2026年5月4日時点では、DeepSeek V4 Pro、Claude Opus 4.7、GPT-5.5は一つの勝者を決める比較ではありません。OpenAIネイティブのcoding、Codex、tool workflowならGPT-5.5を最初に試す。正確性が重いagentやcloud/API deploymentならClaude Opus 4.7をpremium controlに置く。DeepSeek V4 Proは、コスト、open-weight運用、長いコンテキストの大量実験が十分に重要なときだけ、同じタスクで検証するpilotとして扱います。
安全な初期判断は、名前ではなく検証できるルートを選ぶことです。GPT-5.5はOpenAIアカウント、tool surface、structured output、Codexに近い。Opus 4.7は失敗コストが高い作業の基準線になる。DeepSeek V4 Proは割引、互換URL、open-weight model cardが魅力ですが、それだけでproduction defaultを置き換える理由にはなりません。
| 必要なルート | 最初に試すモデル | 合う理由 | 停止基準 |
|---|---|---|---|
| OpenAIネイティブcoding、Codex、tool-heavy API、structured output | GPT-5.5 | OpenAI developer docsはGPT-5.5、1M context、128K max outputを示しており、OpenAI stackで最も素直に試せる。 | production trafficの前にaccount access、limits、console behavior、古いHelp Center noteとの矛盾を再確認する。 |
| correctness-sensitive agents、cloud/API deployment、premium control | Claude Opus 4.7 | AnthropicはOpus 4.7をcoding、agents、tools、vision、cloud deploymentに位置付けている。 | defect、review time、rollback riskが下がらないならpremium costを承認しない。 |
| cost-sensitive pilots、open-weight governance、大量long-context tests | DeepSeek V4 Pro | DeepSeek docsはV4 Pro discount、compatible URLs、1M context、384K max outputを示している。 | route fidelity、quality、latency、rollbackが通るまでpilotに留める。 |
| production defaultの変更 | dual-run first | 公開benchmarkと価格差は自分たちのfailure modesを測らない。 | 同じprompts、tools、files、budgets、acceptance tests、rollback thresholdなしに切り替えない。 |
呼び出せる契約から始める
実務の比較はroute ownerから始まります。GPT-5.5のmodel/API factsはOpenAIが持つ。Claude Opus 4.7のavailabilityとpriceはAnthropicが持つ。DeepSeek V4 ProのAPI、discount、open-weight routeはDeepSeek docsとmodel cardが持つ。レビュー動画や集計表は問いを作る材料になりますが、model labels、prices、endpoint behavior、context windows、discount windowsを決める根拠にはできません。

| 契約項目 | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 Pro |
|---|---|---|---|
| 主要ルート | OpenAI developer platformとOpenAI-native product/tool routes | Anthropic API、Claude products、major cloud partners | DeepSeek APIとofficial open-weight model card |
| 確認すべきmodel label | OpenAI docsはGPT-5.5、GPT-5.5 Chat、GPT-5.5 Thinking、dated variantsを列挙 | deployment前にAnthropic docsまたはconsoleでcurrent model IDを確認 | DeepSeek API docsはdeepseek-v4-proを列挙 |
| contextとoutput | OpenAI docsは1M context、128K max outputを示す | AnthropicはOpus 4.7をlong-contextかつdemanding agent workに置くが、routeごとのlimitsは確認が必要 | DeepSeek docsは1M context、384K max outputを示す |
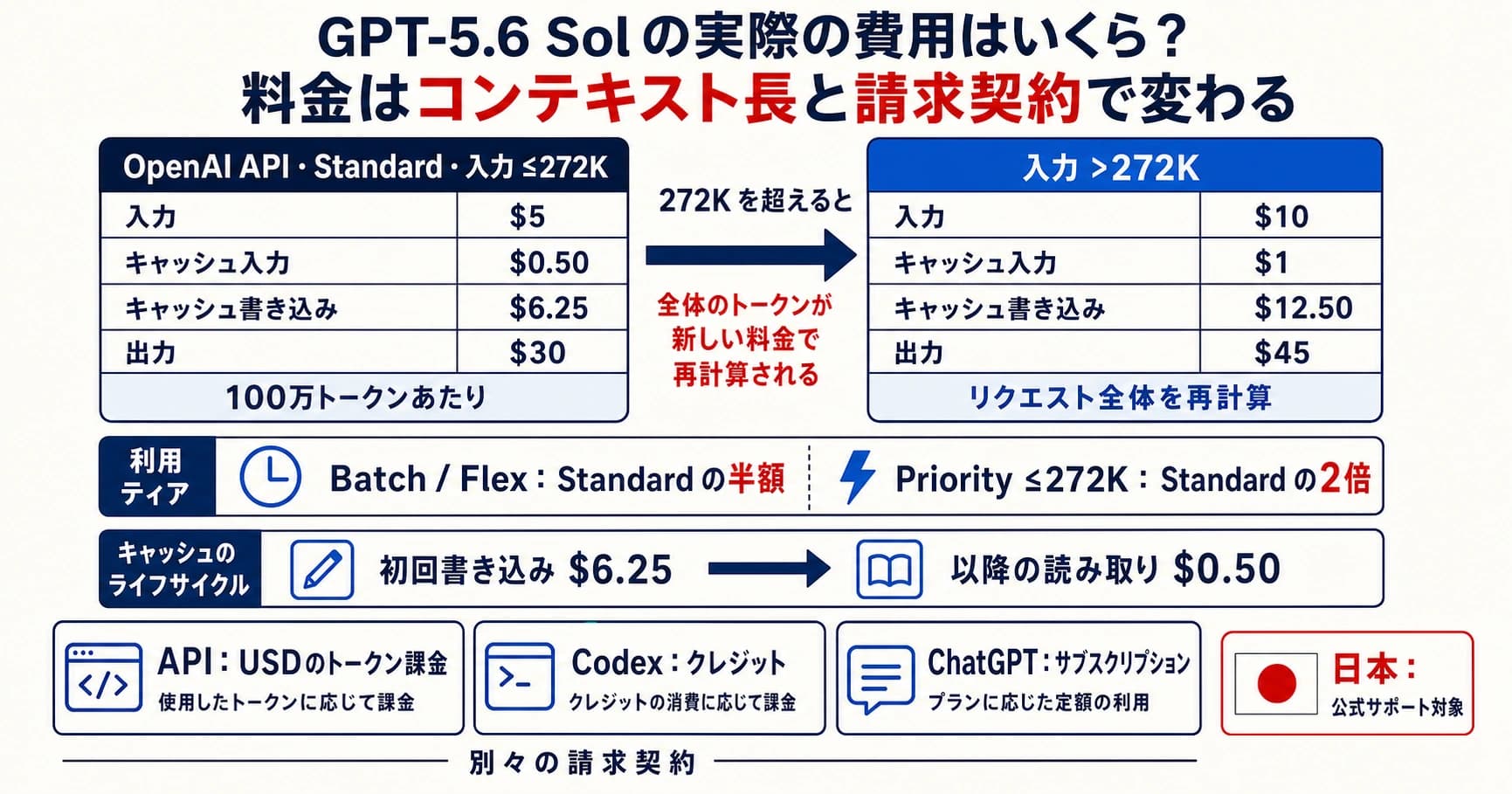
| 価格の所有者 | OpenAI docsはstandard short-context API rowでmillion tokensあたりinput 5ドル、cached input 0.50ドル、output 30ドルを示す | Anthropic launch materialはinput 5ドル、output 25ドルを示す | DeepSeek docsは2026-05-31までのdiscountとしてcache-hit input 0.145ドル、cache-miss input 0.435ドル、output 0.87ドルを示す |
| 残すべき境界 | 古いOpenAI Help Center rollout noteはその日にGPT-5.5 APIを出さないと書いていた一方、現在のdeveloper docsはGPT-5.5を列挙している。production前に現行環境で確認する。 | premium costはdefect、review time、rollout riskの低下でしか正当化できない。 | compatible URLはOpenAIやAnthropic routeとのbehavior parityを証明しない。 |
OpenAI model docsとmodel comparison pageがGPT-5.5のAPI contractを決めます。古いHelp Center rollout noteも無視できません。ChatGPT/Codex rolloutを説明し、その日にGPT-5.5はAPIへ出ないと書いていたため、現在のdeveloper docsとの日付付きの差分が残ります。paid trafficを流す前に、自分のorganizationでmodel visibility、quota、limits、actual callを確認してください。
AnthropicのClaude Opus 4.7 launch pageはClaude products、Anthropic API、Amazon Bedrock、Google Vertex AI、Microsoft Foundryでのavailabilityと、million tokensあたりinput 5ドル、output 25ドルの価格を示します。DeepSeek pricing docsはV4 Pro pricing、OpenAI-compatible/Anthropic-format URLs、1M context、384K max output、temporary discount windowを示します。DeepSeek model cardはopen-weight側として1.6T total parameters、49B activated、1M contextを補足します。
用途ごとにモデルを分ける
DeepSeek V4 Pro、Claude Opus 4.7、GPT-5.5をきれいに比較するには、実際に走らせる仕事へ落とします。OpenAI-native tool loopで強いmodelが、deployable multi-tool agentの最安全controlとは限りません。million tokensあたりの価格が安くても、retry、defect、review loadが増えれば完了タスクは高くなります。

| Workload | 最初に試すモデル | 理由 | 測るもの |
|---|---|---|---|
| OpenAI-native coding、Codex、Responses API tools、structured outputs | GPT-5.5 | OpenAI tool surfaceとaccount controlsに最も近い。 | accepted diffs、tool recovery、format stability、review time、token cost。 |
| correctness-sensitive coding agents、multi-step orchestration | Claude Opus 4.7 | failure costがmodel costより高いときのpremium control。 | defect severity、tool-call reliability、rollback behavior、reviewer trust。 |
| high-volume retries、batch exploration、cheap long-context tests | DeepSeek V4 Pro | temporary discountとopen-weight routeがcost pilotに向く。 | task success rate、retry rate、latency under load、route fidelity。 |
| repo、document、evidence analysisのlong-context work | route-specific test | 3つのrouteが異なる形でlarge contextを持つ。 | truncation、recall quality、output length、full prompt cost。 |
| self-host、private cloud、open-weight governance | DeepSeek V4 Pro | GPT-5.5とOpusはclosed hosted routesで、DeepSeekはopen-weight pathを持つ。 | deployment complexity、security review、inference cost、maintenance burden。 |
| existing production default | dual-run | 既存defaultには既知のfailure modesと運用履歴がある。 | regression count、total cost、human minutes、fallback success。 |
OpenAI-native developmentではGPT-5.5を先に置く価値があります。Codex、OpenAI tools、structured outputs、file handling、account policyに近いため、観測がしやすいからです。これはすべてのAPI workflowでproduction defaultにする意味ではありません。OpenAI stackに深く依存している場面で、最初の検証コストが低いという意味です。
premium reliabilityではClaude Opus 4.7がcontrol laneです。multi-tool orchestration、複雑なcode changes、vision/document review、conservative rolloutでは、model costよりfailure costが高くなります。Opusのpilotが高く見えても、serious defectsとsenior review minutesを減らすなら合理的です。
costとopen-weightの圧力ではDeepSeek V4 Proをpilotに入れます。discountは試す価値があり、compatible endpointsは接続を軽くし、model cardはgovernance teamに重要です。ただしそれはtool errors、JSON stability、long-context recall、SDK edge casesで同じ挙動をする証拠ではありません。
価格は判断材料であって結論ではない
DeepSeek V4 Proのprice advantageは強く見えます。DeepSeek docsは2026年5月31日15:59 UTCまで、V4 Pro discountとしてmillion tokensあたりcache-hit input 0.145ドル、cache-miss input 0.435ドル、output 0.87ドルを示します。list priceは0.58、1.74、3.48ドルです。discount中に始めたpilotは、window後に違う経済性になります。
GPT-5.5はOpenAI comparison table上ではbudget modelではありません。standard short-context API rowではmillion tokensあたりinput 5ドル、cached input 0.50ドル、output 30ドルです。long-context pricingは別のroute rowとして再確認し、このstandard rowと混ぜてはいけません。Claude Opus 4.7はAnthropic launch materialでinput 5ドル、output 25ドルです。raw hosted API priceではDeepSeekが大きく安く、Claudeはpremium control、GPT-5.5は高価なOpenAI-native frontier routeになります。
それでも価格表だけでdeploymentを決めてはいけません。安いmodelがretryを増やし、structured outputを壊し、manual reviewを増やし、別のserving stackを必要にするなら高くなります。高いmodelがhuman review minutesとfailed generationsを削るなら、completed jobでは安くなることがあります。
| Cost variable | なぜ重要か |
|---|---|
| inputとcached input | long prompts、repeated context、cache behaviorで順位が変わる。 |
| output length | GPT-5.5のoutput priceとDeepSeekの384K max outputはlong generation economicsに別々の影響を持つ。 |
| retry rate | token単価が安くてもattempt数が増えると負ける。 |
| human review time | codingやagent workで最も高いのは、結果を読むsenior engineerであることが多い。 |
予算判断では、representative tasksに同じprompts、files、tools、permissions、budgetを入れます。input、cached input、output、retries、task-level cost、p95 latency、review minutesを同じ表に記録します。DeepSeekがその後も安いなら拡張候補です。OpusやGPT-5.5がreviewとrollbackを減らすなら高価格でも正当化できます。
Benchmarkを読みすぎない
公開benchmarkは、workloadが似ているときだけ有用です。coding-agent rows、terminal-task evaluations、browsing/research scores、long-context tests、math/security benchmarksは別の能力を測っています。GPT-5.5がOpenAI-native benchmarkで強いなら、そのrouteで試す理由になります。DeepSeek V4 Proがcost pilotになれない証拠でも、Opus 4.7がpremium controlでなくなった証拠でもありません。
逆も同じです。DeepSeekのprice/performance claimはpilot harnessを作る理由です。high-risk agentのproduction replacementを証明しません。Anthropicのlaunch claimはOpusをcontrol laneに入れる理由です。すべてのタスクでpremiumを払うべき証拠ではありません。
証拠の順番は固定します。
- official docsがroute exists、model label、price、limitsを決める。
- provider or third-party benchmarksが、試すべきworkloadsを示す。
- same-task harnessがdefault候補かを決める。
- production rolloutがreal traffic、permissions、latency、failuresで改善が残るかを確認する。
この順番はcompatible endpointの誤解も防ぎます。DeepSeekはOpenAI-compatibleとAnthropic-format API URLsを提供しますが、URL shapeはbehavior parityではありません。tool calling、streaming、timeouts、tokenization、output format、safety behavior、retries、SDK edge casesは異なり得ます。compatibilityは開始コストを下げるだけで、validationを不要にしません。
切り替え前に同一タスクで試す
実務pilotは小さくて構いません。ただしproduction conversationに耐えるだけの公平さが必要です。あるmodelだけに良いprompt、広いbudget、簡単なtaskを渡してはいけません。candidateは同じprompts、tools、files、budgets、acceptance testsで測ります。

| Pilot gate | すること | Pass condition |
|---|---|---|
| Route check | model label、endpoint、account access、region、quota、fallbackを確認。 | deploy予定のrouteをteamが呼び出せる。 |
| Same prompt and tools | system prompt、files、tools、permissions、task budgetを可能な限り揃える。 | 差分がharnessではなくmodel behaviorから出る。 |
| Representative tasks | easy、hard、long-context、output-format、failure-prone tasksを入れる。 | sampleが実際にcostやreview timeを生む仕事に近い。 |
| Defect scoring | correctness、severity、security risk、recovery effortを分類する。 | candidateがhigh-severity failuresを減らす。 |
| Review-time scoring | human review minutesとaccepted-result rateを数える。 | candidateがtotal workを減らす。 |
| Cost and latency | input、cached input、output、retries、task-level cost、p95 latencyを測る。 | savingsがfull-task accountingで残る。 |
| Rollback threshold | failure rate、latency、costでfallbackを発火する条件を決める。 | old routeへsystem rebuildなしで戻せる。 |
既にGPT-5.4、Opus 4.7、別の安定defaultを持つteamは、「新modelがすごい」より高い基準を置きます。current defaultを残し、candidateをshadow-runし、total workが減り、regressionが許容範囲に入り、rollback pathがあるときだけtrafficを増やします。
初めてrouteを選ぶteamは、high-risk tasksでGPT-5.5とOpus 4.7を先に走らせ、costやopen weightsが重要なところにDeepSeek V4 Proを追加します。DeepSeekが同じtasksを通るなら、特定workloadのdefault候補になります。manual repairが必要な失敗をするならexploration laneに留めます。
隣接する判断
DeepSeek V4 Pro、Claude Opus 4.7、GPT-5.5の三者比較は、最初に試すroute、control lane、production switch ruleを決めるためのものです。より狭い選択や広いroute poolは別に分けた方が安全です。
OpenAIとAnthropicだけの選択なら、GPT-5.5 vs Claude Opus 4.7を使います。OpenAI-native testingとAnthropic deployabilityに集中できます。
Kimiも含めた安価なroute poolなら、Kimi K2.6 vs DeepSeek V4 vs GPT-5.5 vs Claude Opus 4.7が担当します。四者のallocation problemは独立した判断です。
前世代のofficial frontier API routesを比較するなら、Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Proを使います。DeepSeekのrelease背景とroute背景が必要なら、DeepSeek V4から始めます。
よくある質問
GPT-5.5はClaude Opus 4.7やDeepSeek V4 Proより良いのか?
OpenAI-native work、特にcoding、tool workflows、Codex、structured outputではGPT-5.5を最初に試す価値があります。ただし普遍的なwinnerではありません。Claude Opus 4.7はpremium controlであり、DeepSeek V4 Proはcost/open-weight pilotとして検証します。
DeepSeek V4 Proは安いのか?
現在のdocumented API discountでは安いです。ただしdiscount windowには終了日があり、list priceと分けて見る必要があります。completed-task costはquality、retries、latency、review timeで変わります。
coding agentsにはClaude Opus 4.7を使うべきか?
correctness-sensitiveで、Anthropicまたはcloud routesでdeployでき、reviewやrollbackが高い場合はClaude Opus 4.7を先にcontrolにします。OpenAI-native workはGPT-5.5を先に試します。costやopen weightsが重要ならDeepSeek V4 Proをpilotに入れます。
DeepSeek V4 ProはClaude Opus 4.7を置き換えられるか?
同一タスクpilotで証明した後だけです。DeepSeek V4 Proはhigh-volumeやopen-weight workの候補になりますが、priceとcompatible endpointsだけでproduction replacementは証明できません。
GPT-5.5はAPIで使えるのか?
現在のOpenAI developer docsはGPT-5.5 model entriesとAPI price/context detailsを列挙しています。一方、古いHelp Center rollout noteはその日にGPT-5.5 APIを出さないと書いていました。production traffic前にcurrent docs、account access、limits、console behaviorを確認してください。
long-context workでは何を先に試すべきか?
deployment needに合うrouteを試します。OpenAIとDeepSeek docsはrelevant routesで1M contextを示し、AnthropicはOpus 4.7をdemanding long-context agent workに置いています。実タスクでtruncation、recall、output length、latency、full-task costを測ります。
最も安全なproduction switch ruleは?
public benchmarks、price gaps、launch excitementだけでdefaultを切り替えないことです。同じprompts、tools、files、task budgets、acceptance testsでdual-runします。total workが減り、rollback pathがあるときだけpromoteします。
結論はroute planです。GPT-5.5はOpenAI-native first tests、Claude Opus 4.7はpremium deployable control、DeepSeek V4 Proはcostまたはopen-weight pilots。同じタスクで資格を得たmodelだけがproduction defaultになります。