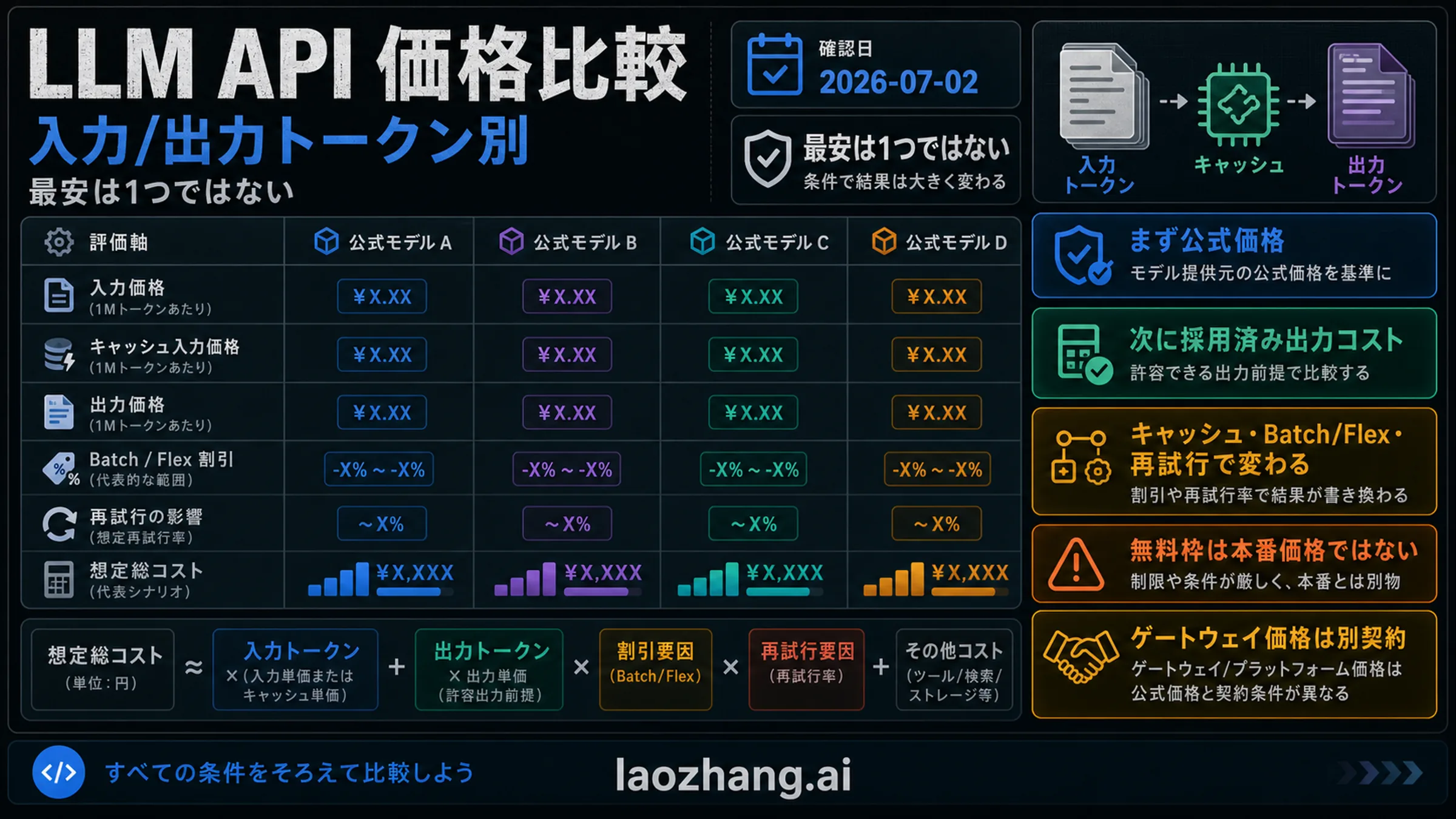
最安の LLM API モデルは、ひとつの名前で固定できません。実際には、あなたの入力量、出力量、キャッシュ率、品質基準、レイテンシ、データ条件を満たしたうえで、採用済み出力あたりの総コストが最も低いモデルです。2026年7月2日の確認では、まず公式のモデル所有者ページを価格の起点にし、その後で Batch/Flex、無料枠、再試行、ツール呼び出し、ゲートウェイ契約を足して判断します。
| ワークロード | 最初に試す低価格レーン | 公式価格アンカー | 最安でなくなる条件 |
|---|---|---|---|
| 大量抽出、短い回答、キャッシュ多用 | deepseek-v4-flash | cache-hit input $0.0028、cache-miss input $0.14、output $0.28 / 1M tokens | 品質、地域、遅延、可用性が不足するとき |
| OpenAI 互換の低価格 API | gpt-5-nano | $0.05 input、$0.005 cached input、$0.40 output。Batch/Flex はさらに低い | 出力が長い、ツール呼び出しが多い、再試行が多いとき |
| Google の最低 scale lane | gemini-2.5-flash-lite | $0.10 input、$0.40 output。Batch/Flex $0.05 / $0.20 | 3.1 系の新機能や品質が必要なとき |
| Google の新しい高頻度 lane | gemini-3.1-flash-lite | $0.25 input、$1.50 output。Batch/Flex $0.125 / $0.75 | Google 内で最安 row だけを探すとき |
| 安いモデルが品質基準を満たさない | Claude Haiku 4.5 | $1 input、$5 output / MTok | 低価格モデルがすでに合格するとき |
停止ルール:入力価格だけで選ばないでください。同じ実プロンプトで入力、キャッシュ入力、出力、ツール、再試行、無料枠、契約境界を測り、採用済み出力コストで比較します。
まず公式価格表を見る
公式ページは、モデル ID、課金単位、現在価格、割引モード、可用性を確認する第一証拠です。価格比較サイトは候補探しには便利ですが、その行を公式価格として引用してはいけません。公式価格、provider 価格、gateway 価格はそれぞれ別の契約です。
OpenAI pricing では gpt-5-nano が $0.05 input、$0.005 cached input、$0.40 output per 1M tokens として掲載されています。Google pricing では gemini-2.5-flash-lite が Google の低価格 scale lane で、gemini-3.1-flash-lite は新しいが高い lane です。DeepSeek pricing は deepseek-v4-flash の cache-hit、cache-miss、output を分けています。Anthropic pricing では Claude Haiku 4.5 が Claude の低価格品質 lane です。
実コスト計算式
実コストは、1回の入力価格ではなく、採用された出力のコストです。安いモデルでも schema 失敗、長すぎる出力、弱い推論、拒否、再試行が多いと、総請求額は上がります。最低限、input tokens、cached input、output tokens、tool calls、quality retries、Batch/Flex latency、region、tax、data terms を同じ表で扱います。
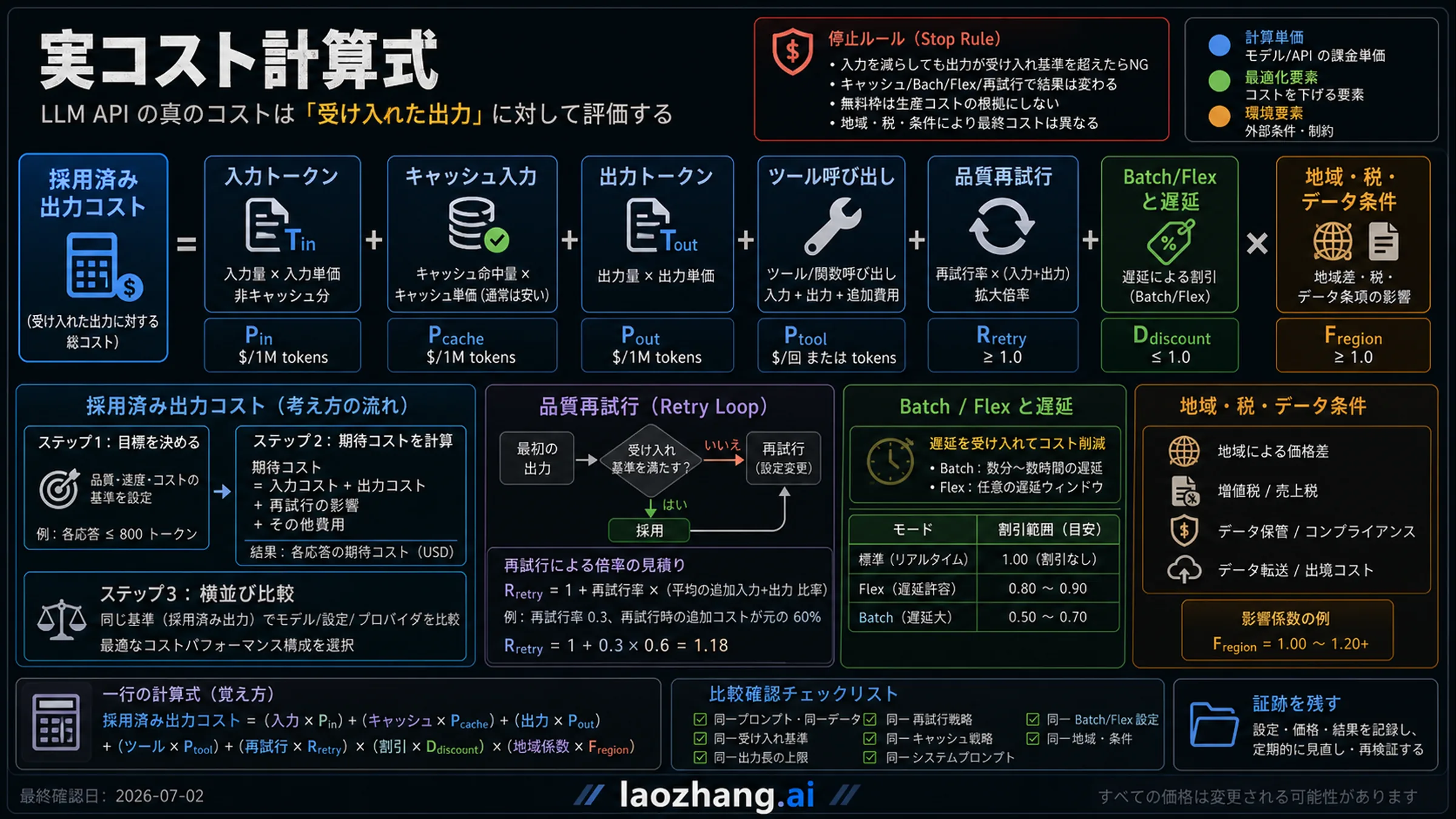
20から50件の代表的タスクで同じ prompt set を走らせ、入力量、出力量、キャッシュ命中、試行回数、合格/不合格、P50/P95 レイテンシを保存します。その総額を合格した出力数で割ると、実際の予算判断に近い数字になります。
ワークロード別に最初の lane を選ぶ
大量抽出ではキャッシュ率と schema validity が重要です。短い要約では出力長と事実性が重要です。コード生成では test pass rate が必要です。Agent ループではツール呼び出しと反復がコストを増やします。長文コンテキストでは引用の正確さとレイテンシが効きます。品質重視の出力では、より高い token row が再試行を減らして安くなる場合があります。
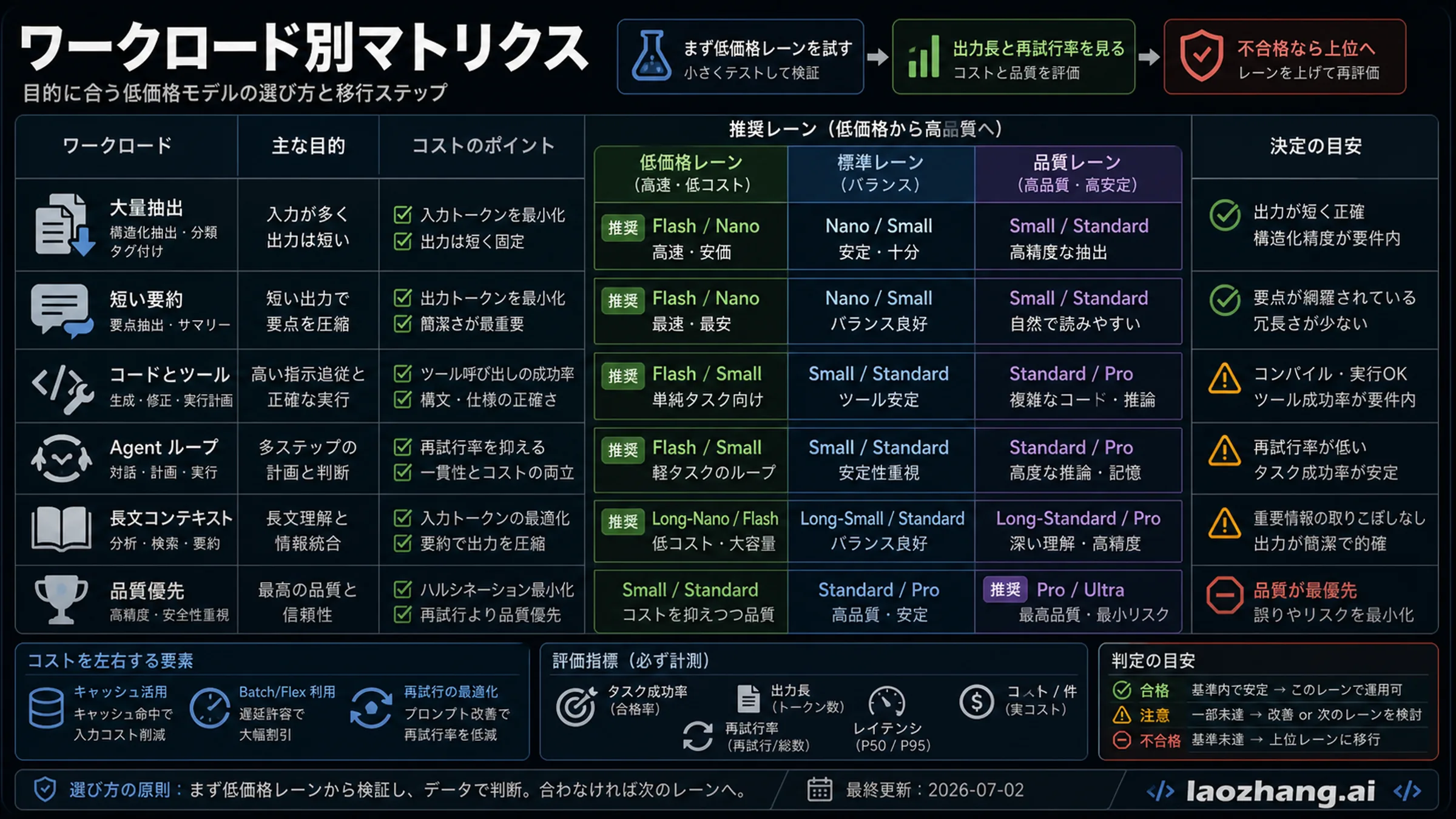
最初から十数個のモデルを比較する必要はありません。低価格 lane を二つ選び、合格基準とアップグレード条件を決めてください。不合格率や再試行率が高いなら上位 lane に移ります。価格が近い場合は、既存 stack、サポート、契約、監視のしやすさも評価します。
無料枠は本番価格ではない
無料枠は学習、prompt 検証、プロトタイプには有用です。しかし production traffic には、安定した quota、billing owner、data terms、support path、障害時の fallback が必要です。Google の pricing は Free Tier と Paid Tier を分け、データ利用条件にも差があります。
無料 route は proof-of-fit として扱い、budget として固定しないでください。本番前に model ID、serving mode、quota、rate limits、billing state、data policy、Batch/Flex、overage behavior を確認します。顧客データ、コード、ログが prompt に入る場合は、無料かどうかより terms が重要です。
ゲートウェイ価格は別契約
Gateway は移行コストを下げることがあります。OpenAI-compatible endpoint、複数モデルの切り替え、ログ、統一サポートがあるからです。ただし gateway price は official vendor price ではありません。OpenRouter、SiliconFlow、laozhang.ai などの provider row を読むときは、model ID、課金単位、cache、失敗時課金、rate limits、返金、data policy を別途検証します。
laozhang.ai を書く場合は、OpenAI-compatible migration、model coverage、logs、routing を評価する gateway route として扱います。正確な価格は現在の console/API で確認し、古い screenshot や aggregator の行を固定しません。
支出前チェックリスト

- 公式 model ID を確認します。
- input、cached input、output、Batch/Flex を記録します。
- 同じ実プロンプトでテストします。
- P50/P95 レイテンシと concurrency を測ります。
- 再試行、拒否、schema 失敗、tool calls を数えます。
- 公式価格、provider 価格、gateway fee を分けます。
- Agent や大量処理には spend cap と kill switch を入れます。
- 公開前に価格と可用性を再確認します。
推奨される開始点
最低の official paid token floor を探すなら DeepSeek V4 Flash を試します。ただし品質、地域、可用性を必ず確認します。OpenAI stack なら gpt-5-nano と Batch/Flex を確認します。Google の低価格 route なら gemini-2.5-flash-lite を起点にし、必要なら gemini-3.1-flash-lite を比較します。安いモデルが不合格なら Claude Haiku 4.5 を quality baseline として測ります。
最終結論は「このモデルが常に最安」ではなく、「この prompt set、この出力長、この cache hit rate、この品質基準では、このモデルの採用済み出力コストが最も低い」です。
予算テスト用のテンプレート
購入判断や本番導入では、価格表の数字をそのまま予算に入れないでください。自分のワークロード用に小さな台帳を作り、同じ prompt、同じ system 指示、同じ RAG 量、同じ出力上限、同じ合格基準で候補モデルを走らせます。記録する項目は、入力トークン、再利用できるキャッシュ前置き、出力トークン、形式エラー、拒否、手直し時間、P50/P95 レイテンシ、地域、quota、サポート責任者、最終的に採用できたかどうかです。この台帳がないと、安い token row が本当に安いのか、単に再試行とレビューへコストを移しているだけなのか分かりません。
| 予算項目 | 記録方法 | 最安判断に効く理由 |
|---|---|---|
| 入力トークン | system、user、検索文脈、tool schema を分ける | 長文脈では低い入力行が効くが、不要な文脈は無駄になる |
| キャッシュ入力 | 再利用できる prefix と hit rate を測る | cache-hit が安くても、再利用率が低いと効かない |
| 出力トークン | 期待長と最大長をタスク別に決める | 出力単価は高く、長い回答は順位を変える |
| 品質の再試行 | 形式崩れ、事実誤り、拒否、手直しを数える | 合格率が低いモデルは安い呼び出しでも高くなる |
| Batch/Flex | 非同期でよい仕事と即時返答が必要な仕事を分ける | 割引は待てる処理だけに意味がある |
| 契約境界 | 公式価格、プロバイダー契約、ゲートウェイ費用を分ける | 支援、ログ、返金、データ条件も本番コストになる |
テストセットは三つに分けると判断しやすくなります。第一は、短い出力で安定した抽出、分類、タグ付け、重複除去、フィールド整形です。ここでは DeepSeek V4 Flash、OpenAI nano、Google Flash-Lite 系の低価格レーンが強く見えます。第二は、要約、比較、メール下書き、商品説明のように出力が長くなるが合否を決めやすい仕事です。ここでは出力単価、長さ制御、事実誤りが重要です。第三は、コード変更、契約レビュー、財務判断、複数ステップの Agent です。ここでは token row よりもテスト通過率、監査性、人間レビューの削減が支配的になります。
抽出では安いが要約では失敗するモデルを、全体の既定モデルにしないでください。短く決定的な仕事は低価格レーンに置き、中程度の仕事は出力長と再試行上限を決め、コードやコンプライアンスでは強いモデルを品質基準として残します。こうしたルーティングは「このモデルが常に最安」というランキングより、請求書と運用で再現しやすい判断になります。
導入前には逆向きレビューも必要です。業務責任者は出力が手直しなしに使えるかを見ます。開発責任者はレイテンシ、rate limit、失敗時の処理を見ます。セキュリティ責任者はデータ条件、ログ保持、地域、サポート経路を見ます。どれか一つでも不合格なら、低い token row はまだ本番の節約になっていません。
支出前の再確認フロー
価格に依存するページや社内メモは、公開日に再確認する前提で扱います。まず公式 pricing ページを開き、model ID、input、cached input、output、Batch/Flex の行を確認します。次に、無料枠と有料枠の条件を混同していないかを確認します。特に data use、quota、support、availability は、試作では問題にならなくても本番では重要です。
ゲートウェイや OpenAI-compatible provider を使う場合は、その価格を公式価格とは別の契約として記録します。確認する項目は、実際の model ID、課金単位、失敗呼び出しの課金、rate limit、返金、ログ、データポリシーです。その後、同じ prompt で小さな請求テストを行い、平均費用ではなく P95 費用、失敗タスク費用、採用済み出力コストを見ます。最後に、schema 失敗率、手直し時間、P95 レイテンシ、地域の可用性、データ条件の不一致をアップグレード条件として書いておきます。
よくある質問
今いちばん安い LLM API モデルは何ですか?
DeepSeek V4 Flash と OpenAI gpt-5-nano が最初の低価格チェックです。Google では gemini-2.5-flash-lite が低価格 scale lane です。最終判断はワークロード次第です。
DeepSeek は常に最安ですか?
いいえ。価格行は非常に低いですが、品質、地域、遅延、可用性が合わないと、再試行と修正で高くなります。
無料 LLM API を本番に使えますか?
通常はそのまま本番価格として使いません。無料枠は prototype に適し、本番は quota、paid terms、support、data policy を確認します。
コーディングにはどれを選べばいいですか?
DeepSeek、OpenAI nano、Google Flash-Lite、既存 provider を同じ実タスクで比較し、test pass rate と採用済み出力コストで判断します。
Claude は高すぎますか?
raw token row は高いですが、Claude Haiku 4.5 が再試行や人間レビューを減らすなら、品質重視タスクでは安くなる場合があります。
価格比較サイトは信頼できますか?
候補探しには使えます。本番前の事実確認は公式 owner page または provider console で行います。