
まず安くコーディングエージェントを試したいなら GPT-5.3-Codex から始めるのが自然です。逆に、コストの中心がトークン単価ではなく、長いタスクの流れや大きなリポジトリ文脈、あるいは弱い初回出力が生む大きな手戻りにあるなら、Claude Opus 4.6 を先に試すほうが合理的です。これが 2026 年 4 月 3 日 時点での実務的な答えです。
ただし、表を見る前に一つだけ整理しておくべき点があります。GPT-5.3-Codex は今も現役の OpenAI モデルですが、現在の Codex 製品全体をそのまま代表する名前ではなくなっています。OpenAI は 2026 年 3 月 5 日 に Codex へ GPT-5.4 を導入し、さらに 2026 年 3 月 17 日 には、大きいモデルが計画と最終判断を担い、GPT-5.4 mini がより細かな補助作業を受け持つ構成を説明しました。つまり、ここで比べるのは Claude Opus 4.6 と GPT-5.3-Codex という二つのモデルであって、現在の Codex 製品全体ではありません。知りたいことが製品選びなら、次は OpenAI Codex 2026年3月アップデート と Claude Code vs Codex を読むほうが正確です。
| もし詰まりどころがこう見えるなら | 先に試すべきモデル | 理由 |
|---|---|---|
| 安く回せるターミナル中心のコーディング作業 | GPT-5.3-Codex | 公式 API 価格が低く、OpenAI 側の公開ベンチマーク根拠もより揃っている |
| リポジトリ規模の長い実行タスク | Claude Opus 4.6 | 1M コンテキストと 128k 出力があり、やり直しが高くつく仕事に向いている |
| どちらの段階も同じシステムにある | 両方を使い分ける | まず GPT-5.3-Codex で軽く試し、文脈や手戻りコストが重くなったら Opus に切り替える |
根拠の前提: 本文は OpenAI と Anthropic の現行公式ページを 2026 年 4 月 3 日 に再確認して作成しています。公開ベンチマークの出し方は対称ではありません。OpenAI は GPT-5.3-Codex 向けに詳しい付録を出しており、Anthropic は Opus 4.6 向けにもう少し絞った公開指標を示しています。以下は「完全に対称な点数表」ではなく、どちらから先に試すべきかを判断するための材料として読むべきです。
まず比較対象をはっきりさせる
この比較が意味を持つのは、比較対象を正確に保つときだけです。GPT-5.3-Codex は 2026 年 2 月 5 日に登場し、OpenAI の現行 API 文書でも現役のコーディングモデルとして掲載され、価格、reasoning effort、利用可能エンドポイント、400,000-token のコンテキスト、128,000-token の最大出力が明記されています。したがって、このモデル名は今も有効であり、Claude Opus 4.6 と直接比べる価値があります。
変わったのは、その外側にある Codex の説明です。OpenAI の現行モデルページでは GPT-5.4 が agentic、coding、専門的な作業向けの主力ファミリーとして扱われ、2026 年 3 月 17 日 の GPT-5.4 mini 記事では、大きいモデルが計画と最終判断を担い、小さいモデルが補助作業を分担する Codex の構成が描かれています。これは GPT-5.3-Codex が消えたという話ではなく、「Codex」と言うときに多くの読者がすでに別のレイヤーの話も混ぜている、という意味です。
この違いが大事なのは、モデル選びと製品選びでは失敗の仕方が違うからです。モデル比較が答えるべきなのは、どのモデルを先に試すべきか。製品比較が答えるべきなのは、どのツールや使い方を採るべきかです。このページはあえてモデルの話に絞ることで、より役に立つ問いに答えます。今のコーディング環境で、どちらを先に試すべきか。
まず押さえたい違い
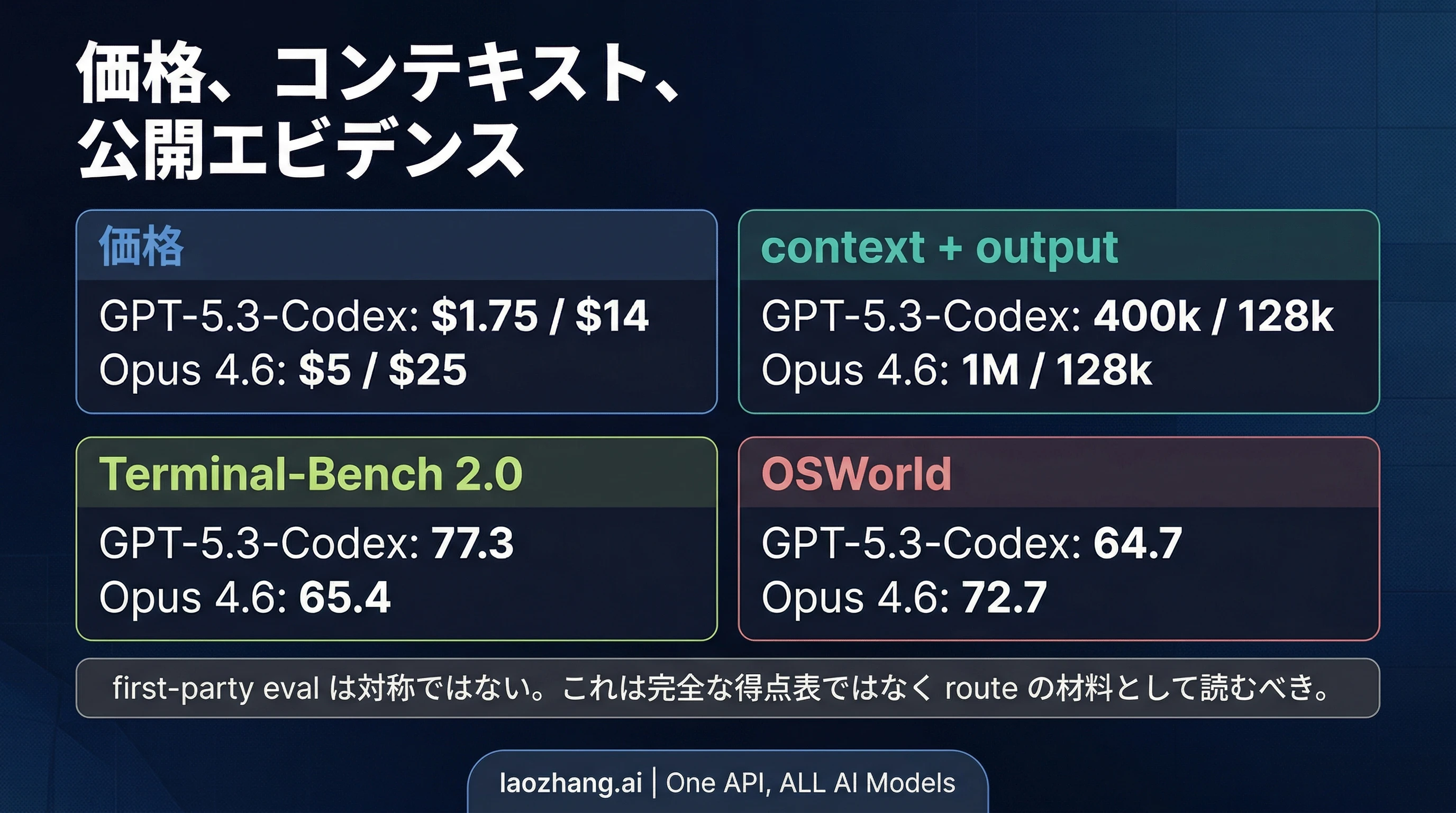
ここで見るべきなのは「どちらが何項目勝っているか」ではなく、どの差が実際の失敗コストに効くかです。GPT-5.3-Codex は何度も試しやすい価格帯にあり、Claude Opus 4.6 は高くつく失敗を減らす側のモデルとして読むと全体像がつかみやすくなります。
| 項目 | GPT-5.3-Codex | Claude Opus 4.6 | 実際の読み方 |
|---|---|---|---|
| 公式 API 価格 | $1.75 input / $14 output / 1M tokens | $5 input / $25 output / 1M tokens | GPT-5.3-Codex は高頻度の試行を回しやすい |
| Cached input | $0.175 / 1M tokens | Anthropic はキャッシュ条件を別の文脈で示す | OpenAI のほうが繰り返し評価を安く回しやすい |
| Context window | 400k | 1M | Opus はより大きいリポジトリや仕様書を一度に抱えやすい |
| 最大出力 | 128k | 128k | 出力上限そのものは最大の差ではない |
| Public Terminal-Bench 2.0 | 77.3 | 65.4 | OpenAI は低コスト側の公開根拠をより強く出している |
| Public OSWorld | 64.7 | 72.7 | Anthropic は長い実行タスクに関する公開根拠が強い |
この表から見えてくるのは、GPT-5.3-Codex は安く何度も試す側、Claude Opus 4.6 は高い失敗を減らす側という分担です。OpenAI の数値は 2026 年 2 月 5 日 の付録に基づき、xhigh reasoning effort 条件で出されたものです。一方 Anthropic の公開材料はもう少し絞られていますが、Terminal-Bench 2.0 の 65.4%、OSWorld の 72.7%、1M context を提示しており、長い実行や大きな文脈が重要な仕事に向いた位置づけは明確です。ここから先に試す順番は決められますが、どちらかを「万能の勝者」と呼ぶには十分ではありません。
GPT-5.3-Codex を先に試しやすい場面
結論: 「より安い価格で、ターミナル中心の反復作業をどこまで回せるか」を見たいなら、GPT-5.3-Codex のほうが先に試しやすいモデルです。
根拠: OpenAI の現行モデルページでは、GPT-5.3-Codex に $1.75 / $14 per million tokens、$0.175 の cached input、400k context、128k output、調整可能な reasoning effort が示されています。付録には Terminal-Bench 2.0 の 77.3% と OSWorld-Verified の 64.7% もあり、OpenAI 側の公開材料は比較的揃っています。
判断: コーディングエージェントの限界をまだ探っていて、反復や再試行、評価実行が多くなりそうなら、まず GPT-5.3-Codex から試すべきです。
この判断の軸は、単なる順位ではなく経済性です。ターミナルでの反復、パッチの試行、ツール呼び出し、自己修正が多いシステムでは、最初に膨らむのは巨大コンテキストのコストよりも試行回数そのものです。そういう環境では、GPT-5.3-Codex は「この作業にどこまでのモデルが必要か」を安く見極めるための入り口になります。失敗しても学習コストが安く済み、十分にこなせるならパイプライン全体で Opus の単価を払う必要はありません。
もう一つの強みは、OpenAI がターミナル中心の作業に対して比較的はっきりした公開材料を出していることです。単に「コーディングに強い」と言われるより、価格、コンテキスト、ベンチマークがまとまって見えるほうが、最初の検証対象としては扱いやすい。まだ運用の輪郭を探っている段階なら、この読み方で十分価値があります。
Claude Opus 4.6 を先に試すべき場面
結論: 本当の問題がトークン単価ではなく、長い文脈や長い手順、一度の失敗が大きなやり直しにつながることにあるなら、Claude Opus 4.6 のほうを先に試す価値があります。
根拠: Anthropic の現行ドキュメントでは、Opus 4.6 に $5 / $25 per million tokens、1M context、128k max output が示されています。公開ページでは Terminal-Bench 2.0 の 65.4%、OSWorld の 72.7% も挙げられており、長い実行やエージェント的な作業に向けた位置づけが明確です。
判断: 大きなリポジトリや多段の作業で、最初の出来が悪いと手戻りコストが大きいなら、Claude Opus 4.6 を先に試すべきです。

Opus を選ぶ理由は、単に「より賢いから」ではありません。より正確に言えば、ある種の仕事では、文脈を落とすこと、途中で筋を見失うこと、レビューに耐えない浅い出力を出すことがそのまま高いコストになります。大きなリポジトリを読み、長い設計資料や運用資料を保持し、まとまった成果物を一度に出したいなら、1M のコンテキストと 128k の出力 は仕事の形そのものを変えます。
ここでは価格が請求額のすべてではありません。単価が高いモデルでも、再試行やレビュー時間、あとから壊れる半端な出力を減らせるなら、全体としては安くつくことがあります。Anthropic の公開材料は、まさにその読み方に沿っています。OpenAI の付録ほど整った比較表ではなくても、Opus 4.6 を「長い仕事に強い高価格モデル」として見る根拠には十分です。
多くのチームが実際に試すべき二段階構成
2026 年のいちばん正直な答えは、ひとつの永久的な勝者ではなく、明確な使い分けのルールです。
まず GPT-5.3-Codex を、安く何度も試せるコーディングエージェント作業に置きます。ターミナル中心の反復、広い評価バッチ、まだ失敗の形を探っている初期の自動化がここに当たります。そのうえで、仕事が大きなリポジトリ全体を抱えたり、長い多段処理になったり、一度の失敗が高い手戻りを生む段階に入ったら、Claude Opus 4.6 に切り替える。これは「どちらも良い」という曖昧な結論ではなく、かなり具体的な二段階構成です。

大事なのは切り替えの基準です。まだ比較的狭い指示で、主な関心が価格に敏感な評価回数にあるなら、GPT-5.3-Codex に任せておけばいい。一方で、文脈が膨らみ、再試行が増え、出力そのものが価値ある成果物になってくるなら、Opus に切り替えるべきです。この判断はトークン単価ではなく、再試行コストと手戻りコストで見るほうが現実に近いです。定価だけを見ていると、弱い初回出力が生む本当のコストを見落とします。
ここで初めて製品の話が実用的になります。OpenAI と Anthropic の両方を同時に使う前提なら、laozhang.ai のような統合ゲートウェイは、請求や認証、モデルの切り替えを別々に抱える手間を減らせます。ここで触れる理由は単純で、この比較のいちばん現実的な答えは多くの場合「両方を役割分担で使うこと」だからです。
より大きな結論は、モデル選びは作業の段階に合わせるべきだということです。安く試す段階のモデルと、本番寄りの重い実行に向いたモデルは、同じコーディング環境の中で無理なく共存できます。2026 年には、そのほうが単一の前線モデルに全部背負わせるより現実的なことが少なくありません。
本当に知りたいのが今の Codex なら
「GPT-5.3-Codex」と検索する人の中には、実際には別の問いを抱えている人もいます。今の Codex はどういう製品なのか。 ただ、その問いにこのページが広く踏み込みすぎるべきではありません。OpenAI の現在の Codex はすでに GPT-5.4 時代の構成に寄っており、app、CLI、IDE、cloud、そして大きいモデルと小さいモデルの役割分担が中心になっています。だからこそ GPT-5.3-Codex はここで有効な比較対象であり続ける一方で、製品全体の答えそのものではなくなっています。
実用的な案内はシンプルです。選んでいるのが モデル なら、このページに残って上の使い分けをそのまま使ってください。選んでいるのが 製品やワークフロー なら、次に読むべきは OpenAI Codex 2026年3月アップデート です。Anthropic のツール系と OpenAI のツール系をどう比べるかが本題なら Claude Code vs Codex を読むほうが適切です。さらに Anthropic 側で役割分担やコスト設計が気になるなら、Claude 4.6 Agent Teams guide と Opus pricing guide が次の一歩になります。
結論
一文でまとめるならこうです。まず安くコーディングエージェントを試したいなら GPT-5.3-Codex。長いタスクで、コンテキストの深さや実行の安定性、出力規模のほうがトークン単価より重いなら Claude Opus 4.6。 そして自分のシステムにその両方の段階があるなら、万能の勝者を探すより、役割を分けて使ったほうが実務的です。