch なら本番と同じ prompt template、timeout、retry policy を使います。
両モデルに同じ repository snapshot、同じ task description、同じ success criteria、同じ tool budget、同じ stop condition を与えます。unit、integration、lint、smoke check も同じです。最後に diff を人間が見ます。test が通っても、over-broad refactor、脆い abstraction、migration step の漏れ、周辺コードの誤読は残ります。
switch threshold は pilot 前に書きます。低リスク batch edit なら、Kimi の defect が Opus より 10% 以内で、cost が半分以下なら default 候補にする、という条件があり得ます。security-sensitive task なら near-parity を要求し、長く dual-run を続けるべきです。
workload route

| workload | Kimi から始める | Opus から始める | default 前に dual-run |
|---|---|---|---|
| high-volume agent experiments | はい | quality sample として使う | 重要 repo 前に必要 |
| low-risk cleanup / test scaffolding | はい | review time が詰まる時 | auto-merge 前に必要 |
| repo-wide migration | control run 後 | はい | はい |
| security / payment code | 通常は先にしない | はい | はい |
| long-context production analysis | 262k で足り cost が支配的なら | 1M または 128k output が必要なら | Opus 判断を置換する前に必要 |
| open-source / self-host evaluation | Kimi が自然な first route | Opus は open route ではない | production decision と競合する前に必要 |
Anthropic 内部の移行が本当の問いなら Claude Opus 4.7 vs Claude Opus 4.6 を使ってください。Anthropic、OpenAI、Google の broader frontier route を選びたいなら Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro が担当です。
API default を変える前に
Kimi first-party、OpenRouter、Microsoft Foundry、その他 provider は別 contract です。model name が近くても、latency、quota、billing、support、failure term は同じではありません。社内 report では、どの route の価格なのかを必ず書くべきです。
Claude 側も単なる model string swap ではありません。Opus 4.7 では sampling parameters、extended thinking、tokenizer behavior、high-resolution image handling、task budget controls などを確認する必要があります。client code が古い parameter を投げるなら、prompt ではなく harness が migration のボトルネックになります。
rollout では cost、quality、time、route を別々に記録します。cost は cached input、input、output、retry、tool calls。quality は blocker、major、minor。time は wall-clock と reviewer minutes。route は Kimi-only、Opus-only、dual-run、rollback。これがない default change は判断ではなく願望です。
評価テンプレート
| 記録するもの | 記録方法 | 意味 |
|---|---|---|
| cost | input、cached input、output、retry、tools | 安い token と安い workflow を分ける |
| quality | blocker、major、minor、style | 重大 defect を平均で薄めない |
| review | reviewer minutes、manual edits、rerun | agent coding の本当の費用を見る |
| route | Kimi-only、Opus-only、dual-run、rollback | pilot を routing rule に変える |
よくある質問
Kimi K2.6 は Claude Opus 4.7 より安いですか?
2026-04-23 の first-party price では、はい。Kimi は $0.95/MTok input、$4.00/MTok output、$0.16/MTok cache hit。Opus は $5/$25 です。provider price は別 contract です。
Kimi K2.6 は Claude Opus 4.7 を置き換えられますか?
あなたの workflow で証明した後なら可能です。ただし正しい初期 claim は「Kimi は cost-sensitive coding work の pilot に値する」であり、「自動で Opus replacement」ではありません。
coding agent にはどちらがよいですか?
high-risk coding、migration、long-context production work では Opus 4.7 が安全な first choice です。低リスク大量試行では Kimi K2.6 から試す価値があります。
Kimi の公式 benchmark は Opus 4.7 への勝利を証明しますか?
いいえ。Kimi の表は K2.6 が current で強いことを示しますが、Opus 4.7 との直接 head-to-head ではありません。
default model 変更前に何をテストすべきですか?
同じ repo、同じ spec、同じ tool budget、同じ tests、同じ reviewer、同じ loss threshold で dual-run してください。
provider comparison page を使ってもよいですか?
test idea と risk scouting には使えます。公式 model ID、price、context、output、API behavior は Kimi と Anthropic の first-party docs に戻してください。
1M context が必要なら?
Claude Opus 4.7 から始めてください。Kimi の 262k context は大きいですが、同じ contract ではありません。