
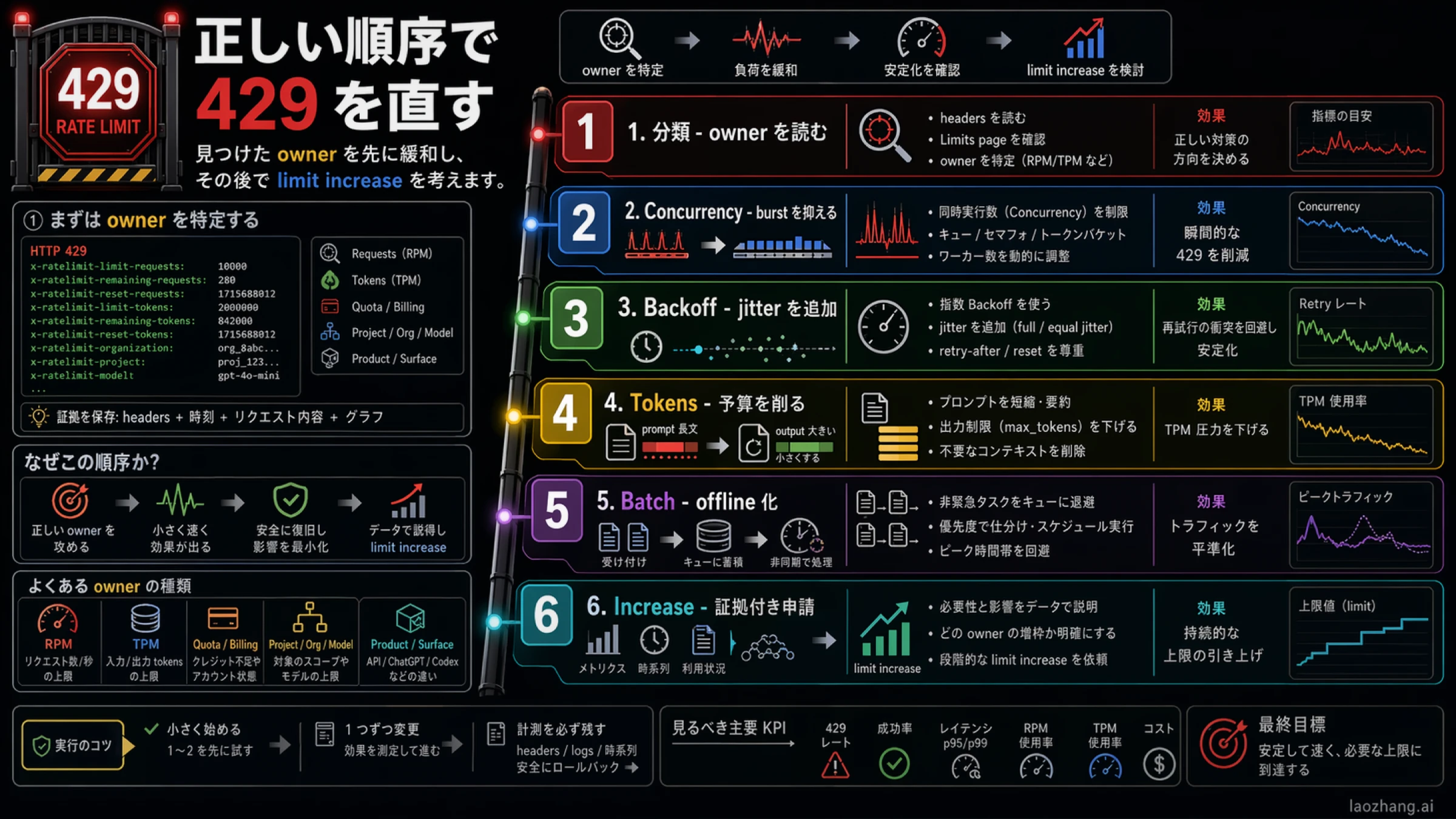
OpenAI API の 429 は、一つの万能な retry エラーではありません。request rate に当たっている場合もあれば、token rate が先に尽きている場合もあります。quota や billing が owner のこともありますし、project や model scope の問題、あるいは ChatGPT や Codex など別の product surface を API 429 と混同していることもあります。だから最初に必要なのは retry loop ではなく、owner の切り分けです。
日本語の解説や体験談では、クレジット不足の話、quota エラー、backoff のコード例が一つの原因のように並びがちです。そのまま読むと、429 は「sleep する」「課金する」「キーを変える」のどれかだと思いやすくなります。しかし本当に速い直し方は、response headers と Limits ページを見て、どの owner が今の route を止めているかを判断することです。
覚えておくべき順序はシンプルです。owner を読む。reset を読む。最小の修正を選ぶ。安定した証拠がそろってから増枠を考える。この順番だけで、かなりの誤修正を避けられます。
TL;DR
| 質問 | 短い答え |
|---|---|
| OpenAI API の 429 は何を意味するか | request、token、quota、billing、scope、reset-window のどれかの境界に当たっています。 |
| 最初に何を見るか | x-ratelimit headers とアカウントの Limits ページです。 |
| 技術的に多い owner は何か | burst、並列過多、token budget の大きすぎる request です。 |
| コード以外で多い owner は何か | quota 不足、billing 状態、trial 終了、wrong surface です。 |
| 増枠の前にやるべきこと | concurrency を下げる、backoff と jitter を入れる、token output を削る、Batch API や queue に逃がす。 |
| やってはいけないこと | blind retry、key rotation、ChatGPT/Codex のプラン変更を API 解決策と見なすこと。 |
retry より先に owner を見る
OpenAI の公開ドキュメントを丁寧に読むと、429 は一枚岩ではないことがわかります。アカウントには live limits があり、usage tier が headroom に影響し、response headers は残量と reset を教え、mitigation は brute-force resend ではなく bounded backoff から始まります。
だから最初の問いは「OpenAI API のレート制限はいくつか」ではなく、「今の request は何に止められたか」です。request-rate owner と token-rate owner は同じ 429 に見えますが、直し方が違います。quota や billing owner なら、retry をきれいに書いても解決しません。scope が違えば、credits を足しても route は正しくなりません。
実務的な四段階にするとこうです。
- owner を確認する。
- reset signal を確認する。
- 最小の安全な修正を行う。
- route と traffic shape が安定してからだけ増枠を考える。
project や organization の設定に自信がないなら OpenAI API Key と Organization ID を参照してください。ChatGPT や Codex の使用枠が気になっているなら OpenAI Codex usage limits と Codex API key vs subscription のほうが正しい surface です。
OpenAI の rate limits が測っているもの
OpenAI は rate limit を単一の固定値として扱っていません。運用で重要なのは次の層です。
- Requests per minute: 短時間に送る request 数。
- Tokens per minute: prompt と output を足した token volume。
- Usage tier: アカウントの headroom に影響する階層。
- Live account limits: 実際に効いている ceiling は Limits ページ。
- Reset signals: 次にいつ窓が開くかを示す header。
この構造があるため、古い記事にある「OpenAI は毎分何回まで」という表をそのまま信じるのは危険です。公開ドキュメントは概念や mitigation を教えてくれますが、今の account ceiling を保証してくれるのは Limits ページです。
特に request pressure と token pressure は分けて読む必要があります。RPM 側の問題は burst や tight loop、過剰な concurrency から来やすく、TPM 側の問題は長い履歴、長すぎる prompt、過大な出力上限から来ます。ここを混同すると、原因に対して弱い修正しか打てません。
平均値だけでは安全と判断できない点にも注意が必要です。minute average では余裕があっても、短い quantized window で limit に当たることがあります。
変更前に response を読む
Cookbook でも rate-limit guide でも、まず response を読む習慣が推されています。failed retry も budget を消費するため、何も見ずに再送すると incident が長引きます。
確認したい headers は次のとおりです。
- x-ratelimit-limit-requests
- x-ratelimit-remaining-requests
- x-ratelimit-reset-requests
- x-ratelimit-limit-tokens
- x-ratelimit-remaining-tokens
- x-ratelimit-reset-tokens

この情報から、最初の分岐をかなり絞れます。
| Signal | ふつう何を示すか | 最初の行動 |
|---|---|---|
| remaining-requests がほぼ 0 | request frequency や並列数が高すぎる | concurrency を下げて burst をならす |
| remaining-tokens がほぼ 0 | prompt と output が重すぎる | token budget を削る |
| reset が短い | route 自体は正しく、窓待ちが必要 | reset 後に jitter をつけて再試行 |
| Limits ページの余力が低い | account や route ceiling が狭い | 先に最適化、必要なら増枠判断 |
| headers は普通なのに失敗 | scope、billing、wrapper、endpoint の可能性 | project、org、model、surface を確認 |
request ごとに status、error body、endpoint、model、project context、x-ratelimit 値を記録しておくと、あとで比較できる incident evidence になります。
最小の分類コードは次のように書けます。
tsconst resetRequests = res.headers.get("x-ratelimit-reset-requests"); const resetTokens = res.headers.get("x-ratelimit-reset-tokens"); const remainingRequests = res.headers.get("x-ratelimit-remaining-requests"); const remainingTokens = res.headers.get("x-ratelimit-remaining-tokens"); const owner = remainingRequests === "0" ? "requests" : remainingTokens === "0" ? "tokens" : "unknown"; // request と token の両方が絡むときは、より遅い reset を採用する。
大切なのはコードの美しさより、誤った branch を選ばないことです。
429 を owner ごとに分ける
1. Request-rate owner
もっとも典型的なのは burst です。request 数、並列数、retry loop が route の現在の余力を超えています。billing ではなく traffic shape を直すべきケースです。
2. Token-rate owner
request 数は多くなくても、各 request が重すぎれば TPM から先に止まります。長い履歴、過大な system prompt、現実とかけ離れた output 上限が原因になりやすいです。
3. Quota または billing owner
この owner では backoff は本質的な解決になりません。使える quota がない、billing が unhealthy、trial が切れているなら、見るべきは account state です。credits や trial 境界が問題なら OpenAI API free trial に分けて確認するのが正しいです。
4. Project、organization、model scope owner
request は syntactically valid でも、route が違えば limit behavior は変わります。環境間で config を流用した結果、scope が違っていたというのは珍しくありません。
5. Wrong product surface owner
ChatGPT、Codex、wrapper の制限と Platform API throughput は同じではありません。ChatGPT のアップグレードで API 429 が直るとは限らず、Codex の使用窓も API の limit そのものではありません。
最小の修正から traffic を整える
owner が見えたら、最初は小さく直します。OpenAI の公開ガイドが一貫して勧めているのは bounded backoff with jitter です。
一般的な順序は次のとおりです。
- route が正しければ、まず reset を待つ。
- burst が原因なら concurrency を下げる。
- exponential backoff と jitter を入れる。
- token pressure なら prompt と output を削る。
- 非同期でよい仕事は queue や Batch API に移す。
- それでも必要なときだけ higher limits を考える。
retry path は失敗するほど静かになるべきです。最低限の形は次のとおりです。
tsconst base = 500; // ms const max = 15000; for (let attempt = 0; attempt < 6; attempt += 1) { const wait = Math.min(max, base * 2 ** attempt); const jitter = Math.random() * 0.25 * wait; await sleep(wait + jitter); }
TPM 側の問題では token trimming がもっとも安い修正になることが多いです。max output を現実に合わせ、履歴を短くし、不要な context を外します。workload が即時でなくてよいなら Batch API や queue に移したほうが素直です。
増枠は安定した証拠のあと
多くのチームは higher limits を考えるタイミングが早すぎます。これでは architecture issue を隠してしまいます。
増枠を考えてよい条件は少なくとも次のとおりです。
- route が正しい。
- billing が健全。
- owner が分かっている。
- retry がすでに bounded。
- prompt と output の budget が妥当。
- それでも sustained capacity が足りない。
その段階で usage tier や limit increase request が意味を持ちます。request 前には model、endpoint、request/token pressure、reset の様子、concurrency profile、すでに行った最適化、Batch API で足りない理由をまとめておくとよいです。
Stop rules
以下は日本語の実務でも特にやりがちな誤修正です。

- key rotation を先にしない。同じ account や route が owner なら意味が薄い。
- throughput を見ずに credits を足さない。quota や billing には効いても RPM/TPM は自動で増えない。
- ChatGPT や Codex のプラン変更を API 修復策にしない。
- 古い表の正確な数値を current truth として扱わない。
- blind retry をしない。失敗した retry も budget を使う。
次の表で判断するとぶれにくくなります。
| 問題の owner | 次にやること |
|---|---|
| Request burst | parallelism を下げて jitter を入れる |
| Token pressure | prompt と output size を削る |
| 短い reset window | 待ってから安全に再試行する |
| Billing や quota | account state を直す |
| Project / model scope | route と scope を修正する |
| API 以外の surface | その surface 専用の runbook に移る |
FAQ
OpenAI API の 429 は何を意味しますか?
request、token、quota、billing、scope、reset-window のどれかの境界に当たっているという意味です。まず分類問題として扱います。
正確な現在の limit はどこで見ますか?
アカウントの Limits ページです。公開ドキュメントは定義や header 名を教えますが、live ceiling は自分のアカウント画面が持っています。
credits を足せば throughput も上がりますか?
いいえ。credits が効くのは quota や billing owner のケースです。request-rate や token-rate ceiling を自動で上げるわけではありません。
ChatGPT Plus や Codex の契約で Platform API 429 は直りますか?
直りません。consumer products と Platform API は別の契約です。
Batch API はいつ有効ですか?
仕事が即時でなくてよいときです。リアルタイムで返さなくてよい処理を synchronous path に残さないほうが安定します。
higher limits はいつ頼むべきですか?
route、billing、retry、token budget が整い、それでも sustained capacity が足りないときです。
実務上の結論
OpenAI API の 429 を速く直す方法は、retry を増やすことでも、何かを先に upgrade することでもありません。owner を見て、reset を見て、最小の修正を選ぶことです。request の問題なら burst をならし、token の問題なら payload を削り、billing や quota なら account state を直し、scope の問題なら正しい project、organization、model、endpoint に戻ります。非同期でよい仕事なら synchronous path から外す。この順番が一番ぶれません。